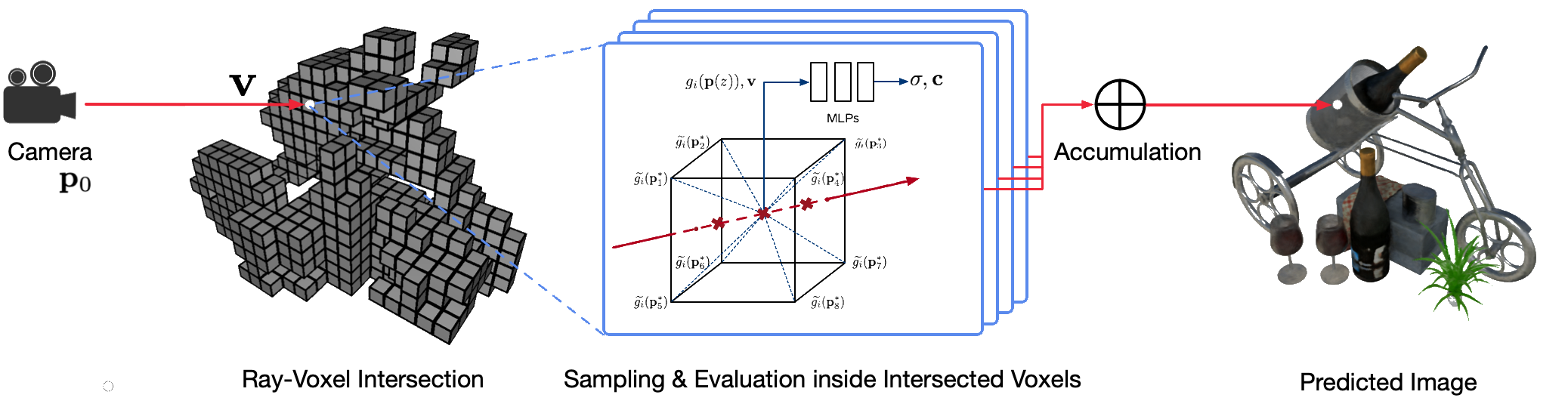
การแสดงมุมมองอิสระของภาพถ่ายที่สมจริงของฉากในโลกแห่งความเป็นจริงโดยใช้เทคนิคคอมพิวเตอร์กราฟิกแบบคลาสสิกถือเป็นปัญหาที่ท้าทาย เนื่องจากต้องใช้ขั้นตอนที่ยากในการจับภาพลักษณะที่ปรากฏและแบบจำลองทางเรขาคณิตที่มีรายละเอียด การแสดงภาพแบบนิวรอลเป็นสาขาใหม่ที่ใช้โครงข่ายประสาทเทียมระดับลึกเพื่อเรียนรู้การแสดงฉากโดยปริยายที่ห่อหุ้มทั้งเรขาคณิตและลักษณะที่ปรากฏจากการสังเกตแบบ 2 มิติ โดยมีหรือไม่มีเรขาคณิตแบบหยาบก็ได้ อย่างไรก็ตาม วิธีการที่มีอยู่ในสาขานี้มักจะแสดงการเรนเดอร์ที่พร่ามัวหรือประสบปัญหาจากกระบวนการเรนเดอร์ที่ช้า เราขอเสนอ Neural Sparse Voxel Fields (NSVF) ซึ่งเป็นการนำเสนอฉากนิวรัลแบบใหม่เพื่อการเรนเดอร์มุมมองฟรีที่รวดเร็วและมีคุณภาพสูง
นี่คือ repo อย่างเป็นทางการสำหรับบทความนี้:
นอกจากนี้เรายังจัดให้มีการดำเนินการอย่างไม่เป็นทางการสำหรับ:
รหัสนี้ถูกนำไปใช้ใน PyTorch โดยใช้เฟรมเวิร์ก fairseq
รหัสได้รับการทดสอบบนระบบต่อไปนี้:
รองรับเฉพาะการเรียนรู้และการเรนเดอร์บน GPU เท่านั้น
หากต้องการติดตั้ง ก่อนอื่นให้โคลน repo นี้และติดตั้งการขึ้นต่อกันทั้งหมด:
pip install -r requirements.txtจากนั้นวิ่ง
pip install --editable ./หรือหากคุณต้องการติดตั้งโค้ดในเครื่อง ให้รัน:
python setup.py build_ext --inplaceคุณสามารถดาวน์โหลดชุดข้อมูลสังเคราะห์และชุดข้อมูลจริงที่ประมวลผลล่วงหน้าซึ่งใช้ในรายงานของเรา โปรดอ้างอิงเอกสารต้นฉบับหากคุณใช้เอกสารใด ๆ ในงานของคุณ
