graph gpt
v0.4.0
พื้นที่เก็บข้อมูลนี้เป็นการใช้งานอย่างเป็นทางการของ “GraphGPT: การเรียนรู้กราฟด้วย Transformers ที่ได้รับการฝึกอบรมล่วงหน้าแบบ Generative” ใน PyTorch
GraphGPT: การเรียนรู้กราฟด้วย Transformers ที่ได้รับการฝึกอบรมล่วงหน้าแบบ Generative
ฉีฟาง จ้าว, เว่ยตง เหริน, เทียนหยู่ ลี่, เสี่ยวเซียว ซู, หง หลิว
10/13/2024
CHANGELOG.md เพื่อดูรายละเอียด18/08/2024
CHANGELOG.md เพื่อดูรายละเอียด07/09/2024
19/03/2024
permute_nodes สำหรับชุดข้อมูลรูปแบบแผนที่ระดับกราฟ เพื่อเพิ่มความแปรผันของเส้นทาง Eulerian และให้ผลลัพธ์ที่ดีขึ้นและแข็งแกร่งStackedGSTTokenizer เพื่อให้โทเค็นความหมาย (เช่น โหนด/edge attrs) สามารถซ้อนกันร่วมกับโทเค็นโครงสร้างได้ และความยาวของลำดับจะลดลงอย่างมาก23/01/2024
01/03/2024

