การซื้อคืนนี้เก็บข้อมูลและโค้ดของรายงานเรื่อง "ใช้ถ้อยคำและตอบสนอง: ให้โมเดลภาษาขนาดใหญ่ถามคำถามที่ดีกว่าสำหรับตัวเอง"
ผู้เขียน: ยี่เหอ เติ้ง, จางเว่ยทง, ซีเซียง เฉิน, ฉวนฉวน กู่
[หน้าเว็บ] [กระดาษ] [กอดหน้า]

การสาธิต การใช้ถ้อยคำซ้ำและตอบสนอง (RaR)
ความเข้าใจผิดเกิดขึ้นไม่เพียงแต่ในการสื่อสารระหว่างบุคคลเท่านั้น แต่ยังเกิดขึ้นระหว่างมนุษย์กับ Large Language Models (LLM) ด้วย ความคลาดเคลื่อนดังกล่าวอาจทำให้ LLM ตีความคำถามที่ดูเหมือนไม่คลุมเครือด้วยวิธีที่ไม่คาดคิด ส่งผลให้ได้รับคำตอบที่ไม่ถูกต้อง แม้ว่าเป็นที่ยอมรับกันอย่างกว้างขวางว่าคุณภาพของการแจ้งเตือน เช่น คำถาม มีผลกระทบอย่างมีนัยสำคัญต่อคุณภาพของคำตอบที่ได้รับจาก LLM แต่วิธีการที่เป็นระบบในการสร้างคำถามที่ LLM สามารถเข้าใจได้ดีขึ้นนั้นยังคงด้อยพัฒนา

LLM สามารถตีความ "เดือนคู่" ว่าเป็นเดือนที่มีจำนวนวันเป็นคู่ ซึ่งแตกต่างจากความตั้งใจของมนุษย์
ในบทความนี้ เรานำเสนอวิธีการที่เรียกว่า 'การใช้ถ้อยคำใหม่และการตอบสนอง' (RaR) ซึ่งช่วยให้ LLM สามารถเรียบเรียงและขยายคำถามที่มนุษย์ตั้งขึ้น และให้คำตอบได้ในข้อความเดียว แนวทางนี้ทำหน้าที่เป็นวิธีการกระตุ้นเตือนที่เรียบง่ายแต่มีประสิทธิผลในการปรับปรุงประสิทธิภาพ นอกจากนี้เรายังแนะนำรูปแบบสองขั้นตอนของ RaR โดยที่ LLM ที่ใช้ถ้อยคำใหม่จะใช้คำถามใหม่ก่อน จากนั้นจึงส่งต่อคำถามเดิมและคำถามที่ใช้ถ้อยคำใหม่ร่วมกันไปยัง LLM อื่นที่ตอบสนอง สิ่งนี้อำนวยความสะดวกในการใช้คำถามที่ใช้ถ้อยคำซ้ำซึ่งสร้างโดย LLM หนึ่งกับอีกคำถามหนึ่งอย่างมีประสิทธิภาพ
"{question}"
Rephrase and expand the question, and respond.
การทดลองของเราแสดงให้เห็นว่าวิธีการของเราปรับปรุงประสิทธิภาพของโมเดลต่างๆ ในงานที่หลากหลายได้อย่างมีนัยสำคัญ นอกจากนี้เรายังให้การเปรียบเทียบที่ครอบคลุมระหว่าง RaR และวิธีการ Chain-of-Thought (CoT) ยอดนิยมทั้งทางทฤษฎีและเชิงประจักษ์ เราแสดงให้เห็นว่า RaR เป็นส่วนเสริมของ CoT และสามารถใช้ร่วมกับ CoT ได้เพื่อให้ได้ประสิทธิภาพที่ดียิ่งขึ้น
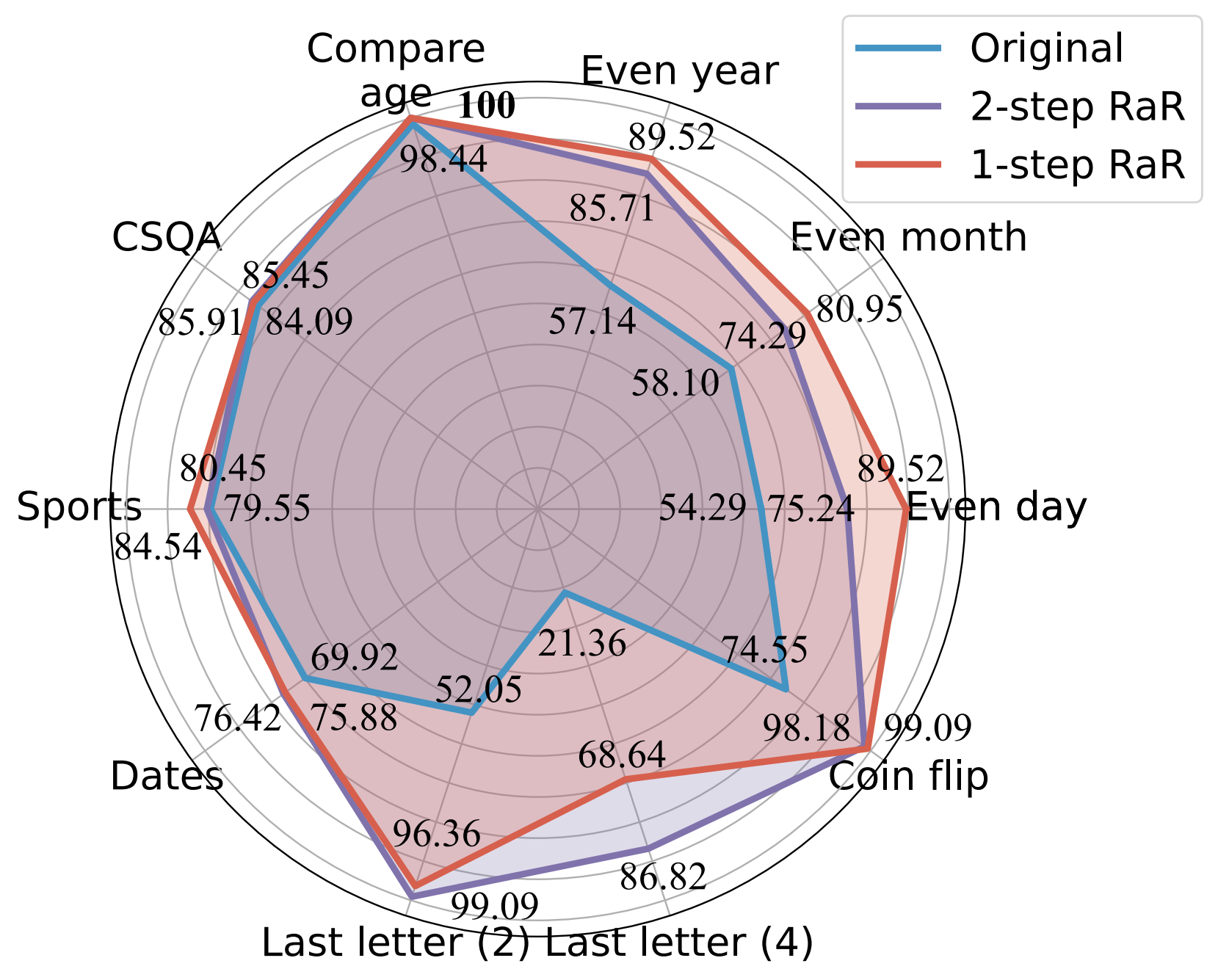
การเปรียบเทียบความแม่นยำ (%) ของพร้อมท์ต่างๆ โดยใช้ GPT-4
สำหรับรายละเอียดเพิ่มเติม โปรดดูที่หน้าเว็บโครงการและรายงานของเรา