| ชุดข้อมูล | ลิงค์ดาวน์โหลด | หมายเหตุเกี่ยวกับการแยกชุดข้อมูล |
|---|---|---|
| สังเคราะห์-NSVF | ดาวน์โหลด (.zip) | 0_* (การฝึกอบรม) 1_* (การตรวจสอบความถูกต้อง) 2_* (การทดสอบ) |
| สังเคราะห์ NeRF | ดาวน์โหลด (.zip) | 0_* (การฝึกอบรม) 1_* (การตรวจสอบความถูกต้อง) 2_* (การทดสอบ) |
| BlendedMVS | ดาวน์โหลด (.zip) | 0_* (การฝึก) 1_* (การทดสอบ) |
| รถถัง&วัด | ดาวน์โหลด (.zip) | 0_* (การฝึก) 1_* (การทดสอบ) |
หากต้องการเตรียมชุดข้อมูลใหม่ของฉากเดียวสำหรับการฝึกอบรมและการทดสอบ โปรดปฏิบัติตามโครงสร้างข้อมูล:
< dataset_name >
| -- bbox.txt # bounding-box file
| -- intrinsics.txt # 4x4 camera intrinsics
| -- rgb
| -- 0.png # target image for each view
| -- 1.png
...
| -- pose
| -- 0.txt # camera pose for each view (4x4 matrices)
| -- 1.txt
...
[optional]
| -- test_traj.txt # camera pose for free-view rendering demonstration (4N x 4) โดยที่ไฟล์ bbox.txt มีบรรทัดที่อธิบายขอบเขตเริ่มต้นและขนาด voxel:
x_min y_min z_min x_max y_max z_max initial_voxel_size โปรดทราบว่าชื่อไฟล์ของภาพเป้าหมายและไฟล์ท่าโพสของกล้องที่เกี่ยวข้องนั้นไม่จำเป็นต้องเหมือนกันทุกประการ อย่างไรก็ตาม ลำดับของไฟล์ทั้งสองประเภทนี้ (จัดเรียงตามสตริง) จะต้องตรงกัน ชุดข้อมูลจะถูกแบ่งตามดัชนีมุมมอง ตัวอย่างเช่น " train (0..100) , valid (100..200) และ test (200..400) " หมายถึงการดู 100 รายการแรกสำหรับการฝึก การดู 100-199 ครั้งสำหรับการตรวจสอบ และการดู 200-399 ครั้งสำหรับการทดสอบ .
