VisualGLM 6B
1.0.0
? HF Repo • ⚒️ SwissArmyTransformer (วันเสาร์) • ?
• ? [CogView@NeurIPS 21] [GitHub] • ? [GLM@ACL 22] [GitHub]
เข้าร่วมกับเราบน Slack และ WeChat
[10/2023] ยินดีต้อนรับสู่ CogVLM (https://github.com/THUDM/CogVLM) ซึ่งเป็นโมเดลบทสนทนาหลายรูปแบบรุ่นใหม่ของ Zhipu AI โดยนำสถาปัตยกรรมใหม่ของผู้เชี่ยวชาญด้านภาพมาใช้ และได้รับรางวัลที่หนึ่งในปี 10 งานหลายรูปแบบแบบคลาสสิกที่เชื่อถือได้ โมเดลภาษาอังกฤษแบบโอเพ่นซอร์ส CogVLM-17B ในปัจจุบันจะขึ้นอยู่กับโมเดลภาษาจีนแบบโอเพ่นซอร์ส GLM
VisualGLM-6B เป็นโมเดลภาษาโต้ตอบแบบโอเพ่นซอร์สหลายรูปแบบที่รองรับ รูปภาพ ภาษาจีน และภาษาอังกฤษ โมเดลภาษานั้นใช้ ChatGLM-6B พร้อมด้วยพารามิเตอร์ 6.2 พันล้านตัว ส่วนรูปภาพจะสร้างสะพานเชื่อมระหว่างโมเดลภาพและ โมเดลภาษาผ่านการฝึกอบรม BLIP2-Qformer โดยมีโมเดลทั้งหมดประกอบด้วยพารามิเตอร์ 7.8 พันล้านพารามิเตอร์ คลิกที่นี่เพื่อดูเวอร์ชันภาษาอังกฤษ
VisualGLM-6B เป็นโมเดลภาษาโอเพ่นซอร์สหลายรูปแบบที่รองรับ รูปภาพ ภาษาจีนและภาษาอังกฤษ โมเดลภาษาอิงตาม ChatGLM-6B และมีพารามิเตอร์ 6.2 พันล้านตัว ส่วนรูปภาพจะสร้างสะพานเชื่อมระหว่างโมเดลภาพและโมเดลภาษา โดยการฝึกอบรม BLIP2-Qformer โมเดลโดยรวมมีพารามิเตอร์ทั้งหมด 7.8 พันล้าน
VisualGLM-6B อาศัยคู่ข้อความรูปภาพภาษาจีนคุณภาพสูง 30 ล้านคู่จากชุดข้อมูล CogView และคู่ข้อความรูปภาพภาษาอังกฤษที่ผ่านการคัดกรอง 300 ล้านคู่สำหรับการฝึกอบรมล่วงหน้าภาษาจีนและอังกฤษจะเท่ากัน วิธีการฝึกอบรมนี้จะจัดข้อมูลภาพให้สอดคล้องกับพื้นที่ความหมายของ ChatGLM ได้ดีขึ้น ในขั้นตอนการปรับแต่งที่ตามมา โมเดลจะได้รับการฝึกอบรมเกี่ยวกับข้อมูลคำถามและคำตอบแบบภาพขนาดยาวเพื่อสร้างคำตอบที่สอดคล้องกับความชอบของมนุษย์
