โค้ดนี้สร้างขึ้นจากโมเดลการเรียนรู้เชิงลึกของรูปภาพที่มีอยู่แล้วไปเป็น BEV โดยอ้างอิงจากรายงานการแปลรูปภาพลงในแผนที่ รหัสนี้เขียนโดยใช้ python 3.7 และได้รับการฝึกอบรมเกี่ยวกับชุดข้อมูล nuScenes โปรดดู ReadMe ของพื้นที่เก็บข้อมูลเพื่อดูข้อมูลอ้างอิงและชุดข้อมูลที่จะติดตั้ง
ขั้นตอนแรกคือการสร้างโฟลเดอร์ชื่อ "translating-images-into-maps-main" และดาวน์โหลดไฟล์ทั้งหมดลงไป จากนั้น เนื่องจากไฟล์มีขนาดใหญ่ จุดตรวจสอบล่าสุดของการฝึกอบรมของเราและชุดข้อมูล mini nuScenes ที่ใช้สำหรับการตรวจสอบจึงสามารถดาวน์โหลดได้จาก Google ไดรฟ์นี้ ควรเพิ่มโฟลเดอร์เหล่านี้ลงในไดเร็กทอรี "translating-images-to-maps-main" โดยตรง
ด้านล่างนี้คือรายการไลบรารีที่จำเป็นสำหรับ Repo นี้:
opencv
numpy
pyquaternion
shapely
lmdb
nuscenes-devkit
pillow
matplotlib
torchvision
descartes
scipy
tensorboard
scikit-image
cv2
หากต้องการใช้ฟังก์ชันของที่เก็บนี้ อาจจำเป็นต้องเปลี่ยนอาร์กิวเมนต์บรรทัดคำสั่งต่อไปนี้:
--name: name of the experiment
--video-name: name of the video file within the video root and without extension
--savedir: directory to save experiments to
--val-interval: number of epochs between validation runs
--root: directory of the repository
--video-root: absolute directory to the video input
--nusc-version: nuscenes version (either “v1.0-mini” or “v1.0-trainval” for the full US dataset)
--train-split: training split (either “train_mini" or “train_roddick” for the full US dataset)
--val-split: validation split (either “val_mini" or “val_roddick” for the full US dataset)
--data-size: percentage of dataset to train on
--epochs: number of epochs to train for
