QuillGPT
1.0.0

QuillGPT เป็นการใช้งานบล็อกตัวถอดรหัส GPT ตามสถาปัตยกรรมจากกระดาษ Attention is All You Need โดย Vaswani et อัล ใช้งานใน PyTorch นอกจากนี้ พื้นที่เก็บข้อมูลนี้ยังมีโมเดลที่ได้รับการฝึกล่วงหน้าสองโมเดล ได้แก่ Shakespearean GPT และ Harpoon GPT พร้อมด้วยตุ้มน้ำหนักที่ได้รับการฝึกแล้ว เพื่อความสะดวกในการทดลองและการปรับใช้ จึงมี Streamlit Playground สำหรับการสำรวจโมเดลเหล่านี้แบบโต้ตอบและไมโครเซอร์วิส FastAPI ที่นำไปใช้กับคอนเทนเนอร์ Docker เพื่อการปรับใช้ที่ปรับขนาดได้ นอกจากนี้ คุณยังจะพบสคริปต์ Python สำหรับการฝึกโมเดล GPT ใหม่ๆ และการอนุมานเกี่ยวกับโมเดลเหล่านั้น พร้อมด้วยสมุดบันทึกที่แสดงโมเดลที่ได้รับการฝึกแล้ว เพื่ออำนวยความสะดวกในการเข้ารหัสและถอดรหัสข้อความ จึงมีการใช้โทเค็นไนเซอร์อย่างง่าย สำรวจ QuillGPT เพื่อใช้เครื่องมือเหล่านี้และปรับปรุงโครงการประมวลผลภาษาธรรมชาติของคุณ!
มีโมเดลและตุ้มน้ำหนักที่ได้รับการฝึกล่วงหน้าสองแบบรวมอยู่ในที่เก็บนี้
