WilmerAI
1.0.0
นี่เป็นโครงการส่วนตัวที่อยู่ระหว่างการพัฒนาอย่างหนัก อาจมีข้อบกพร่อง รหัสที่ไม่สมบูรณ์ หรือปัญหาอื่นๆ ที่ไม่ได้ตั้งใจ ด้วยเหตุนี้ ซอฟต์แวร์จึงมีให้ตามที่เป็นอยู่ โดยไม่มีการรับประกันใดๆ
WilmerAI สะท้อนให้เห็นถึงงานของนักพัฒนารายเดียวและความพยายามในเวลาและทรัพยากรส่วนตัวของเขา มุมมอง วิธีการ ฯลฯ ใด ๆ ที่พบในนั้นเป็นของเขาเองและไม่ควรสะท้อนถึงนายจ้างของเขา
WilmerAI เป็นระบบมิดเดิลแวร์ที่ซับซ้อนซึ่งออกแบบมาเพื่อรับข้อความแจ้งที่เข้ามาและดำเนินการต่างๆ กับข้อความเหล่านั้นก่อนที่จะส่งไปยัง LLM API งานนี้รวมถึงการใช้ Large Language Model (LLM) เพื่อจัดหมวดหมู่พรอมต์และกำหนดเส้นทางไปยังเวิร์กโฟลว์ที่เหมาะสมหรือการประมวลผลบริบทขนาดใหญ่ (โทเค็นมากกว่า 200,000 รายการ) เพื่อสร้างพรอมต์ที่เล็กลงและจัดการได้ง่ายกว่าซึ่งเหมาะสำหรับโมเดลท้องถิ่นส่วนใหญ่
WilmerAI ย่อมาจาก "จะเกิดอะไรขึ้นถ้าโมเดลภาษากำหนดเส้นทางการอนุมานทั้งหมดอย่างเชี่ยวชาญ"
ผู้ช่วยขับเคลื่อนโดย LLM หลายตัวควบคู่กัน : ข้อความแจ้งขาเข้าสามารถกำหนดเส้นทางไปยัง "หมวดหมู่" โดยแต่ละหมวดหมู่ขับเคลื่อนโดยเวิร์กโฟลว์ แต่ละเวิร์กโฟลว์สามารถมีโหนดได้มากเท่าที่คุณต้องการ โดยแต่ละโหนดขับเคลื่อนโดย LLM ที่แตกต่างกัน ตัวอย่างเช่น หากคุณถามผู้ช่วยของคุณว่า "คุณช่วยเขียนเกม Snake ให้ฉันด้วยภาษาไพธอนได้ไหม" นั่นอาจจัดอยู่ในประเภท CODING และไปที่เวิร์กโฟลว์การเขียนโค้ดของคุณ โหนดแรกของเวิร์กโฟลว์นั้นอาจขอให้ Codestral-22b (หรือ ChatGPT 4o หากคุณต้องการ) ตอบคำถาม โหนดที่สองอาจขอให้ Deepseek V2 หรือ Claude Sonnet ตรวจสอบโค้ด โหนดถัดไปอาจขอให้ Codestral มอบครั้งสุดท้ายอีกครั้งแล้วตอบกลับคุณ ไม่ว่าเวิร์กโฟลว์ของคุณจะเป็นเพียงโมเดลเดียวที่ตอบสนองเนื่องจากเป็นโค้ดเดอร์ที่ดีที่สุดของคุณ หรือไม่ว่าจะเป็นโหนดต่างๆ ของ LLM ต่างๆ ที่ทำงานร่วมกันเพื่อสร้างการตอบสนอง คุณก็เลือกได้
การสนับสนุนสำหรับ Wikipedia API ออฟไลน์ : WilmerAI มีโหนดที่สามารถเรียกไปยัง OfflineWikipediaTextApi ซึ่งหมายความว่า คุณสามารถมีหมวดหมู่ได้ เช่น "ข้อเท็จจริง" ที่จะดูข้อความขาเข้าของคุณ สร้างการสืบค้นจากนั้น สืบค้น Wikipedia API สำหรับบทความที่เกี่ยวข้อง และใช้บทความนั้นเป็นการแทรกบริบท RAG เพื่อตอบกลับ
สรุปการแชทที่สร้างขึ้นอย่างต่อเนื่องเพื่อจำลอง "หน่วยความจำ" : โหนดสรุปการแชทจะสร้าง "ความทรงจำ" โดยการแยกข้อความของคุณเป็นก้อนแล้วสรุปและบันทึกลงในไฟล์ จากนั้นจะนำส่วนที่สรุปเหล่านั้นมาและสร้างการสรุปการสนทนาทั้งหมดอย่างต่อเนื่องและอัปเดตอย่างต่อเนื่อง ซึ่งสามารถดึงและใช้งานได้ภายในการแจ้งเตือนไปยัง LLM ผลลัพธ์ช่วยให้คุณสามารถสนทนาตามบริบทได้มากกว่า 200,000 รายการ และติดตามสิ่งที่พูดไปแล้วได้ แม้ว่าจะจำกัดข้อความเตือนสำหรับ LLM ไว้ที่บริบท 5,000 หรือน้อยกว่าก็ตาม