--batch-size: batch size
--cuda-available: environment used (0 for cpu, 1 for cuda)
--iou: iou metric used (0 for iou, 1 for diou)
สำหรับการฝึกโมเดล อาร์กิวเมนต์บรรทัดคำสั่งเหล่านี้สามารถแก้ไขได้:
--optimizer: optimizer for gradient descent to run during training. Default: adam
--lr: learning rate. Default: 5e-5
--momentum: momentum for Stochastic gradient descent. Default: 0.9
--weight-decay: weight decay. Default: 1e-4
--lr-decay: learning rate decay. Default: 0.99
ชุดข้อมูล NuScenes Mini และ Full อยู่ที่ตำแหน่งต่อไปนี้:
นูซีน มินิ:
NuScenes ฉบับเต็มของสหรัฐอเมริกา:
เนื่องจาก NuScene mini และชุดข้อมูลแบบเต็มไม่มีรูปแบบอินพุตรูปภาพที่เหมือนกัน (lmdb หรือ PNG) จึงจำเป็นต้องมีการแก้ไขบางอย่างกับโค้ดเพื่อใช้อย่างใดอย่างหนึ่ง:
mini เป็นเท็จเพื่อใช้ชุดข้อมูลขนาดเล็กตลอดจนเส้นทาง args และการแยกในไฟล์ train.py , validation.py และ inference.py data = nuScenesMaps (
root = args . root ,
split = args . val_split ,
grid_size = args . grid_size ,
grid_res = args . grid_res ,
classes = args . load_classes_nusc ,
dataset_size = args . data_size ,
desired_image_size = args . desired_image_size ,
mini = True ,
gt_out_size = ( 200 , 200 ),
)
loader = DataLoader (
data ,
batch_size = args . batch_size ,
shuffle = False ,
num_workers = 0 ,
collate_fn = src . data . collate_funcs . collate_nusc_s ,
drop_last = True ,
pin_memory = True
)data_loader.py : # if mini:
image_input_key = pickle . dumps ( id , protocol = 3 )
with self . images_db . begin () as txn :
value = txn . get ( key = image_input_key )
image = Image . open ( io . BytesIO ( value )). convert ( mode = 'RGB' )