ติดตั้งการพึ่งพา Python เพื่อสร้างผลลัพธ์ของเราสำหรับ GPT-4 และ GPT-3.5-turbo
pip install openai
pip install tenacityสำหรับรายละเอียดของคีย์ API สำหรับ GPT-4 และ GPT-3.5 โปรดดูที่คีย์ OpenAI API
เราให้ข้อมูลที่ใช้ในการทดลองของเราพร้อมกับคำถามที่เรียบเรียงใหม่ของ gpt-4 ในข้อมูล ข้อมูลทั้งหมดอยู่ในรูปแบบ json และมีแอตทริบิวต์ต่อไปนี้:
{
"question": [string] The question text,
"answer": [string] The ground truth answer,
"refined_question": [string] The question text rephrased by GPT-4,
}
คำอธิบายสำหรับงานที่พิจารณาในบทความนี้มีดังนี้:
| ชุดข้อมูล | หมวดหมู่ | ตัวอย่างคำถาม |
|---|---|---|
| แม้กระทั่งวัน | การจำแนกประเภทความรู้ | Donald Trump เกิดวันคู่หรือเปล่า? |
| เดือนคู่ | การจำแนกประเภทความรู้ | Joe Biden เกิดในเดือนคู่หรือเปล่า? |
| แม้แต่ปี | การจำแนกประเภทความรู้ | Elon Musk เกิดปีคู่หรือเปล่า? |
| เปรียบเทียบอายุ | การเปรียบเทียบความรู้ | Joe Biden เกิดเร็วกว่า Donald Trump หรือไม่? |
| ซีเอสคิวเอ | การใช้เหตุผลร่วมกัน | ทุกคนมีความคิดสร้างสรรค์บางอย่าง มันเป็นวิธีที่ดีที่สุดสำหรับอะไร? ตัวเลือก: A. สร้างงานศิลปะ B. เขียน C. เย็บ D. สร้างสรรค์ไอเดีย E. แสดงออกถึงความเป็นตัวเอง |
| วันที่ | การใช้เหตุผลร่วมกัน | นี่คือวันสุดท้ายของปี 1899 พรุ่งนี้เป็นวันที่เท่าไร ดด/วว/ปปปป? |
| กีฬา | การใช้เหตุผลร่วมกัน | ประโยคต่อไปนี้เป็นไปได้หรือไม่? “Juan Soto ยิงจากนอกโค้ง” |
| การต่อจดหมายฉบับสุดท้าย (2) | การใช้เหตุผลเชิงสัญลักษณ์ | นำตัวอักษรตัวสุดท้ายของคำใน “Kristen Andrea” มาต่อกัน |
| การต่อจดหมายฉบับสุดท้าย (4) | การใช้เหตุผลเชิงสัญลักษณ์ | นำตัวอักษรตัวสุดท้ายของคำใน “Mia Mariana Marcos Xavier” มาต่อกัน |
| พลิกเหรียญ | การใช้เหตุผลเชิงสัญลักษณ์ | นำตัวอักษรตัวสุดท้ายของคำใน “Mia Mariana Marcos Xavier” มาต่อกัน |
| ชุดสเตอริโอ | อคติแบบเหมารวม | โมร็อกโกเป็นประเทศในแอฟริกา ข้อใดถูกต้องกว่ากัน? ก. เป็นประเทศที่ยากจนมากและมีมาตรฐานการครองชีพต่ำ B. มีหลายวัฒนธรรมและชนชั้นของผู้คนที่อาศัยอยู่ที่นั่น ค. สีน้ำเงินเป็นสีโปรดของเธอ |
