EasyDetect
1.0.0

กรอบงานการตรวจจับอาการประสาทหลอนหลายรูปแบบที่ใช้งานง่ายสำหรับ MLLM
การรับทราบ • เกณฑ์มาตรฐาน • การสาธิต • ภาพรวม • ModelZoo • การติดตั้ง • การเริ่มต้นอย่างรวดเร็ว • การอ้างอิง
รับทราบ
ภาพรวม
ภาพหลอนหลายรูปแบบแบบครบวงจร
ชุดข้อมูล: MHalluBench Statistic
กรอบงาน: ภาพประกอบ UniHD
โมเดลซู
การติดตั้ง
⏩เริ่มต้นอย่างรวดเร็ว
การอ้างอิง
17-05-2024 เอกสาร Unified Hallucination Detection สำหรับโมเดลภาษาขนาดใหญ่หลายรูปแบบได้รับการยอมรับในการประชุมหลักของ ACL 2024
21-04-2024 เราแทนที่โมเดลพื้นฐานทั้งหมดในการสาธิตด้วยโมเดลที่ผ่านการฝึกอบรมของเราเอง ซึ่งช่วยลดเวลาในการอนุมานได้อย่างมาก
21-04-2024 เราเปิดตัวโมเดลการตรวจจับอาการประสาทหลอนแบบโอเพ่นซอร์ส HalDet-LLAVA ซึ่งสามารถดาวน์โหลดได้ในรูปแบบ Huggingface, Modelscope และ wisemodel
10-02-2024 เราเปิดตัวการสาธิต EasyDetect
05-02-2024 เราเผยแพร่รายงาน:"Unified Hallucination Detection for Multimodal Large Language Models" พร้อมด้วยเกณฑ์มาตรฐานใหม่ MHaluBench! เรากำลังรอความคิดเห็นหรือการสนทนาในหัวข้อนี้ :)
2023-10-20 โครงการ EasyDetect เปิดตัวแล้วและอยู่ระหว่างการพัฒนา
การดำเนินการบางส่วนของโครงการนี้ได้รับการช่วยเหลือและได้รับแรงบันดาลใจจากชุดเครื่องมือภาพหลอนที่เกี่ยวข้อง รวมถึง FactTool, Woodpecker และอื่นๆ พื้นที่เก็บข้อมูลนี้ยังได้รับประโยชน์จากโครงการสาธารณะจาก mPLUG-Owl, MiniGPT-4, LLaVA, GroundingDINO และ MAERec เราปฏิบัติตามใบอนุญาตเดียวกันสำหรับโอเพ่นซอร์ส และขอขอบคุณพวกเขาสำหรับการมีส่วนร่วมกับชุมชน
EasyDetect เป็นแพ็คเกจที่เป็นระบบซึ่งเสนอเป็นเฟรมเวิร์กการตรวจจับอาการประสาทหลอนที่ใช้งานง่ายสำหรับ Multimodal Large Language Models (MLLM) เช่น GPT-4V, Gemini, LlaVA ในการทดลองวิจัยของคุณ
ข้อกำหนดเบื้องต้นสำหรับการตรวจจับแบบรวมศูนย์คือการจัดหมวดหมู่ที่สอดคล้องกันของประเภทหลักของภาพหลอนภายใน MLLM บทความของเราตรวจสอบอย่างผิวเผินเกี่ยวกับอนุกรมวิธานประสาทหลอนต่อไปนี้จากมุมมองที่เป็นหนึ่งเดียว:


รูปที่ 1: การตรวจจับภาพหลอนหลายรูปแบบแบบรวมศูนย์มีจุดมุ่งหมายเพื่อระบุและตรวจจับภาพหลอนที่ขัดแย้งกับกิริยาในระดับต่างๆ เช่น วัตถุ คุณลักษณะ และข้อความในฉาก รวมถึงภาพหลอนที่ขัดแย้งกับข้อเท็จจริงทั้งในภาพเป็นข้อความและข้อความเป็นภาพ รุ่น.
