hercules
v10.7.2
การวิเคราะห์ประวัติ Git ที่รวดเร็ว เจาะลึก และปรับแต่งได้สูง
ภาพรวม • วิธีใช้งาน • การติดตั้ง • การบริจาค • ใบอนุญาต
Hercules เป็นเครื่องมือวิเคราะห์พื้นที่เก็บข้อมูล Git ที่รวดเร็วและปรับแต่งได้สูงอย่างน่าอัศจรรย์ซึ่งเขียนด้วยภาษา Go รวมแบตเตอรี่แล้ว ขับเคลื่อนโดย go-git
ประกาศ (พฤศจิกายน 2020): ผู้เขียนหลักกลับมาจากบริเวณขอบรกและกำลังค่อยๆ กลับมาดำเนินการพัฒนาต่อ ดูแผนงาน
มีเครื่องมือบรรทัดคำสั่งสองรายการ: hercules และ labours โปรแกรมแรกคือโปรแกรมที่เขียนด้วยภาษา Go ซึ่งรับพื้นที่เก็บข้อมูล Git และดำเนินการงานการวิเคราะห์ Directed Acyclic Graph (DAG) เหนือประวัติการคอมมิตทั้งหมด อย่างที่สองคือสคริปต์ Python ซึ่งแสดงแปลงที่กำหนดไว้ล่วงหน้าเหนือข้อมูลที่รวบรวม โดยปกติแล้วเครื่องมือทั้งสองนี้จะใช้ร่วมกันผ่านท่อ สามารถเขียนการวิเคราะห์แบบกำหนดเองได้โดยใช้ระบบปลั๊กอิน นอกจากนี้ยังสามารถรวมผลการวิเคราะห์หลายรายการเข้าด้วยกันได้ ซึ่งเกี่ยวข้องกับองค์กรต่างๆ ประวัติความมุ่งมั่นที่วิเคราะห์แล้วประกอบด้วยสาขา การผสาน ฯลฯ
Hercules ถูกนำมาใช้อย่างประสบความสำเร็จสำหรับโครงการภายในหลายโครงการที่แหล่งที่มา{d} มีโพสต์ในบล็อก: 1, 2 และการนำเสนอ โปรดสนับสนุนโดยการทดสอบ แก้ไขข้อบกพร่อง เพิ่มการวิเคราะห์ใหม่ หรือเขียนโค้ดผยอง!
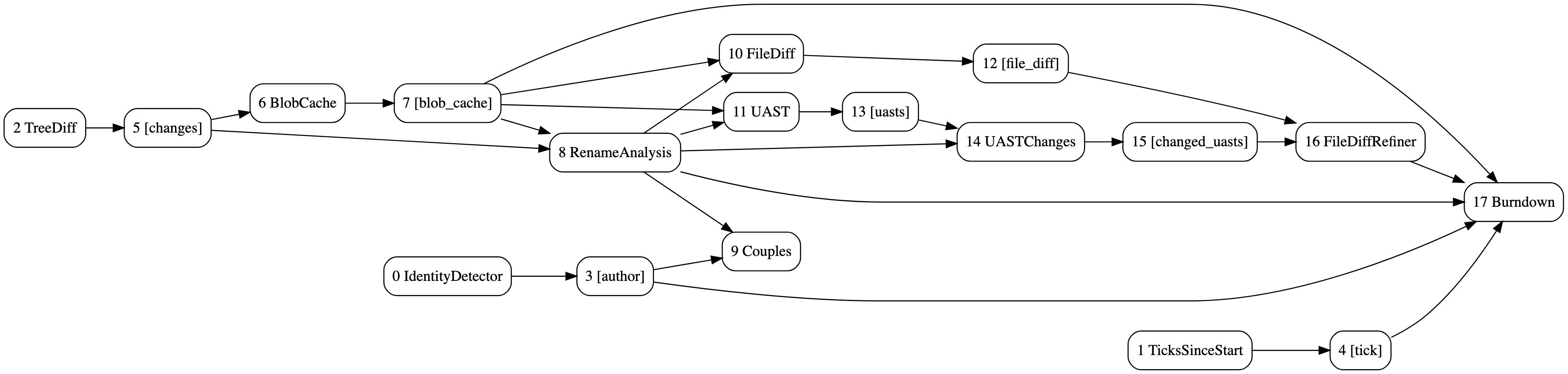