| คุณสมบัติ | เช็คสเปียร์ GPT | ฉมวก GPT |
|---|---|---|
| พารามิเตอร์ | 10.7 ม | 226 ม |
| ตุ้มน้ำหนัก | ตุ้มน้ำหนัก | ตุ้มน้ำหนัก |
| การกำหนดค่าโมเดล | การกำหนดค่า | การกำหนดค่า |
| ข้อมูลการฝึกอบรม | ข้อความจากบทละครของเช็คสเปียร์ (input.txt) | ข้อความสุ่มจากหนังสือ (corpus.txt) |
| ประเภทการฝัง | การฝังตัวละคร | การฝังตัวละคร |
| สมุดบันทึกการฝึกอบรม | โน๊ตบุ๊ค | โน๊ตบุ๊ค |
| ฮาร์ดแวร์ | NVIDIA T4 | NVIDIA A100 |
| การสูญเสียการฝึกอบรมและการตรวจสอบความถูกต้อง | 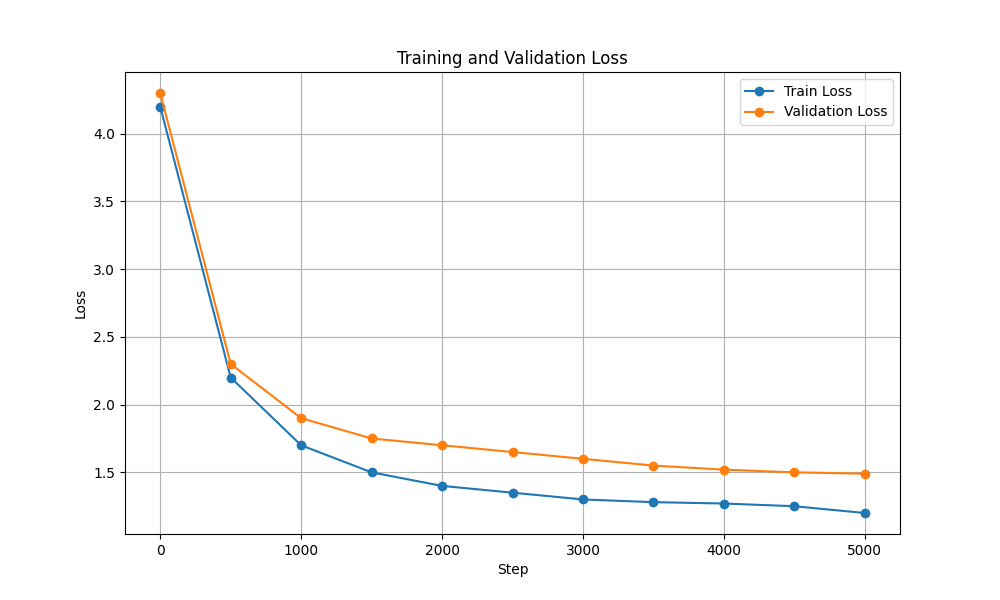 | 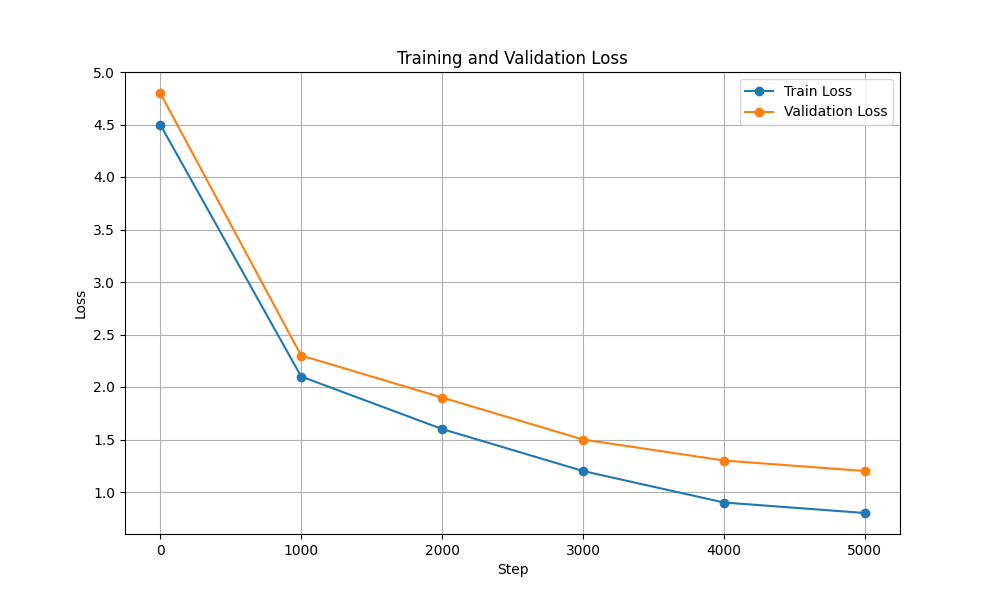 |
หากต้องการรันสคริปต์การฝึกอบรมและการอนุมาน ให้ทำตามขั้นตอนเหล่านี้:
git clone https://github.com/NotShrirang/GPT-From-Scratch.git
cd GPT-From-Scratchpip install -r requirements.txtอย่าลืมดาวน์โหลดตุ้มน้ำหนักสำหรับ Harpoon GPT จากที่นี่ก่อนดำเนินการต่อ!