ด้วยชุดข้อมูลของฉากเดียว ( {DATASET} ) เราใช้คำสั่งต่อไปนี้เพื่อฝึกโมเดล NSVF เพื่อสังเคราะห์มุมมองใหม่ที่ 800x800 พิกเซล โดยมีขนาดแบทช์ 4 ภาพต่อ GPU และ 2048 รังสีต่อภาพ ตามค่าเริ่มต้น โค้ดจะตรวจจับ GPU ที่มีอยู่ทั้งหมดโดยอัตโนมัติ
ในตัวอย่างต่อไปนี้ เราใช้สถาปัตยกรรมที่กำหนดไว้ล่วงหน้า nsvf_base พร้อมอาร์กิวเมนต์เฉพาะ:
--no-sampling-at-reader โมเดลจะสุ่มตัวอย่างเฉพาะพิกเซลในพื้นที่ภาพที่ฉายของ voxels แบบกระจายสำหรับการฝึก1/8 (0.125) ของขนาด voxel ซึ่งโดยทั่วไปจะอธิบายไว้ในไฟล์ bbox.txt--use-octree ได้ มันจะสร้าง voxel octree แบบกระจัดกระจายเพื่อเร่งจุดตัดของ ray-voxel โดยเฉพาะเมื่อจำนวน voxel มากกว่า 10000--pruning-every-steps เป็น 2500 โมเดลจะดำเนินการตัดตัวเองทุกๆ 2500 ขั้นตอน--half-voxel-size-at และ --reduce-step-size-at เป็น 5000,25000,75000 ขนาด voxel และขนาดขั้นตอนจะลดลงครึ่งหนึ่งที่ 5k , 25k และ 75k ตามลำดับโปรดทราบว่าแม้ว่าการตั้งค่าพารามิเตอร์ข้างต้นจะใช้กับการทดลองส่วนใหญ่ในรายงาน แต่ก็สามารถปรับพารามิเตอร์เหล่านี้เพื่อให้ได้คุณภาพที่ดีขึ้นได้ นอกจากพารามิเตอร์ข้างต้นแล้ว พารามิเตอร์อื่นๆ ยังสามารถใช้การตั้งค่าเริ่มต้นได้อีกด้วย
นอกจากสถาปัตยกรรม nsvf_base แล้ว คุณสามารถตรวจสอบสถาปัตยกรรมอื่นๆ หรือกำหนดสถาปัตยกรรมของคุณเองได้ในไฟล์ fairnr/models/nsvf.py
python -u train.py ${DATASET}
--user-dir fairnr
--task single_object_rendering
--train-views " 0..100 " --view-resolution " 800x800 "
--max-sentences 1 --view-per-batch 4 --pixel-per-view 2048
--no-preload
--sampling-on-mask 1.0 --no-sampling-at-reader
--valid-views " 100..200 " --valid-view-resolution " 400x400 "
--valid-view-per-batch 1
--transparent-background " 1.0,1.0,1.0 " --background-stop-gradient
--arch nsvf_base
--initial-boundingbox ${DATASET} /bbox.txt
--use-octree
--raymarching-stepsize-ratio 0.125
--discrete-regularization
--color-weight 128.0 --alpha-weight 1.0
--optimizer " adam " --adam-betas " (0.9, 0.999) "
--lr 0.001 --lr-scheduler " polynomial_decay " --total-num-update 150000
--criterion " srn_loss " --clip-norm 0.0
--num-workers 0
--seed 2
--save-interval-updates 500 --max-update 150000
--virtual-epoch-steps 5000 --save-interval 1
--half-voxel-size-at " 5000,25000,75000 "
--reduce-step-size-at " 5000,25000,75000 "
--pruning-every-steps 2500
--keep-interval-updates 5 --keep-last-epochs 5
--log-format simple --log-interval 1
--save-dir ${SAVE}
--tensorboard-logdir ${SAVE} /tensorboard
| tee -a $SAVE /train.log จุดตรวจจะถูกบันทึกไว้ใน {SAVE} คุณสามารถเปิดเทนเซอร์บอร์ดเพื่อตรวจสอบความคืบหน้าของการฝึกได้:
tensorboard --logdir= ${SAVE} /tensorboard --port=10000มีตัวอย่างสคริปต์การฝึกอบรมเพิ่มเติมเพื่อสร้างผลลัพธ์จากรายงานของเราตามตัวอย่าง
เมื่อโมเดลได้รับการฝึกฝนแล้ว คำสั่งต่อไปนี้จะถูกนำมาใช้เพื่อประเมินคุณภาพการเรนเดอร์ในมุมมองทดสอบที่กำหนด {MODEL_PATH}
python validate.py ${DATASET}
--user-dir fairnr
--valid-views " 200..400 "