VisualGLM-6B ได้รับการฝึกอบรมโดยไลบรารี SwissArmyTransformer (หรือ sat สั้นๆ ว่า) ซึ่งเป็นไลบรารีเครื่องมือที่รองรับการปรับเปลี่ยนและการฝึกอบรม Transformer อย่างยืดหยุ่น และสนับสนุนวิธีการปรับแต่งพารามิเตอร์อย่างละเอียดอย่างมีประสิทธิภาพ เช่น Lora และ P-tuning โปรเจ็กต์นี้จัดเตรียมอินเทอร์เฟซของ Huggingface ที่สอดคล้องกับพฤติกรรมของผู้ใช้ และยังจัดเตรียมอินเทอร์เฟซตาม sat ด้วย
เมื่อรวมกับเทคโนโลยีการวัดปริมาณแบบจำลอง ผู้ใช้สามารถปรับใช้ภายในเครื่องบนกราฟิกการ์ดระดับผู้บริโภคได้ (หน่วยความจำวิดีโอขั้นต่ำที่ต้องการคือ 6.3G ที่ระดับการวัดปริมาณ INT4)
โมเดลโอเพ่นซอร์ส VisualGLM-6B มีวัตถุประสงค์เพื่อส่งเสริมการพัฒนาเทคโนโลยีโมเดลขนาดใหญ่ร่วมกับชุมชนโอเพ่นซอร์ส ขอให้นักพัฒนาและทุกคนปฏิบัติตามข้อตกลงโอเพ่นซอร์ส และอย่าใช้โมเดลโอเพ่นซอร์สและโค้ดและอนุพันธ์ตาม โครงการโอเพ่นซอร์สนี้เพื่อวัตถุประสงค์ใด ๆ ที่อาจก่อให้เกิดอันตรายต่อประเทศและสังคม การใช้งานที่เป็นอันตรายและบริการใด ๆ ที่ไม่ได้รับการประเมินและจัดทำเอกสารด้านความปลอดภัย ปัจจุบัน โปรเจ็กต์นี้ยังไม่ได้พัฒนาแอปพลิเคชันใดๆ อย่างเป็นทางการที่ใช้ VisualGLM-6B รวมถึงเว็บไซต์, แอป Android, แอปพลิเคชัน Apple iOS, แอป Windows เป็นต้น
เนื่องจาก VisualGLM-6B ยังคงอยู่ในเวอร์ชัน v1 เป็นที่ทราบกันว่าในปัจจุบันมี ข้อจำกัด บางประการ เช่น ข้อเท็จจริงของคำอธิบายรูปภาพ/ปัญหาภาพหลอนของโมเดล การเก็บข้อมูลรายละเอียดรูปภาพไม่เพียงพอ และข้อจำกัดบางประการจากโมเดลภาษา แม้ว่าแบบจำลองจะพยายามอย่างดีที่สุดเพื่อให้แน่ใจว่าข้อมูลสอดคล้องและถูกต้องในแต่ละขั้นตอนของการฝึกอบรม เนื่องจากแบบจำลอง VisualGLM-6B ขนาดเล็กและความจริงที่ว่าแบบจำลองได้รับผลกระทบจากปัจจัยความน่าจะเป็นและแบบสุ่ม ความแม่นยำของ ไม่สามารถรับประกันเนื้อหาเอาต์พุตได้ และโมเดลอาจทำให้เข้าใจผิดได้ง่าย (ดูรายละเอียดในส่วนข้อจำกัด) ใน VisualGLM เวอร์ชันต่อๆ ไป จะมีการพยายามปรับปัญหาดังกล่าวให้เหมาะสม โครงการนี้ไม่รับความเสี่ยงและความรับผิดชอบด้านความปลอดภัยของข้อมูลและความเสี่ยงต่อความคิดเห็นสาธารณะที่เกิดจากโมเดลและโค้ดโอเพ่นซอร์ส หรือความเสี่ยงและความรับผิดชอบที่เกิดจากโมเดลใดๆ ที่ถูกทำให้เข้าใจผิด ถูกนำไปใช้ในทางที่ผิด เผยแพร่ หรือใช้ประโยชน์อย่างไม่เหมาะสม