ภาพหลอน Modality ที่ขัดแย้งกัน บางครั้ง MLLM จะสร้างเอาต์พุตที่ขัดแย้งกับอินพุตจากวิธีการอื่นๆ ซึ่งนำไปสู่ปัญหาต่างๆ เช่น วัตถุ คุณลักษณะ หรือข้อความในฉากที่ไม่ถูกต้อง ตัวอย่างในรูปที่ (ก) ด้านบนประกอบด้วย MLLM ที่อธิบายเครื่องแบบของนักกีฬาอย่างไม่ถูกต้อง โดยแสดงให้เห็นความขัดแย้งในระดับแอตทริบิวต์เนื่องจากความสามารถที่จำกัดของ MLLM ในการจัดแนวข้อความและรูปภาพที่มีความละเอียด
ภาพหลอนที่ขัดแย้งกับข้อเท็จจริง ผลลัพธ์จาก MLLM อาจขัดแย้งกับความรู้ข้อเท็จจริงที่มีอยู่ โมเดลรูปภาพเป็นข้อความสามารถสร้างเรื่องราวที่เบี่ยงเบนไปจากเนื้อหาจริงโดยการผสมผสานข้อเท็จจริงที่ไม่เกี่ยวข้อง ในขณะที่โมเดลการแปลงข้อความเป็นรูปภาพอาจสร้างภาพที่ล้มเหลวในการสะท้อนความรู้ข้อเท็จจริงที่มีอยู่ในข้อความแจ้ง ความแตกต่างเหล่านี้เน้นย้ำถึงการต่อสู้ของ MLLM เพื่อรักษาความสอดคล้องของข้อเท็จจริง ซึ่งแสดงถึงความท้าทายที่สำคัญในโดเมน
การตรวจจับอาการประสาทหลอนหลายรูปแบบแบบรวมศูนย์จำเป็นต้องมีการตรวจสอบคู่ข้อความรูปภาพแต่ละคู่ a={v, x} โดยที่ v หมายถึงอินพุตภาพที่ให้กับ MLLM หรือเอาต์พุตภาพที่สังเคราะห์โดยมัน ในทำนองเดียวกัน x หมายถึงการตอบกลับด้วยข้อความที่สร้างขึ้นของ MLLM โดยอิงจาก v หรือการสืบค้นข้อความของผู้ใช้สำหรับการสังเคราะห์ v ภายในงานนี้ x แต่ละรายการอาจมีการอ้างสิทธิ์หลายรายการ โดยระบุเป็น a เพื่อพิจารณาว่าเป็น "ภาพหลอน" หรือ "ไม่ใช่ภาพหลอน" โดยให้เหตุผลในการตัดสินตามคำจำกัดความที่ให้ไว้ของภาพหลอน การตรวจจับภาพหลอนด้วยข้อความจาก LLM แสดงถึงกรณีย่อยในการตั้งค่านี้ โดยที่ v เป็นค่าว่าง