--valid-view-resolution " 800x800 "
--no-preload
--task single_object_rendering
--max-sentences 1
--valid-view-per-batch 1
--path ${MODEL_PATH}
--model-overrides ' {"chunk_size":512,"raymarching_tolerance":0.01,"tensorboard_logdir":"","eval_lpips":True} ' โปรดทราบว่าเราจะแทนที่ raymarching_tolerance เป็น 0.01 เพื่อเปิดใช้งานการยกเลิกก่อนกำหนดเพื่อเพิ่มความเร็วในการเรนเดอร์
การเรนเดอร์มุมมองอิสระสามารถทำได้เมื่อโมเดลได้รับการฝึกฝนและระบุวิถีการเรนเดอร์ ตัวอย่างเช่น คำสั่งต่อไปนี้ใช้สำหรับการเรนเดอร์ด้วยวิถีวงกลม (ความเร็วเชิงมุม 3 องศา/เฟรม, 15 เฟรมต่อ GPU) ซึ่งจะส่งออกรูปภาพที่แสดงผลต่อการดูและรวมรูปภาพลงในวิดีโอ .mp4 ใน ${SAVE}/output ดังนี้:

ตามค่าเริ่มต้น โค้ดสามารถตรวจจับ GPU ที่มีอยู่ทั้งหมดได้
python render.py ${DATASET}
--user-dir fairnr
--task single_object_rendering
--path ${MODEL_PATH}
--model-overrides ' {"chunk_size":512,"raymarching_tolerance":0.01} '
--render-beam 1 --render-angular-speed 3 --render-num-frames 15
--render-save-fps 24
--render-resolution " 800x800 "
--render-path-style " circle "
--render-path-args " {'radius': 3, 'h': 2, 'axis': 'z', 't0': -2, 'r':-1} "
--render-output ${SAVE} /output
--render-output-types " color " " depth " " voxel " " normal " --render-combine-output
--log-format " simple " โค้ดของเรายังรองรับการเรนเดอร์สำหรับท่าโพสของกล้องที่กำหนดอีกด้วย ตัวอย่างเช่น คำสั่งต่อไปนี้ใช้สำหรับการเรนเดอร์ด้วยท่ากล้องที่กำหนดไว้ในไฟล์ที่ 200-399 ภายใต้โฟลเดอร์ ${DATASET}/pose :
python render.py ${DATASET}
--user-dir fairnr
--task single_object_rendering
--path ${MODEL_PATH}
--model-overrides ' {"chunk_size":512,"raymarching_tolerance":0.01} '
--render-save-fps 24
--render-resolution " 800x800 "
--render-camera-poses ${DATASET} /pose
--render-views " 200..400 "
--render-output ${SAVE} /output
--render-output-types " color " " depth " " voxel " " normal " --render-combine-output
--log-format " simple " โค้ดยังรองรับการเรนเดอร์ด้วยท่ากล้องที่กำหนดไว้ในไฟล์ . .txt โปรดดูตัวอย่างนี้
นอกจากนี้เรายังสนับสนุนการเรียกใช้ Marching Cube เพื่อแยกพื้นผิว ISO ออกเป็นตาข่ายสามเหลี่ยมจากโมเดล NSVF ที่ผ่านการฝึกอบรมแล้วและบันทึกเป็น {SAVE}/{NAME}.ply
python extract.py
--user-dir fairnr
--path ${MODEL_PATH}
--output ${SAVE}
--name ${NAME}
--format ' mc_mesh '
--mc-threshold 0.5
--mc-num-samples-per-halfvoxel 5 นอกจากนี้ยังเป็นไปได้ที่จะส่งออก voxels แบบกระจายที่เรียนรู้โดยการตั้งค่า --format 'voxel_mesh' ไฟล์เอาต์พุต .ply สามารถเปิดได้ด้วยโปรแกรมดู 3 มิติ เช่น MeshLab

NSVF ได้รับอนุญาตจาก MIT ใบอนุญาตนี้ใช้กับโมเดลที่ได้รับการฝึกอบรมล่วงหน้าด้วยเช่นกัน
กรุณาอ้างอิงเป็น
@article { liu2020neural ,
title = { Neural Sparse Voxel Fields } ,
author = { Liu, Lingjie and Gu, Jiatao and Lin, Kyaw Zaw and Chua, Tat-Seng and Theobalt, Christian } ,
journal = { NeurIPS } ,
year = { 2020 }
}