DAG ของการวิเคราะห์ภาวะเหนื่อยหน่ายและคู่รักด้วยการปรับแต่งส่วนต่าง UAST สร้างด้วย hercules --burndown --burndown-people --couples --feature=uast --dry-run --dump-dag doc/dag.dot https://github.com/src-d/hercules
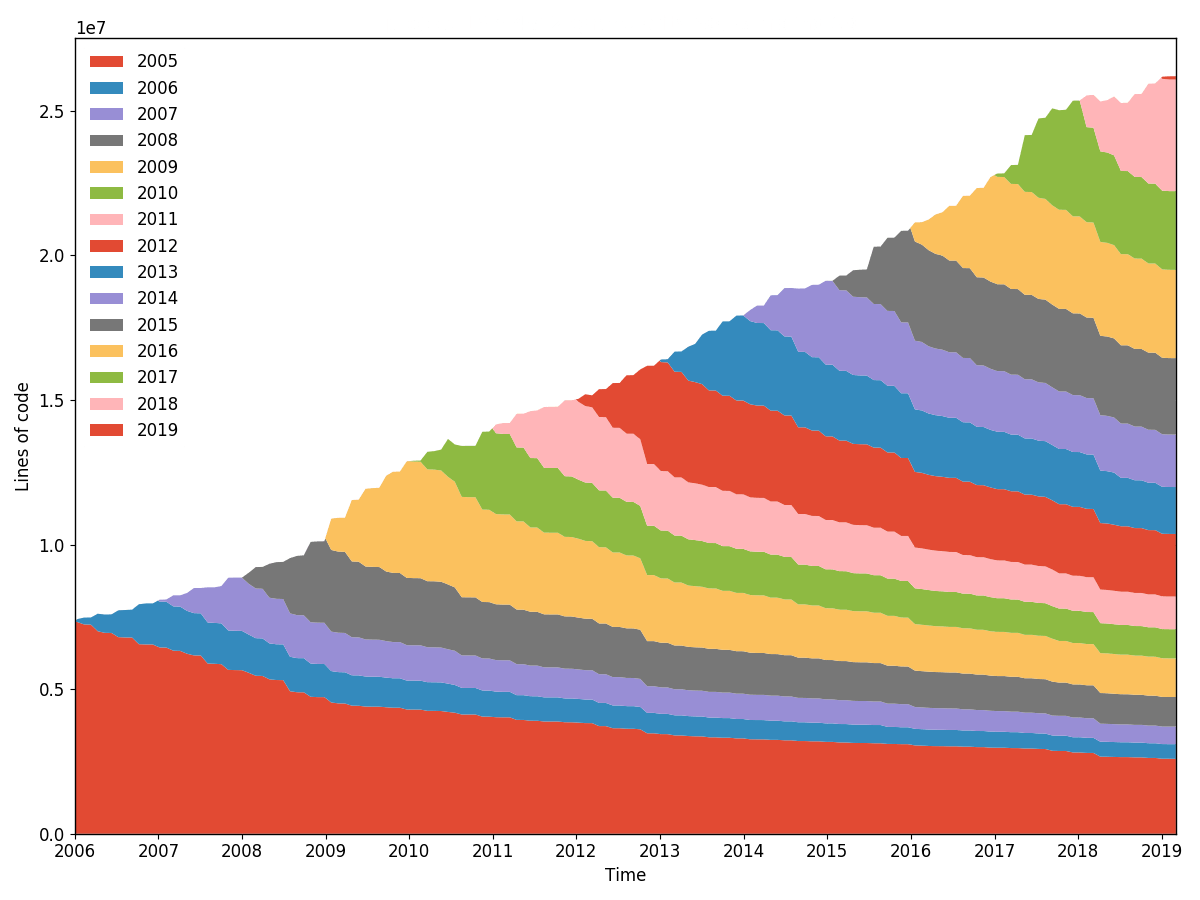
torvalds/linux line burndown (รายละเอียด 30, การสุ่มตัวอย่าง 30, สุ่มตัวอย่างใหม่ตามปี) สร้างด้วย hercules --burndown --first-parent --pb https://github.com/torvalds/linux | labours -f pb -m burndown-project ใน 1 ชั่วโมง 40 นาที
คว้าไบนารี่ของ hercules จากหน้าเผยแพร่ labours สามารถติดตั้งได้จาก PyPi:
pip3 install labours
pip3 เป็นตัวจัดการแพ็คเกจ Python
สามารถติดตั้ง Numpy และ Scipy บน Windows ได้โดยใช้ http://www.lfd.uci.edu/~gohlke/pythonlibs/
คุณจะต้องมี Go (>= v1.11) และ protoc
git clone https://github.com/src-d/hercules && cd hercules
make
pip3 install -e ./python
เป็นไปได้ที่จะรัน Hercules เป็น GitHub Action: Hercules บน GitHub Marketplace โปรดดูขั้นตอนการทำงานตัวอย่างซึ่งสาธิตวิธีการตั้งค่า
...ยินดีต้อนรับ! ดูการมีส่วนร่วมและจรรยาบรรณ
อาปาเช่ 2.0
การอ้างอิงบรรทัดคำสั่งที่มีประโยชน์และเชื่อถือได้ล่าสุด:
hercules --help
ตัวอย่างบางส่วน:
# Use "memory" go-git backend and display the burndown plot. "memory" is the fastest but the repository's git data must fit into RAM.