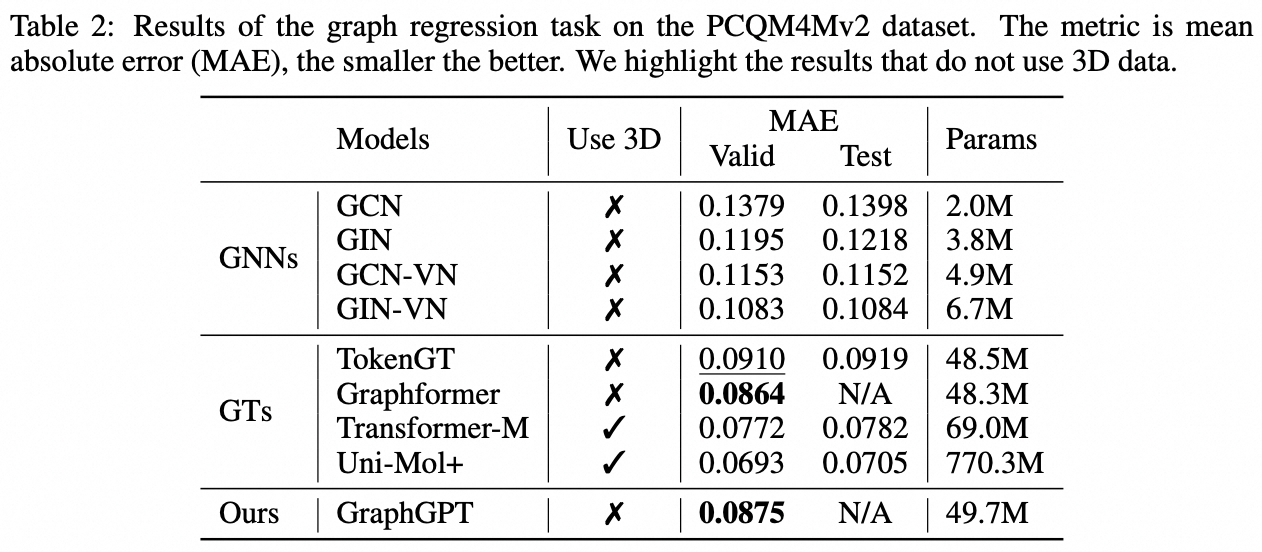
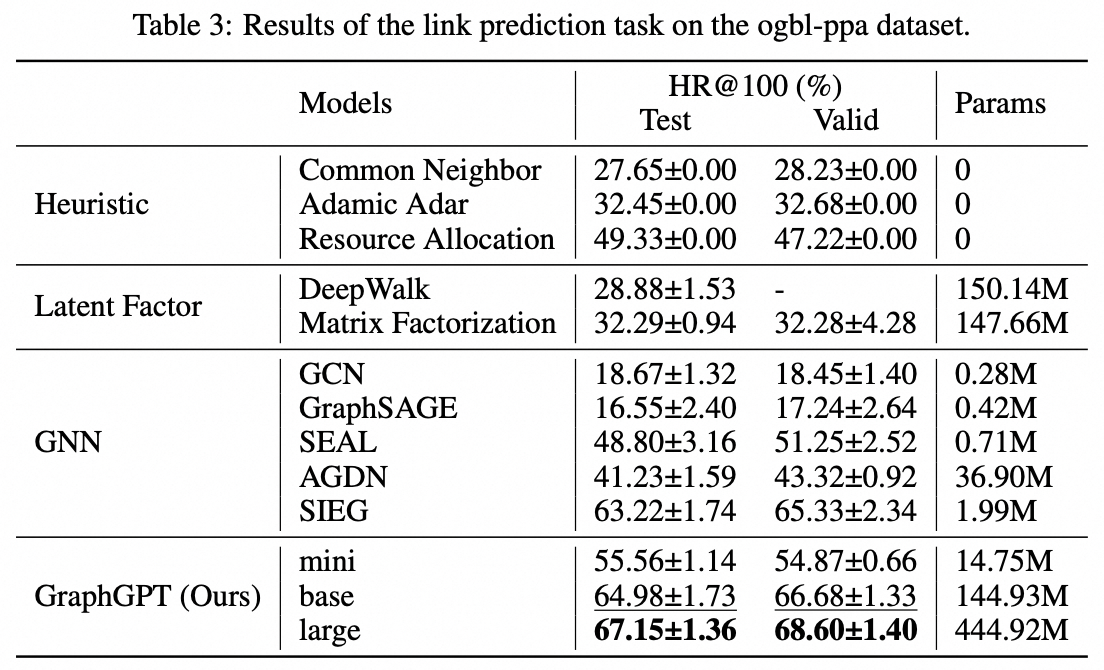
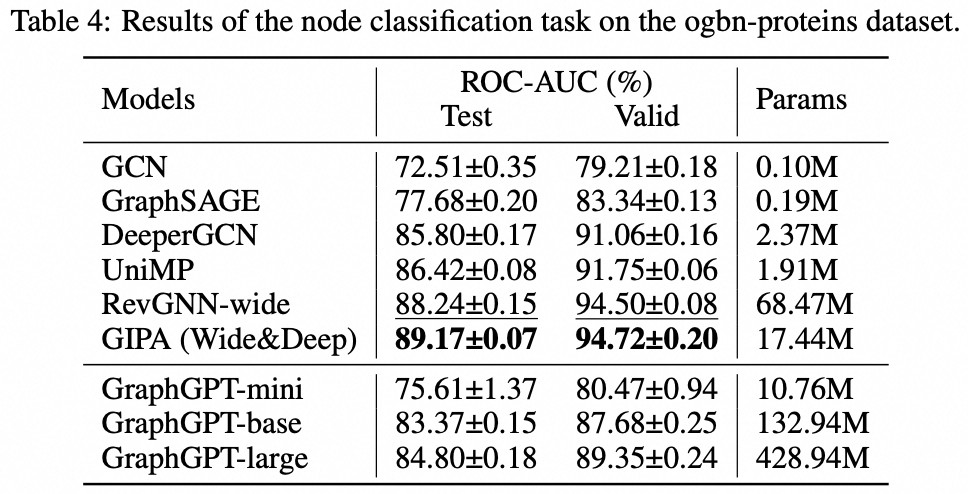
เราขอเสนอ GraphGPT ซึ่งเป็นโมเดลใหม่สำหรับการเรียนรู้กราฟโดย Generative Pre-training Graph Eulerian Transformers (GET) ที่ดูแลตนเอง ก่อนอื่นเราจะแนะนำ GET ซึ่งประกอบด้วยแกนหลักของตัวเข้ารหัส/ตัวถอดรหัสของ Transformer และการแปลงที่เปลี่ยนแต่ละกราฟหรือกราฟย่อยตัวอย่างให้เป็นลำดับของโทเค็นที่แสดงถึงโหนด ขอบ และคุณลักษณะที่ย้อนกลับได้โดยใช้เส้นทาง Eulerian จากนั้นเราจะฝึกอบรม GET ล่วงหน้าด้วยงาน next-token-prediction (NTP) หรืองาน masked-token-prediction (SMTP) ที่กำหนดเวลาไว้ สุดท้ายนี้ เราปรับแต่งโมเดลด้วยงานที่ได้รับการดูแล