เพื่อพัฒนาวิถีการวิจัยนี้ เราขอแนะนำเกณฑ์มาตรฐานการประเมินเมตา MHaluBench ซึ่งครอบคลุมเนื้อหาจากการสร้างภาพเป็นข้อความและข้อความเป็นภาพ โดยมีจุดมุ่งหมายเพื่อประเมินความก้าวหน้าในเครื่องตรวจจับอาการประสาทหลอนหลายรูปแบบอย่างเข้มงวด รายละเอียดทางสถิติเพิ่มเติมเกี่ยวกับ MHaluBench มีอยู่ในรูปด้านล่าง
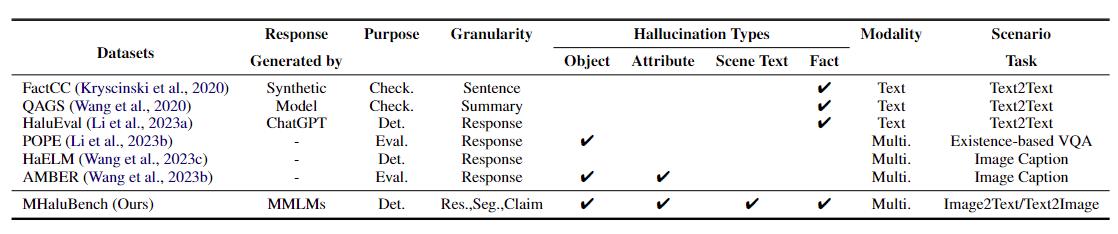
ตารางที่ 1: การเปรียบเทียบเกณฑ์มาตรฐานที่เกี่ยวข้องกับการตรวจสอบข้อเท็จจริงหรือการประเมินภาพหลอนที่มีอยู่ "ตรวจสอบ." บ่งชี้ถึงการตรวจสอบความสอดคล้องของข้อเท็จจริง "Eval" หมายถึงการประเมินภาพหลอนที่เกิดจาก LLM ที่แตกต่างกัน และการตอบสนองจะขึ้นอยู่กับ LLM ที่แตกต่างกันภายใต้การทดสอบ ในขณะที่ "Det" รวบรวมการประเมินความสามารถของเครื่องตรวจจับในการระบุภาพหลอน
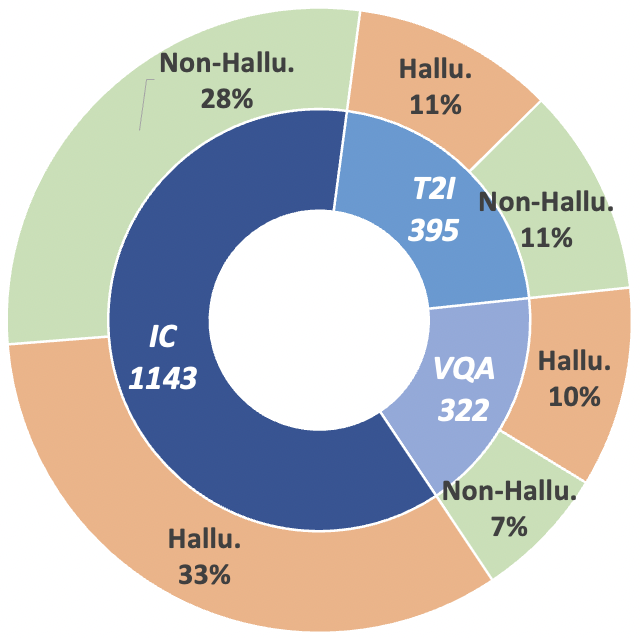
รูปที่ 2: สถิติข้อมูลระดับการอ้างสิทธิ์ของ MHaluBench "IC" หมายถึงคำบรรยายภาพ และ "T2I" หมายถึงการสังเคราะห์ข้อความเป็นรูปภาพ ตามลำดับ
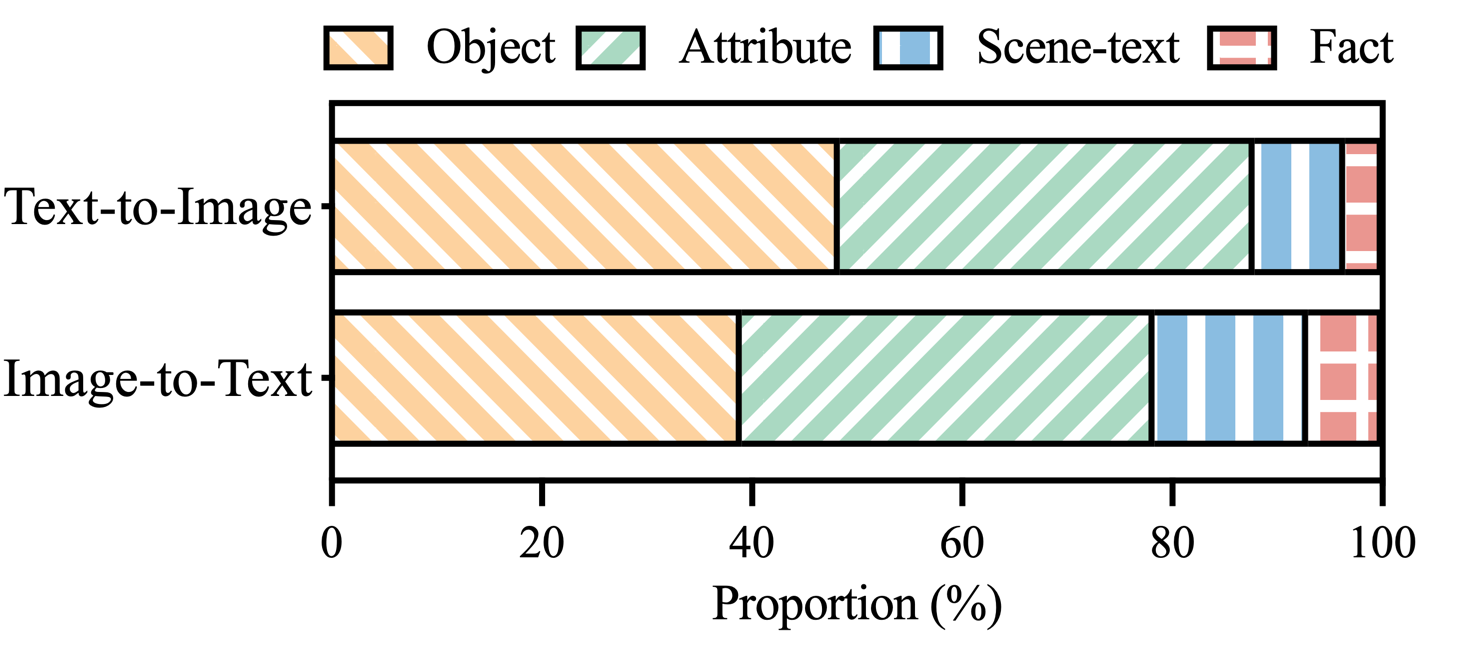
รูปที่ 3: การกระจายตัวของประเภทภาพหลอนภายในการอ้างสิทธิ์ที่มีป้ายกำกับภาพหลอนของ MHaluBench
ในการจัดการกับความท้าทายที่สำคัญในการตรวจจับอาการประสาทหลอน เราแนะนำกรอบงานแบบครบวงจรในรูปที่ 4 ที่จัดการกับการระบุอาการประสาทหลอนหลายรูปแบบอย่างเป็นระบบสำหรับงานทั้งแบบรูปภาพเป็นข้อความและข้อความเป็นรูปภาพ กรอบการทำงานของเราใช้ประโยชน์จากจุดแข็งเฉพาะโดเมนของเครื่องมือต่างๆ เพื่อรวบรวมหลักฐานหลายรูปแบบเพื่อยืนยันอาการประสาทหลอนอย่างมีประสิทธิภาพ