# else:
# original_nusenes_dir = "/work/scitas-share/datasets/Vita/civil-459/NuScenes_full/US/samples/CAM_FRONT"
# new_cam_path = os.path.join(original_nusenes_dir, Path(cam_path).name)
# image = Image.open(new_cam_path).convert(mode='RGB')สามารถดูจุดตรวจที่ได้รับการฝึกไว้ล่วงหน้าได้ที่นี่:
จุดตรวจสอบจะต้องถูกเก็บไว้ภายใน /pretrained_models/27_04_23_11_08 จากไดเร็กทอรีรากของที่เก็บนี้ หากคุณต้องการโหลดจากไดเร็กทอรีอื่น โปรดเปลี่ยนอาร์กิวเมนต์ต่อไปนี้:
- - savedir = "pretrained_models" # Careful, this path is relative in validation.py but global in train.py
- - name = "27_04_23_11_08"หากต้องการฝึก scitas คุณต้องเปิดสคริปต์ต่อไปนี้จากไดเร็กทอรีราก:
sbatch job.script.sh
วิธีฝึกซีพียูในเครื่อง:
python3 train.py
ตรวจสอบให้แน่ใจว่าได้ปรับสคริปต์ด้วย args บรรทัดคำสั่งของคุณ
วิธีตรวจสอบประสิทธิภาพของโมเดลบน scitas:
sbatch job.validate.sh
วิธีฝึกซีพียูในเครื่อง:
python3 validate.py
ตรวจสอบให้แน่ใจว่าได้ปรับสคริปต์ด้วย args บรรทัดคำสั่งของคุณ
หากต้องการอนุมานวิดีโอเกี่ยวกับ scitas:
sbatch job.evaluate.sh
วิธีฝึกซีพียูในเครื่อง:
python3 inference.py
ตรวจสอบให้แน่ใจว่าได้ปรับสคริปต์ด้วย args บรรทัดคำสั่งของคุณ โดยเฉพาะ:
--batch-size // 1 for the test videos
--video-name
--video-root
โปรเจ็กต์นี้จัดทำขึ้นในบริบทของหลักสูตรการเรียนรู้เชิงลึกสำหรับยานยนต์อัตโนมัติ CIVIL-459 ซึ่งสอนโดยศาสตราจารย์ Alexandre Alahi ที่ EPFL เราได้รับการดูแลโดยนักศึกษาปริญญาเอก Yuejiang Liu เป้าหมายหลักของโครงการของหลักสูตรนี้คือการพัฒนาโมเดลการเรียนรู้เชิงลึกที่สามารถนำไปใช้บนระบบขับเคลื่อนอัตโนมัติของ Tesla ได้ สำหรับกลุ่มของเรา เราได้พิจารณาถึงการเปลี่ยนแปลงจากภาพจากกล้องตาข้างเดียวไปเป็นภาพจากมุมสูง ซึ่งสามารถทำได้โดยใช้การแบ่งส่วนความหมายเพื่อจำแนกองค์ประกอบต่างๆ เช่น รถยนต์ ทางเท้า คนเดินเท้า และเส้นขอบฟ้า
