airllm
1.0.0

เริ่มต้นอย่างรวดเร็ว | การกำหนดค่า | MacOS | ตัวอย่างสมุดบันทึก | คำถามที่พบบ่อย
AirLLM ปรับการใช้งานหน่วยความจำอนุมานให้เหมาะสม ทำให้โมเดลภาษาขนาดใหญ่ 70B สามารถรันการอนุมานบนการ์ด GPU ขนาด 4GB ใบเดียว โดยไม่ต้องหาปริมาณ การกลั่น และการตัด และคุณสามารถรัน 405B Llama3.1 บน vram 8GB ได้แล้วตอนนี้
[20/08/2024] v2.11.0: รองรับ Qwen2.5
[2024/08/18] v2.10.1 รองรับการอนุมาน CPU รองรับโมเดลที่ไม่แบ่งส่วน ขอบคุณ @NavodPeiris สำหรับการทำงานที่ยอดเยี่ยม!
[2024/07/30] รองรับ Llama3.1 405B (ตัวอย่างโน้ตบุ๊ก) รองรับ การหาปริมาณ 8 บิต/4 บิต
[2024/04/20] AirLLM รองรับ Llama3 โดยกำเนิดแล้ว เรียกใช้ Llama3 70B บน GPU ตัวเดียวขนาด 4GB
[25/12/2566] v2.8.2: รองรับ MacOS ที่ใช้โมเดลภาษาขนาดใหญ่ 70B
[20/12/2566] v2.7: รองรับ AirLLMMixtral
[20/12/2566] v2.6: เพิ่ม AutoModel ตรวจจับประเภทโมเดลโดยอัตโนมัติ ไม่จำเป็นต้องจัดเตรียมคลาสโมเดลเพื่อเริ่มต้นโมเดล
[12/2023/18] v2.5: เพิ่มการดึงข้อมูลล่วงหน้าเพื่อทับซ้อนกับการโหลดโมเดลและการคำนวณ การปรับปรุงความเร็ว 10%
[2023/12/03] เพิ่มการรองรับ ChatGLM , QWen , Baichuan , Mistral , InternLM !
[2023/12/02] เพิ่มการรองรับสำหรับตัวป้องกัน ตอนนี้สนับสนุนโมเดล 10 อันดับแรกทั้งหมดในลีดเดอร์บอร์ด llm แบบเปิด
[2023/12/01] airllm 2.0. รองรับการบีบอัด: ความเร็วรันไทม์เพิ่มขึ้น 3 เท่า!
[2023/11/20] airllm เวอร์ชันเริ่มต้น!
ขั้นแรก ติดตั้งแพ็คเกจ airllm pip
pip install airllmจากนั้น เริ่มต้น AirLLMLlama2 ส่งรหัส repo ID ของโมเดลที่ใช้งานอยู่ หรือเส้นทางในเครื่อง และการอนุมานสามารถทำได้คล้ายกับโมเดลหม้อแปลงทั่วไป
( คุณยังสามารถระบุเส้นทางเพื่อบันทึกโมเดลแบบแบ่งเลเยอร์ที่แยกผ่าน layer_shards_saving_path เมื่อเริ่มต้น AirLLMLlama2
from airllm import AutoModel
MAX_LENGTH = 128
# could use hugging face model repo id:
model = AutoModel . from_pretrained ( "garage-bAInd/Platypus2-70B-instruct" )