โมเดลที่ใช้งานง่ายแต่มีประสิทธิภาพนี้ให้ผลลัพธ์ที่เหนือกว่าหรือใกล้เคียงกับวิธีการล้ำสมัยสำหรับงานกราฟ ขอบ และระดับโหนดบนชุดข้อมูลโมเลกุลขนาดใหญ่ PCQM4Mv2 ซึ่งเป็นชุดข้อมูลการเชื่อมโยงโปรตีน-โปรตีน ogbl-ppa , ชุดข้อมูลเครือข่ายการอ้างอิง ogbl-citation2 และชุดข้อมูล ogbn-proteins จาก Open Graph Benchmark (OGB) นอกจากนี้ การฝึกอบรมล่วงหน้าแบบเจนเนอเรทีฟยังช่วยให้เราฝึก GraphGPT ได้ถึงพารามิเตอร์ 2B+ พร้อมประสิทธิภาพที่เพิ่มขึ้นอย่างต่อเนื่อง ซึ่งเกินความสามารถของ GNN และหม้อแปลงกราฟรุ่นก่อนๆ
หลังจากแปลงกราฟออยเลอร์ไรซ์เป็นลำดับแล้ว มีหลายวิธีในการแนบคุณลักษณะของโหนดและขอบเข้ากับลำดับ เราตั้งชื่อวิธีการเหล่านี้ว่า short long และ prolonged
เมื่อพิจารณาจากกราฟแล้ว เราจะทำการออยเลอร์ไลซ์กราฟก่อน แล้วจึงแปลงกราฟให้เป็นลำดับที่เทียบเท่ากัน จากนั้นเราจะจัดทำดัชนีโหนดใหม่แบบวนรอบ