ในระหว่างการวิจัยเกี่ยวกับภาพจากตาข้างเดียวไปจนถึงโมเดลการเรียนรู้เชิงลึกของ BEV เราสังเกตเห็นว่าข้อมูลเกี่ยวกับคนเดินถนนสูญหายไปในระหว่างการแบ่งส่วน ส่งผลให้การจำแนกประเภทไม่ดี ดังที่เห็นในภาพด้านล่าง เมื่อประเมินแล้ว แบบจำลองที่เราเลือกมีค่าเฉลี่ย 25.7% IoU (จุดตัดเหนือยูเนียน) มากกว่า 14 คลาสของออบเจ็กต์บนชุดข้อมูล nuScenes ความแม่นยำในการคาดการณ์สำหรับผู้ขับขี่นั้นดี (74.5%) ค่อนข้างต่ำสำหรับจักรยาน สิ่งกีดขวาง และรถพ่วง อย่างไรก็ตาม ความแม่นยำในการทำนายสำหรับคนเดินเท้า (9.5%) ยังต่ำเกินไป ความแม่นยำต่ำเช่นนี้อาจทำให้เกิดอุบัติเหตุได้หากมีคนข้ามถนนโดยไม่ได้อยู่บนทางข้าม

ข้อมูลเพิ่มเติมเกี่ยวกับการวิจัยของเราสามารถพบได้ในไดรฟ์
เนื่องจากการตรวจจับคนเดินถนนที่ไม่ดีดูเหมือนจะเป็นปัญหาเร่งด่วนที่สุดสำหรับโมเดลที่ได้รับการฝึกอบรมในปัจจุบัน เราจึงมุ่งที่จะปรับปรุงความแม่นยำโดยพิจารณาจากฟังก์ชันการสูญเสียที่เหมาะสมยิ่งขึ้น และฝึกอบรมโมเดลใหม่บนชุดข้อมูล nuScenes
โมเดลที่เราสร้างขึ้นนั้นได้รับการฝึกฝนโดยใช้
อีกประเด็นหนึ่งด้วย
ที่
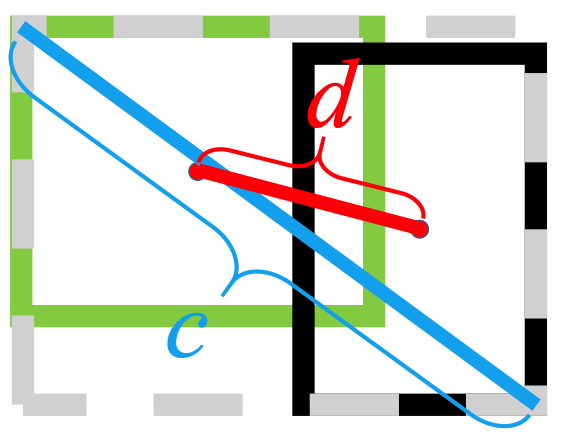
ใช้บรรทัดฐาน L2 เพื่อลดระยะห่างระหว่างกล่องที่คาดการณ์และกล่องเป้าหมาย และมาบรรจบกันเร็วกว่ามาก

การยืดแนวนอน

การยืดแนวตั้ง
นอกจากนี้ การสูญเสีย DIOU ยังทำให้เกิดคำศัพท์ที่ทำให้เป็นมาตรฐานซึ่งส่งเสริมการบรรจบกันที่ราบรื่น
ดังที่เห็นในภาพต่อไปนี้.
หลังจากขั้นตอนการวิจัย เราได้ดำเนินการ bbox_overlaps_diou ในไฟล์ /src/utils.py โดยใช้