VisualGLM-6B สามารถตอบคำถามและตอบความรู้ที่เกี่ยวข้องกับคำอธิบายรูปภาพได้ 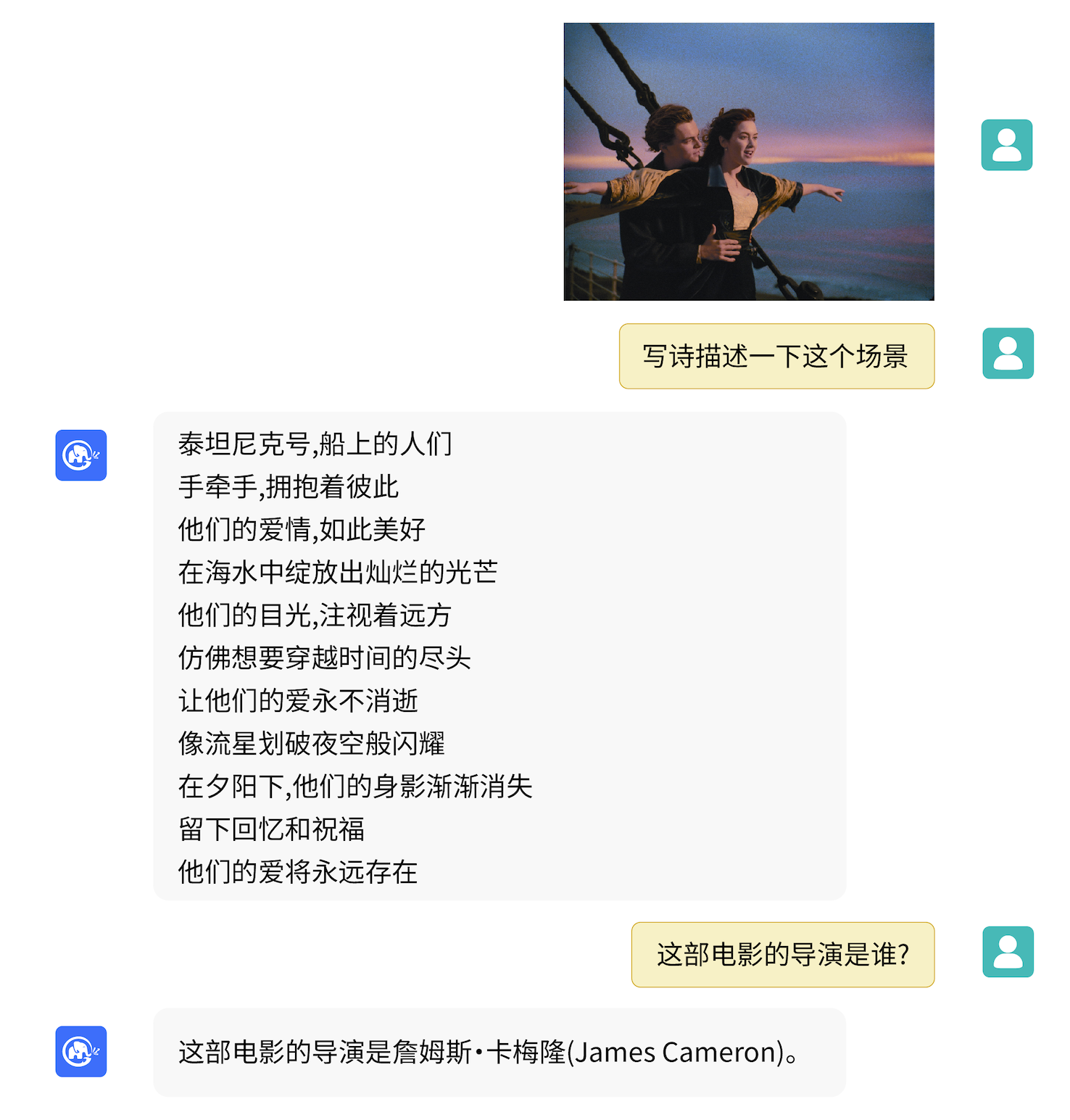


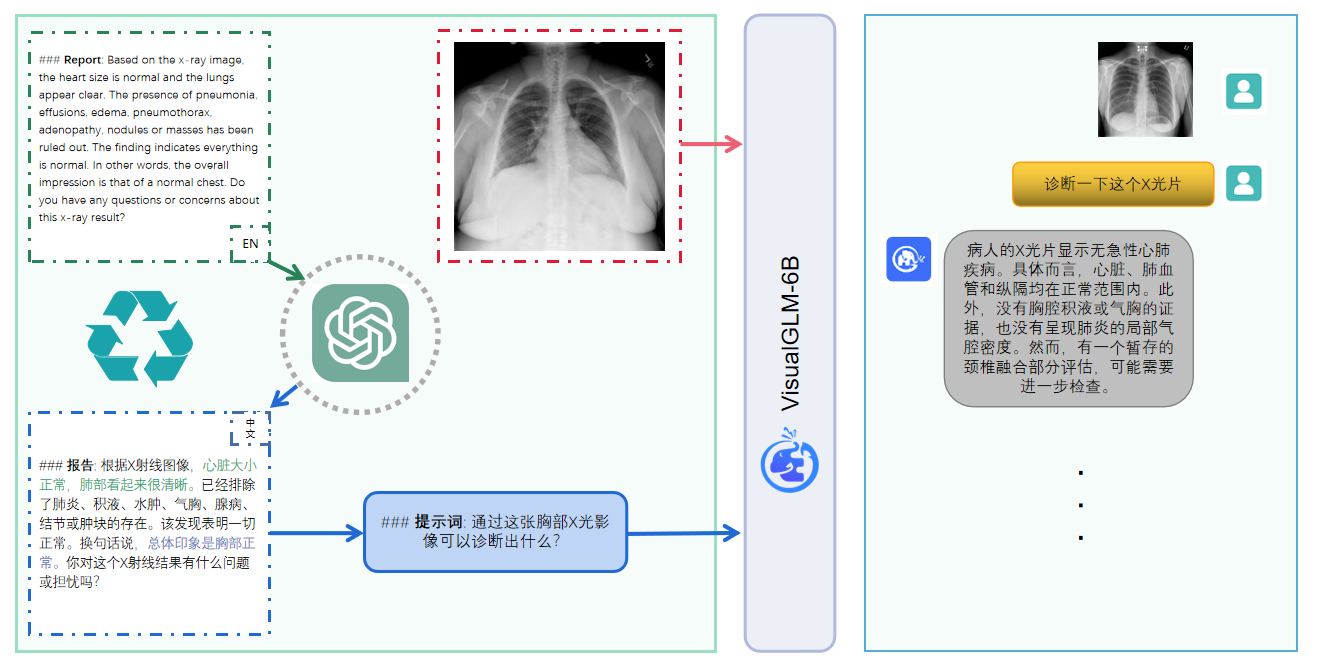

ใช้ pip เพื่อติดตั้งการอ้างอิง
pip install -i https://pypi.org/simple -r requirements.txt
# 国内请使用aliyun镜像,TUNA等镜像同步最近出现问题,命令如下
pip install -i https://mirrors.aliyun.com/pypi/simple/ -r requirements.txt
ในขณะนี้ ไลบรารี deepspeed (ซึ่งรองรับการฝึกอบรมไลบรารี sat ) จะถูกติดตั้งตามค่าเริ่มต้น ไลบรารีนี้ไม่จำเป็นสำหรับการอนุมานโมเดล ในเวลาเดียวกัน สภาพแวดล้อม Windows บางอย่างจะประสบปัญหาเมื่อติดตั้งไลบรารีนี้ หากเราต้องการข้ามการติดตั้ง deepspeed เราก็สามารถเปลี่ยนคำสั่งเป็นได้
pip install -i https://mirrors.aliyun.com/pypi/simple/ -r requirements_wo_ds.txt
pip install -i https://mirrors.aliyun.com/pypi/simple/ --no-deps "SwissArmyTransformer>=0.4.4"
หากคุณใช้ไลบรารี Huggingface Transformers เพื่อเรียกโมเดล ( คุณต้องติดตั้งแพ็คเกจการพึ่งพาข้างต้นด้วย! ) คุณสามารถส่งโค้ดต่อไปนี้ (โดยที่เส้นทางรูปภาพคือเส้นทางในเครื่อง):
from transformers import AutoTokenizer , AutoModel
tokenizer = AutoTokenizer . from_pretrained ( "THUDM/visualglm-6b" , trust_remote_code = True )
model = AutoModel . from_pretrained ( "THUDM/visualglm-6b" , trust_remote_code = True ). half (). cuda ()
image_path = "your image path"
response , history = model . chat ( tokenizer , image_path , "描述这张图片。" , history = [])
print ( response )
response , history = model . chat ( tokenizer , image_path , "这张图片可能是在什么场所拍摄的?" , history = history )