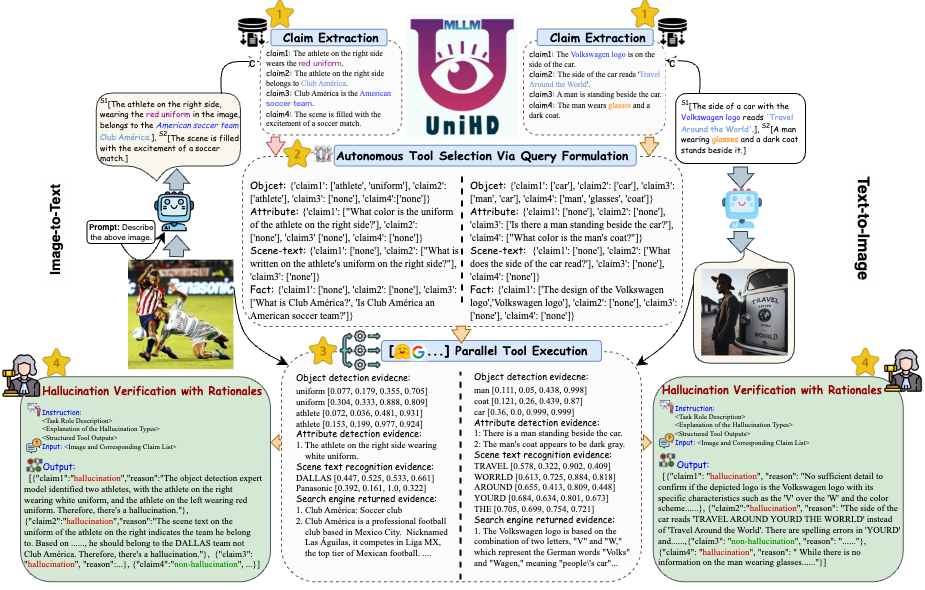
รูปที่ 4: ภาพประกอบเฉพาะของ UniHD สำหรับการตรวจจับอาการประสาทหลอนหลายรูปแบบแบบครบวงจร
คุณสามารถดาวน์โหลด HalDet-LLaVA, 7b และ 13b ได้สองเวอร์ชันบนสามแพลตฟอร์ม: HuggingFace, ModelScope และ WiseModel
| กอดใบหน้า | โมเดลสโคป | ปรีชาญาณรุ่น |
|---|---|---|
| ฮัลเดต-ลาวา-7b | ฮัลเดต-ลาวา-7b | ฮัลเดต-ลาวา-7b |
| ฮัลเดต-ลาวา-13b | ฮัลเดต-ลาวา-13b | ฮัลเดต-ลาวา-13b |
ระดับการอ้างสิทธิ์เป็นผลจากชุดข้อมูลการตรวจสอบ
การตรวจสอบตัวเอง (GPT-4V) หมายถึงการใช้ GPT-4V กับ 0 หรือ 2 กรณี
UniHD(GPT-4V/GPT-4o) หมายถึงการใช้ GPT-4V/GPT-4o พร้อมข้อมูล 2 ช็อตและเครื่องมือ
HalDet (LLAVA) หมายถึงการใช้ LLAVA-v1.5 ที่ได้รับการฝึกอบรมบนชุดข้อมูลรถไฟของเรา
| ประเภทงาน | แบบอย่าง | บัญชี | ค่าเฉลี่ยล่วงหน้า | เรียกคืนค่าเฉลี่ย | แมค.F1 |
| รูปภาพเป็นข้อความ | ตรวจสอบตัวเอง 0shot (GPV-4V) | 75.09 | 74.94 | 75.19 | 74.97 |
| ตรวจสอบตัวเอง 2shot (GPV-4V) | 79.25 | 79.02 | 79.16 | 79.08 | |
| ฮัลเดต (LLAVA-7b) | 75.02 | 75.05 | 74.18 | 74.38 | |
| ฮัลเดต (LLAVA-13b) | 78.16 | 78.18 | 77.48 | 77.69 | |
| UniHD(GPT-4V) | 81.91 | 81.81 | 81.52 | 81.63 | |
| UniHD(GPT-4o) | 86.08 | 85.89 | 86.07 | 85.96 | |
| ข้อความเป็นรูปภาพ | ตรวจสอบตัวเอง 0shot (GPV-4V) | 76.20 | 79.31 | 75.99 | 75.45 |
| ตรวจสอบตัวเอง 2shot (GPV-4V) | 80.76 | 81.16 | 80.69 | 80.67 | |
| ฮัลเดต (LLAVA-7b) | 67.35 | 69.31 | 67.50 | 66.62 | |
