YAYI2
1.0.0

[README] [?HF Repo] [?เวอร์ชันเว็บ]
จีน |. อังกฤษ
[2024.03.28] โมเดลและข้อมูลทั้งหมดถูกอัปโหลดไปยัง Magic Community
[2023.12.22] เราเผยแพร่รายงานทางเทคนิค YAYI 2: โมเดลภาษาขนาดใหญ่แบบโอเพ่นซอร์สหลายภาษา
YAYI 2 คือ โมเดลภาษาโอเพ่นซอร์สขนาดใหญ่รุ่นใหม่ ที่พัฒนาโดย Zhongke Wenge รวมถึงเวอร์ชัน Base และ Chat ด้วยขนาดพารามิเตอร์ 30B YAYI2-30B เป็นโมเดลภาษาขนาดใหญ่ที่ใช้ Transformer ซึ่งใช้คลังข้อมูลหลายภาษาคุณภาพสูงและโทเค็นมากกว่า 2 ล้านล้านโทเค็นสำหรับการฝึกอบรมล่วงหน้า สำหรับสถานการณ์การใช้งานทั่วไปและเฉพาะโดเมน เราใช้คำสั่งหลายล้านคำสั่งสำหรับการปรับแต่งอย่างละเอียด และใช้วิธีการเรียนรู้การเสริมผลตอบรับของมนุษย์เพื่อปรับโมเดลให้สอดคล้องกับคุณค่าของมนุษย์ได้ดีขึ้น
รุ่นโอเพ่นซอร์สในครั้งนี้คือรุ่นฐาน YAYI2-30B เราหวังว่าจะส่งเสริมการพัฒนาชุมชนโอเพ่นซอร์สโมเดลขนาดใหญ่ที่ได้รับการฝึกอบรมล่วงหน้าของจีน ผ่านทางโอเพ่นซอร์สของโมเดลขนาดใหญ่ Yayi และมีส่วนร่วมอย่างแข็งขันในเรื่องนี้ เราทำงานร่วมกับพันธมิตรทุกรายผ่านโอเพ่นซอร์สเพื่อสร้างระบบนิเวศแบบจำลองขนาดใหญ่ของ Yayi
สำหรับรายละเอียดทางเทคนิคเพิ่มเติม โปรดอ่านรายงานทางเทคนิคของเรา YAYI 2: โมเดลภาษาขนาดใหญ่แบบโอเพ่นซอร์สหลายภาษา
| ชื่อชุดข้อมูล | ขนาด | ? การระบุรุ่น HF | ดาวน์โหลดที่อยู่ | โลโก้โมเดลเมจิก | ดาวน์โหลดที่อยู่ |
|---|---|---|---|---|---|
| ข้อมูลพรีเทรน YAYI2 | 500G | wenge-การวิจัย/yayi2_pretrain_data | ดาวน์โหลดชุดข้อมูล | wenge-การวิจัย/yayi2_pretrain_data | ดาวน์โหลดชุดข้อมูล |