print ( response ) โค้ดด้านบนจะดาวน์โหลดการใช้งานโมเดลและพารามิเตอร์โดย transformers โดยอัตโนมัติ การใช้งานโมเดลที่สมบูรณ์สามารถพบได้ใน Hugging Face Hub หากคุณดาวน์โหลดพารามิเตอร์โมเดลจาก Hugging Face Hub ช้า คุณสามารถดาวน์โหลดไฟล์พารามิเตอร์โมเดลด้วยตนเองได้จากที่นี่ และโหลดโมเดลในเครื่อง สำหรับวิธีการเฉพาะ โปรดดูที่การโหลดโมเดลจากภายในเครื่อง สำหรับข้อมูลเกี่ยวกับปริมาณ การอนุมาน CPU การเร่งความเร็วแบ็กเอนด์ Mac MPS ฯลฯ ตามโมเดลไลบรารี Transformers โปรดดูการปรับใช้ ChatGLM-6B ที่มีต้นทุนต่ำ
หากคุณใช้ไลบรารี SwissArmyTransformer เพื่อเรียกโมเดล วิธีการจะคล้ายกัน คุณสามารถใช้ตัวแปรสภาพแวดล้อม SAT_HOME เพื่อกำหนดตำแหน่งการดาวน์โหลดโมเดลได้ ในไดเรกทอรีคลังสินค้านี้:
import argparse
from transformers import AutoTokenizer
tokenizer = AutoTokenizer . from_pretrained ( "THUDM/chatglm-6b" , trust_remote_code = True )
from model import chat , VisualGLMModel
model , model_args = VisualGLMModel . from_pretrained ( 'visualglm-6b' , args = argparse . Namespace ( fp16 = True , skip_init = True ))
from sat . model . mixins import CachedAutoregressiveMixin
model . add_mixin ( 'auto-regressive' , CachedAutoregressiveMixin ())
image_path = "your image path or URL"
response , history , cache_image = chat ( image_path , model , tokenizer , "描述这张图片。" , history = [])
print ( response )
response , history , cache_image = chat ( None , model , tokenizer , "这张图片可能是在什么场所拍摄的?" , history = history , image = cache_image )
print ( response ) การปรับแต่งพารามิเตอร์อย่างละเอียดอย่างมีประสิทธิภาพยังทำได้อย่างง่ายดายโดยใช้ไลบรารี sat
งานต่อเนื่องหลายรูปแบบมีการกระจายอย่างกว้างขวางและมีหลายประเภท และการฝึกอบรมล่วงหน้ามักไม่ครอบคลุมทุกอย่าง ในที่นี้ เรามีตัวอย่างการปรับแต่งตัวอย่างเล็กๆ น้อยๆ โดยใช้รูปภาพที่มีคำอธิบายประกอบ 20 ภาพ เพื่อเพิ่มความสามารถของโมเดลในการตอบคำถาม "เบื้องหลัง"
