nmt
1.0.0
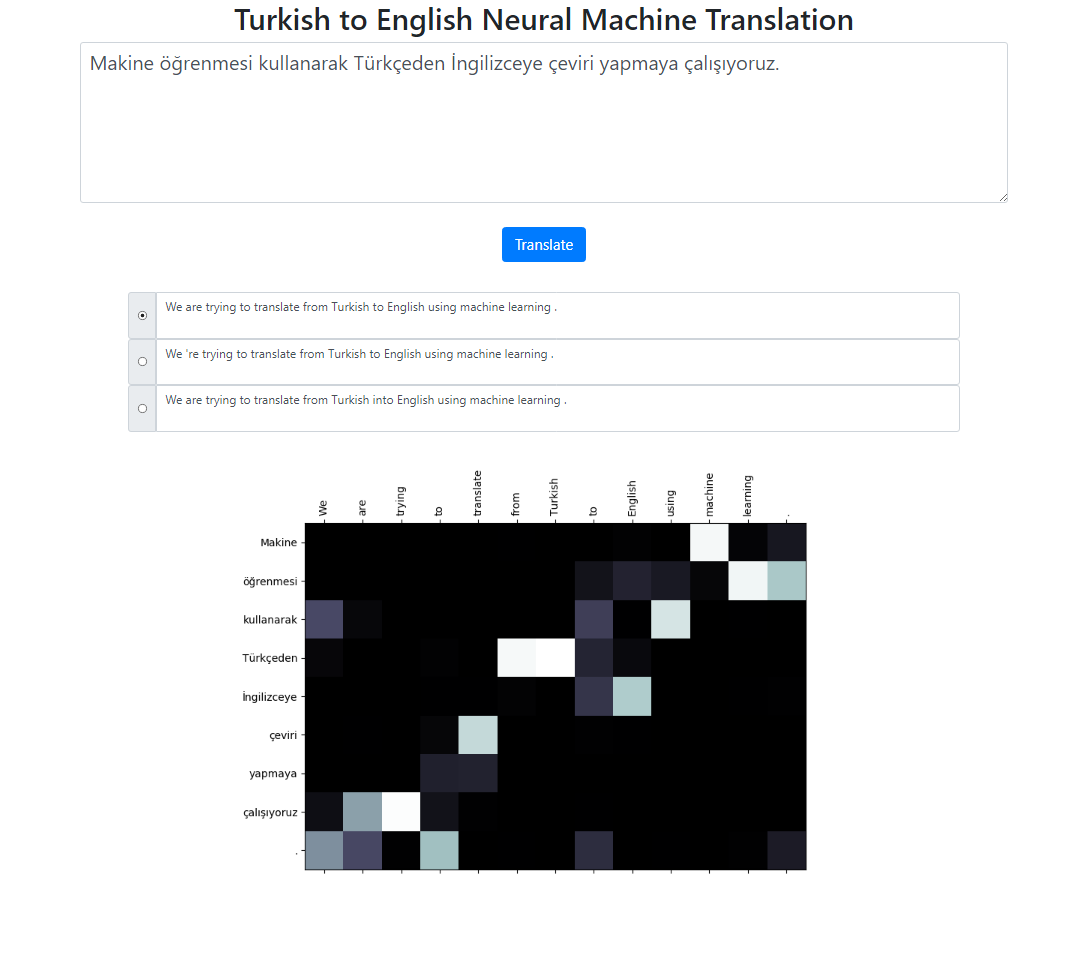
พื้นที่เก็บข้อมูลนี้ใช้ระบบแปลภาษาตุรกีเป็นอังกฤษโดยใช้โมเดล Seq2Seq + Global Attention นอกจากนี้ยังมีแอปพลิเคชัน Flask ที่คุณสามารถเรียกใช้ในเครื่องได้ คุณสามารถป้อนข้อความ แปล และตรวจสอบผลลัพธ์ตลอดจนการแสดงภาพความสนใจได้ เราดำเนินการค้นหาลำแสงโดยมีลำแสงขนาด 3 อยู่เบื้องหลัง และส่งคืนลำดับที่เป็นไปได้มากที่สุดโดยจัดเรียงตามคะแนนสัมพัทธ์
ชุดข้อมูลสำหรับโปรเจ็กต์นี้นำมาจากที่นี่ ฉันได้ใช้คลังข้อมูล Tatoeba ฉันได้ลบข้อมูลที่ซ้ำกันบางส่วนที่พบในข้อมูลแล้ว ฉันยังทำการ pretokenized ชุดข้อมูลด้วย สามารถดูเวอร์ชันสุดท้ายได้ในโฟลเดอร์ข้อมูล
สำหรับการสร้างโทเค็นประโยคภาษาตุรกี ฉันใช้ RegexpTokenizer ของ nltk
puncts_ยกเว้น_apostrophe = '!"#$%&()*+,-./:;<=>?@[]^_`{|}~'TOKENIZE_PATTERN = fr"[{puncts_ยกเว้น_apostrophe}]|w+|['w ]+"regex_tokenizer = RegexpTokenizer(รูปแบบ=TOKENIZE_PATTERN)text = "ไททานิค 15 นิสสัน พาซาร์เตซี saat 02:20'de battı."tokenized_text = regex_tokenizer.tokenize(text)print(" ".join(tokenized_text))# Output: Titanic 15 Nisan pazartesi saat 02 : 20 'de battı .# คุณสมบัติการแยกนี้ใน "02 : 20" แตกต่างจาก tokenizer ภาษาอังกฤษ # เราสามารถรับมือกับสถานการณ์เหล่านั้นได้ แต่ฉันอยากจะทำให้มันเรียบง่ายและ ดูว่า # การกระจายความสนใจของคำเหล่านั้นสอดคล้องกับโทเค็นภาษาอังกฤษหรือไม่ # มีกรณีที่คล้ายกันส่วนใหญ่เป็นวันที่เช่นกันในตัวอย่างนี้: 02/09/2019สำหรับการสร้างประโยคภาษาอังกฤษให้เป็นโทเค็น ฉันใช้โมเดลภาษาอังกฤษของ spacey