| ชื่อรุ่น | ความยาวบริบท | ? การระบุรุ่น HF | ดาวน์โหลดที่อยู่ | โลโก้โมเดลเมจิก | ดาวน์โหลดที่อยู่ |
|---|---|---|---|---|---|
| YAYI2-30B | 4096 | wenge-การวิจัย/yayi2-30b | ดาวน์โหลดโมเดล | wenge-การวิจัย/yayi2-30b | ดาวน์โหลดโมเดล |
| YAYI2-30B-แชท | 4096 | wenge-การวิจัย/yayi2-30b-แชท | เร็วๆ นี้... |
เราทำการประเมินชุดข้อมูลเกณฑ์มาตรฐานหลายชุด รวมถึง C-Eval, MMLU, CMMLU, AGIEval, GAOKAO-Bench, GSM8K, MATH, BBH, HumanEval และ MBPP เราตรวจสอบประสิทธิภาพของแบบจำลองในการทำความเข้าใจภาษา ความรู้ในวิชา การใช้เหตุผลทางคณิตศาสตร์ การใช้เหตุผลเชิงตรรกะ และการสร้างรหัส โมเดล YAYI 2 แสดงให้เห็นถึงการปรับปรุงประสิทธิภาพที่สำคัญเหนือโมเดลโอเพ่นซอร์สที่มีขนาดใกล้เคียงกัน
| ความรู้เรื่อง | คณิตศาสตร์ | การใช้เหตุผลเชิงตรรกะ | รหัส | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| แบบอย่าง | C-Eval(วาล) | มจล | เอจีวัล | ซีเอ็มเอ็มแอลยู | GAOKAO-ม้านั่ง | GSM8K | คณิตศาสตร์ | บีบีเอช | HumanEval | เอ็มบีพีพี |
| 5 ช็อต | 5 ช็อต | 3/0-ช็อต | 5 ช็อต | 0-ช็อต | 8/4-ช็อต | 4 ช็อต | 3 ช็อต | 0-ช็อต | 3 ช็อต | |
| MPT-30B | - | 46.9 | 33.8 | - | - | 15.2 | 3.1 | 38.0 | 25.0 | 32.8 |
| ฟอลคอน-40บี | - | 55.4 | 37.0 | - | - | 19.6 | 5.5 | 37.1 | 0.6 | 29.8 |
| แอลลามา2-34บี | - | 62.6 | 43.4 | - | - | 42.2 | 6.2 | 44.1 | 22.6 | 33.0 |
| ไป๋ชวน2-13B | 59.0 | 59.5 | 37.4 | 61.3 | 45.6 | 52.6 | 10.1 | 49.0 | 17.1 | 30.8 |
| คิวเวน-14B | 71.7 | 67.9 | 51.9 | 70.2 | 62.5 | 61.6 | 25.2 | 53.7 | 32.3 | 39.8 |