คลายซิป fewshot-data.zip และรันคำสั่งต่อไปนี้:
bash finetune/finetune_visualglm.sh
ปัจจุบันรองรับการปรับแต่งแบบละเอียดสามวิธี:
--layer_range และ --lora_rank ตามสถานการณ์และปริมาณข้อมูลเฉพาะได้bash finetune/finetune_visualglm_qlora.sh QLoRA หาปริมาณเลเยอร์เชิงเส้นของ ChatGLM ด้วย 4 บิต และต้องการหน่วยความจำวิดีโอเพียง 9.8GB สำหรับการปรับแต่งอย่างละเอียด--use_lora ด้วย --use_ptuning ได้ แต่ไม่แนะนำ เว้นแต่สถานการณ์จำลองของแอปพลิเคชันจะได้รับการแก้ไขอย่างมากหลังจากการฝึกอบรม คุณสามารถใช้คำสั่งต่อไปนี้เพื่ออนุมานได้:
python cli_demo.py --from_pretrained your_checkpoint_path --prompt_zh 这张图片的背景里有什么内容?
ก่อนทำการปรับแต่งแบบละเอียด:
欢迎使用 VisualGLM-6B 模型,输入图像URL或本地路径读图,继续输入内容对话,clear 重新开始,stop 终止程序
请输入图像路径或URL(回车进入纯文本对话): fewshot-data/2p.png
用户:这张图片的背景里有什么内容?
VisualGLM-6B:人们总是被生活琐事所困扰,无法摆脱束缚.
用户:clear
请输入图像路径或URL(回车进入纯文本对话): fewshot-data/meme.png
用户:这张图片的背景里有什么内容?
VisualGLM-6B:这张图片的背景是一张狗的图片,它躺在木地板上。
用户:clear
请输入图像路径或URL(回车进入纯文本对话): fewshot-data/passport.png
用户:这张图片的背景里有什么内容?
VisualGLM-6B:这张图片的背景是一台电脑键盘和两张护照。
用户:clear
请输入图像路径或URL(回车进入纯文本对话):
หลังการปรับแบบละเอียด:
欢迎使用 VisualGLM-6B 模型,输入图像URL或本地路径读图,继续输入内容对话,clear 重新开始,stop 终止程序
请输入图像路径或URL(回车进入纯文本对话): fewshot-data/2p.png
用户:这张图片的背景里有什么内容?
VisualGLM-6B:这张图片的背景是雨天,
用户:描述一下这张图片。
VisualGLM-6B:这张图片描绘了雨天的情景,雨水淅淅沥沥地落在地面上。人们穿着雨衣或雨伞,走在雨中,似乎在寻找着什么.
用户:clear
请输入图像路径或URL(回车进入纯文本对话): fewshot-data/meme.png
用户:这张图片的背景里有什么内容?
VisualGLM-6B:这张图片的背景是木质地板。
用户:什么颜色的地板
VisualGLM-6B:这张图片的背景是蓝色的。
用户:描述一下这张图片。
VisualGLM-6B:这张图片描绘了一只棕色的小狗躺在蓝色的木质地板上。
用户:clear
请输入图像路径或URL(回车进入纯文本对话): fewshot-data/passport.png
用户:这张图片的背景里有什么内容?