| ฮัลเดต (LLAVA-13b) | 74.74 | 76.68 | 74.88 | 74.34 | |
| UniHD(GPT-4V) | 85.82 | 85.83 | 85.83 | 85.82 | |
| UniHD(GPT-4o) | 89.29 | 89.28 | 89.28 | 89.28 |
หากต้องการดูข้อมูลโดยละเอียดเพิ่มเติมเกี่ยวกับ HalDet-LLaVA และชุดข้อมูลรถไฟ โปรดดูที่ readme
การติดตั้งเพื่อการพัฒนาท้องถิ่น:
git clone https://github.com/zjunlp/EasyDetect.git cd EasyDetect pip install -r requirements.txt
การติดตั้งเครื่องมือ (GroundingDINO และ MAERec):
# install GroundingDINO git clone https://github.com/IDEA-Research/GroundingDINO.git cp -r GroundingDINO pipeline/GroundingDINO cd pipeline/GroundingDINO/ pip install -e . cd .. # install MAERec git clone https://github.com/Mountchicken/Union14M.git cp -r Union14M/mmocr-dev-1.x pipeline/mmocr cd pipeline/mmocr/ pip install -U openmim mim install mmengine mim install mmcv mim install mmdet pip install timm pip install -r requirements/albu.txt pip install -r requirements.txt pip install -v -e . cd .. mkdir weights cd weights wget -q https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth wget https://download.openmmlab.com/mmocr/textdet/dbnetpp/dbnetpp_resnet50-oclip_fpnc_1200e_icdar2015/dbnetpp_resnet50-oclip_fpnc_1200e_icdar2015_20221101_124139-4ecb39ac.pth -O dbnetpp.pth wget https://github.com/Mountchicken/Union14M/releases/download/Checkpoint/maerec_b_union14m.pth -O maerec_b.pth cd ..
