Adding Private Data to LLMs
1.0.0
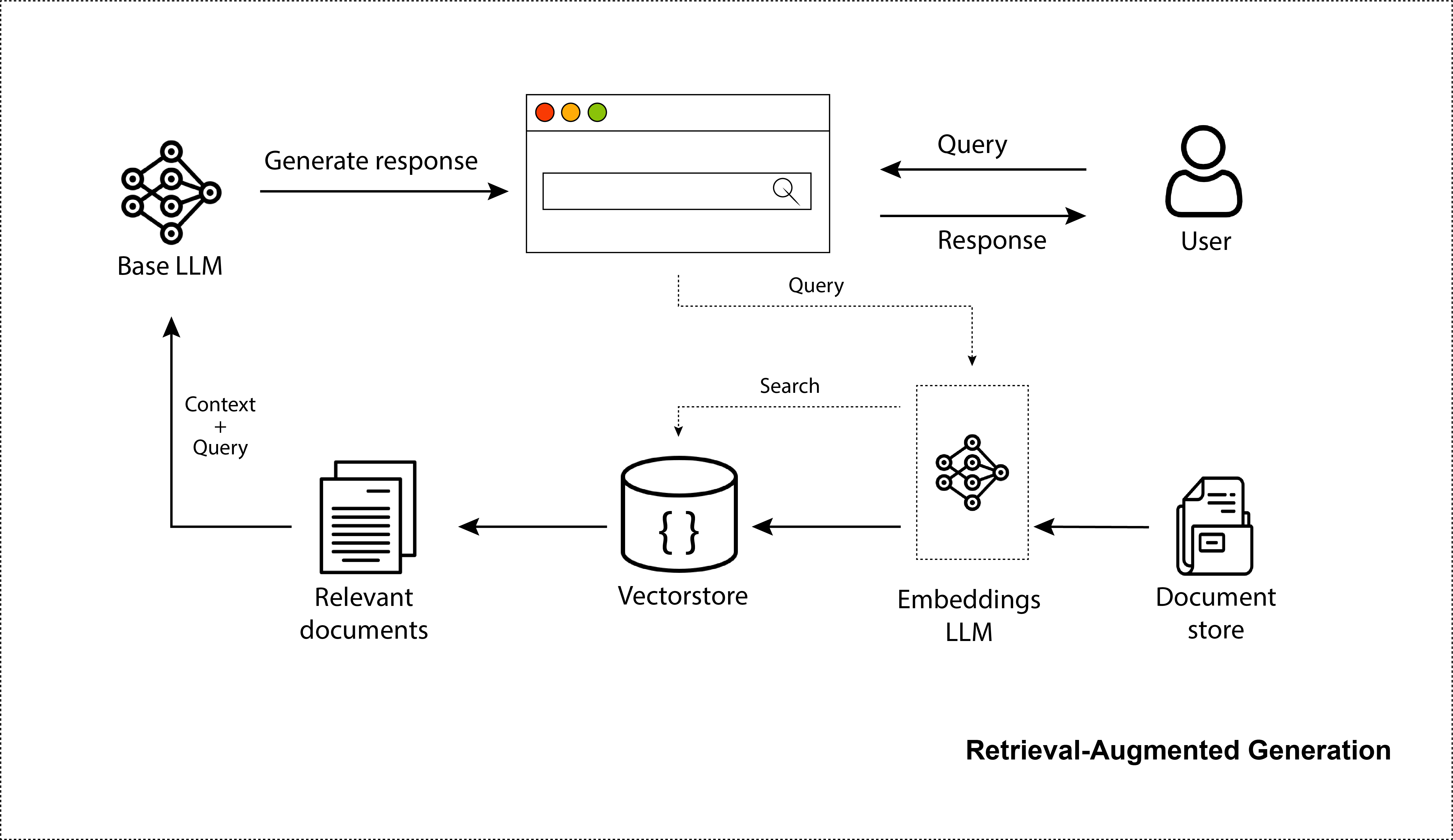
LLM ทำให้โลกตะลึงด้วยความสามารถในการสร้างภาพ โค้ด และบทสนทนาที่สมจริง ไม่ต้องสงสัยเลยว่า ChatGPT ครองโลกอย่างถล่มทลาย คนเป็นล้านกำลังใช้มัน แม้จะเป็นประโยชน์สำหรับความรู้ทั่วไป แต่ก็รู้เฉพาะข้อมูลที่ได้รับการฝึกอบรม ซึ่งเป็นข้อมูลอินเทอร์เน็ตโดยทั่วไปก่อนปี 2021 ขาดความตระหนักในข้อมูลส่วนตัวของคุณและยังคงไม่ได้รับข้อมูลเกี่ยวกับแหล่งข้อมูลล่าสุด ดังนั้น เพื่อปรับปรุงพวกเขาในเรื่องนั้น เราสามารถให้ข้อมูลที่เราดึงมาจากขั้นตอนการค้นหาให้พวกเขาได้ สิ่งนี้ทำให้เป็นจริงมากขึ้น และให้ความสามารถที่ดีขึ้นในการจัดหาข้อมูลที่ทันสมัยให้กับโมเดล โดยไม่จำเป็นต้องฝึกโมเดลขนาดใหญ่เหล่านี้ใหม่ นี่คือสิ่งที่ระบบดึงข้อมูล-เสริม LLM หรือระบบดึงข้อมูล-เพิ่มรุ่น (RAG) คืออะไร แท้จริงแล้ว พื้นที่เก็บข้อมูลนี้จะสรุปการสร้างระบบ RAG อย่างแม่นยำ และอธิบายขั้นตอนการเพิ่มประสิทธิภาพที่เกี่ยวข้อง
เศษผ้า