| ฝึกงานLM-20B | 58.8 | 62.1 | 44.6 | 59.0 | 45.5 | 52.6 | 7.9 | 52.5 | 25.6 | 35.6 |
| อากีลา2-34B | 98.5 | 76.0 | 43.8 | 78.5 | 37.8 | 50.0 | 17.8 | 42.5 | 0.0 | 41.0 |
| ยี่-34B | 81.8 | 76.3 | 56.5 | 82.6 | 68.3 | 67.6 | 15.9 | 66.4 | 26.2 | 38.2 |
| YAYI2-30B | 80.9 | 80.5 | 62.0 | 84.0 | 64.4 | 71.2 | 14.8 | 54.5 | 53.1 | 45.8 |
เราทำการประเมินโดยใช้ซอร์สโค้ดที่ได้รับจากที่เก็บ OpenCompass Github สำหรับรุ่นเปรียบเทียบ เราจะแสดงรายการผลการประเมินในรายการ OpenCompass ณ วันที่ 15 ธันวาคม 2023 สำหรับรุ่นอื่นๆ ที่ไม่ได้เข้าร่วมในการประเมินบนแพลตฟอร์ม OpenCompass รวมถึง MPT, Falcon และ LLaMa 2 เราได้นำผลลัพธ์ที่รายงานโดย LLaMA 2 มาใช้
เรามีตัวอย่างง่ายๆ เพื่อแสดงวิธีใช้ YAYI2-30B สำหรับการอนุมานอย่างรวดเร็ว ตัวอย่างนี้สามารถรันบน A100/A800 เครื่องเดียวได้
git clone https://github.com/wenge-research/YAYI2.git
cd YAYI2conda create --name yayi_inference_env python=3.8
conda activate yayi_inference_envโปรดทราบว่าโปรเจ็กต์นี้ต้องใช้ Python 3.8 หรือสูงกว่า
pip install transformers==4.33.1
pip install torch==2.0.1
pip install sentencepiece==0.1.99
pip install accelerate==0.25.0
>> > from transformers import AutoModelForCausalLM , AutoTokenizer
>> > tokenizer = AutoTokenizer . from_pretrained ( "wenge-research/yayi2-30b" , trust_remote_code = True )
>> > model = AutoModelForCausalLM . from_pretrained ( "wenge-research/yayi2-30b" , device_map = "auto" , trust_remote_code = True )
>> > inputs = tokenizer ( 'The winter in Beijing is' , return_tensors = 'pt' )