en_nlp = spacy.load('en_core_web_sm')text = "เรือไททานิกจมลงเมื่อเวลา 02:20 น. ของวันจันทร์ที่ 15 เมษายน"tokenized_text = en_nlp.tokenizer(text)print(" ".join([tok.text for tok in tokenized_text) ]))# เอาต์พุต: เรือไททานิคจมเมื่อเวลา 02:20 น. ของวันจันทร์ที่ 15 เมษายนประโยคภาษาตุรกีและภาษาอังกฤษคาดว่าจะอยู่ในไฟล์สองไฟล์ที่แตกต่างกัน
file: train.tr tr_sent_1 tr_sent_2 tr_sent_3 ... file: train.en en_sent_1 en_sent_2 en_sent_3 ...
โปรดเรียกใช้ python train.py -h เพื่อดูรายการข้อโต้แย้งทั้งหมด
Sample usage: python train.py --train_data train.tr train.en --valid_data valid.tr valid.en --n_epochs 30 --batch_size 32 --embedding_dim 256 --hidden_size 256 --num_layers 2 --bidirectional --dropout_p 0.3 --device cuda
เพื่อคำนวณคะแนนสีน้ำเงินระดับคอร์ปัส
usage: test.py [-h] --model_file MODEL_FILE --valid_data VALID_DATA [VALID_DATA ...] Neural Machine Translation Testing optional arguments: -h, --help show this help message and exit --model_file MODEL_FILE Model File --valid_data VALID_DATA [VALID_DATA ...] Validation_data Sample Usage: python test.py --model_file model.bin --validation_data valid.tr valid.en
สำหรับการรันแอปพลิเคชันในเครื่อง ให้รัน:
python app.py
ตรวจสอบให้แน่ใจว่าเส้นทางโมเดลของคุณในไฟล์ config.py ถูกกำหนดไว้อย่างถูกต้อง
ไฟล์โมเดล
ไฟล์คำศัพท์
การใช้หน่วยคำย่อย (สำหรับทั้งภาษาตุรกีและภาษาอังกฤษ)
กลไกความสนใจที่แตกต่างกัน (การเรียนรู้พารามิเตอร์ที่แตกต่างกันสำหรับความสนใจ)
รหัส Skeleton สำหรับโครงการนี้นำมาจากหลักสูตร NLP ของ Stanford: CS224n


