self instruct
1.0.0
พื้นที่เก็บข้อมูลนี้ประกอบด้วยโค้ดและข้อมูลสำหรับรายงานการเรียนรู้ด้วยตนเอง ซึ่งเป็นวิธีการในการจัดแนวโมเดลภาษาที่ได้รับการฝึกล่วงหน้าให้สอดคล้องกับคำแนะนำ
การสอนด้วยตนเองเป็นกรอบการทำงานที่ช่วยให้โมเดลภาษาปรับปรุงความสามารถในการปฏิบัติตามคำสั่งภาษาธรรมชาติ ทำได้โดยการใช้รุ่นของแบบจำลองเพื่อสร้างชุดข้อมูลการเรียนการสอนจำนวนมาก ด้วย Self-Instruct คุณสามารถปรับปรุงความสามารถในการปฏิบัติตามคำแนะนำของโมเดลภาษาได้โดยไม่ต้องอาศัยคำอธิบายประกอบแบบแมนนวล
ในช่วงไม่กี่ปีที่ผ่านมา มีความสนใจเพิ่มมากขึ้นในการสร้างแบบจำลองที่สามารถปฏิบัติตามคำสั่งภาษาธรรมชาติเพื่อทำงานที่หลากหลายได้ โมเดลเหล่านี้เรียกว่าโมเดลภาษาที่ "ปรับตามคำสั่ง" ได้แสดงให้เห็นถึงความสามารถในการสรุปงานใหม่ๆ อย่างไรก็ตาม ประสิทธิภาพการทำงานขึ้นอยู่กับคุณภาพและปริมาณของข้อมูลคำสั่งที่มนุษย์เขียนขึ้นอย่างมากซึ่งใช้ในการฝึกอบรม ซึ่งอาจจำกัดด้วยความหลากหลายและความคิดสร้างสรรค์ เพื่อเอาชนะข้อจำกัดเหล่านี้ สิ่งสำคัญคือต้องพัฒนาแนวทางทางเลือกสำหรับการกำกับดูแลโมเดลที่ได้รับการปรับแต่งคำสั่ง และปรับปรุงความสามารถในการปฏิบัติตามคำสั่ง
กระบวนการสอนตนเองเป็นอัลกอริธึมการบูตสแตรปแบบวนซ้ำที่เริ่มต้นด้วยชุดคำสั่งที่เขียนด้วยตนเอง และใช้คำสั่งเหล่านั้นเพื่อแจ้งให้โมเดลภาษาสร้างคำสั่งใหม่และอินสแตนซ์อินพุต-เอาท์พุตที่สอดคล้องกัน จากนั้นรุ่นเหล่านี้จะถูกกรองเพื่อลบรุ่นคุณภาพต่ำหรือรุ่นที่คล้ายกันออก และข้อมูลผลลัพธ์จะถูกเพิ่มกลับไปยังกลุ่มงาน กระบวนการนี้สามารถทำซ้ำได้หลายครั้ง ส่งผลให้มีการรวบรวมข้อมูลการสอนจำนวนมากที่สามารถใช้เพื่อปรับแต่งโมเดลภาษาให้ปฏิบัติตามคำแนะนำได้อย่างมีประสิทธิภาพมากขึ้น
นี่คือภาพรวมของการสอนด้วยตนเอง:
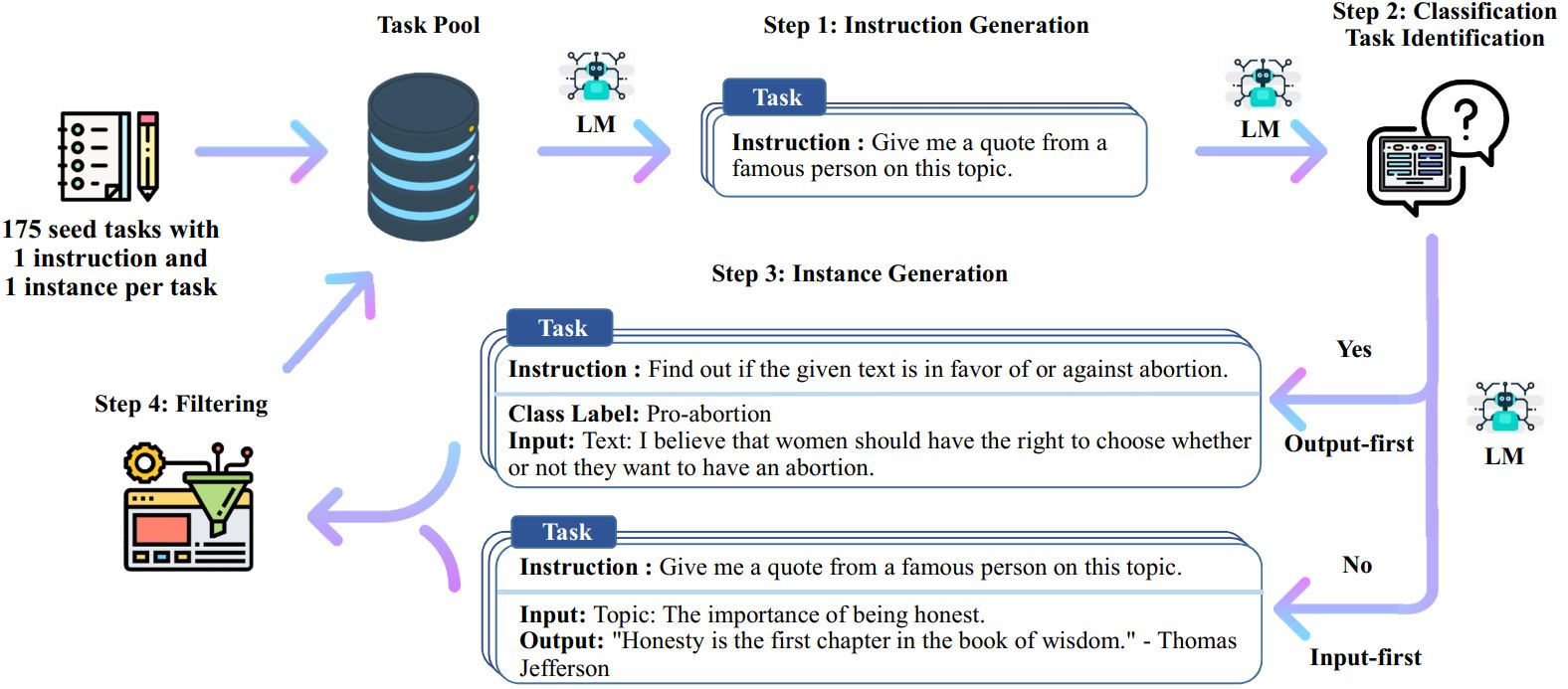
* งานนี้ยังคงอยู่ในระหว่างดำเนินการ เราอาจอัปเดตรหัสและข้อมูลในขณะที่เราดำเนินการ โปรดใช้ความระมัดระวังเกี่ยวกับการควบคุมเวอร์ชัน