>> > inputs = inputs . to ( 'cuda' )
>> > pred = model . generate (
** inputs ,
max_new_tokens = 256 ,
eos_token_id = tokenizer . eos_token_id ,
do_sample = True ,
repetition_penalty = 1.2 ,
temperature = 0.4 ,
top_k = 100 ,
top_p = 0.8
)
>> > print ( tokenizer . decode ( pred . cpu ()[ 0 ], skip_special_tokens = True ))เมื่อคุณเยี่ยมชมเป็นครั้งแรก จะต้องดาวน์โหลดและโหลดแบบจำลองซึ่งอาจใช้เวลาสักครู่
โปรเจ็กต์นี้รองรับการปรับแต่งคำสั่งโดยละเอียดตามเฟรมเวิร์กการฝึกอบรมแบบกระจาย กำหนดค่าสภาพแวดล้อมและรันสคริปต์ที่เกี่ยวข้องเพื่อเริ่มการปรับแต่งแบบเต็มพารามิเตอร์หรือการปรับแต่ง LoRA
conda create --name yayi_train_env python=3.10
conda activate yayi_train_envpip install -r requirements.txtpip install --upgrade acceleratepip install flash-attn==2.0.3 --no-build-isolation
pip install triton==2.0.0.dev20221202 --no-deps รูปแบบข้อมูล: อ้างอิงถึง data/yayi_train_example.json ซึ่งเป็นไฟล์ JSON มาตรฐาน ข้อมูลแต่ละชิ้นประกอบด้วย "system" และ "conversations" โดยที่ "system" คือข้อมูลการตั้งค่าบทบาทส่วนกลางและสามารถเป็นสตริงว่างได้ "conversations" คือบทสนทนาหลายรอบระหว่างตัวละครมนุษย์และตัวละครยายี่
คำแนะนำการใช้งาน: เรียกใช้คำสั่งต่อไปนี้เพื่อเริ่มการปรับแต่งแบบเต็มพารามิเตอร์ของรุ่น Yayi คำสั่งนี้รองรับการฝึกอบรมหลายเครื่องและหลายการ์ด ขอแนะนำให้ใช้การกำหนดค่าฮาร์ดแวร์ 16*A100 หรือสูงกว่า
deepspeed --hostfile config/hostfile
--module training.trainer_yayi2