จากนั้นฟังก์ชันนี้จะใช้ในการคำนวณหลายสเกล compute_multiscale_iou ของไฟล์เดียวกัน สำหรับแต่ละชั้นเรียน iou ) จะถูกคำนวณตามขนาดแบตช์ ผลลัพธ์ของฟังก์ชันคือพจนานุกรม iou_dict ที่มีหลายสเกล
จากนั้นเราใช้ค่าเหล่านี้ใน train.py โดยที่ val-interval ค่าเหล่านี้ยังใช้ใน validation.py ซึ่งใช้ในการแสดงความสูญเสียและ
เราฝึกโมเดลบนชุดข้อมูล NuScenes โดยเริ่มจาก checkpoint-008.pth.gz ครั้งหนึ่งกับ
การสนับสนุนอีกประการหนึ่งคือรูปแบบใหม่ของการแสดงภาพเพื่อแยกแยะคลาสได้ดีขึ้นด้วยป้ายกำกับและค่า IoU ที่เกี่ยวข้องทั้งหมด สิ่งนี้ถูกนำไปใช้ในไฟล์ visualization.py
สุดท้ายนี้ เราได้ดำเนินการเพื่อใช้โหมดที่จะรับวิดีโอ .mp4 เป็นอินพุต และจะแยกย่อยออกเป็นเฟรมภาพแต่ละเฟรม สิ่งเหล่านี้จะถูกประเมินโดยแบบจำลอง และเราสามารถเห็นภาพผลลัพธ์ของการแบ่งส่วนในไฟล์ inference.py
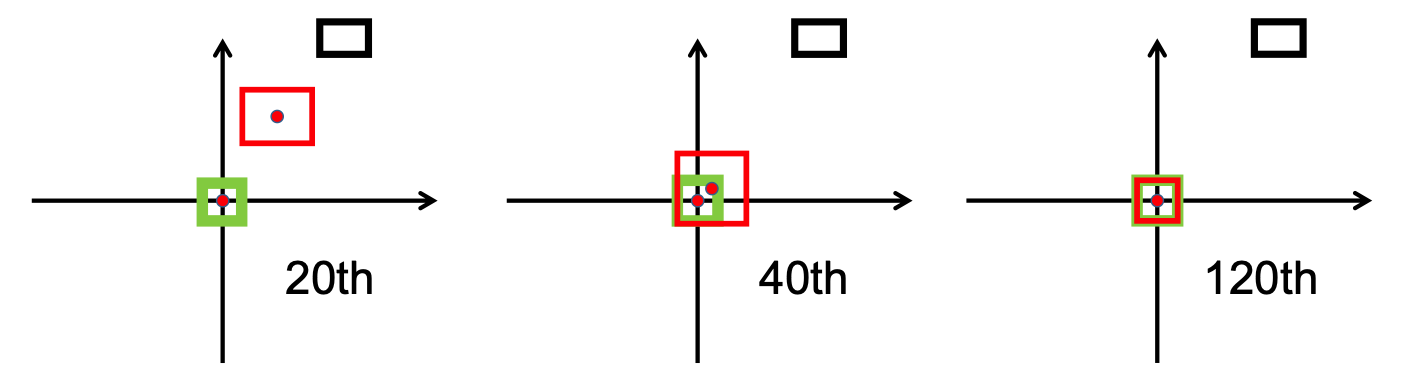
เพื่อให้มีแนวคิดเบื้องต้นเกี่ยวกับกลยุทธ์การฝึกอบรมของโมเดลนี้ ขั้นแรกเราจึงตัดสินใจฝึกโมเดลนี้บนชุดข้อมูลขนาดเล็กของ NuScenes เริ่มต้นจาก checkpoint-008.pth.gz เราสามารถฝึกโมเดลสองโมเดลที่แตกต่างกันในตัววัด IoU ที่ใช้ (IoU สำหรับตัวหนึ่งและ DIoU สำหรับอีกตัวหนึ่ง) ผลลัพธ์ที่ได้รับจาก NuScenes มินิแบทช์หลังการฝึกอบรม 10 ครั้งแสดงไว้ในตารางด้านล่าง

หลังจากดูผลลัพธ์เหล่านี้แล้ว เราสังเกตว่ากลุ่มคนเดินเท้าซึ่งเราใช้ตามสมมติฐานของเรา ไม่ได้นำเสนอผลลัพธ์ที่สรุปได้แต่อย่างใด ดังนั้นเราจึงสรุปว่าชุดข้อมูลขนาดเล็กไม่เพียงพอสำหรับความต้องการของเรา และตัดสินใจย้ายการฝึกอบรมของเราไปยังชุดข้อมูลเต็มรูปแบบบน Scitas
หลังจากฝึกฝนโมเดลใหม่ของเรา (ด้วย DIoU หรือ IoU) จาก checkpoint-008.pth.gz สำหรับ 8 ยุคใหม่ เราก็สังเกตเห็นผลลัพธ์ที่น่าหวัง โดยมีเป้าหมายเพื่อเปรียบเทียบประสิทธิภาพของโมเดลที่ได้รับการฝึกอบรมใหม่เหล่านี้ เราได้ดำเนินการขั้นตอนการตรวจสอบชุดข้อมูลขนาดเล็ก การแสดงภาพผลลัพธ์สำหรับรูปภาพของชุดข้อมูลนี้มีดังต่อไปนี้