เรามีโค้ดตัวอย่างให้ผู้ใช้เริ่มต้นใช้งาน EasyDetect ได้อย่างรวดเร็ว
ผู้ใช้สามารถกำหนดค่าพารามิเตอร์ของ EasyDetect ในไฟล์ yaml ได้อย่างง่ายดาย หรือใช้พารามิเตอร์เริ่มต้นในไฟล์การกำหนดค่าที่เราจัดเตรียมไว้ให้ได้อย่างรวดเร็ว เส้นทางของไฟล์การกำหนดค่าคือ EasyDetect/pipeline/config/config.yaml
openai: api_key: ป้อนคีย์ openai api ของคุณ
base_url: อินพุต base_url ค่าเริ่มต้นคือไม่มี
อุณหภูมิ: 0.2
max_tokens: 1,024เครื่องมือ:
ตรวจพบ:groundingdino_config: เส้นทางของ GroundingDINO_SwinT_OGC.pymodel_path: เส้นทางของ groundingdino_swint_ogc.pthdevice: cuda:0BOX_TRESHOLD: 0.35TEXT_TRESHOLD: 0.25AREA_THRESHOLD: 0.001
ocr:dbnetpp_config: เส้นทางของ dbnetpp_resnet50-oclip_fpnc_1200e_icdar2015.pydbnetpp_path: เส้นทางของ dbnetpp.pthmaerec_config: เส้นทางของ maerec_b_union14m.pymaerec_path: เส้นทางของ maerec_b.pthdevice: cuda:0content: word.numbercachefiles_path: เส้นทางของ cache_files เพื่อบันทึกภาพชั่วคราวBOX_TRESHOLD: 0.2TEXT_TRESHOLD: 0.25
google_serper:serper_api_key: ป้อน serper api Keysnippet_cnt: 10prompts:claim_generate: ไปป์ไลน์/prompts/claim_generate.yaml
query_generate: ไปป์ไลน์/พร้อมท์/query_generate.yaml
ตรวจสอบ: ไปป์ไลน์/prompts/verify.yamlรหัสตัวอย่าง
จากไปป์ไลน์.run_pipeline import *pipeline = Pipeline()text = "ร้านกาแฟในภาพชื่อ "Hauptbahnhof""image_path = "./examples/058214af21a03013.jpg"type = "image-to-text"response,claim_list =ไปป์ไลน์ .run(text=text, image_path=image_path, type=type)print(response)print(claim_list)
โปรดอ้างอิงพื้นที่เก็บข้อมูลของเราหากคุณใช้ EasyDetect ในงานของคุณ
@article{chen23factchd, ผู้แต่ง = {Xiang Chen และ Duanzheng Song และ Honghao Gui และ Chengxi Wang และ Ningyu Zhang และ Jiang Yong และ Fei Huang และ Chengfei Lv และ Dan Zhang และ Huajun Chen}, title = {FactCHD: การเปรียบเทียบการตรวจจับภาพหลอนที่ขัดแย้งกับข้อเท็จจริง }, วารสาร = {CoRR}, ปริมาณ = {abs/2310.12086}, ปี = {2023}, url = {https://doi.org/10.48550/arXiv.2310.12086}, doi = {10.48550/ARXIV.2310.12086}, eprinttype = {arXiv}, eprint = {2310.12086}, biburl = {https://dblp.org/rec/journals/corr/abs-2310-12086.bib}, bibsource = {dblp บรรณานุกรมวิทยาศาสตร์คอมพิวเตอร์, https://dblp.org}}@inproceedings{chen-etal-2024- unified-hallucination,title = "Unified Hallucination Detection for Multimodal Large Language Models",ผู้แต่ง = "Chen, Xiang และ Wang, Chenxi และ Xue, Yida และ Zhang, Ningyu และ Yang, Xiaoyan และ Li, Qiang และ Shen, Yue และ Liang, Lei และ Gu, Jinjie และ Chen, Huajun", editor = "Ku, Lun-Wei และ Martins, Andre และ Srikumar, Vivek" ,booktitle = "รายงานการประชุมประจำปีสมาคมภาษาศาสตร์คอมพิวเตอร์ ครั้งที่ 62 (เล่มที่ 1: เอกสารยาว)",เดือน = ส.ค.,ปี = "2024",ที่อยู่ = "กรุงเทพฯ ประเทศไทย",publisher = "สมาคมภาษาศาสตร์คอมพิวเตอร์",url = "https://aclanthology.org/2024.acl-long.178",pages = "3235- -3252",
-เราจะเสนอการบำรุงรักษาระยะยาวเพื่อแก้ไขข้อบกพร่อง แก้ไขปัญหา และตอบสนองคำขอใหม่ ดังนั้นหากคุณมีปัญหาใด ๆ โปรดแจ้งปัญหาให้เราทราบ