--report_to " tensorboard "
--data_path " ./data/yayi_train_example.json "
--model_name_or_path " your_model_path "
--output_dir " ./output "
--model_max_length 2048
--num_train_epochs 1
--per_device_train_batch_size 1
--gradient_accumulation_steps 1
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 500
--save_total_limit 10
--learning_rate 5e-6
--warmup_steps 2000
--lr_scheduler_type cosine
--logging_steps 1
--gradient_checkpointing True
--deepspeed " ./config/deepspeed.json "
--bf16 True หรือเริ่มผ่านทางบรรทัดคำสั่ง:
bash scripts/start.sh โปรดทราบว่าหากคุณต้องการใช้เทมเพลต ChatML เพื่อปรับแต่งคำแนะนำ คุณสามารถเปลี่ยน --module training.trainer_yayi2 ในคำสั่งเป็น --module training.trainer_chatml ได้ หากคุณต้องการปรับแต่งเทมเพลต Chat คุณสามารถแก้ไขได้ ระบบในเทมเพลต Chat ของ trainer_chatml.py คำจำกัดความโทเค็นพิเศษสำหรับบทบาททั้งสามของ ผู้ใช้ และผู้ช่วย ต่อไปนี้เป็นตัวอย่างของเทมเพลต ChatML หากใช้เทมเพลตนี้หรือเทมเพลตแบบกำหนดเองระหว่างการฝึก เทมเพลตนั้นจะต้องสอดคล้องกันในระหว่างการอนุมานด้วย
<|im_start|>system
You are a helpful and harmless assistant named YAYI.<|im_end|>
<|im_start|>user
Hello!<|im_end|>
<|im_start|>assistant
Hello! How can I assist you today?<|im_end|>
<|im_start|>user
1+1=<|im_end|>
<|im_start|>assistant
1+1 equals 2.<|im_end|>
bash scripts/start_lora.sh ในขั้นตอนก่อนการฝึกอบรม เราไม่เพียงแต่ใช้ข้อมูลอินเทอร์เน็ตเพื่อฝึกความสามารถด้านภาษาของโมเดล แต่ยังเพิ่มข้อมูลทั่วไปที่เลือกและข้อมูลโดเมนเพื่อพัฒนาทักษะทางวิชาชีพของโมเดลอีกด้วย การกระจายข้อมูลมีดังนี้: 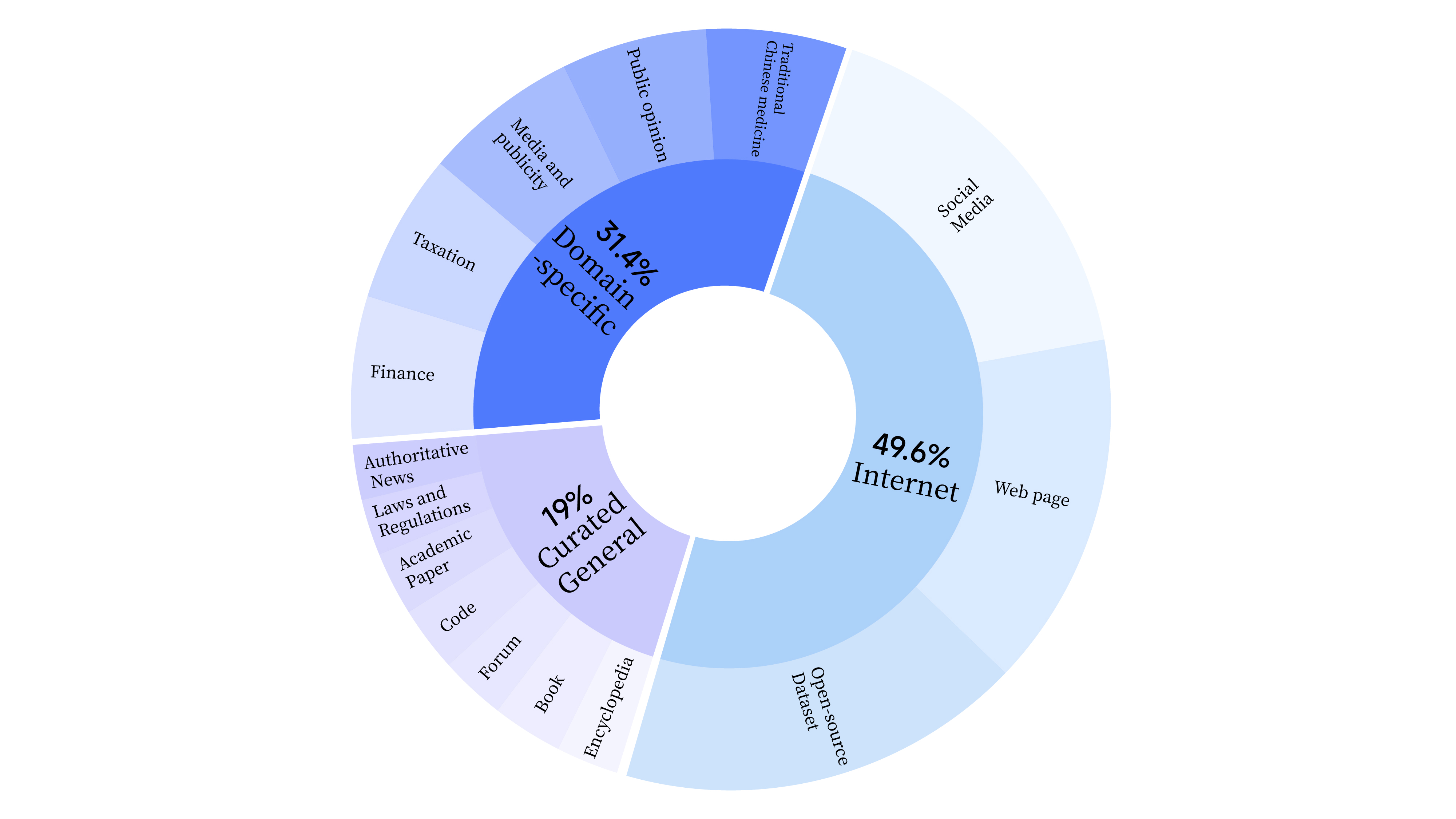