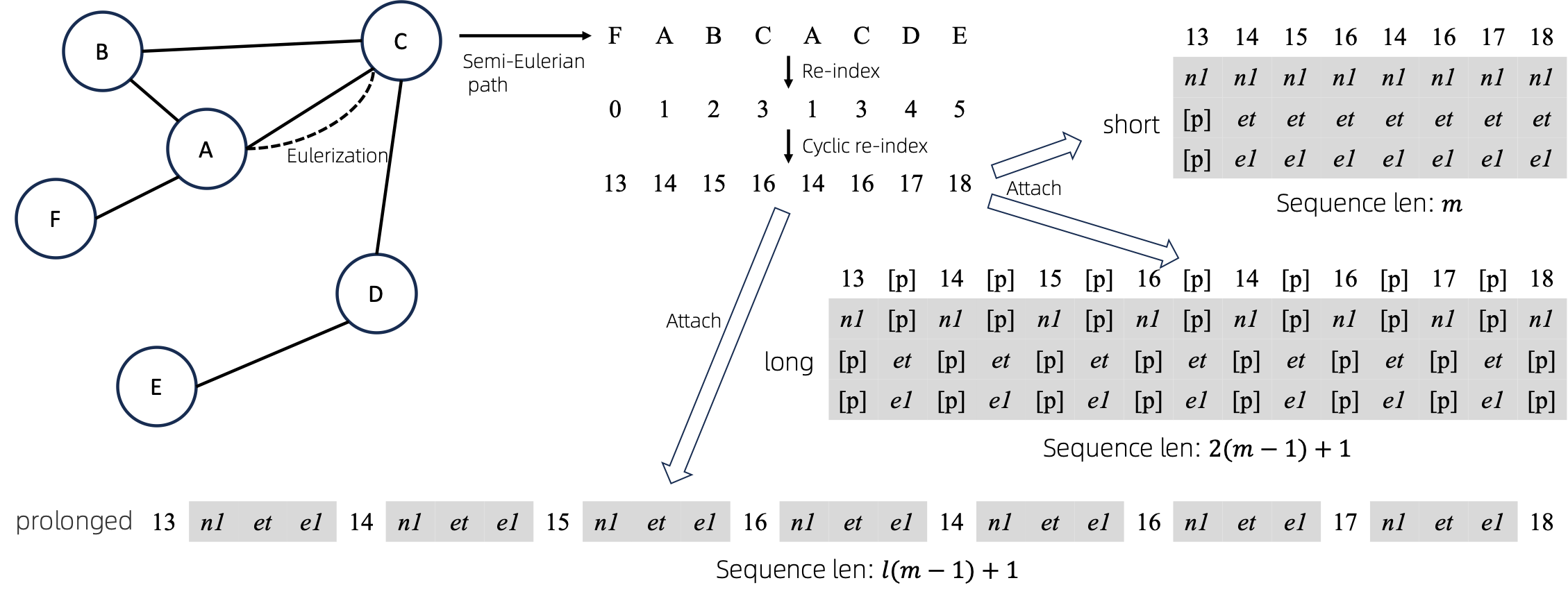
สมมติว่ากราฟมีแอตทริบิวต์ของโหนดหนึ่งรายการและคุณลักษณะของ Edge หนึ่งรายการ จากนั้นวิธี short , long และ prolong จะแสดงอยู่ด้านบน
ในรูปด้านบน n1 , n2 และ e1 แสดงถึงโทเค็นของแอตทริบิวต์โหนดและขอบ และ [p] แสดงถึงโทเค็นการเติม
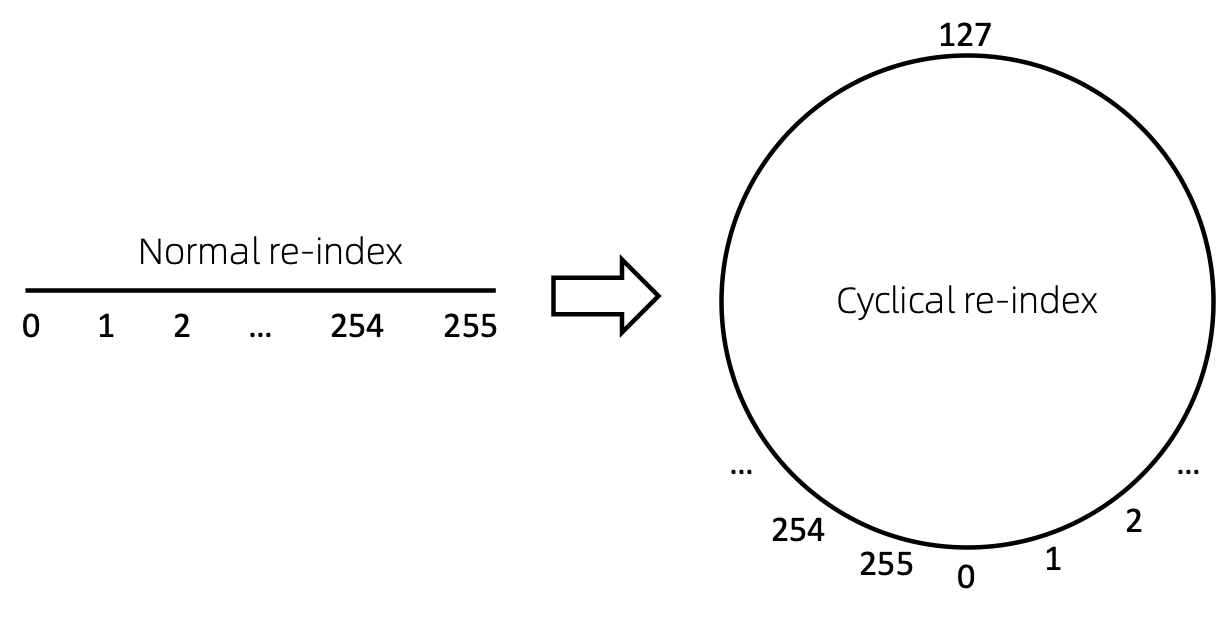
วิธีที่ตรงไปตรงมาในการจัดทำดัชนีลำดับของโหนดใหม่คือการเริ่มต้นด้วย 0 และเพิ่ม 1 ทีละน้อย ด้วยวิธีนี้ โทเค็นของดัชนีขนาดเล็กจะได้รับการฝึกฝนอย่างเพียงพอ และดัชนีขนาดใหญ่จะไม่ได้รับการฝึกฝน เพื่อเอาชนะสิ่งนี้ เราเสนอ cyclical re-index ซึ่งเริ่มต้นด้วยตัวเลขสุ่มในช่วงที่กำหนด พูด [0, 255] และเพิ่มขึ้นทีละ 1 หลังจากไปถึงขอบเขต เช่น 255 ดัชนีโหนดถัดไปจะเป็น 0 .