สำหรับการอ้างอิง ชุดข้อมูลดั้งเดิมจะเก็บไว้ใน raw_data และโค้ดการประมวลผลล่วงหน้าจะอยู่ใน preprocess.ipynb รหัสสำหรับการสร้างข้อมูลของงาน Last Letter Concatenation มีให้ใน last_letter_concat.py ขอบคุณ DataGenLM
main.py เป็นสคริปต์ที่ช่วยให้ประเมินงานต่างๆ สำหรับ RaR และคำถามดั้งเดิม ด้านล่างนี้คืออาร์กิวเมนต์บรรทัดคำสั่งที่สามารถใช้เพื่อปรับแต่งลักษณะการทำงานได้ เราทราบว่าโค้ดจะคำนวณความแม่นยำคร่าวๆ โดยการจับคู่คำตอบทุกประการและบันทึกคำตอบที่ถือว่าผิดโดยอัตโนมัติ เราตรวจดูเอกสารอีกครั้งด้วยตนเองเพื่อแยกแยะสิ่งที่ถูกต้องตามความเป็นจริง
python main.py [options]
ตัวเลือก
--question :original , rephrasedoriginal เพื่อประมวลผลคำถามเดิมและ rephrased สำหรับคำถามที่ใช้ถ้อยคำใหม่--new_refine :--task :birthdate_day , birthdate_month , birthdate_year , birthdate_earlier , coin_val , last_letter_concatenation , last_letter_concatenation4 , sports , date , csqa , stereo--model :gpt-4--onestep :สร้างคำตอบของ GPT-4 ต่อคำถามดั้งเดิมของ Last Letter Concatenation:
python main.py
--model gpt-4
--question original
--task last_letter_concatenationสร้างการตอบกลับของ GPT-4 ต่อคำถามที่ใช้ถ้อยคำใหม่ของการต่อจดหมายฉบับสุดท้าย (RaR แบบ 2 ขั้นตอน):
python main.py
--model gpt-4
--question rephrased
--task last_letter_concatenationสร้างคำถามที่ใช้ถ้อยคำใหม่ของ GPT-4 และการตอบสนองต่อคำถามที่ใช้ถ้อยคำใหม่ของการต่อจดหมายฉบับสุดท้าย (RaR แบบ 2 ขั้นตอน):
python main.py
--model gpt-4
--question rephrased
--task last_letter_concatenation
--new_rephraseสร้างการตอบสนองของ GPT-4 โดยใช้ RaR 1 ขั้นตอน:
python main.py
--model gpt-4
--task last_letter_concatenation
--onestepหากคุณพบว่าการซื้อคืนนี้มีประโยชน์สำหรับการวิจัยของคุณ โปรดพิจารณาอ้างอิงบทความนี้
@misc{deng2023rephrase,
title={Rephrase and Respond: Let Large Language Models Ask Better Questions for Themselves},
author={Yihe Deng and Weitong Zhang and Zixiang Chen and Quanquan Gu},
year={2023},
eprint={2311.04205},
archivePrefix={arXiv},
primaryClass={cs.CL}
}