มันถูกโฮสต์บน Streamlit Cloud Service คุณสามารถเยี่ยมชมได้ผ่านลิงค์ที่นี่
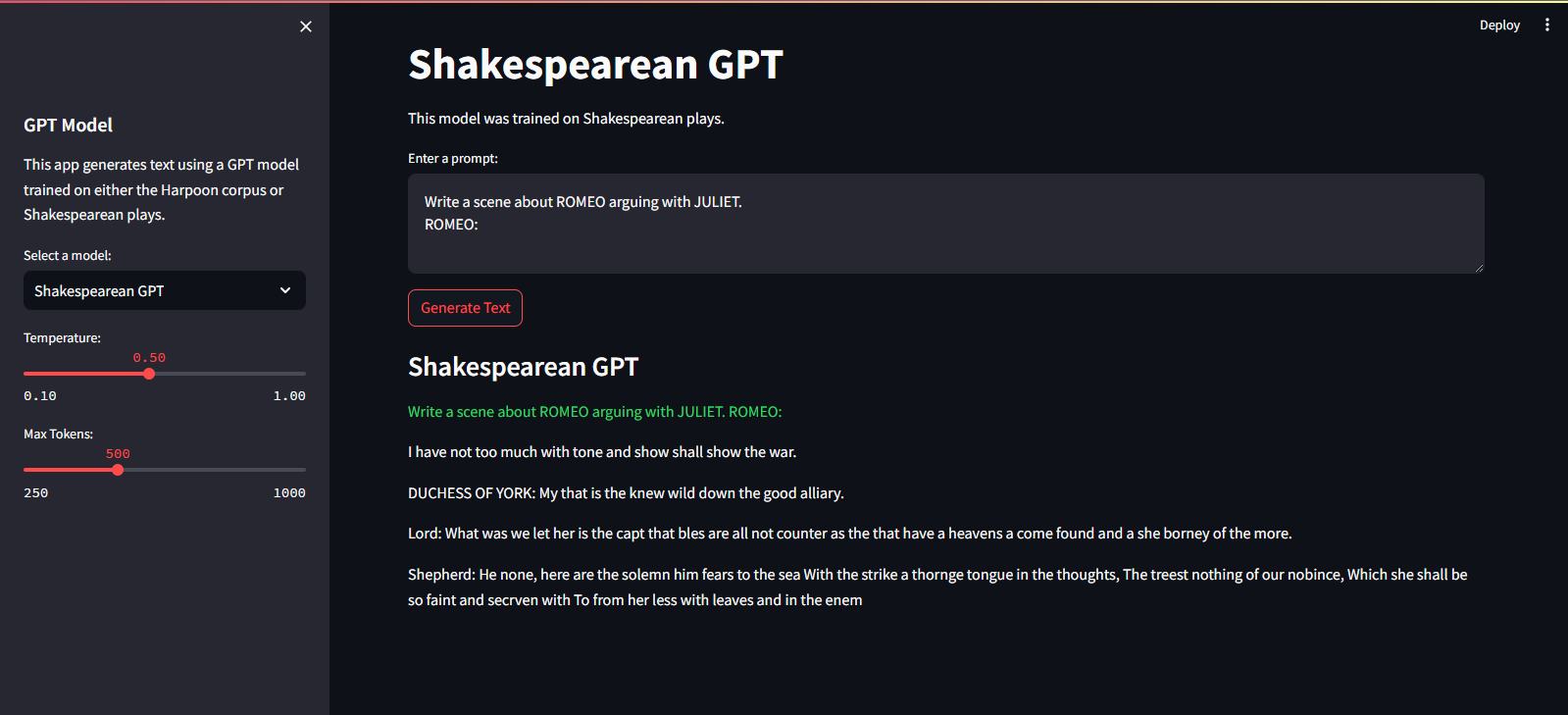
streamlit run app.pypython main.py./run.sh start-dev./run.sh stop-devหากต้องการฝึกโมเดล GPT ให้ทำตามขั้นตอนเหล่านี้:
เตรียมข้อมูล. ใส่ข้อมูลข้อความทั้งหมดลงในไฟล์ .txt ไฟล์เดียวแล้วบันทึก
เขียนการกำหนดค่าสำหรับหม้อแปลงและบันทึกไฟล์
ตัวอย่างเช่น: json { "data_path": "data/corpus.txt", "vocab_size": 135, "batch_size": 32, "block_size": 256, "max_iters": 3000, "eval_interval": 300, "learning_rate": 3e-5, "eval_iters": 50, "n_embd": 1024, "n_head": 12, "n_layer": 18, "dropout": 0.3, }
ฝึกโมเดลโดยใช้สคริปต์ scripts/train_gpt.py
python scripts/train_gpt.py
--config_path config/config.json
--data_path data/corpus.txt
--output_dir trained_models (คุณสามารถเปลี่ยน config_path , data_path และ output_dir ตามความต้องการของคุณ)