เทคสแต็ค
การติดตั้ง
ลิงค์ที่เป็นประโยชน์
ติดต่อ
แลงเชน
ลามะIndex
อาซัวร์ โอเพ่นเอไอ
กราดิโอ
โคลนพื้นที่เก็บข้อมูล Github
โคลน git https://github.com/zekaouinoureddine/Adding-Private-Data-to-LLMs.git
ข้อกำหนด Cd ไปยังไดเร็กทอรีโปรเจ็กต์และตรวจสอบให้แน่ใจว่าคุณได้ติดตั้ง Python 3 พร้อมด้วยการขึ้นต่อกันที่จำเป็น
cd การเพิ่มข้อมูลส่วนตัวไปยัง LLM pip ติดตั้ง -r ข้อกำหนด.txt
เรียกใช้แอป Gradio
หลาม rag.py
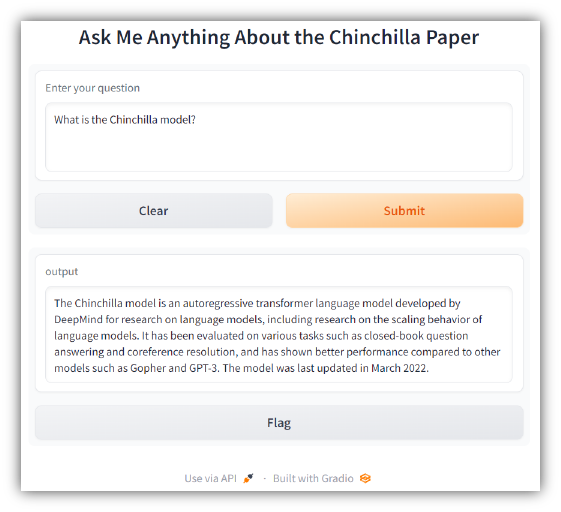
ไปที่ http://127.0.0.1:7860 บนเครื่องของคุณเพื่อทดสอบแอป คุณควรเห็นสิ่งต่อไปนี้:
| บล็อก | แพลตฟอร์ม | ภาษา | โน๊ตบุ๊ค |
|---|---|---|---|
| ถามข้อมูลของคุณเอง | บล็อกของไฮเบอรัส | อีเอส | |
| ถามข้อมูลของคุณเอง | ปานกลาง | TH | |
| ถามหน้าเว็บของคุณ | บล็อกของไฮเบอรัส | อีเอส | |
| ถามหน้าเว็บของคุณ | ปานกลาง | TH |
ถ้าชอบก็กดติดตามผมได้ที่:
LinkedIn: นูร์ เอ็ดดีน เซคาอูอิ
ทวิตเตอร์: @NZekaoui
กลับไปด้านบน


