EasyOCR
v1.7.2
OCR ที่พร้อมใช้งานพร้อมภาษาที่รองรับมากกว่า 80 ภาษาและสคริปต์การเขียนยอดนิยมทั้งหมด รวมถึง: ละติน จีน อารบิก เทวนาครี ซีริลลิก ฯลฯ
ลองสาธิตบนเว็บไซต์ของเรา
รวมเข้ากับ Huggingface Spaces ? โดยใช้กราดิโอ ลองใช้การสาธิตเว็บ:
24 กันยายน 2567 - เวอร์ชัน 1.7.2
อ่านบันทึกประจำรุ่นทั้งหมด



ติดตั้งโดยใช้ pip
สำหรับเวอร์ชันเสถียรล่าสุด:
pip install easyocrสำหรับรุ่นการพัฒนาล่าสุด:
pip install git+https://github.com/JaidedAI/EasyOCR.git หมายเหตุ 1: สำหรับ Windows โปรดติดตั้ง torch และ torchvision ก่อนโดยทำตามคำแนะนำอย่างเป็นทางการที่นี่ https://pytorch.org บนเว็บไซต์ pytorch ต้องแน่ใจว่าได้เลือกเวอร์ชัน CUDA ที่ถูกต้องที่คุณมี หากคุณต้องการทำงานในโหมด CPU เท่านั้น ให้เลือก CUDA = None
หมายเหตุ 2: เรายังจัดเตรียม Dockerfile ไว้ที่นี่ด้วย
import easyocr
reader = easyocr . Reader ([ 'ch_sim' , 'en' ]) # this needs to run only once to load the model into memory
result = reader . readtext ( 'chinese.jpg' )ผลลัพธ์จะอยู่ในรูปแบบรายการ แต่ละรายการแสดงถึงกรอบขอบเขต ข้อความที่ตรวจพบ และระดับความมั่นใจ ตามลำดับ
[([[189, 75], [469, 75], [469, 165], [189, 165]], '愚园路' , 0.3754989504814148),
([[86, 80], [134, 80], [134, 128], [86, 128]], '西' , 0.40452659130096436),
([[517, 81], [565, 81], [565, 123], [517, 123]], '东' , 0.9989598989486694),
([[78, 126], [136, 126], [136, 156], [78, 156]], ' 315 ' , 0.8125889301300049),
([[514, 126], [574, 126], [574, 156], [514, 156]], ' 309 ' , 0.4971577227115631),
([[226, 170], [414, 170], [414, 220], [226, 220]], ' Yuyuan Rd. ' , 0.8261902332305908),
([[79, 173], [125, 173], [125, 213], [79, 213]], ' W ' , 0.9848111271858215),
([[529, 173], [569, 173], [569, 213], [529, 213]], ' E ' , 0.8405593633651733)] หมายเหตุ 1: ['ch_sim','en'] คือรายการภาษาที่คุณต้องการอ่าน คุณสามารถส่งผ่านหลายภาษาพร้อมกันได้ แต่ไม่สามารถใช้ทุกภาษาร่วมกันได้ ภาษาอังกฤษเข้ากันได้กับทุกภาษา และภาษาที่ใช้อักขระร่วมกันมักจะเข้ากันได้
หมายเหตุ 2: แทนที่จะส่งพาธไฟล์ chinese.jpg คุณสามารถส่งออบเจ็กต์รูปภาพ OpenCV (อาร์เรย์ numpy) หรือไฟล์รูปภาพเป็นไบต์ได้ URL ไปยังรูปภาพดิบก็เป็นที่ยอมรับเช่นกัน
หมายเหตุ 3: line reader = easyocr.Reader(['ch_sim','en']) ใช้สำหรับการโหลดโมเดลลงในหน่วยความจำ ต้องใช้เวลาพอสมควร แต่ต้องดำเนินการเพียงครั้งเดียวเท่านั้น
คุณยังสามารถตั้งค่า detail=0 เพื่อให้เอาต์พุตง่ายขึ้นได้