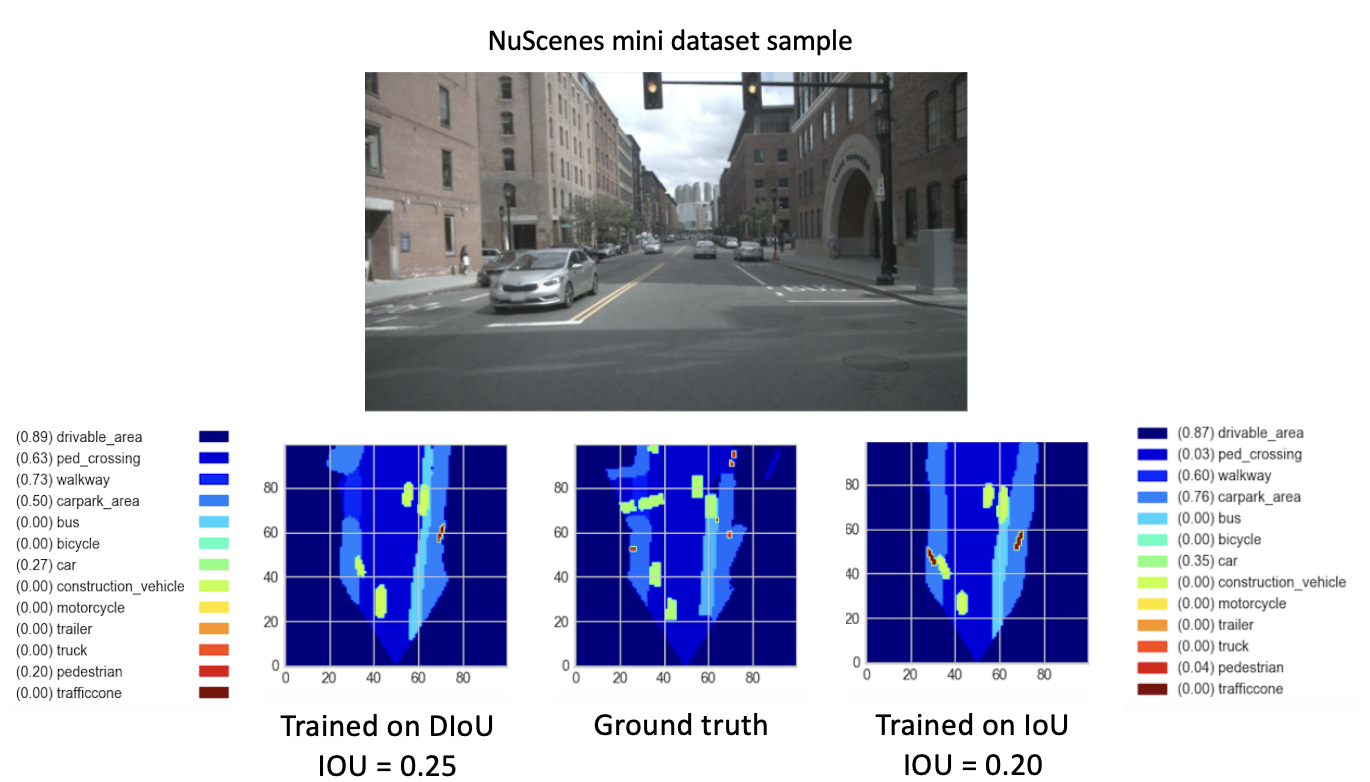
นี่.

ในที่สุดผลลัพธ์เหล่านี้ก็แสดงให้เห็นถึงประสิทธิภาพที่ดีขึ้นของ
ตอนนี้เรามีโมเดลที่ผ่านการฝึกอบรมแล้ว เราสามารถใช้โมเดลดังกล่าวเพื่อคาดการณ์ BEV โดยใช้รูปภาพหรือวิดีโออินพุตใดๆ ได้ แม้ว่าความทะเยอทะยานของเราคือการนำวิธีการของเราไปใช้ในการสาธิตครั้งสุดท้ายของหลักสูตร แต่น่าเสียดายที่แผนที่จากมุมสูงที่อนุมานได้นั้นมีประสิทธิภาพไม่เพียงพอ รูปด้านล่างแสดงผลการอนุมานของวิดีโอทดสอบรายการใดรายการหนึ่งที่มีให้ (ดูวิดีโอทดสอบ)

เราเชื่อว่าการขาดประสิทธิภาพสำหรับการอนุมานนี้เกิดจากพารามิเตอร์ต่อไปนี้:
แม้ว่าทางผ่านจาก
ทางเลือกหนึ่งคือการดำเนินการ
ที่
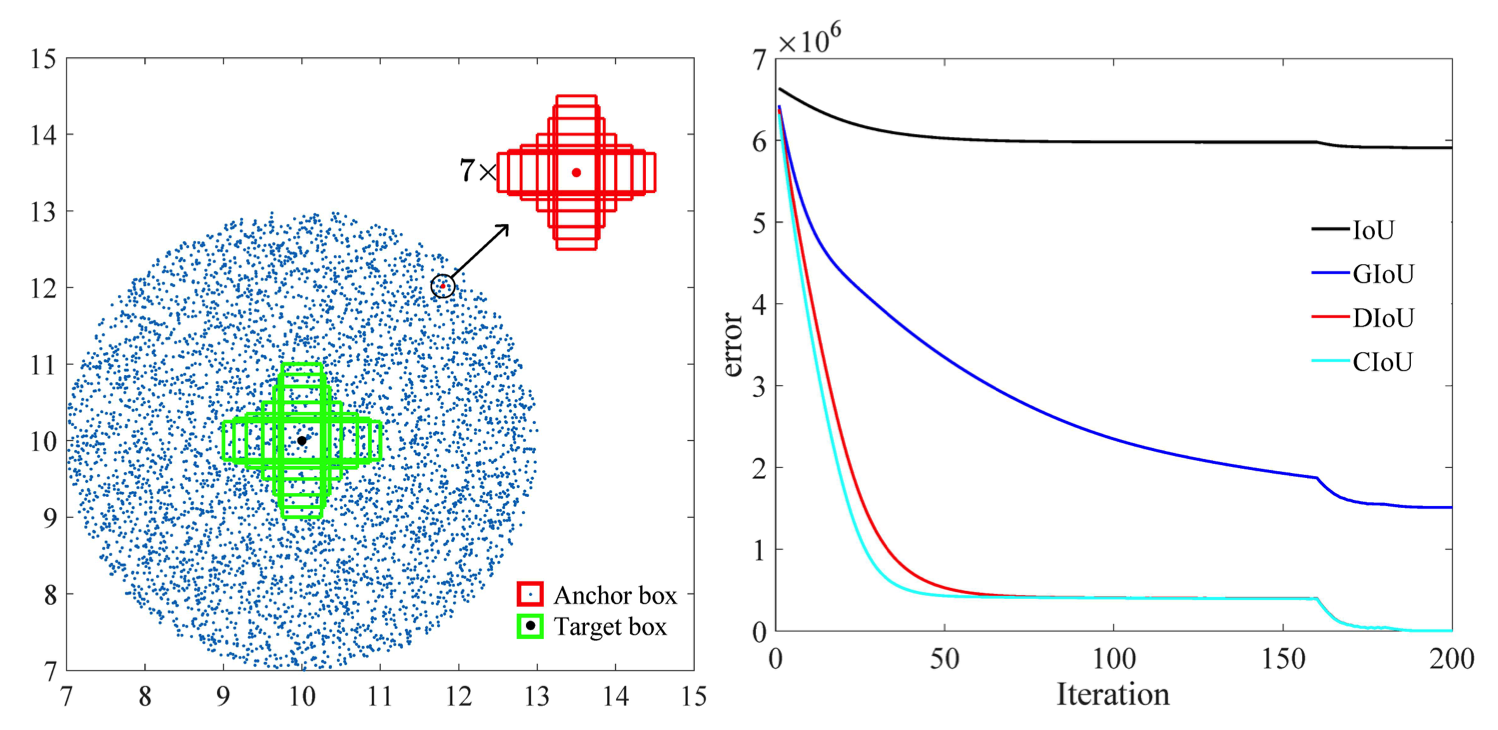
นอกจากนี้ ตามการวิจัยที่ทำโดยบทความนี้ [2] ข้อผิดพลาดการถดถอยสำหรับ CIOU ลดลงเร็วกว่าส่วนที่เหลือ และจะมาบรรจบกันที่
อีกทางเลือกหนึ่งคือการฝึกอบรมชุดข้อมูลที่อุดมไปด้วยสภาพแวดล้อมที่มีผู้คนพลุกพล่านเพื่อให้เป็นตัวแทนคนเดินถนนและจักรยานได้ดีขึ้น
สุดท้ายนี้ เพื่อตรวจสอบความถูกต้องของสมมติฐานของเราอย่างแท้จริง จึงสามารถดำเนินการตรวจสอบชุดข้อมูล NuScenes แบบเต็มได้ และสามารถเปรียบเทียบ IoU ทางเท้าของทั้งสองรุ่นได้
(1) Zhaohui Zheng, Ping Wang, Wei Liu, Jinze Li, Rongguang Ye, Dongwei Ren (2020) การสูญเสียระยะทาง-IoU: การเรียนรู้ที่เร็วขึ้นและดีขึ้นสำหรับการถดถอยกรอบขอบเขต https://arxiv.org/pdf/1911.08287.pdf
(2) Zhaohui Zheng, Ping Wang, Dongwei Ren, Wei Liu, Rongguang Ye, Qinghua Hu, Wangmeng Zuo (2021) การเพิ่มประสิทธิภาพปัจจัยทางเรขาคณิตในการเรียนรู้แบบจำลองและการอนุมานสำหรับการตรวจจับวัตถุและการแบ่งส่วนอินสแตนซ์ https://arxiv.org/pdf/2005.03572.pdf