ใช้คอมพิวเตอร์หลายเครื่องเพื่อประมวลผลความทรงจำและการตอบสนองแบบขนาน : หากคุณมีคอมพิวเตอร์ 2 เครื่องที่สามารถเรียกใช้ LLM ได้ คุณสามารถกำหนดให้เครื่องหนึ่งเป็น "ผู้ตอบกลับ" และอีกเครื่องหนึ่งรับผิดชอบในการสร้างความทรงจำ/สรุป เวิร์กโฟลว์ประเภทนี้ช่วยให้คุณพูดคุยกับ LLM ของคุณต่อไปได้ในขณะที่ความทรงจำ/ข้อมูลสรุปกำลังได้รับการอัปเดต ในขณะที่ยังคงใช้ความทรงจำที่มีอยู่ ซึ่งหมายความว่าไม่จำเป็นต้องรอให้สรุปอัปเดตเลย แม้ว่าคุณจะมอบหมายโมเดลขนาดใหญ่และทรงพลังเพื่อจัดการงานนั้นเพื่อให้คุณมีความทรงจำที่มีคุณภาพสูงขึ้นก็ตาม (ดูตัวอย่างผู้ใช้ convo-role-dual-model )
การแชทกลุ่ม LLM หลายกลุ่มใน SillyTavern: คุณสามารถใช้ Wilmer เพื่อแชทกลุ่มใน ST โดยที่ตัวละครทุกตัวเป็น LLM ที่แตกต่างกัน หากคุณต้องการ (ผู้เขียนทำสิ่งนี้เป็นการส่วนตัว) มีตัวอย่างตัวละครที่มีอยู่ใน DocsSillyTavern แบ่งออกเป็นสองกลุ่ม อักขระ/กลุ่มตัวอย่างเหล่านี้เป็นชุดย่อยของกลุ่มขนาดใหญ่ที่ผู้เขียนใช้
ฟังก์ชันการทำงานของมิดเดิลแวร์: WilmerAI อยู่ระหว่างอินเทอร์เฟซที่คุณใช้ในการสื่อสารกับ LLM (เช่น SillyTavern, OpenWebUI หรือแม้แต่เทอร์มินัลของโปรแกรม Python) และ API แบ็กเอนด์ที่ให้บริการ LLM สามารถจัดการ LLM แบ็กเอนด์หลายรายการพร้อมกันได้
การใช้ LLM หลายรายการพร้อมกัน: ตัวอย่างการตั้งค่า: SillyTavern -> WilmerAI -> KoboldCpp หลายอินสแตนซ์ ตัวอย่างเช่น Wilmer สามารถเชื่อมต่อกับ Command-R 35b, Codestral 22b, Gemma-2-27b และใช้สิ่งเหล่านี้ทั้งหมดในการตอบกลับไปยังผู้ใช้ ตราบใดที่ LLM ที่คุณเลือกถูกเปิดเผยผ่านจุดสิ้นสุด v1/Completion หรือแชท/Completion หรือจุดสิ้นสุด Generate ของ KoboldCpp คุณก็สามารถใช้งานได้
ค่าที่ตั้งล่วงหน้าที่ปรับแต่งได้ : ค่าที่ตั้งไว้ล่วงหน้าจะถูกบันทึกไว้ในไฟล์ json ที่คุณสามารถปรับแต่งได้อย่างง่ายดาย เกือบทุกค่าที่ตั้งล่วงหน้าสามารถจัดการผ่าน json รวมถึงชื่อพารามิเตอร์ด้วย ซึ่งหมายความว่าคุณไม่จำเป็นต้องรอการอัปเดตของ Wilmer เพื่อใช้ประโยชน์จากสิ่งใหม่ ตัวอย่างเช่น DRY เพิ่งเปิดตัวบน KoboldCpp หากนั่นไม่ได้อยู่ใน json ที่ตั้งไว้ล่วงหน้าสำหรับ Wilmer คุณควรจะสามารถเพิ่มมันและเริ่มใช้งานได้
ตำแหน่งข้อมูล API: มีตำแหน่งข้อมูล chat/Completions ที่เข้ากันได้กับ OpenAI API และตำแหน่งข้อมูล v1/Completions เพื่อเชื่อมต่อผ่านส่วนหน้าของคุณ และสามารถเชื่อมต่อกับประเภทใดประเภทหนึ่งที่ส่วนหลังได้ ซึ่งช่วยให้สามารถกำหนดค่าที่ซับซ้อนได้ เช่น การเชื่อมต่อกับ Wilmer เป็น v1/Completion API จากนั้นให้ Wilmer เชื่อมต่อกับแชท/Completion, v1/Completion KoboldCpp สร้างจุดสิ้นสุดทั้งหมดในเวลาเดียวกัน