output_dir ที่ระบุในคำสั่งหลังการฝึก คุณสามารถใช้โมเดล GPT ที่ได้รับการฝึกสำหรับการสร้างข้อความได้ นี่คือตัวอย่างของการใช้แบบจำลองที่ได้รับการฝึกเพื่อการอนุมาน:
python scripts/inference_gpt.py
--config_path config/shakespearean_config.json
--weights_path weights/GPT_model_char.pt
--max_length 500
--prompt " Once upon a time " 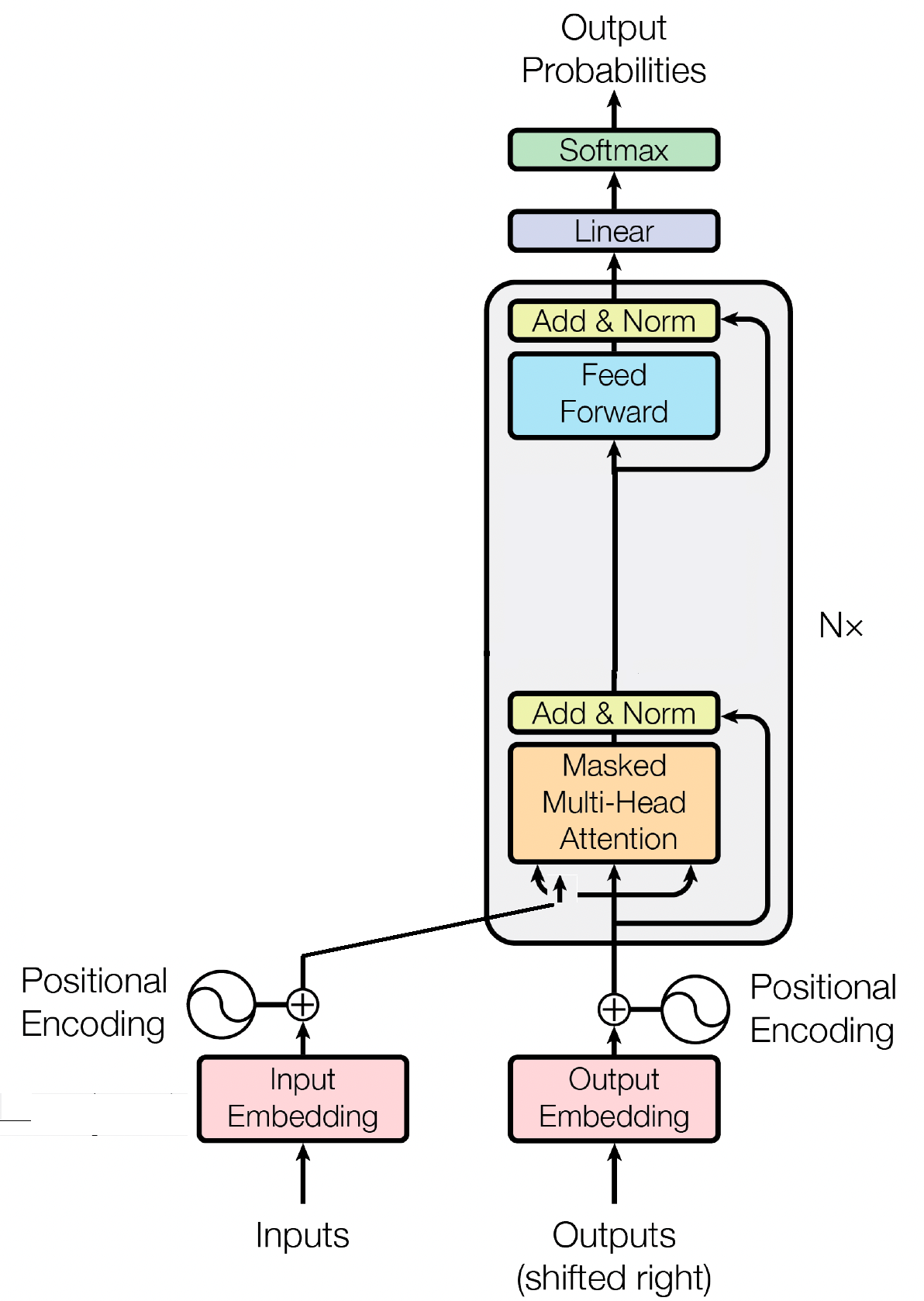
บล็อกตัวถอดรหัสเป็นองค์ประกอบสำคัญของโมเดล GPT (Generative Pre-trained Transformer) ซึ่งเป็นจุดที่ GPT จะสร้างข้อความจริงๆ มันใช้ประโยชน์จากกลไกการเอาใจใส่ตนเองในการประมวลผลลำดับอินพุตและสร้างเอาต์พุตที่สอดคล้องกัน บล็อกตัวถอดรหัสแต่ละบล็อกประกอบด้วยหลายเลเยอร์ รวมถึงเลเยอร์การเอาใจใส่ตัวเอง โครงข่ายประสาทเทียมแบบฟีดฟอร์เวิร์ด และการทำให้เลเยอร์เป็นมาตรฐาน ชั้นการเอาใจใส่ตนเองช่วยให้แบบจำลองชั่งน้ำหนักความสำคัญของคำต่างๆ ในลำดับ โดยจับบริบทและการพึ่งพาโดยไม่คำนึงถึงตำแหน่งของพวกเขา ซึ่งจะทำให้โมเดล GPT สามารถสร้างข้อความที่เกี่ยวข้องกับบริบทได้