เราได้สร้างชุดไปป์ไลน์การประมวลผลข้อมูลเพื่อปรับปรุงคุณภาพข้อมูลในทุกด้าน รวมถึงสี่โมดูล: การกำหนดมาตรฐาน การทำความสะอาดแบบศึกษาสำนึก การขจัดข้อมูลซ้ำซ้อนหลายระดับ และการกรองความเป็นพิษ เรารวบรวมข้อมูลดิบทั้งหมด 240TB และยังมีข้อมูลคุณภาพสูงเพียง 10.6TB เท่านั้นหลังจากการประมวลผลล่วงหน้า กระบวนการโดยรวมมีดังนี้: 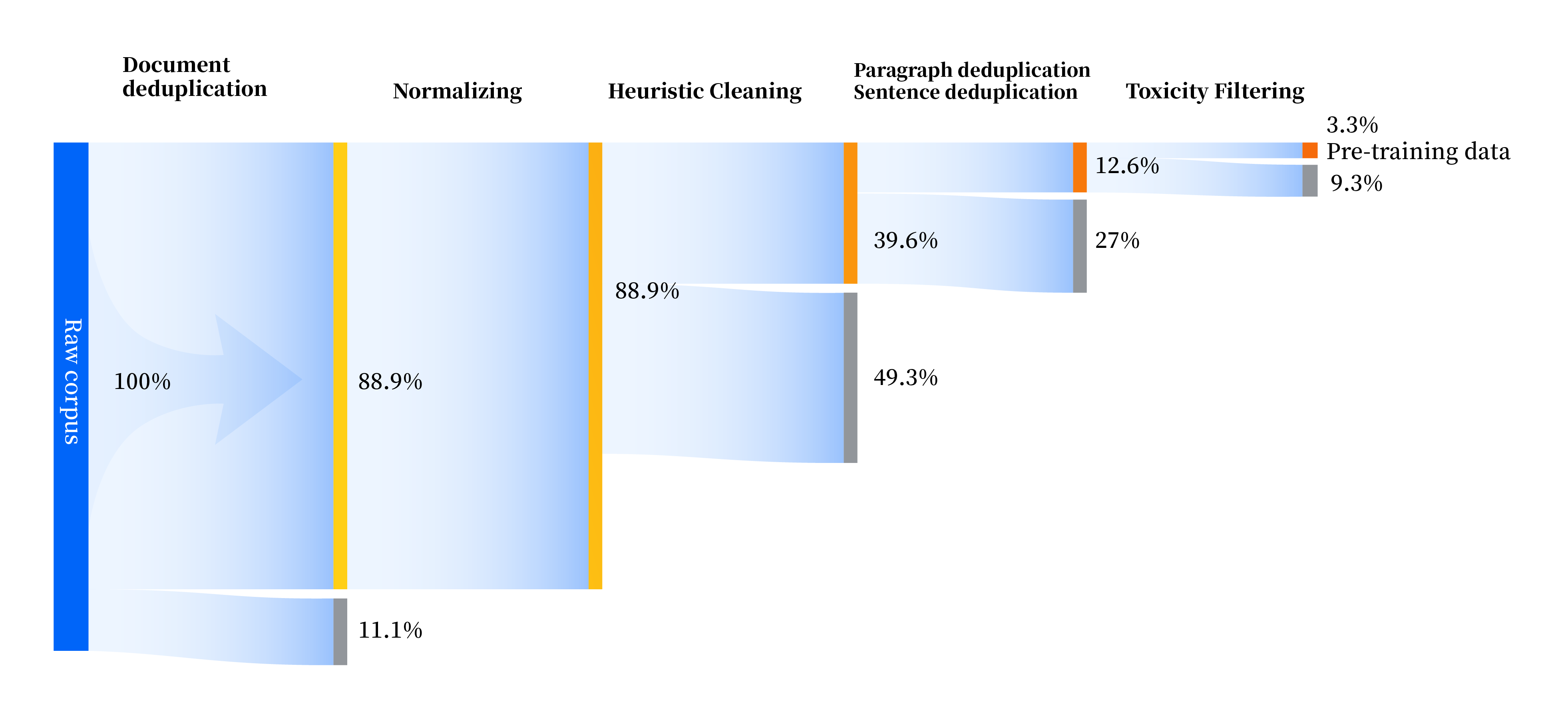

เส้นโค้งการสูญเสียของรุ่น YAYI 2 แสดงในรูปด้านล่าง: 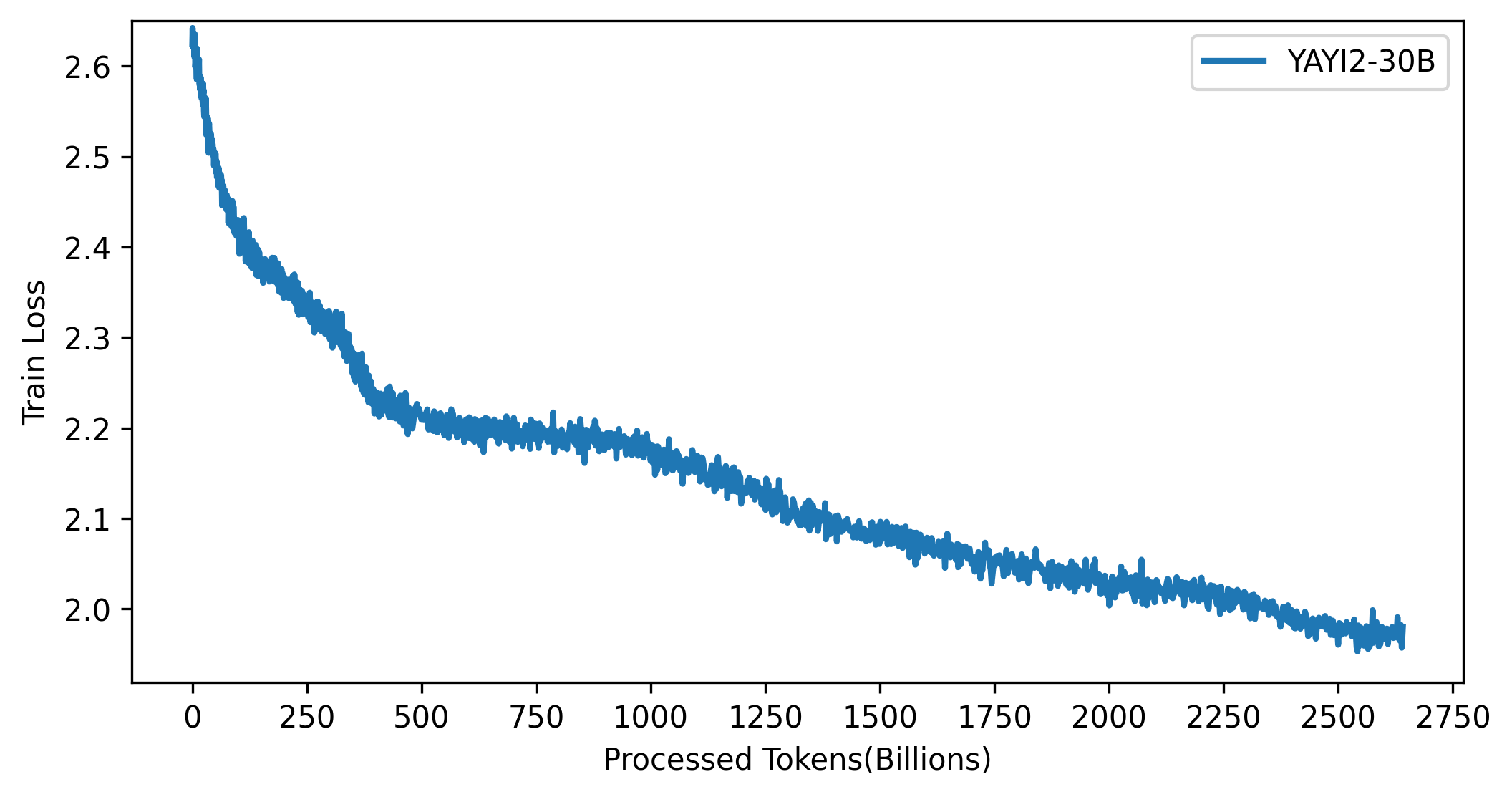
รหัสในโครงการนี้เป็นโอเพ่นซอร์สตามโปรโตคอล Apache-2.0 การใช้โมเดล YAYI 2 และข้อมูลของชุมชนต้องเป็นไปตาม "ข้อตกลงสิทธิ์การใช้งานชุมชนโมเดล Yayi YAYI 2" หากคุณต้องการใช้รุ่น YAYI 2 series หรืออนุพันธ์เพื่อวัตถุประสงค์ทางการค้า โปรดกรอก "ข้อมูลการจดทะเบียนพาณิชย์รุ่น YAYI 2" และส่งไปที่ [email protected] เราจะติดต่อคุณภายใน 3 วันทำการหลังจากได้รับอีเมล การตรวจสอบจะดำเนินการเป็นประจำทุกวัน หลังจากผ่านการตรวจสอบ คุณจะได้รับใบอนุญาตเชิงพาณิชย์ โปรดปฏิบัติตามเนื้อหาที่เกี่ยวข้องของ "ข้อตกลงใบอนุญาตเชิงพาณิชย์รุ่น YAYI 2" อย่างเคร่งครัด
หากคุณใช้แบบจำลองของเราในการทำงานของคุณ โปรดอ้างอิงรายงานของเรา:
@article{YAYI 2,
author = {Yin Luo, Qingchao Kong, Nan Xu, et.al.},
title = {YAYI 2: Multilingual Open Source Large Language Models},
journal = {arXiv preprint arXiv:2312.14862},
url = {https://arxiv.org/abs/2312.14862},
year = {2023}
}