เทมเพลตพร้อมท์: รองรับเทมเพลตพร้อมท์สำหรับจุดสิ้นสุด v1/Completions API WilmerAI ยังมีเทมเพลตพร้อมต์ของตัวเองสำหรับการเชื่อมต่อจากส่วนหน้าผ่าน v1/Completions เทมเพลตสามารถพบได้ในโฟลเดอร์ "Docs" และพร้อมสำหรับการอัปโหลดไปยัง SillyTavern
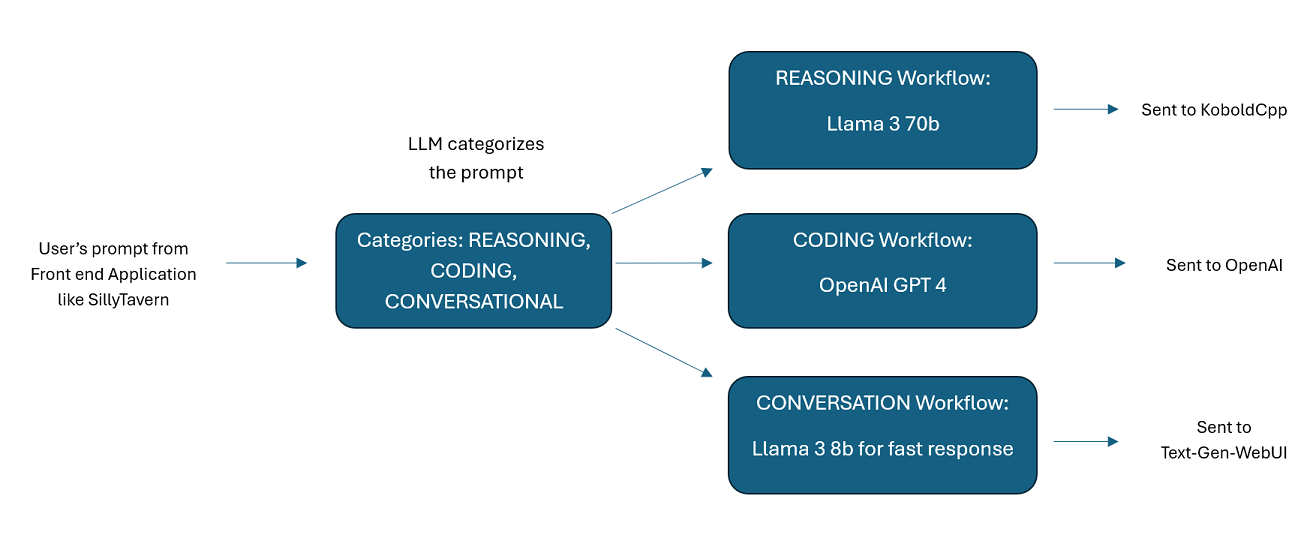
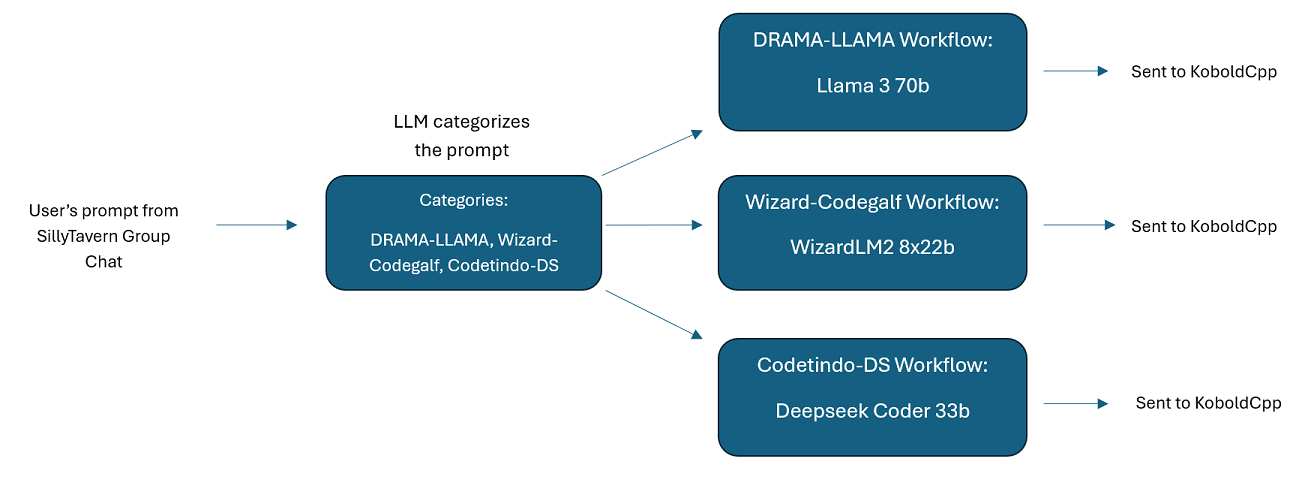
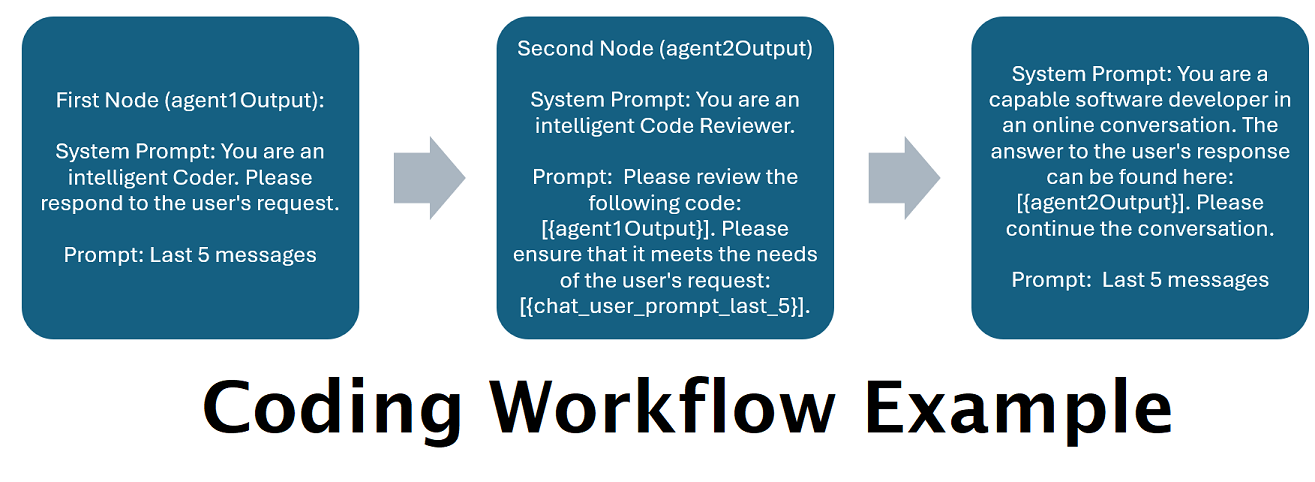
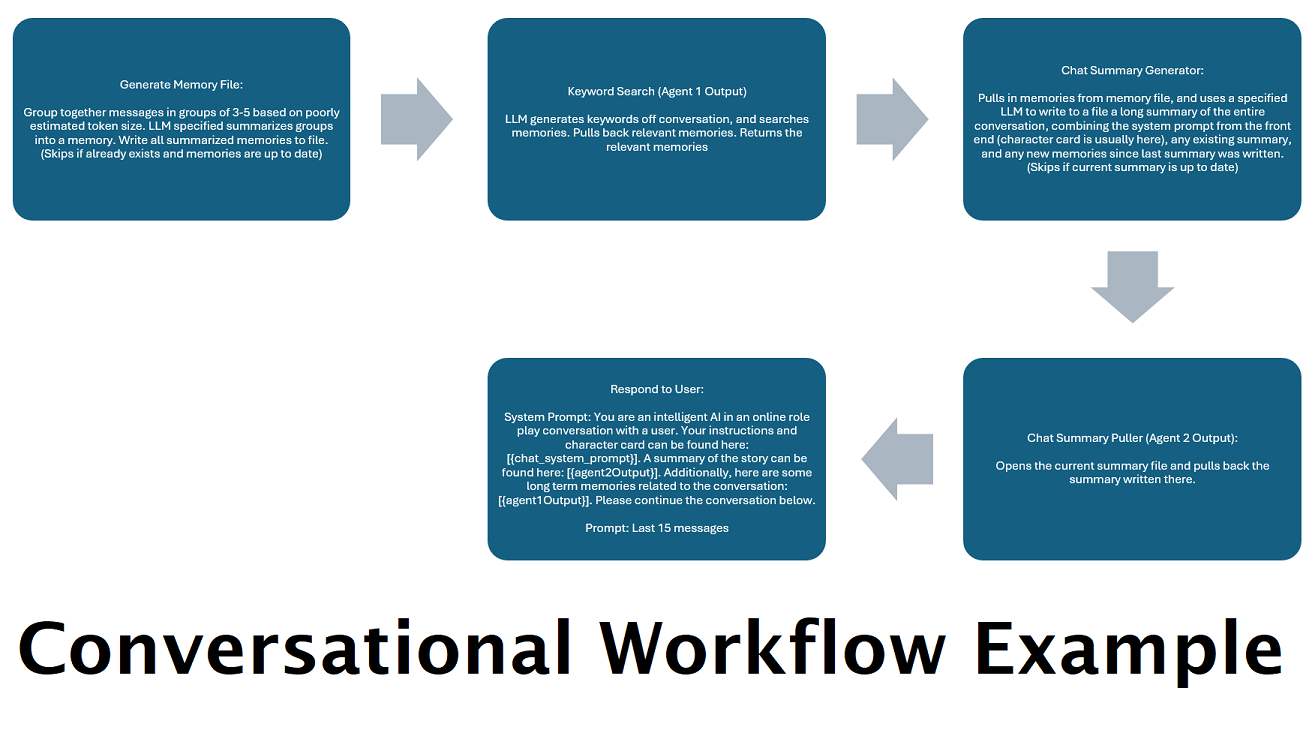

โปรดทราบว่าโดยธรรมชาติแล้วเวิร์กโฟลว์สามารถทำการเรียกตำแหน่งข้อมูล API ได้หลายครั้ง ขึ้นอยู่กับวิธีที่คุณตั้งค่า WilmerAI ไม่ติดตามการใช้โทเค็น ไม่รายงานการใช้โทเค็นที่แม่นยำผ่าน API และเสนอวิธีการใด ๆ ที่เป็นไปได้ในการตรวจสอบการใช้โทเค็น ดังนั้น หากการติดตามการใช้โทเค็นมีความสำคัญสำหรับคุณด้วยเหตุผลด้านต้นทุน โปรดติดตามจำนวนโทเค็นที่คุณใช้ผ่านแดชบอร์ดใดๆ ที่ LLM API ของคุณมอบให้ โดยเฉพาะอย่างยิ่งเมื่อคุณคุ้นเคยกับซอฟต์แวร์นี้ตั้งแต่เนิ่นๆ
LLM ของคุณส่งผลโดยตรงต่อคุณภาพของ WilmerAI นี่คือโปรเจ็กต์ที่ขับเคลื่อนด้วย LLM ซึ่งโฟลว์และเอาท์พุตเกือบทั้งหมดขึ้นอยู่กับ LLM ที่เชื่อมต่อและการตอบสนอง หากคุณเชื่อมต่อ Wilmer กับโมเดลที่สร้างเอาต์พุตคุณภาพต่ำ หรือหากค่าที่ตั้งล่วงหน้าหรือเทมเพลตพร้อมท์ของคุณมีข้อบกพร่อง คุณภาพโดยรวมของ Wilmer ก็จะมีคุณภาพต่ำกว่ามากเช่นกัน มันไม่แตกต่างไปจากเวิร์กโฟลว์เอเจนต์ในลักษณะนั้นมากนัก
ในขณะที่ผู้เขียนพยายามอย่างเต็มที่เพื่อสร้างสิ่งที่มีประโยชน์และมีคุณภาพสูง แต่นี่เป็นโปรเจ็กต์เดี่ยวที่ทะเยอทะยานและมักจะมีปัญหา (โดยเฉพาะอย่างยิ่งเนื่องจากผู้เขียนไม่ใช่นักพัฒนา Python โดยกำเนิด และอาศัย AI อย่างมากเพื่อช่วยให้เขาได้สิ่งนี้ ไกล). แม้ว่าเขาจะค่อยๆ คิดออกก็ตาม
Wilmer เปิดเผยทั้งตำแหน่งข้อมูล OpenAI v1/Completions และ chat/Completions ทำให้เข้ากันได้กับส่วนหน้าส่วนใหญ่ แม้ว่าฉันจะใช้สิ่งนี้กับ SillyTavern เป็นหลัก แต่ก็อาจทำงานกับ Open-WebUI ได้เช่นกัน
หากต้องการเชื่อมต่อเป็นการเติมข้อความใน SillyTavern ให้ทำตามขั้นตอนเหล่านี้ (ภาพหน้าจอด้านล่างนี้มาจาก SillyTavern):
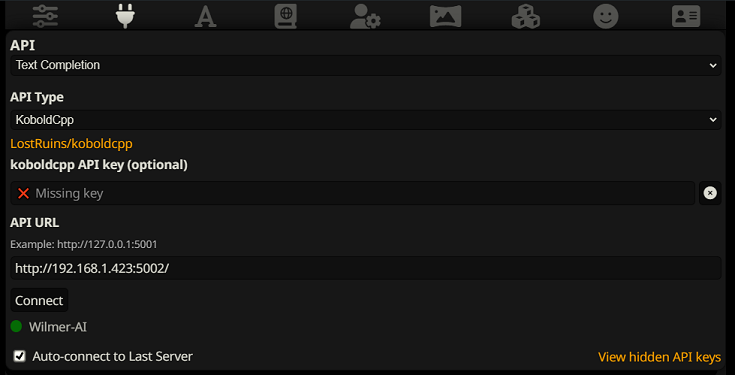
เมื่อใช้การเติมข้อความให้สมบูรณ์ คุณต้องใช้รูปแบบเทมเพลต Prompt เฉพาะของ WilmerAI ไฟล์ ST ที่นำเข้าได้สามารถพบได้ภายใน Docs/SillyTavern/InstructTemplate เทมเพลตบริบทยังรวมอยู่ด้วยหากคุณต้องการใช้สิ่งนั้นเช่นกัน
เทมเพลตคำแนะนำมีลักษณะดังนี้:
[Beg_Sys]You are an intelligent AI Assistant.[Beg_User]SomeOddCodeGuy: Hey there![Beg_Assistant]Wilmer: Hello![Beg_User]SomeOddCodeGuy: This is a test[Beg_Assistant]Wilmer: Nice.