reader . readtext ( 'chinese.jpg' , detail = 0 )ผลลัพธ์:
[ '愚园路' , '西' , '东' , ' 315 ' , ' 309 ' , ' Yuyuan Rd. ' , ' W ' , ' E ' ]น้ำหนักโมเดลสำหรับภาษาที่เลือกจะถูกดาวน์โหลดโดยอัตโนมัติ หรือคุณสามารถดาวน์โหลดได้ด้วยตนเองจากศูนย์กลางโมเดลและใส่ไว้ในโฟลเดอร์ '~/.EasyOCR/model'
ในกรณีที่คุณไม่มี GPU หรือ GPU ของคุณมีหน่วยความจำเหลือน้อย คุณสามารถรันโมเดลในโหมด CPU-only ได้โดยเพิ่ม gpu=False
reader = easyocr . Reader ([ 'ch_sim' , 'en' ], gpu = False )สำหรับข้อมูลเพิ่มเติม โปรดอ่านบทช่วยสอนและเอกสารประกอบ API
$ easyocr -l ch_sim en -f chinese.jpg --detail=1 --gpu=Trueสำหรับรูปแบบการจดจำ อ่านที่นี่
สำหรับโมเดลการตรวจจับ (CRAFT) อ่านที่นี่
reader = easyocr . Reader ([ 'en' ], detection = 'DB' , recognition = 'Transformer' )แนวคิดก็คือสามารถเสียบโมเดลที่ล้ำสมัยเข้ากับ EasyOCR ได้ มีอัจฉริยะจำนวนมากที่พยายามสร้างโมเดลการตรวจจับ/การจดจำที่ดีขึ้น แต่เราไม่ได้พยายามเป็นอัจฉริยะที่นี่ เราแค่อยากให้ผลงานของพวกเขาเข้าถึงได้โดยสาธารณะอย่างรวดเร็ว ... ฟรี (เราเชื่อว่าอัจฉริยะส่วนใหญ่ต้องการให้งานของตนสร้างผลกระทบเชิงบวกอย่างรวดเร็ว/ใหญ่ที่สุดเท่าที่จะเป็นไปได้) ไปป์ไลน์ควรมีลักษณะคล้ายแผนภาพด้านล่าง ช่องสีเทาเป็นตัวยึดสำหรับโมดูลสีฟ้าอ่อนที่เปลี่ยนแปลงได้
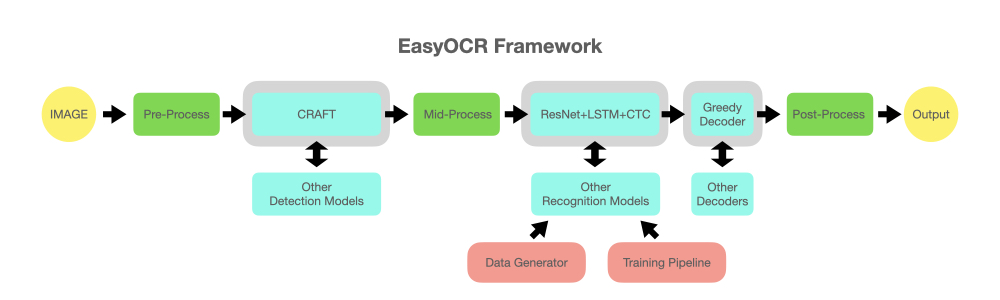
โปรเจ็กต์นี้อิงจากการวิจัยและโค้ดจากเอกสารหลายฉบับและแหล่งเก็บข้อมูลโอเพ่นซอร์ส
การดำเนินการเรียนรู้เชิงลึกทั้งหมดอิงจาก Pytorch
การดำเนินการตรวจจับใช้อัลกอริธึม CRAFT จากพื้นที่เก็บข้อมูลอย่างเป็นทางการนี้และเอกสารของพวกเขา (ขอบคุณ @YoungminBaek จาก @clovaai) เรายังใช้แบบจำลองที่ได้รับการฝึกล่วงหน้าด้วย สคริปต์การฝึกอบรมจัดทำโดย @gmuffiness
โมเดลการจดจำคือ CRNN (กระดาษ) ประกอบด้วย 3 องค์ประกอบหลัก: การแยกคุณสมบัติ (ขณะนี้เรากำลังใช้ Resnet) และ VGG, การติดฉลากลำดับ (LSTM) และการถอดรหัส (CTC) ไปป์ไลน์การฝึกอบรมสำหรับการดำเนินการจดจำเป็นเวอร์ชันที่ได้รับการปรับเปลี่ยนของเฟรมเวิร์กมาตรฐานการรู้จำข้อความเชิงลึก (ขอบคุณ @ ku21fan จาก @clovaai) พื้นที่เก็บข้อมูลนี้เป็นอัญมณีที่สมควรได้รับการยอมรับมากขึ้น
รหัสค้นหาบีมขึ้นอยู่กับพื้นที่เก็บข้อมูลนี้และบล็อกของเขา (ขอบคุณ @githubharald)
การสังเคราะห์ข้อมูลจะขึ้นอยู่กับ TextRecognitionDataGenerator (ขอบคุณ @เบลวาล)
และอ่านเรื่องราวดีๆ เกี่ยวกับ CTC จาก distill.pub ที่นี่
มาพัฒนามนุษยชาติด้วยกันด้วยการทำให้ทุกคนเข้าถึง AI ได้!