การฝังอินพุตมีบทบาทสำคัญในโมเดลที่ใช้หม้อแปลงไฟฟ้า เช่น GPT โดยการแปลงโทเค็นอินพุตให้เป็นการแสดงตัวเลขที่มีความหมาย การฝังเหล่านี้ทำหน้าที่เป็นอินพุตเริ่มต้นสำหรับโมเดล โดยรวบรวมข้อมูลเชิงความหมายเกี่ยวกับคำในลำดับ กระบวนการนี้เกี่ยวข้องกับการแมปแต่ละโทเค็นในลำดับอินพุตกับปริภูมิเวกเตอร์มิติสูง โดยที่โทเค็นที่คล้ายกันจะอยู่ในตำแหน่งที่ใกล้กันมากขึ้น ซึ่งช่วยให้โมเดลเข้าใจความสัมพันธ์ระหว่างคำต่างๆ และเรียนรู้จากข้อมูลอินพุตได้อย่างมีประสิทธิภาพ จากนั้นการฝังอินพุตจะถูกป้อนเข้าไปในเลเยอร์ถัดไปของโมเดลเพื่อการประมวลผลต่อไป
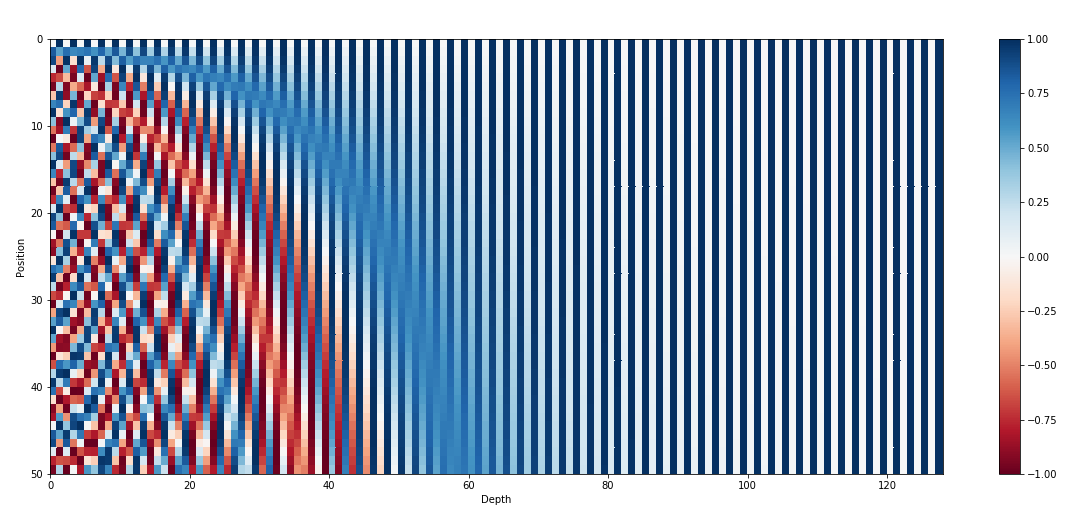
นอกเหนือจากการฝังอินพุตแล้ว การฝังตำแหน่งยังเป็นองค์ประกอบที่สำคัญอีกประการหนึ่งของสถาปัตยกรรมหม้อแปลงไฟฟ้า เช่น GPT เนื่องจากหม้อแปลงขาดข้อมูลโดยธรรมชาติเกี่ยวกับลำดับของโทเค็นในลำดับ การฝังตำแหน่งจึงถูกนำมาใช้เพื่อให้โมเดลมีข้อมูลตำแหน่ง การฝังเหล่านี้เข้ารหัสตำแหน่งของแต่ละโทเค็นภายในลำดับ ทำให้โมเดลสามารถแยกแยะระหว่างโทเค็นตามตำแหน่งได้ ด้วยการรวมการฝังตำแหน่งเข้าด้วยกัน หม้อแปลงไฟฟ้าอย่าง GPT จึงสามารถจับลักษณะลำดับของข้อมูลได้อย่างมีประสิทธิภาพ และสร้างเอาต์พุตที่สอดคล้องกันซึ่งรักษาลำดับที่ถูกต้องของคำในข้อความที่สร้างขึ้น