จาก SillyTavern:
"input_sequence": "[Beg_User]",
"output_sequence": "[Beg_Assistant]",
"first_output_sequence": "[Beg_Assistant]",
"last_output_sequence": "",
"system_sequence_prefix": "[Beg_Sys]",
"system_sequence_suffix": "",
ไม่มีการขึ้นบรรทัดใหม่หรืออักขระที่คาดหวังระหว่างแท็ก
โปรดตรวจสอบให้แน่ใจว่าเทมเพลตบริบทเป็น "เปิดใช้งาน" (ช่องทำเครื่องหมายเหนือเมนูแบบเลื่อนลง)
หากต้องการเชื่อมต่อเป็นการเสร็จสิ้นการแชทใน SillyTavern ให้ทำตามขั้นตอนเหล่านี้ (ภาพหน้าจอด้านล่างนี้มาจาก SillyTavern):
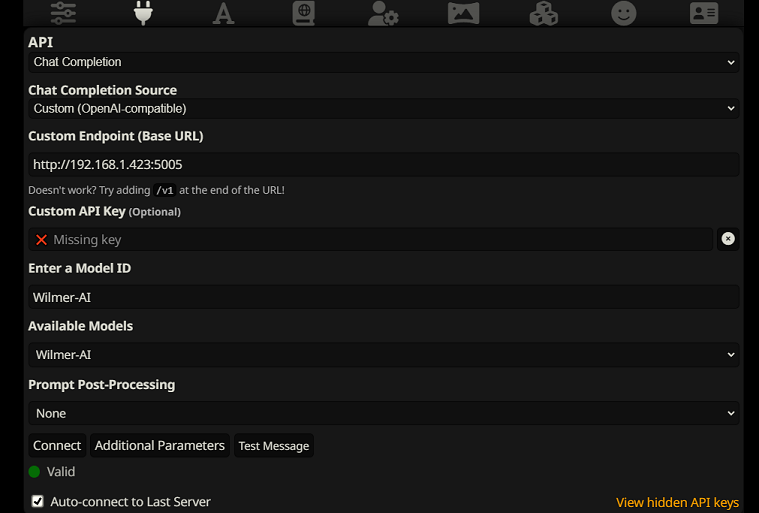
chatCompleteAddUserAssistant เป็น true (ฉันไม่แนะนำให้ตั้งค่าเป็นจริงทั้งสองพร้อมกัน เลือกชื่อตัวละครจาก SillyTavern หรือผู้ใช้/ผู้ช่วยจาก Wilmer AI อาจสับสนได้)สำหรับการเชื่อมต่อประเภทใดประเภทหนึ่ง ฉันขอแนะนำให้ไปที่ไอคอน "A" ใน SillyTavern และเลือก "รวมชื่อ" และ "บังคับกลุ่มและบุคคล" ภายใต้โหมดคำสั่ง จากนั้นไปที่ไอคอนด้านซ้ายสุด (ซึ่งมีตัวอย่างอยู่) และตรวจสอบ " stream" ที่ด้านซ้ายบน จากนั้นที่ด้านขวาบนให้ทำเครื่องหมาย "ปลดล็อก" ใต้บริบทแล้วลากไปที่ 200,000+ ให้วิลเมอร์กังวลเกี่ยวกับบริบท
ปัจจุบันวิลเมอร์ไม่มีส่วนต่อประสานกับผู้ใช้ ทุกอย่างถูกควบคุมผ่านไฟล์การกำหนดค่า JSON ที่อยู่ในโฟลเดอร์ "สาธารณะ" โฟลเดอร์นี้มีการกำหนดค่าที่จำเป็นทั้งหมด เมื่ออัปเดตหรือดาวน์โหลดสำเนาใหม่ของ WilmerAI คุณควรคัดลอกโฟลเดอร์ "สาธารณะ" ของคุณไปยังการติดตั้งใหม่เพื่อคงการตั้งค่าของคุณไว้
ส่วนนี้จะแนะนำคุณตลอดการตั้งค่า Wilmer ฉันแบ่งส่วนต่างๆ ออกเป็นขั้นตอน ฉันอาจแนะนำให้คัดลอกแต่ละขั้นตอน 1 ต่อ 1 ลงใน LLM และขอให้ช่วยคุณตั้งค่าส่วนนี้ นั่นอาจทำให้เรื่องนี้ง่ายขึ้นมาก
หมายเหตุสำคัญ
สิ่งสำคัญคือต้องทราบสามสิ่งเกี่ยวกับการตั้งค่าของ Wilmer
A) ไฟล์ที่ตั้งไว้ล่วงหน้าสามารถปรับแต่งได้ 100% สิ่งที่อยู่ในไฟล์นั้นจะไปที่ llm API เนื่องจาก Cloud API ไม่ได้จัดการค่าที่ตั้งล่วงหน้าต่างๆ ที่ LLM API ภายในเครื่องจัดการ ด้วยเหตุนี้ หากคุณใช้ OpenAI API หรือบริการคลาวด์อื่นๆ การโทรอาจจะล้มเหลวหากคุณใช้การตั้งค่าล่วงหน้า AI ในพื้นที่ปกติอย่างใดอย่างหนึ่ง โปรดดูค่าที่ตั้งไว้ล่วงหน้า "OpenAI-API" สำหรับตัวอย่างสิ่งที่ openAI ยอมรับ
B) ฉันเพิ่งเปลี่ยนข้อความแจ้งทั้งหมดใน Wilmer เพื่อเปลี่ยนจากการใช้บุคคลที่สองไปเป็นบุคคลที่สาม สิ่งนี้ให้ผลลัพธ์ที่ค่อนข้างดีสำหรับฉัน และฉันหวังว่าจะได้ผลสำหรับคุณเช่นกัน
C) ตามค่าเริ่มต้น ไฟล์ผู้ใช้ทั้งหมดจะถูกตั้งค่าให้เปิดการตอบกลับแบบสตรีม คุณต้องเปิดใช้งานสิ่งนี้ในส่วนหน้าของคุณที่เรียก Wilmer เพื่อให้ทั้งสองตรงกัน หรือคุณต้องเข้าไปที่ Users/username.json และตั้งค่า Stream เป็น "false" หากคุณมีข้อมูลที่ไม่ตรงกัน โดยที่ส่วนหน้าทำ/ไม่คาดว่าจะมีการสตรีม และ Wilmer ของคุณคาดหวังสิ่งที่ตรงกันข้าม ไม่น่าจะมีอะไรแสดงที่ส่วนหน้า
การติดตั้ง Wilmer นั้นตรงไปตรงมา ตรวจสอบให้แน่ใจว่าคุณได้ติดตั้ง Python แล้ว ผู้เขียนได้ใช้โปรแกรมกับ Python 3.10 และ 3.12 และทำงานได้ดีทั้งคู่
ตัวเลือกที่ 1: การใช้สคริปต์ที่ให้มา
เพื่อความสะดวก Wilmer มีไฟล์ BAT สำหรับ Windows และไฟล์ .sh สำหรับ macOS สคริปต์เหล่านี้จะสร้างสภาพแวดล้อมเสมือน ติดตั้งแพ็คเกจที่จำเป็นจาก requirements.txt จากนั้นเรียกใช้ Wilmer คุณสามารถใช้สคริปต์เหล่านี้เพื่อเริ่ม Wilmer ในแต่ละครั้ง
.bat ที่ให้มา.sh ที่ให้มาสิ่งสำคัญ: ห้ามเรียกใช้ไฟล์ BAT หรือ SH โดยไม่ตรวจสอบก่อน เนื่องจากอาจมีความเสี่ยงได้ หากคุณไม่แน่ใจเกี่ยวกับความปลอดภัยของไฟล์ดังกล่าว ให้เปิดไฟล์ใน Notepad/TextEdit คัดลอกเนื้อหา จากนั้นขอให้ LLM ของคุณตรวจสอบปัญหาที่อาจเกิดขึ้น
ตัวเลือกที่ 2: การติดตั้งด้วยตนเอง
หรือคุณสามารถติดตั้งการขึ้นต่อกันและรัน Wilmer ด้วยตนเองตามขั้นตอนต่อไปนี้:
ติดตั้งแพ็คเกจที่จำเป็น:
pip install -r requirements.txtเริ่มโปรแกรม:
python server.pyสคริปต์ที่ให้มาได้รับการออกแบบเพื่อปรับปรุงกระบวนการโดยการตั้งค่าสภาพแวดล้อมเสมือน อย่างไรก็ตาม คุณสามารถเพิกเฉยต่อสิ่งเหล่านี้ได้อย่างปลอดภัยหากคุณต้องการติดตั้งด้วยตนเอง
หมายเหตุ : เมื่อเรียกใช้ไฟล์ bat, ไฟล์ sh หรือไฟล์ python ตอนนี้ทั้งสามไฟล์ยอมรับอาร์กิวเมนต์ OPTIONAL ต่อไปนี้:
ตัวอย่างเช่น ลองพิจารณาการรันที่เป็นไปได้ต่อไปนี้:
bash run_macos.sh (จะใช้ผู้ใช้ที่ระบุใน _current-user.json, กำหนดค่าใน "สาธารณะ", บันทึกใน "บันทึก")bash run_macos.sh --User "single-model-assistant" (จะใช้ค่าเริ่มต้นเป็นสาธารณะสำหรับการกำหนดค่าและ "บันทึก" สำหรับบันทึก)bash run_macos.sh --ConfigDirectory "/users/socg/Public/configs" --User "single-model-assistant" (จะใช้ค่าเริ่มต้นสำหรับ "บันทึก"bash run_macos.sh --ConfigDirectory "/users/socg/Public/configs" --User "single-model-assistant" --LoggingDirectory "/users/socg/wilmerlogs"อาร์กิวเมนต์ทางเลือกเหล่านี้ทำให้ผู้ใช้สามารถหมุนอินสแตนซ์ของ WilmerAI ได้หลายอินสแตนซ์ โดยแต่ละอินสแตนซ์ใช้โปรไฟล์ผู้ใช้ที่แตกต่างกัน บันทึกไปยังตำแหน่งอื่น และระบุการกำหนดค่าในตำแหน่งอื่น หากต้องการ
ภายใน Public/Configs คุณจะพบชุดโฟลเดอร์ที่มีไฟล์ json สองสิ่งที่คุณสนใจมากที่สุดคือโฟลเดอร์ Endpoints และโฟลเดอร์ Users
หมายเหตุ: โหนดเวิร์กโฟลว์ตามความเป็นจริงของผู้ใช้ assistant-single-model , assistant-multi-model และ group-chat-example จะพยายามใช้โปรเจ็กต์ OfflineWikipediaTextApi เพื่อดึงบทความวิกิพีเดียฉบับเต็มไปยัง RAG หากคุณไม่มี API นี้ ขั้นตอนการทำงานไม่ควรมีปัญหาใดๆ แต่โดยส่วนตัวแล้วฉันใช้ API นี้เพื่อช่วยปรับปรุงการตอบสนองตามข้อเท็จจริงที่ฉันได้รับ คุณสามารถระบุที่อยู่ IP ให้กับ API ของคุณใน json ผู้ใช้ที่คุณเลือกได้
ขั้นแรก เลือกผู้ใช้เทมเพลตที่คุณต้องการใช้:
Assistant-single-model : เทมเพลตนี้ใช้สำหรับโมเดลขนาดเล็กตัวเดียวที่ใช้กับทุกโหนด นอกจากนี้ยังมีเส้นทางสำหรับประเภทหมวดหมู่ต่างๆ มากมาย และใช้การตั้งค่าล่วงหน้าที่เหมาะสมสำหรับแต่ละโหนด หากคุณสงสัยว่าเหตุใดจึงมีเส้นทางสำหรับหมวดหมู่ต่างๆ ในเมื่อมีเพียง 1 โมเดล นั่นคือเพื่อให้คุณสามารถกำหนดหมวดหมู่ล่วงหน้าให้แต่ละหมวดหมู่ได้ และเพื่อให้คุณสามารถสร้างเวิร์กโฟลว์แบบกำหนดเองสำหรับโมเดลเหล่านั้นได้ บางทีคุณอาจต้องการให้ผู้เขียนโค้ดทำซ้ำหลายครั้งเพื่อตรวจสอบตัวเอง หรือให้เหตุผลเพื่อคิดทบทวนสิ่งต่างๆ ในหลายขั้นตอน
Assistant-multi-model : เทมเพลตนี้ใช้สำหรับหลายโมเดลพร้อมกัน เมื่อดูที่ปลายทางสำหรับผู้ใช้รายนี้ คุณจะเห็นว่าทุกหมวดหมู่มีปลายทางของตัวเอง ไม่มีอะไรหยุดยั้งคุณจากการใช้ API เดิมซ้ำสำหรับหลายประเภทได้อย่างแน่นอน ตัวอย่างเช่น คุณอาจใช้ Llama 3.1 70b สำหรับการเขียนโค้ด คณิตศาสตร์ และการใช้เหตุผล และใช้ Command-R 35b 08-2024 สำหรับการจัดหมวดหมู่ การสนทนา และข้อเท็จจริง อย่ารู้สึกว่าคุณต้องการโมเดลที่แตกต่างกัน 10 แบบ นี่เป็นเพียงเพื่อให้คุณนำมาได้มากเท่าที่ต้องการ ผู้ใช้รายนี้ใช้ค่าที่ตั้งล่วงหน้าที่เหมาะสมสำหรับแต่ละโหนดในเวิร์กโฟลว์
convo-roleplay-single-model : ผู้ใช้นี้ใช้โมเดลเดียวที่มีเวิร์กโฟลว์ที่กำหนดเองซึ่งดีสำหรับการสนทนา และควรจะดีสำหรับการสวมบทบาท (รอข้อเสนอแนะเพื่อปรับแต่งหากจำเป็น) สิ่งนี้จะข้ามเส้นทางทั้งหมด
convo-roleplay-dual-model : ผู้ใช้นี้ใช้สองโมเดลที่มีเวิร์กโฟลว์ที่กำหนดเองซึ่งดีสำหรับการสนทนา และควรจะดีสำหรับการสวมบทบาท (รอข้อเสนอแนะเพื่อปรับแต่งหากจำเป็น) สิ่งนี้จะข้ามเส้นทางทั้งหมด หมายเหตุ : ขั้นตอนการทำงานนี้จะทำงานได้ดีที่สุดถ้าคุณมีคอมพิวเตอร์ 2 เครื่องที่สามารถเรียกใช้ LLM ได้ ด้วยการตั้งค่าปัจจุบันสำหรับผู้ใช้รายนี้ เมื่อคุณส่งข้อความถึง Wilmer โมเดลการตอบกลับ (คอมพิวเตอร์ 1) จะตอบกลับคุณ จากนั้นเวิร์กโฟลว์จะใช้ "การล็อกเวิร์กโฟลว์" ณ จุดนั้น โมเดลสรุปหน่วยความจำ/แชท (คอมพิวเตอร์ 2) จะเริ่มอัปเดตความทรงจำและบทสรุปของการสนทนาจนถึงตอนนี้ ซึ่งจะถูกส่งต่อไปยังผู้ตอบกลับเพื่อช่วยจดจำสิ่งต่างๆ หากคุณต้องส่งพรอมต์อีกครั้งในขณะที่กำลังเขียนความทรงจำ ผู้ตอบกลับ (คอมพิวเตอร์ 1) จะดึงข้อมูลสรุปที่มีอยู่แล้วตอบกลับคุณ การล็อกเวิร์กโฟลว์จะทำให้คุณไม่สามารถเข้าสู่ส่วนความทรงจำใหม่ได้อีกครั้ง ความหมายก็คือ คุณสามารถพูดคุยกับโมเดลการตอบกลับของคุณต่อไปได้ในขณะที่กำลังเขียนความทรงจำใหม่ นี่คือการเพิ่มประสิทธิภาพอย่างมาก ฉันได้ลองใช้แล้ว และสำหรับฉัน เวลาในการตอบกลับนั้นยอดเยี่ยมมาก หากไม่มีสิ่งนี้ ฉันจะได้รับการตอบกลับภายใน 30 วินาที 3-5 ครั้ง และทันใดนั้นก็ต้องรอ 2 นาทีเพื่อสร้างความทรงจำ ด้วยวิธีนี้ ทุกข้อความจะมีความยาว 30 วินาทีในแต่ละครั้งบน Llama 3.1 70b บน Mac Studio ของฉัน
