Copulas
v0.12.0 - 2024-11-12
พื้นที่เก็บข้อมูลนี้เป็นส่วนหนึ่งของโครงการ Synthetic Data Vault ซึ่งเป็นโครงการจาก DataCebo

Copulas เป็นไลบรารี Python สำหรับการสร้างแบบจำลองการแจกแจงหลายตัวแปรและการสุ่มตัวอย่างโดยใช้ฟังก์ชัน copula เมื่อใช้ตารางข้อมูลตัวเลข ให้ใช้ Copulas เพื่อเรียนรู้การแจกแจงและสร้างข้อมูลสังเคราะห์ใหม่ตามคุณสมบัติทางสถิติเดียวกัน
คุณสมบัติที่สำคัญ:
สร้างแบบจำลองข้อมูลหลายตัวแปร เลือกจากการแจกแจงแบบตัวแปรเดียวและโคพูลัสที่หลากหลาย รวมถึงอาร์คิมีเดียนโคพูลัส เกาส์เซียนโคพูลัส และโคพูลัสเถาวัลย์
เปรียบเทียบข้อมูลจริงและข้อมูลสังเคราะห์ด้วยภาพ หลังจากสร้างแบบจำลองของคุณ การแสดงภาพมีให้เลือกใช้ในรูปแบบฮิสโตแกรม 1 มิติ แผนภาพกระจาย 2 มิติ และแผนภาพกระจาย 3 มิติ
เข้าถึงและจัดการพารามิเตอร์ที่เรียนรู้ ด้วยการเข้าถึงภายในของโมเดลโดยสมบูรณ์ คุณสามารถตั้งค่าหรือปรับแต่งพารามิเตอร์ตามที่คุณต้องการได้
ติดตั้งไลบรารี Copulas โดยใช้ pip หรือ conda
pip install copulasconda install -c conda-forge copulasเริ่มต้นใช้งานชุดข้อมูลสาธิต ชุดข้อมูลนี้มีคอลัมน์ตัวเลข 3 คอลัมน์
from copulas . datasets import sample_trivariate_xyz
real_data = sample_trivariate_xyz ()
real_data . head ()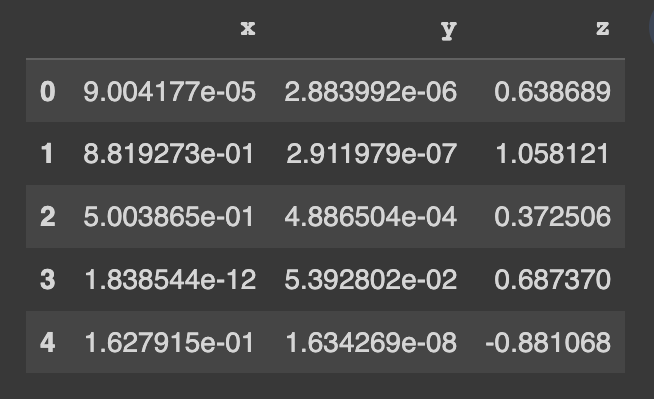
สร้างโมเดลข้อมูลโดยใช้โคปูลา และใช้เพื่อสร้างข้อมูลสังเคราะห์ ห้องสมุด Copulas มีตัวเลือกมากมาย รวมถึง Gaussian Copula, Vine Copulas และ Archimedian Copulas
from copulas . multivariate import GaussianMultivariate
copula = GaussianMultivariate ()
copula . fit ( real_data )
synthetic_data = copula . sample ( len ( real_data ))แสดงภาพข้อมูลจริงและข้อมูลสังเคราะห์ควบคู่กัน มาทำสิ่งนี้ในแบบ 3 มิติเพื่อดูชุดข้อมูลทั้งหมดของเรา
from copulas . visualization import compare_3d
compare_3d ( real_data , synthetic_data )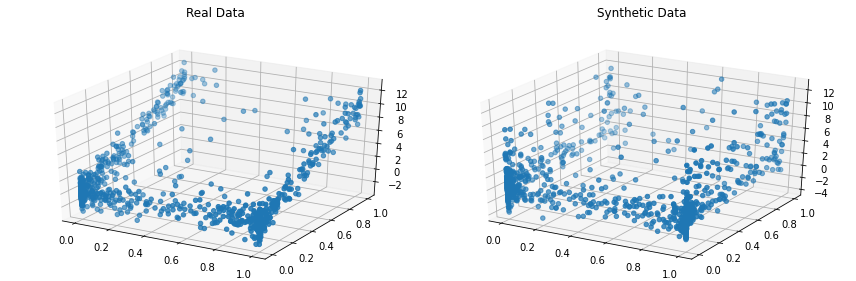
คลิกด้านล่างเพื่อเรียกใช้โค้ดด้วยตนเองบน Colab Notebook และค้นพบฟีเจอร์ใหม่ๆ
เรียนรู้เพิ่มเติมเกี่ยวกับห้องสมุด Copulas จากไซต์เอกสารของเรา
คำถามหรือประเด็น? เข้าร่วมช่อง Slack ของเราเพื่อหารือเพิ่มเติมเกี่ยวกับ Copulas และข้อมูลสังเคราะห์ หากคุณพบจุดบกพร่องหรือมีคำขอคุณสมบัติ คุณสามารถเปิดปัญหาบน GitHub ของเราได้
สนใจที่จะมีส่วนร่วมใน Copulas หรือไม่? อ่านคู่มือการมีส่วนร่วมของเราเพื่อเริ่มต้น
โครงการโอเพ่นซอร์ส Copulas เริ่มต้นครั้งแรกที่ Data to AI Lab ที่ MIT ในปี 2018 ขอขอบคุณทีมงานผู้ร่วมให้ข้อมูลของเราที่สร้างและดูแลรักษาห้องสมุดตลอดหลายปีที่ผ่านมา!
ดูผู้มีส่วนร่วม

โครงการ Synthetic Data Vault ถูกสร้างขึ้นครั้งแรกที่ Data to AI Lab ของ MIT ในปี 2559 หลังจาก 4 ปีของการวิจัยและความร่วมมือกับองค์กร เราได้สร้าง DataCebo ในปี 2020 โดยมีเป้าหมายในการขยายโครงการ ปัจจุบัน DataCebo เป็นผู้พัฒนา SDV ซึ่งเป็นระบบนิเวศที่ใหญ่ที่สุดสำหรับการสร้างและประเมินข้อมูลสังเคราะห์ เป็นที่ตั้งของไลบรารีหลายแห่งที่รองรับข้อมูลสังเคราะห์ รวมถึง:
เริ่มต้นใช้งานแพ็คเกจ SDV ซึ่งเป็นโซลูชันแบบครบวงจรและแหล่งรวมข้อมูลสังเคราะห์ในที่เดียว หรือใช้ไลบรารีแบบสแตนด์อโลนสำหรับความต้องการเฉพาะ