# or use model's local path...
#model = AutoModel.from_pretrained("/home/ubuntu/.cache/huggingface/hub/models--garage-bAInd--Platypus2-70B-instruct/snapshots/b585e74bcaae02e52665d9ac6d23f4d0dbc81a0f")
input_text = [
'What is the capital of United States?' ,
#'I like',
]
input_tokens = model . tokenizer ( input_text ,
return_tensors = "pt" ,
return_attention_mask = False ,
truncation = True ,
max_length = MAX_LENGTH ,
padding = False )
generation_output = model . generate (
input_tokens [ 'input_ids' ]. cuda (),
max_new_tokens = 20 ,
use_cache = True ,
return_dict_in_generate = True )
output = model . tokenizer . decode ( generation_output . sequences [ 0 ])
print ( output )หมายเหตุ: ในระหว่างการอนุมาน โมเดลดั้งเดิมจะถูกแยกย่อยและบันทึกเป็นเลเยอร์ก่อน โปรดตรวจสอบให้แน่ใจว่ามีพื้นที่ดิสก์เพียงพอในไดเร็กทอรีแคชของ Huggingface
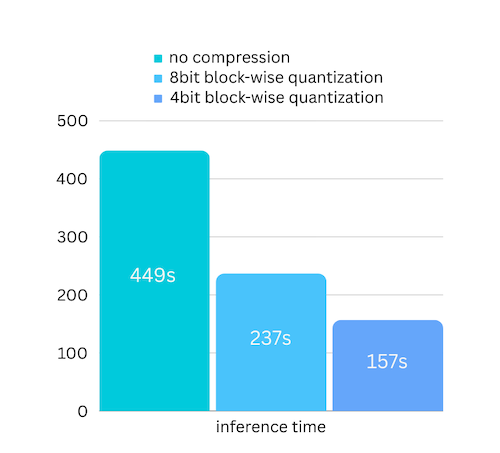
เราเพิ่งเพิ่มการบีบอัดโมเดลตามการบีบอัดโมเดลตามปริมาณเชิงปริมาณแบบบล็อก ซึ่งสามารถ เพิ่มความเร็วในการอนุมานได้ สูงสุดถึง 3 เท่า โดย สูญเสียความแม่นยำไปจนแทบจะมองข้ามไป! (ดูการประเมินประสิทธิภาพเพิ่มเติม และเหตุใดเราจึงใช้การวัดปริมาณแบบบล็อกในบทความนี้)
pip install -U bitsandbytespip install -U airllm model = AutoModel . from_pretrained ( "garage-bAInd/Platypus2-70B-instruct" ,
compression = '4bit' # specify '8bit' for 8-bit block-wise quantization
)โดยปกติการหาปริมาณจะต้องวัดปริมาณทั้งน้ำหนักและการเปิดใช้งานเพื่อเร่งความเร็วให้เร็วขึ้น ซึ่งทำให้ยากต่อการรักษาความถูกต้องและหลีกเลี่ยงผลกระทบของค่าผิดปกติในอินพุตทุกประเภท
แม้ว่าในกรณีของเรา คอขวดส่วนใหญ่จะอยู่ที่การโหลดดิสก์ เราเพียงแต่ต้องทำให้ขนาดการโหลดโมเดลเล็กลงเท่านั้น ดังนั้นเราจึงต้องวัดปริมาณเฉพาะส่วนของตุ้มน้ำหนักเท่านั้น ซึ่งง่ายกว่าที่จะรับประกันความถูกต้องแม่นยำ
เมื่อเริ่มต้นโมเดล เรารองรับการกำหนดค่าต่อไปนี้:
เพียงติดตั้ง airllm และรันโค้ดเหมือนกับบน linux ดูเพิ่มเติมในการเริ่มต้นอย่างรวดเร็ว
ตัวอย่าง [สมุดบันทึกหลาม] (https://github.com/lyogavin/airllm/blob/main/air_llm/examples/run_on_macos.ipynb)
ตัวอย่าง Colab ที่นี่:
from airllm import AutoModel
MAX_LENGTH = 128
model = AutoModel . from_pretrained ( "THUDM/chatglm3-6b-base" )
input_text = [ 'What is the capital of China?' ,]
input_tokens = model . tokenizer ( input_text ,
return_tensors = "pt" ,
return_attention_mask = False ,
truncation = True ,
max_length = MAX_LENGTH ,
padding = True )
generation_output = model . generate (
input_tokens [ 'input_ids' ]. cuda (),
max_new_tokens = 5 ,
use_cache = True ,
return_dict_in_generate = True )
model . tokenizer . decode ( generation_output . sequences [ 0 ]) from airllm import AutoModel
MAX_LENGTH = 128
model = AutoModel . from_pretrained ( "Qwen/Qwen-7B" )
input_text = [ 'What is the capital of China?' ,]
