ขณะสำรวจวิทยาการเข้ารหัสลับ ฉันพบวิดีโอของ Khan Academy ที่ทำให้ฉันสนใจข้อบกพร่องของรหัสลับของ Caesar อันโด่งดัง
เมื่อใดก็ตามที่คุณเขียนจดหมายยาวๆ หรืออีเมลเป็นภาษาอังกฤษ คุณจะทิ้งลายนิ้วมือไว้ข้างหลังโดยไม่ได้ตั้งใจ หากคุณสแกนข้อความที่คุณเขียนและนับความถี่ของตัวอักษรแต่ละตัว คุณจะพบรูปแบบที่ค่อนข้างสม่ำเสมอ 'e' มักจะเป็นตัวอักษรที่เกิดซ้ำมากที่สุดในข้อความทั้งหมด ฉันสุ่มนิทานจากอินเทอร์เน็ตมาทดสอบเรื่องนี้ และผลลัพธ์ที่ฉันได้รับคือสิ่งที่คาดหวังจากเรื่องนี้ 'e' เป็นตัวอักษรที่ได้รับความนิยมมากที่สุดจริงๆ ข้อเท็จจริงนี้ถือเป็นจริงสำหรับข้อความใดๆ ที่ยาวพอ
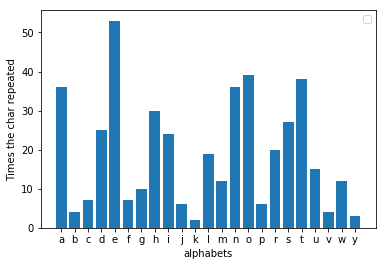
ข้อบกพร่องที่ Al-kindi พบก็คือ เมื่อคุณวิเคราะห์ความถี่ของข้อความที่เข้ารหัส จดหมายอื่นจะเกิดขึ้นซ้ำมากที่สุด หากคุณตรวจสอบว่าตัวอักษรเลื่อนจากสามไปไกลแค่ไหน คุณจะพบค่าที่จะแทนที่ข้อความได้ ตัวอย่างเช่น หาก 'h' เป็นตัวอักษรยอดนิยมในข้อความที่เข้ารหัส การเปลี่ยนแปลงนั้นน่าจะเป็นสาม ตอนนี้การกลับกะทำให้เราสามารถรับข้อความต้นฉบับได้อย่างง่ายดาย ใน decoder.py เมื่อคุณป้อนไฟล์ที่เข้ารหัส มันจะถอดรหัสข้อความและพิมพ์ออกมา ฉันเข้ารหัสนิทานเรื่องเดียวกันโดยเปลี่ยนตัวอักษรเป็นสามตัวอักษร และปรากฎว่า 'h' เป็นตัวอักษรที่ได้รับความนิยมมากที่สุดที่นี่
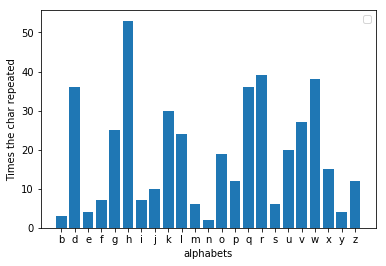
หากต้องการสร้างผลลัพธ์ของการเข้ารหัสของฉันขึ้นมาใหม่ และสำรวจมันด้วยข้อความอื่นๆ นอกเหนือจาก Python คุณต้องติดตั้ง Matplotlib ไว้ด้วย
pip install matplotlibข้อควรจำ : ตัวถอดรหัสทำงานบนหลักการของภาษาศาสตร์และสถิติ ดังนั้นข้อความที่ยาวขึ้นจึงได้ผลลัพธ์ที่แม่นยำยิ่งขึ้น
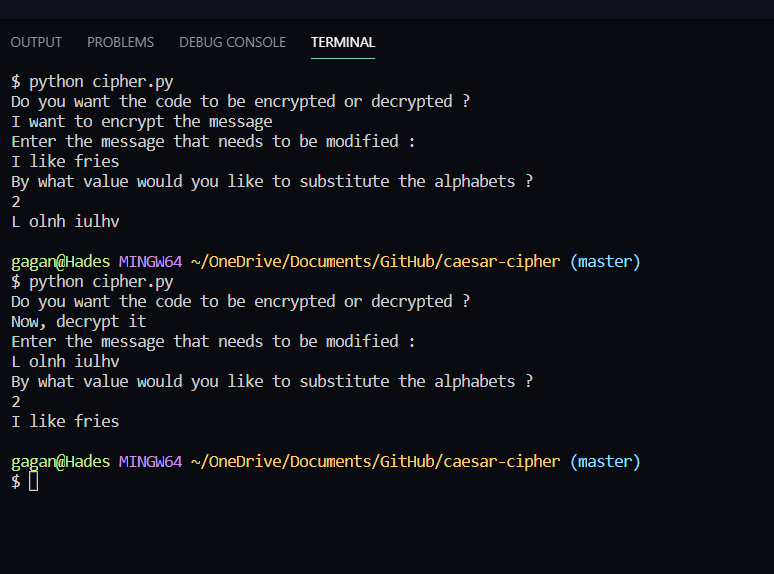
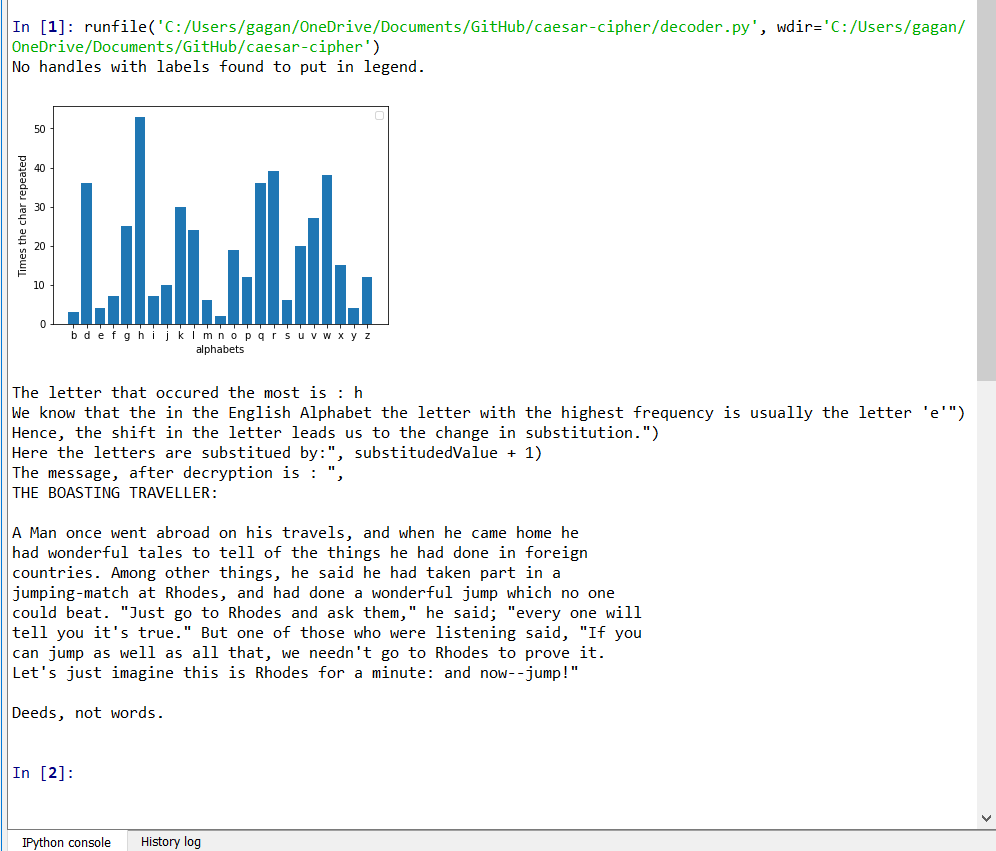
กากันเทวาคีรี © MIT