ล้าสมัย จะได้รับการปรับปรุงเร็ว ๆ นี้
git clone https://github.com/alibaba/graph-gpt.gitconda create -n graph_gpt python=3.8 pytorch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 pytorch-cuda=11.7 -c pytorch -c nvidia
conda activate graph_gpt
cd graph-gpt
pip install -r ./requirements.txt
pip install torch-scatter torch-sparse -f https://data.pyg.org/whl/torch-1.13.1+cpu.html
sudo apt-get install bcชุดข้อมูลจะถูกดาวน์โหลดโดยใช้แพ็คเกจ ogb ของ python
เมื่อคุณเรียกใช้สคริปต์ใน ./examples ชุดข้อมูลจะถูกดาวน์โหลดโดยอัตโนมัติ
อย่างไรก็ตาม ชุดข้อมูล PCQM4M-v2 มีขนาดใหญ่ และการดาวน์โหลดและการประมวลผลล่วงหน้าอาจเป็นปัญหาได้ เราขอแนะนำ cd ./src/utils/ และ python dataset_utils.py เพื่อดาวน์โหลดและประมวลผลชุดข้อมูลล่วงหน้าแยกกัน
./examples/graph_lvl/pcqm4m_v2_pretrain.sh เช่น dataset_name , model_name , batch_size , workerCount และอื่นๆ จากนั้นเรียกใช้ ./examples/graph_lvl/pcqm4m_v2_pretrain.sh เพื่อฝึกโมเดลล่วงหน้าด้วย PCQM4M-v2 ชุดข้อมูล./examples/toy_examples/reddit_pretrain.sh โดยตรง./examples/graph_lvl/pcqm4m_v2_supervised.sh เช่น dataset_name , model_name , batch_size , workerCount , pretrain_cpt และอื่นๆ จากนั้นรัน ./examples/graph_lvl/pcqm4m_v2_supervised.sh เพื่อปรับแต่งอย่างละเอียดกับงานดาวน์สตรีม ../examples/toy_examples/reddit_supervised.sh โดยตรง .pre-commit-config.yaml : สร้างไฟล์ที่มีเนื้อหาต่อไปนี้สำหรับ python repos :
- repo : https://github.com/pre-commit/pre-commit-hooks
rev : v4.4.0
hooks :
- id : check-yaml
- id : end-of-file-fixer
- id : trailing-whitespace
- repo : https://github.com/psf/black
rev : 23.7.0
hooks :
- id : blackpre-commit install : ติดตั้ง pre-commit ลงใน git hooks ของคุณpre-commit install ควรเป็นสิ่งแรกที่คุณทำเสมอpre-commit run --all-files : รัน hooks ที่คอมมิตล่วงหน้าทั้งหมดบนที่เก็บpre-commit autoupdate : อัปเดต hooks ของคุณเป็นเวอร์ชันล่าสุดโดยอัตโนมัติgit commit -n : การตรวจสอบก่อนคอมมิตสามารถปิดใช้งานได้สำหรับคอมมิตเฉพาะด้วยคำสั่ง หากคุณพบว่างานนี้มีประโยชน์ กรุณาอ้างอิงเอกสารต่อไปนี้:
@article{zhao2024graphgpt,
title={GraphGPT: Graph Learning with Generative Pre-trained Transformers},
author={Zhao, Qifang and Ren, Weidong and Li, Tianyu and Xu, Xiaoxiao and Liu, Hong},
journal={arXiv preprint arXiv:2401.00529},
year={2024}
}ฉีฟาง จ้าว ([email protected])
ขอขอบคุณอย่างจริงใจสำหรับข้อเสนอแนะของคุณเกี่ยวกับงานของเรา!
เผยแพร่ภายใต้ใบอนุญาต MIT (ดู LICENSE ):
Ali-GraphGPT-project is an AI project on training large scale transformer decoder with graph datasets,
developed by Alibaba and licensed under the MIT License.