VisualGLM-6B:这张图片的背景是电脑键盘。
用户:描述一下这张图片。
VisualGLM-6B:这张图片的特点是电脑键盘和护照。
用户:有几张护照
VisualGLM-6B:两张护照。
用户:clear
请输入图像路径或URL(回车进入纯文本对话):
หากคุณต้องการรวมพารามิเตอร์ของส่วน LoRA เข้ากับน้ำหนักดั้งเดิม คุณสามารถเรียก merge_lora() ได้ เช่น:
from finetune_visualglm import FineTuneVisualGLMModel
import argparse
model , args = FineTuneVisualGLMModel . from_pretrained ( 'checkpoints/finetune-visualglm-6b-05-19-07-36' ,
args = argparse . Namespace (
fp16 = True ,
skip_init = True ,
use_gpu_initialization = True ,
device = 'cuda' ,
))
model . get_mixin ( 'lora' ). merge_lora ()
args . layer_range = []
args . save = 'merge_lora'
args . mode = 'inference'
from sat . training . model_io import save_checkpoint
save_checkpoint ( 1 , model , None , None , args ) การปรับแต่งอย่างละเอียดจำเป็นต้องติดตั้งไลบรารี deepspeed ในปัจจุบัน กระบวนการนี้รองรับเฉพาะระบบ Linux และคำแนะนำด้านกระบวนการเพิ่มเติมสำหรับระบบ Windows จะแล้วเสร็จในอนาคตอันใกล้นี้
python cli_demo.py โปรแกรมจะดาวน์โหลดโมเดล sat โดยอัตโนมัติและดำเนินการสนทนาแบบโต้ตอบบนบรรทัดคำสั่ง ป้อนคำแนะนำแล้วกด Enter เพื่อสร้างการตอบกลับ ป้อนล้างประวัติการสนทนา
 โปรแกรมจัดเตรียมไฮเปอร์พารามิเตอร์ต่อไปนี้เพื่อควบคุมกระบวนการผลิตและความแม่นยำในการหาปริมาณ:
โปรแกรมจัดเตรียมไฮเปอร์พารามิเตอร์ต่อไปนี้เพื่อควบคุมกระบวนการผลิตและความแม่นยำในการหาปริมาณ:
usage: cli_demo.py [-h] [--max_length MAX_LENGTH] [--top_p TOP_P] [--top_k TOP_K] [--temperature TEMPERATURE] [--english] [--quant {8,4}]
optional arguments:
-h, --help show this help message and exit
--max_length MAX_LENGTH
max length of the total sequence
--top_p TOP_P top p for nucleus sampling
--top_k TOP_K top k for top k sampling
--temperature TEMPERATURE
temperature for sampling
--english only output English
--quant {8,4} quantization bits
ควรสังเกตว่าในระหว่างการฝึกอบรม คำพร้อมท์สำหรับคู่คำถามและคำตอบภาษาอังกฤษคือ Q: A: : ในขณะที่ข้อความเตือนภาษาจีนคือ问:答: และผสมกับภาษาจีน หากจำเป็น หากต้องการตอบกลับเป็นภาษาอังกฤษ โปรดใช้ตัวเลือก --english ใน cli_demo.py