group-chat-example : ผู้ใช้คนนี้เป็นตัวอย่างของการแชทกลุ่มส่วนตัวของฉันเอง ตัวละครและกลุ่มที่รวมอยู่นั้นเป็นตัวละครจริงและกลุ่มจริงที่ฉันใช้ คุณสามารถค้นหาตัวละครตัวอย่างได้ในโฟลเดอร์ Docs/SillyTavern อักขระเหล่านี้เป็นอักขระที่เข้ากันได้กับ SillyTavern ซึ่งคุณสามารถนำเข้าโดยตรงไปยังโปรแกรมนั้นหรือโปรแกรมใดๆ ที่รองรับประเภทการนำเข้าอักขระ .png ตัวละครของทีม dev มีเพียง 1 โหนดต่อเวิร์กโฟลว์: พวกมันเพียงตอบกลับคุณ อักขระกลุ่มที่ปรึกษามี 2 โหนดต่อเวิร์กโฟลว์ โหนดแรกสร้างการตอบสนอง และโหนดที่สองบังคับใช้ "บุคคล" ของอักขระ (จุดสิ้นสุดที่รับผิดชอบในเรื่องนี้คือจุดสิ้นสุด businessgroup-speaker ) บุคลิกแชทกลุ่มช่วยได้มากในการตอบสนองที่คุณได้รับ แม้ว่าคุณจะใช้เพียง 1 รุ่นก็ตาม อย่างไรก็ตาม ฉันตั้งเป้าที่จะใช้โมเดลที่แตกต่างกันสำหรับตัวละครทุกตัว (แต่นำโมเดลกลับมาใช้ใหม่ระหว่างกลุ่ม ตัวอย่างเช่น ฉันมีตัวละครโมเดล Llama 3.1 70b ในแต่ละกลุ่ม)
เมื่อคุณเลือกผู้ใช้ที่คุณต้องการใช้แล้ว มีสองขั้นตอนในการดำเนินการ:
อัปเดตตำแหน่งข้อมูลสำหรับผู้ใช้ของคุณภายใต้ Public/Configs/Endpoints อักขระตัวอย่างจะถูกจัดเรียงเป็นโฟลเดอร์สำหรับแต่ละตัว โฟลเดอร์ปลายทางของผู้ใช้ระบุไว้ที่ด้านล่างของไฟล์ user.json คุณจะต้องกรอกข้อมูลจุดสิ้นสุดทุกจุดอย่างเหมาะสมสำหรับ LLM ที่คุณใช้ คุณสามารถดูตัวอย่างตำแหน่งข้อมูลบางส่วนได้ในโฟลเดอร์ _example-endpoints
คุณจะต้องตั้งค่าผู้ใช้ปัจจุบันของคุณ คุณสามารถทำได้เมื่อรันไฟล์ bat/sh/py โดยใช้อาร์กิวเมนต์ --User หรือคุณสามารถทำสิ่งนี้ได้ใน Public/Configs/Users/_current-user.json เพียงใส่ชื่อผู้ใช้เป็นผู้ใช้ปัจจุบันแล้วบันทึก
คุณจะต้องเปิดไฟล์ json ของผู้ใช้และดูตัวเลือกต่างๆ ที่นี่คุณสามารถตั้งค่าได้ว่าคุณต้องการสตรีมหรือไม่ สามารถตั้งค่าที่อยู่ IP เป็น wiki API ออฟไลน์ของคุณ (หากคุณใช้งาน) ระบุตำแหน่งที่คุณต้องการให้ไฟล์ความทรงจำ/สรุปของคุณไปในระหว่างโฟลว์ DiscussionId และยังระบุตำแหน่งที่คุณ ต้องการให้ sqllite db ไปหากคุณใช้ Workflow Locks
แค่นั้นแหละ! เรียกใช้วิลเมอร์ เชื่อมต่อแล้วคุณน่าจะพร้อมไป
ขั้นแรก เราจะตั้งค่าจุดสิ้นสุดและโมเดล ภายในโฟลเดอร์ Public/Configs คุณจะเห็นโฟลเดอร์ย่อยต่อไปนี้ มาดูสิ่งที่คุณต้องการกันดีกว่า
ไฟล์การกำหนดค่าเหล่านี้แสดงถึงตำแหน่งข้อมูล LLM API ที่คุณเชื่อมต่ออยู่ ตัวอย่างเช่น ไฟล์ JSON ต่อไปนี้ SmallModelEndpoint.json กำหนดจุดปลาย:
{
"modelNameForDisplayOnly" : " Small model for all tasks " ,
"endpoint" : " http://127.0.0.1:5000 " ,
"apiTypeConfigFileName" : " KoboldCpp " ,
"maxContextTokenSize" : 8192 ,
"modelNameToSendToAPI" : " " ,
"promptTemplate" : " chatml " ,
"addGenerationPrompt" : true
}ไฟล์การกำหนดค่าเหล่านี้แสดงถึงประเภท API ต่างๆ ที่คุณอาจพบเมื่อใช้ Wilmer
{
"nameForDisplayOnly" : " KoboldCpp Example " ,
"type" : " koboldCppGenerate " ,
"presetType" : " KoboldCpp " ,
"truncateLengthPropertyName" : " max_context_length " ,
"maxNewTokensPropertyName" : " max_length " ,
"streamPropertyName" : " stream "
} ไฟล์เหล่านี้ระบุเทมเพลตพร้อมต์สำหรับโมเดล ลองพิจารณาตัวอย่างต่อไปนี้ llama3.json :
{
"promptTemplateAssistantPrefix" : " <|start_header_id|>assistant<|end_header_id|> nn " ,
"promptTemplateAssistantSuffix" : " <|eot_id|> " ,
"promptTemplateEndToken" : " " ,
"promptTemplateSystemPrefix" : " <|start_header_id|>system<|end_header_id|> nn " ,
"promptTemplateSystemSuffix" : " <|eot_id|> " ,
"promptTemplateUserPrefix" : " <|start_header_id|>user<|end_header_id|> nn " ,
"promptTemplateUserSuffix" : " <|eot_id|> "
} เทมเพลตเหล่านี้ใช้กับการเรียกตำแหน่งข้อมูล v1/Completion ทั้งหมด หากคุณไม่ต้องการใช้เทมเพลต จะมีไฟล์ชื่อ _chatonly.json ที่แบ่งข้อความด้วยการขึ้นบรรทัดใหม่เท่านั้น
การสร้างและเปิดใช้งานผู้ใช้เกี่ยวข้องกับสี่ขั้นตอนหลัก ทำตามคำแนะนำด้านล่างเพื่อตั้งค่าผู้ใช้ใหม่
ขั้นแรก ภายในโฟลเดอร์ Users ให้สร้างไฟล์ JSON สำหรับผู้ใช้ใหม่ วิธีที่ง่ายที่สุดในการทำเช่นนี้คือการคัดลอกไฟล์ JSON ของผู้ใช้ที่มีอยู่ วางเป็นไฟล์ที่ซ้ำกัน จากนั้นเปลี่ยนชื่อ นี่คือตัวอย่างไฟล์ JSON ของผู้ใช้:
{
"port" : 5006 ,
"stream" : true ,
"customWorkflowOverride" : false ,
"customWorkflow" : " CodingWorkflow-LargeModel-Centric " ,
"routingConfig" : " assistantSingleModelCategoriesConfig " ,
"categorizationWorkflow" : " CustomCategorizationWorkflow " ,
"defaultParallelProcessWorkflow" : " SlowButQualityRagParallelProcessor " ,
"fileMemoryToolWorkflow" : " MemoryFileToolWorkflow " ,
"chatSummaryToolWorkflow" : " GetChatSummaryToolWorkflow " ,