การเอาใจใส่ตนเอง ซึ่งเป็นกลไกพื้นฐานในโมเดลที่ใช้หม้อแปลงไฟฟ้า เช่น GPT ทำงานโดยการกำหนดคะแนนความสำคัญให้กับคำต่างๆ ตามลำดับ กระบวนการนี้เกี่ยวข้องกับสามขั้นตอนสำคัญ: การคำนวณคะแนนความสนใจ การใช้ softmax เพื่อรับน้ำหนักความสนใจ และสุดท้ายก็รวมน้ำหนักเหล่านี้เข้ากับอินพุตที่ฝังอยู่เพื่อสร้างการนำเสนอตามบริบท โดยแก่นแท้แล้ว การเอาใจใส่ในตนเองทำให้แบบจำลองสามารถมุ่งเน้นไปที่คำที่เกี่ยวข้องมากขึ้น ในขณะที่ไม่เน้นคำที่มีความสำคัญน้อยกว่า อำนวยความสะดวกในการเรียนรู้ที่มีประสิทธิภาพของการพึ่งพาตามบริบทภายในข้อมูลอินพุต กลไกนี้เป็นหัวใจสำคัญในการจับภาพการขึ้นต่อกันในระยะยาวและความแตกต่างตามบริบท ช่วยให้โมเดลหม้อแปลงไฟฟ้าสามารถสร้างลำดับข้อความที่ยาวได้
MIT © Shrirang Mahajan
อย่าลังเลที่จะส่งคำขอดึง สร้างปัญหา หรือกระจายข่าว!
สนับสนุนฉันโดยเพียงแค่นำแสดงโดยพื้นที่เก็บข้อมูลนี้!