ร่วมบริจาคได้ 3 ช่องทาง:
Coder: โปรดส่ง PR สำหรับข้อบกพร่อง/การปรับปรุงเล็กๆ น้อยๆ สำหรับเรื่องที่ใหญ่กว่า โปรดปรึกษาเราโดยเปิดประเด็นก่อน มีรายการปัญหาข้อบกพร่อง/การปรับปรุงที่เป็นไปได้ที่ติดแท็ก 'PR WELCOME'
ผู้ใช้: บอกเราว่า EasyOCR มีประโยชน์ต่อคุณ/องค์กรของคุณอย่างไรเพื่อส่งเสริมการพัฒนาต่อไป โพสต์กรณีความล้มเหลวในส่วนปัญหาเพื่อช่วยปรับปรุงโมเดลในอนาคต
ผู้นำด้านเทคโนโลยี/กูรู: หากคุณพบว่าห้องสมุดนี้มีประโยชน์ โปรดบอกต่อ! (ดูโพสต์ของ Yann Lecun เกี่ยวกับ EasyOCR)
หากต้องการขอภาษาใหม่ เราต้องการให้คุณส่ง PR พร้อมไฟล์ 2 ไฟล์ต่อไปนี้:
หากภาษาของคุณมีองค์ประกอบที่เป็นเอกลักษณ์ (เช่น 1. อารบิก: ตัวอักษรเปลี่ยนรูปแบบเมื่อแนบชิดกัน + เขียนจากขวาไปซ้าย 2. ไทย: ตัวอักษรบางตัวต้องอยู่เหนือบรรทัดและบางตัวอยู่ด้านล่าง) โปรดให้ความรู้แก่เราอย่างดีที่สุด ตามความสามารถของคุณและ/หรือให้ลิงก์ที่เป็นประโยชน์ สิ่งสำคัญคือต้องดูแลรายละเอียดเพื่อให้ได้ระบบที่ใช้งานได้จริง
สุดท้ายนี้ โปรดเข้าใจว่าลำดับความสำคัญของเราจะต้องไปที่ภาษายอดนิยมหรือชุดภาษาที่ใช้ตัวละครร่วมกันส่วนใหญ่ (และบอกเราด้วยว่านี่เป็นกรณีของภาษาของคุณหรือไม่) เราต้องใช้เวลาอย่างน้อยหนึ่งสัปดาห์ในการพัฒนาโมเดลใหม่ ดังนั้นคุณอาจต้องรอสักพักกว่าโมเดลใหม่จะออก
ดูรายการภาษาที่กำลังพัฒนา
เนื่องจากทรัพยากรมีจำกัด ปัญหาที่มีอายุมากกว่า 6 เดือนจะถูกปิดโดยอัตโนมัติ โปรดเปิดปัญหาอีกครั้งหากเป็นปัญหาร้ายแรง
สำหรับการสนับสนุนระดับองค์กร Jaided AI นำเสนอบริการเต็มรูปแบบสำหรับระบบ OCR/AI แบบกำหนดเองตั้งแต่การใช้งาน การฝึกอบรม/การปรับแต่ง และการปรับใช้ คลิกที่นี่เพื่อติดต่อเรา