เราเผยแพร่ชุดข้อมูลที่มีคำสั่ง 52k ซึ่งจับคู่กับอินพุตและเอาต์พุตอินสแตนซ์ 82K ข้อมูลคำสั่งนี้สามารถใช้เพื่อดำเนินการปรับแต่งคำสั่งสำหรับโมเดลภาษา และทำให้โมเดลภาษาปฏิบัติตามคำแนะนำได้ดีขึ้น ข้อมูลที่สร้างโดยโมเดลทั้งหมดสามารถเข้าถึงได้ใน data/gpt3-generations/batch_221203/all_instances_82K.jsonl ข้อมูลนี้ (+ งาน 175 เมล็ด) ที่จัดรูปแบบใหม่ในรูปแบบการปรับแต่ง GPT3 ที่สะอาดหมดจด (พร้อมท์ + เสร็จสิ้น) data/finetuning/self_instruct_221203 คุณสามารถใช้สคริปต์ใน ./scripts/finetune_gpt3.sh เพื่อปรับแต่ง GPT3 ในข้อมูลนี้
หมายเหตุ : ข้อมูลนี้สร้างขึ้นโดยโมเดลภาษา (GPT3) และมีข้อผิดพลาดหรืออคติบางอย่างอย่างหลีกเลี่ยงไม่ได้ เราวิเคราะห์คุณภาพของข้อมูลตามคำสั่งแบบสุ่ม 200 คำสั่งในรายงานของเรา และพบว่า 46% ของจุดข้อมูลอาจมีปัญหา เราขอแนะนำให้ผู้ใช้ใช้ข้อมูลนี้ด้วยความระมัดระวังและเสนอวิธีการใหม่ในการกรองหรือปรับปรุงข้อบกพร่อง
นอกจากนี้เรายังเปิดตัวชุดงานที่เขียนโดยผู้เชี่ยวชาญ 252 ชุดใหม่และคำแนะนำที่ได้รับแรงบันดาลใจจากแอปพลิเคชันที่มุ่งเน้นผู้ใช้ (แทนที่จะเป็นงาน NLP ที่มีการศึกษาอย่างดี) ข้อมูลนี้ถูกใช้ในส่วนการประเมินโดยมนุษย์ของรายงานการเรียนรู้ด้วยตนเอง โปรดดูการประเมินโดยมนุษย์ README สำหรับรายละเอียดเพิ่มเติม
ในการสร้างข้อมูลการสอนด้วยตนเองโดยใช้งานเริ่มต้นของคุณเองหรือโมเดลอื่นๆ เราจะโอเพ่นซอร์สสคริปต์ของเราสำหรับไปป์ไลน์ทั้งหมดที่นี่ โค้ดปัจจุบันของเราได้รับการทดสอบบนโมเดล GPT3 ที่เข้าถึงได้ผ่าน OpenAI API เท่านั้น
นี่คือสคริปต์สำหรับการสร้างข้อมูล:
# 1. สร้างคำสั่งจากงานเริ่มต้น/scripts/generate_instructions.sh# 2. ระบุว่าคำสั่งนั้นแสดงถึงงานการจัดหมวดหมู่หรือไม่/scripts/is_clf_or_not.sh# 3. สร้างอินสแตนซ์สำหรับแต่ละคำสั่ง/scripts/generate_instances sh# 4 การกรอง การประมวลผล และการจัดรูปแบบใหม่/scripts/prepare_for_finetuning.sh
หากคุณใช้กรอบงานหรือข้อมูล Self-Instruct โปรดอ้างอิงถึงเรา
@misc{selfinstruct, title={Self-Instruct: Aligning Language Model with Self Generated Instructions}, ผู้แต่ง={Wang, Yizhong และ Kordi, Yeganeh และ Mishra, Swaroop และ Liu, Alisa และ Smith, Noah A. และ Khashabi, Daniel และ ฮาจิชิร์ซี, ฮันนาเนห์}, Journal={arXiv preprint arXiv:2212.10560}, ปี={2022}} 