นอกจากนี้เรายังมีเครื่องมือบรรทัดคำสั่งเอฟเฟกต์เครื่องพิมพ์ดีดที่สืบทอดมาจาก ChatGLM-6B เครื่องมือนี้ใช้โมเดล Huggingface:
python cli_demo_hf.pyนอกจากนี้เรายังรองรับการใช้งานโมเดลหลายการ์ดแบบขนาน: (คุณต้องอัปเดต sat เวอร์ชันล่าสุด หากคุณเคยดาวน์โหลดจุดตรวจสอบมาก่อน คุณจะต้องลบออกด้วยตนเองแล้วดาวน์โหลดอีกครั้ง)
torchrun --nnode 1 --nproc-per-node 2 cli_demo_mp.py
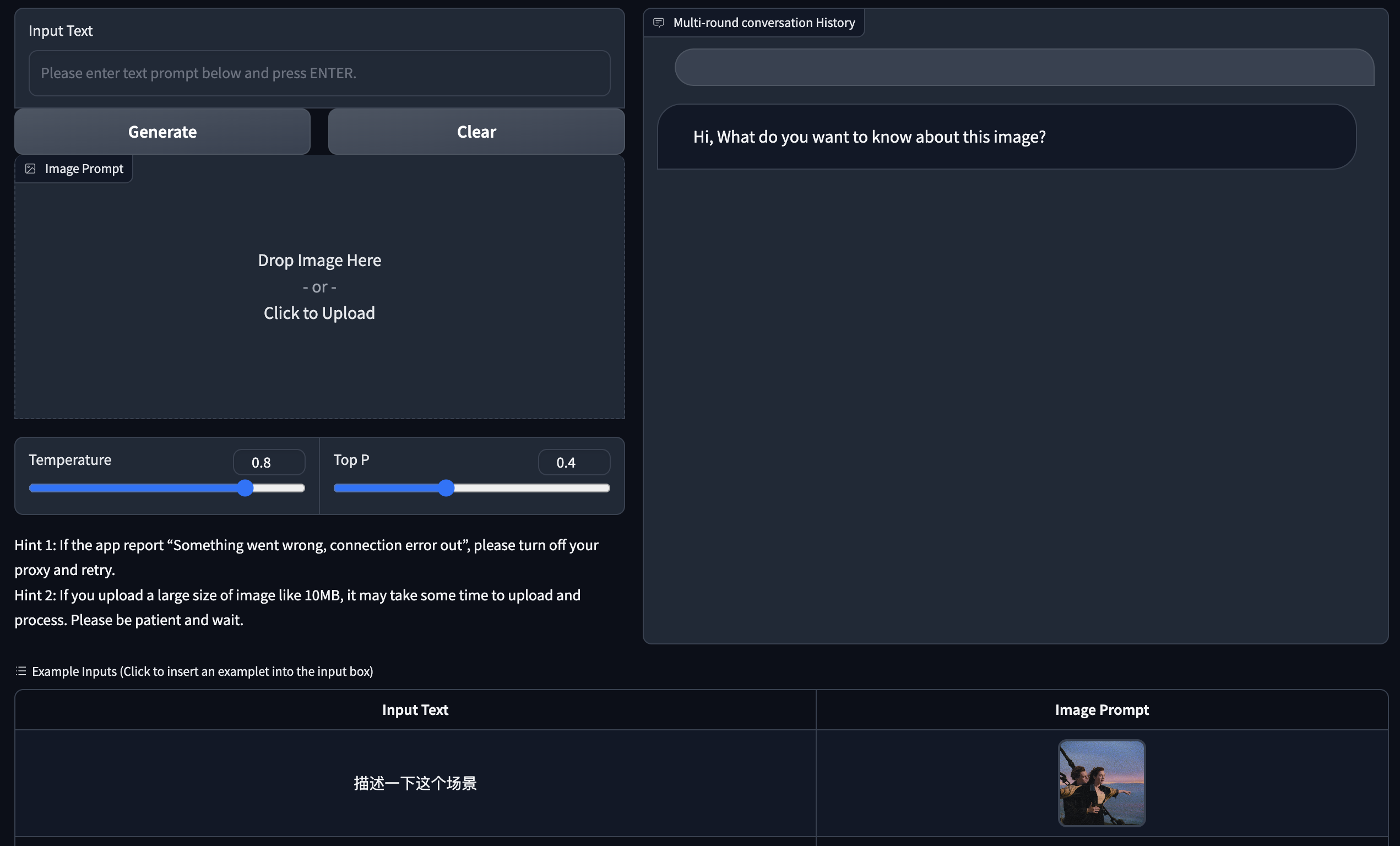
เราจัดให้มีการสาธิตเวอร์ชันเว็บโดยใช้ Gradio ขั้นแรกให้ติดตั้ง Gradio: pip install gradio จากนั้นดาวน์โหลดและเข้าสู่คลังข้อมูลนี้เพื่อรัน web_demo.py :
git clone https://github.com/THUDM/VisualGLM-6B
cd VisualGLM-6B
python web_demo.py
โปรแกรมจะดาวน์โหลดโมเดล sat รันเว็บเซิร์ฟเวอร์และส่งออกที่อยู่โดยอัตโนมัติ เปิดที่อยู่เอาต์พุตในเบราว์เซอร์เพื่อใช้งาน
นอกจากนี้เรายังมีเครื่องมือเอฟเฟกต์เครื่องพิมพ์ดีดเวอร์ชันเว็บที่สืบทอดมาจาก ChatGLM-6B เครื่องมือนี้ใช้โมเดล Huggingface และจะทำงานบนพอร์ต :8080 หลังจากเริ่มต้นระบบ:
python web_demo_hf.py การสาธิตเวอร์ชันเว็บทั้งสองยอมรับพารามิเตอร์บรรทัดคำสั่ง --share เพื่อสร้างลิงก์สาธารณะ gradio และยอมรับ --quant 4 และ --quant 8 เพื่อใช้ 4-bit quantization/8-bit quantization ตามลำดับเพื่อลดการใช้หน่วยความจำวิดีโอ
ขั้นแรก คุณต้องติดตั้งการพึ่งพาเพิ่มเติม pip install fastapi uvicorn จากนั้นรัน api.py ในคลังสินค้า:
python api.py โปรแกรมจะดาวน์โหลดโมเดล sat โดยอัตโนมัติซึ่งใช้งานบนพอร์ตโลคัล 8080 เป็นค่าเริ่มต้นและเรียกผ่านวิธี POST ต่อไปนี้เป็นตัวอย่างของการใช้ curl เพื่อขอ โดยทั่วไป คุณยังสามารถใช้วิธีโค้ดเพื่อดำเนินการ POST ได้
echo " { " image " : " $( base64 path/to/example.jpg ) " , " text " : "描述这张图片" , " history " :[]} " > temp.json
curl -X POST -H " Content-Type: application/json " -d @temp.json http://127.0.0.1:8080ค่าส่งคืนที่ได้รับคือ
{
"response":"这张图片展现了一只可爱的卡通羊驼,它站在一个透明的背景上。这只羊驼长着一张毛茸茸的耳朵和一双大大的眼睛,它的身体是白色的,带有棕色斑点。",
"history":[('描述这张图片', '这张图片展现了一只可爱的卡通羊驼,它站在一个透明的背景上。这只羊驼长着一张毛茸茸的耳朵和一双大大的眼睛,它的身体是白色的,带有棕色斑点。')],
"status":200,
"time":"2023-05-16 20:20:10"
}
นอกจากนี้เรายังมี api_hf.py ที่ใช้โมเดล Huggingface การใช้งานสอดคล้องกับ API ของโมเดล sat:
python api_hf.pyในการใช้งาน Huggingface โมเดลจะโหลดด้วยความแม่นยำ FP16 เป็นค่าเริ่มต้น และการรันโค้ดด้านบนต้องใช้หน่วยความจำวิดีโอประมาณ 15GB หาก GPU ของคุณมีหน่วยความจำจำกัด คุณสามารถลองโหลดโมเดลในโหมดเชิงปริมาณได้ วิธีใช้:
# 按需修改,目前只支持 4/8 bit 量化。下面将只量化ChatGLM,ViT 量化时误差较大
model = AutoModel . from_pretrained ( "THUDM/visualglm-6b" , trust_remote_code = True ). quantize ( 8 ). half (). cuda () ในการใช้งาน sat คุณต้องส่งพารามิเตอร์ก่อนเพื่อเปลี่ยนตำแหน่งการโหลดเป็น cpu จากนั้นจึงดำเนินการหาปริมาณ วิธีการมีดังนี้ ดู cli_demo.py สำหรับรายละเอียด:
from sat . quantization . kernels import quantize
quantize ( model , args . quant ). cuda ()
# 只需要 7GB 显存即可推理โปรเจ็กต์นี้อยู่ในเวอร์ชัน V1 พารามิเตอร์และปริมาณการคำนวณของโมเดลภาพและภาษาค่อนข้างน้อย เราได้สรุปแนวทางการปรับปรุงหลักดังนี้:
รหัสของพื้นที่เก็บข้อมูลนี้เป็นโอเพ่นซอร์สตามข้อตกลง Apache-2.0 การใช้น้ำหนักของโมเดล VisualGLM-6B จำเป็นต้องเป็นไปตาม Model License
หากคุณพบว่างานของเรามีประโยชน์ โปรดพิจารณาอ้างอิงเอกสารต่อไปนี้
@inproceedings{du2022glm,
title={GLM: General Language Model Pretraining with Autoregressive Blank Infilling},
author={Du, Zhengxiao and Qian, Yujie and Liu, Xiao and Ding, Ming and Qiu, Jiezhong and Yang, Zhilin and Tang, Jie},
booktitle={Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)},
pages={320--335},
year={2022}
}
@article{ding2021cogview,
title={Cogview: Mastering text-to-image generation via transformers},
author={Ding, Ming and Yang, Zhuoyi and Hong, Wenyi and Zheng, Wendi and Zhou, Chang and Yin, Da and Lin, Junyang and Zou, Xu and Shao, Zhou and Yang, Hongxia and others},
journal={Advances in Neural Information Processing Systems},
volume={34},
pages={19822--19835},
year={2021}
}
ชุดข้อมูลในขั้นตอนการปรับแต่งคำสั่งของ VisualGLM-6B ประกอบด้วยส่วนหนึ่งของข้อมูลกราฟิกและข้อความภาษาอังกฤษจากโปรเจ็กต์ MiniGPT-4 และ LLAVA รวมถึงชุดข้อมูลการทำงานข้ามโมดัลแบบคลาสสิกหลายชุด เราขอขอบคุณอย่างจริงใจสำหรับข้อมูลเหล่านี้ ผลงาน