input_tokens = model . tokenizer ( input_text ,
return_tensors = "pt" ,
return_attention_mask = False ,
truncation = True ,
max_length = MAX_LENGTH )
generation_output = model . generate (
input_tokens [ 'input_ids' ]. cuda (),
max_new_tokens = 5 ,
use_cache = True ,
return_dict_in_generate = True )
model . tokenizer . decode ( generation_output . sequences [ 0 ]) from airllm import AutoModel
MAX_LENGTH = 128
model = AutoModel . from_pretrained ( "baichuan-inc/Baichuan2-7B-Base" )
#model = AutoModel.from_pretrained("internlm/internlm-20b")
#model = AutoModel.from_pretrained("mistralai/Mistral-7B-Instruct-v0.1")
input_text = [ 'What is the capital of China?' ,]
input_tokens = model . tokenizer ( input_text ,
return_tensors = "pt" ,
return_attention_mask = False ,
truncation = True ,
max_length = MAX_LENGTH )
generation_output = model . generate (
input_tokens [ 'input_ids' ]. cuda (),
max_new_tokens = 5 ,
use_cache = True ,
return_dict_in_generate = True )
model . tokenizer . decode ( generation_output . sequences [ 0 ])โค้ดจำนวนมากอิงจากผลงานที่ยอดเยี่ยมของ SimJeg ในการแข่งขันสอบ Kaggle ตะโกนสุดเสียงถึง SimJeg:
บัญชี GitHub @SimJeg รหัสบน Kaggle การสนทนาที่เกี่ยวข้อง
safetensors_rust.SafetensorError: เกิดข้อผิดพลาดขณะทำการดีซีเรียลไลซ์ส่วนหัว: MetadataIncompleteBuffer
หากคุณพบข้อผิดพลาดนี้ สาเหตุส่วนใหญ่ที่เป็นไปได้คือพื้นที่ดิสก์ของคุณไม่เพียงพอ กระบวนการแยกโมเดลใช้ดิสก์มาก ดูสิ่งนี้ คุณอาจต้องขยายพื้นที่ดิสก์ ล้าง .cache ของ Huggingface แล้วรันใหม่
เป็นไปได้มากว่าคุณกำลังโหลดโมเดล QWen หรือ ChatGLM พร้อมคลาส Llama2 ลองดังต่อไปนี้:
สำหรับรุ่น QWen:
from airllm import AutoModel #<----- instead of AirLLMLlama2
AutoModel . from_pretrained (...)สำหรับรุ่น ChatGLM:
from airllm import AutoModel #<----- instead of AirLLMLlama2
AutoModel . from_pretrained (...)บางรุ่นเป็นรุ่นที่มีรั้วรอบขอบชิด ต้องใช้โทเค็น API แบบกอด คุณสามารถระบุ hf_token:
model = AutoModel . from_pretrained ( "meta-llama/Llama-2-7b-hf" , #hf_token='HF_API_TOKEN')โทเค็นไนเซอร์ของบางรุ่นไม่มีโทเค็นการเติม ดังนั้นคุณจึงสามารถตั้งค่าโทเค็นการเติมหรือเพียงแค่ปิดการกำหนดค่าการเติม:
input_tokens = model . tokenizer ( input_text ,
return_tensors = "pt" ,
return_attention_mask = False ,
truncation = True ,
max_length = MAX_LENGTH ,
padding = False #<----------- turn off padding
)หากคุณพบว่า AirLLM มีประโยชน์ในการวิจัยของคุณและต้องการอ้างอิง โปรดใช้รายการ BibTex ต่อไปนี้:
@software{airllm2023,
author = {Gavin Li},
title = {AirLLM: scaling large language models on low-end commodity computers},
url = {https://github.com/lyogavin/airllm/},
version = {0.0},
year = {2023},
}
ยินดีกับการมีส่วนร่วม แนวคิด และการอภิปราย!
หากคุณพบว่ามีประโยชน์ กรุณาหรือซื้อกาแฟให้ฉันหน่อย!