"conversationMemoryToolWorkflow" : " CustomConversationMemoryToolWorkflow " ,
"recentMemoryToolWorkflow" : " RecentMemoryToolWorkflow " ,
"discussionIdMemoryFileWorkflowSettings" : " _DiscussionId-MemoryFile-Workflow-Settings " ,
"discussionDirectory" : " D: \ Temp " ,
"sqlLiteDirectory" : " D: \ Temp " ,
"chatPromptTemplateName" : " _chatonly " ,
"verboseLogging" : true ,
"chatCompleteAddUserAssistant" : true ,
"chatCompletionAddMissingAssistantGenerator" : true ,
"useOfflineWikiApi" : true ,
"offlineWikiApiHost" : " 127.0.0.1 " ,
"offlineWikiApiPort" : 5728 ,
"endpointConfigsSubDirectory" : " assistant-single-model " ,
"useFileLogging" : false
}0.0.0.0 ทำให้มองเห็นได้บนเครือข่ายของคุณหากทำงานบนคอมพิวเตอร์เครื่องอื่น รองรับการเรียกใช้ Wilmer หลายอินสแตนซ์บนพอร์ตที่แตกต่างกันtrue เราเตอร์จะถูกปิดใช้งาน และพร้อมท์ทั้งหมดจะส่งไปยังเวิร์กโฟลว์ที่ระบุเท่านั้น ทำให้เป็นอินสแตนซ์เวิร์กโฟลว์เดียวของ WilmercustomWorkflowOverride เป็น trueRouting โดยไม่มีนามสกุล . .jsonDiscussionIdchatCompleteAddUserAssistant เป็น true เท่านั้นDataFinder ของกลุ่มตัวอย่าง จากนั้น อัปเดตไฟล์ _current-user.json เพื่อระบุผู้ใช้ที่คุณต้องการใช้ จับคู่ชื่อของไฟล์ JSON ของผู้ใช้ใหม่ โดยไม่มีนามสกุล .json
หมายเหตุ : คุณสามารถเพิกเฉยต่อสิ่งนี้ได้หากคุณต้องการใช้อาร์กิวเมนต์ --User เมื่อรัน Wilmer แทน
สร้างไฟล์ JSON การกำหนดเส้นทางในโฟลเดอร์ Routing ไฟล์นี้สามารถตั้งชื่ออะไรก็ได้ที่คุณต้องการ อัปเดตคุณสมบัติ routingConfig ในไฟล์ JSON ของผู้ใช้ด้วยชื่อนี้ ลบส่วนขยาย .json นี่คือตัวอย่างของไฟล์กำหนดค่าการกำหนดเส้นทาง:
{
"CODING" : {
"description" : " Any request which requires a code snippet as a response " ,
"workflow" : " CodingWorkflow "
},
"FACTUAL" : {
"description" : " Requests that require factual information or data " ,
"workflow" : " ConversationalWorkflow "
},
"CONVERSATIONAL" : {
"description" : " Casual conversation or non-specific inquiries " ,
"workflow" : " FactualWorkflow "
}
}.json จะถูกทริกเกอร์หากเลือกหมวดหมู่ ในโฟลเดอร์ Workflow ให้สร้างโฟลเดอร์ใหม่ที่ตรงกับชื่อผู้ใช้จากโฟลเดอร์ Users วิธีที่รวดเร็วที่สุดในการทำเช่นนี้คือการคัดลอกโฟลเดอร์ของผู้ใช้ที่มีอยู่ ทำซ้ำ และเปลี่ยนชื่อ
หากคุณเลือกที่จะไม่ทำการเปลี่ยนแปลงอื่นๆ คุณจะต้องดำเนินการตามขั้นตอนการทำงานและอัปเดตตำแหน่งข้อมูลให้ชี้ไปยังตำแหน่งข้อมูลที่คุณต้องการ หากคุณใช้เวิร์กโฟลว์ตัวอย่างที่เพิ่มเข้ากับ Wilmer คุณก็น่าจะสบายดี
ภายในโฟลเดอร์ "สาธารณะ" คุณควรมี:
เวิร์กโฟลว์ในโปรเจ็กต์นี้ได้รับการแก้ไขและควบคุมในโฟลเดอร์ Public/Workflows ภายในโฟลเดอร์เวิร์กโฟลว์เฉพาะของผู้ใช้ของคุณ ตัวอย่างเช่น หากผู้ใช้ของคุณชื่อ socg และคุณมีไฟล์ socg.json อยู่ในโฟลเดอร์ Users ดังนั้นภายในเวิร์กโฟลว์คุณควรมีโฟลเดอร์ Workflows/socg
ต่อไปนี้เป็นตัวอย่างลักษณะของ JSON ของเวิร์กโฟลว์:
[
{
"title" : " Coding Agent " ,
"agentName" : " Coder Agent One " ,
"systemPrompt" : " You are an exceptionally powerful and intelligent technical AI that is currently in a role play with a user in an online chat. n The instructions for the roleplay can be found below: n [ n {chat_system_prompt} n ] n Please continue the conversation below. Please be a good team player. This means working together towards a common goal, and does not always include being overly polite or agreeable. Disagreement when the other user is wrong can help foster growth in everyone, so please always speak your mind and critically review your peers. Failure to correct someone who is wrong could result in the team's work being a failure. " ,
"prompt" : " " ,
"lastMessagesToSendInsteadOfPrompt" : 6 ,
"endpointName" : " SocgMacStudioPort5002 " ,
"preset" : " Coding " ,
"maxResponseSizeInTokens" : 500 ,
"addUserTurnTemplate" : false
},
{
"title" : " Reviewing Agent " ,
"agentName" : " Code Review Agent Two " ,
"systemPrompt" : " You are an exceptionally powerful and intelligent technical AI that is currently in a role play with a user in an online chat. " ,
"prompt" : " You are in an online conversation with a user. The last five messages can be found here: n [ n {chat_user_prompt_last_five} n ] n You have already considered this request quietly to yourself within your own inner thoughts, and come up with a possible answer. The answer can be found here: n [ n {agent1Output} n ] n Please critically review the response, reconsidering your initial choices, and ensure that it is accurate, complete, and fulfills all requirements of the user's request. nn Once you have finished reconsidering your answer, please respond to the user with the correct and complete answer. nn IMPORTANT: Do not mention your inner thoughts or make any mention of reviewing a solution. The user cannot see the answer above, and any mention of it would confuse the user. Respond to the user with a complete answer as if it were the first time you were answering it. " ,
"endpointName" : " SocgMacStudioPort5002 " ,
"preset" : " Coding " ,
"maxResponseSizeInTokens" : 1000 ,
"addUserTurnTemplate" : true
}
]ขั้นตอนการทำงานข้างต้นประกอบด้วยโหนดการสนทนา โหนดทั้งสองทำสิ่งง่ายๆ อย่างหนึ่ง นั่นคือ ส่งข้อความไปยัง LLM ที่ระบุที่จุดสิ้นสุด
title การตั้งชื่อที่ลงท้ายด้วย "หนึ่ง", "สอง" ฯลฯ จะมีประโยชน์มาก เพื่อติดตามผลลัพธ์ของตัวแทน เอาต์พุตของโหนดแรกจะถูกบันทึกไปที่ {agent1Output} เอาต์พุตที่สองใน {agent2Output} และอื่นๆEndpoints โดยไม่มีนามสกุล .jsonPresets โดยไม่มีนามสกุล .jsonfalse (ดูโหนดตัวอย่างแรกด้านบน) หากคุณส่งข้อความแจ้ง ให้ตั้งค่านี้เป็น true (ดูโหนดตัวอย่างที่สองด้านบน) NOTE: The addDiscussionIdTimestampsForLLM feature was an experiment, and truthfully I am not happy with how the experiment went. Even the largest LLMs misread the timestamps, got confused by them, etc. I have other plans for this feature which should be far more useful, but I left it in and won't be removing it, even though I don't necessarily recommend using it. -Socg
คุณสามารถใช้ตัวแปรหลายตัวภายในพรอมต์เหล่านี้ สิ่งเหล่านี้จะถูกแทนที่อย่างเหมาะสมเมื่อรันไทม์:
{chat_user_prompt_last_one} : ข้อความสุดท้ายในการสนทนาโดยไม่มีแท็กแม่แบบพรอมต์ห่อข้อความ{templated_user_prompt_last_one} : ข้อความสุดท้ายในการสนทนาห่อไว้ในแท็กแม่แบบพรอมต์ของผู้ใช้/ผู้ช่วยที่เหมาะสม{chat_system_prompt} : พรอมต์ระบบที่ส่งจากส่วนหน้า มักจะมีการ์ดอักขระและข้อมูลสำคัญอื่น ๆ{templated_system_prompt} : ระบบพรอมต์จากส่วนหน้าห่อไว้ในแท็กแม่แบบพรอมต์ระบบที่เหมาะสม{agent#Output} : # ถูกแทนที่ด้วยหมายเลขที่คุณต้องการ ทุกโหนดจะสร้างเอาต์พุตเอเจนต์ โหนดแรกคือ 1 เสมอและแต่ละโหนดที่ตามมาเพิ่มขึ้นโดย 1 ตัวอย่างเช่น {agent1Output} สำหรับโหนดแรก {agent2Output} สำหรับวินาที ฯลฯ ฯลฯ{category_colon_descriptions} : ดึงหมวดหมู่และคำอธิบายจากไฟล์ JSON Routing ของคุณ{categoriesSeparatedByOr} : ดึงชื่อหมวดหมู่คั่นด้วย "หรือ"[TextChunk] : ตัวแปรพิเศษที่ไม่ซ้ำกันกับโปรเซสเซอร์แบบขนานซึ่งไม่ได้ใช้บ่อยหมายเหตุ: สำหรับความเข้าใจที่ลึกซึ้งยิ่งขึ้นเกี่ยวกับวิธีการทำงานของความทรงจำโปรดดูส่วนความเข้าใจความทรงจำ
โหนดนี้จะดึงจำนวนความทรงจำ n (หรือข้อความล่าสุดหากไม่มีการสนทนาอยู่) และเพิ่มตัวคั่นที่กำหนดเองระหว่างพวกเขา ดังนั้นหากคุณมีไฟล์หน่วยความจำที่มี 3 ความทรงจำและเลือกตัวคั่นของ " n --------- n" คุณอาจได้รับสิ่งต่อไปนี้:
This is the first memory
---------
This is the second memory
---------
This is the third memory
การรวมโหนดนี้เข้ากับบทสรุปการแชทสามารถอนุญาตให้ LLM ได้รับไม่เพียง แต่การแยกย่อยสรุปของการสนทนาทั้งหมดโดยรวม แต่ยังเป็นรายการของความทรงจำทั้งหมดที่สรุปได้ซึ่งอาจมีข้อมูลรายละเอียดและละเอียดมากขึ้นเกี่ยวกับ มัน. การส่งทั้งสองข้อความเข้าด้วยกันพร้อมกับข้อความ 15-20 สุดท้ายสามารถสร้างความประทับใจของหน่วยความจำอย่างต่อเนื่องและต่อเนื่องของการแชททั้งหมดจนถึงข้อความล่าสุด การดูแลเป็นพิเศษในการสร้างพรอมต์ที่ดีสำหรับการสร้างความทรงจำสามารถช่วยให้มั่นใจได้ว่ารายละเอียดที่คุณสนใจจะถูกจับในขณะที่รายละเอียดที่เกี่ยวข้องน้อยลงจะถูกละเว้น
โหนดนี้จะไม่สร้างความทรงจำใหม่ นี่คือเพื่อให้การล็อคเวิร์กโฟลว์สามารถเคารพได้หากคุณใช้มันในการตั้งค่าหลายคอมพิวเตอร์ ปัจจุบันวิธีที่ดีที่สุดในการสร้างความทรงจำคือโหนด FullChatsummary