hercules --burndown https://github.com/go-git/go-git | labours -m burndown-project --resample month
# Use "file system" go-git backend and print some basic information about the repository.
hercules /path/to/cloned/go-git
# Use "file system" go-git backend, cache the cloned repository to /tmp/repo-cache, use Protocol Buffers and display the burndown plot without resampling.
hercules --burndown --pb https://github.com/git/git /tmp/repo-cache | labours -m burndown-project -f pb --resample raw
# Now something fun
# Get the linear history from git rev-list, reverse it
# Pipe to hercules, produce burndown snapshots for every 30 days grouped by 30 days
# Save the raw data to cache.yaml, so that later is possible to labours -i cache.yaml
# Pipe the raw data to labours, set text font size to 16pt, use Agg matplotlib backend and save the plot to output.png
git rev-list HEAD | tac | hercules --commits - --burndown https://github.com/git/git | tee cache.yaml | labours -m burndown-project --font-size 16 --backend Agg --output git.png
labours -i /path/to/yaml อนุญาตให้อ่านเอาต์พุตจาก hercules ซึ่งบันทึกไว้ในดิสก์
สามารถจัดเก็บพื้นที่เก็บข้อมูลที่โคลนไว้บนดิสก์ได้ การวิเคราะห์ที่ตามมาสามารถรันบนไดเร็กทอรีที่เกี่ยวข้องแทนการโคลนตั้งแต่ต้น:
# First time - cache
hercules https://github.com/git/git /tmp/repo-cache
# Second time - use the cache
hercules --some-analysis /tmp/repo-cache
การดำเนินการจะสร้างอาร์ติแฟกต์ชื่อ hercules_charts เนื่องจากปัจจุบันเป็นไปไม่ได้ที่จะแพ็กหลายไฟล์ในอาร์ติแฟกต์เดียว แผนภูมิทั้งหมดและไฟล์ Tensorflow Projector จึงถูกแพ็กในไฟล์เก็บถาวร tar ภายใน หากต้องการดูการฝัง ให้ไปที่ projector.tensorflow.org คลิก "โหลด" และเลือก TSV ทั้งสองรายการ จากนั้นใช้ UMAP หรือ T-SNE
docker run --rm srcd/hercules hercules --burndown --pb https://github.com/git/git | docker run --rm -i -v $(pwd):/io srcd/hercules labours -f pb -m burndown-project -o /io/git_git.png
hercules --burndown
labours -m burndown-project
สถิติการเบิร์นดาวน์บรรทัดสำหรับที่เก็บทั้งหมด เหมือนกับที่ git-of-theseus ทำ แต่เร็วกว่ามาก การตำหนิจะดำเนินการอย่างมีประสิทธิภาพและเพิ่มขึ้นโดยใช้อัลกอริธึมการติดตามทรี RB ที่กำหนดเอง และเฉพาะวันที่แก้ไขล่าสุดเท่านั้นที่จะถูกบันทึกในขณะที่ดำเนินการวิเคราะห์
การวิเคราะห์การเบิร์นดาวน์ทั้งหมดขึ้นอยู่กับค่าของ รายละเอียด และ การสุ่มตัวอย่าง รายละเอียดคือจำนวนวันที่แต่ละแบนด์ในสแต็กประกอบด้วย การสุ่มตัวอย่างคือความถี่ที่สแนปช็อตสถานะเหนื่อยหน่าย ยิ่งค่าน้อยลง โครงเรื่องก็จะราบรื่นมากขึ้น แต่งานก็จะเสร็จมากขึ้น
มีตัวเลือกในการสุ่มตัวอย่างแถบภายใน labours เพื่อให้คุณสามารถกำหนดการแจกแจงที่แม่นยำมากและเห็นภาพด้วยวิธีต่างๆ นอกจากนี้ การสุ่มตัวอย่างใหม่จะจัดแนวแถบข้ามขอบเขตเป็นระยะ เช่น เดือนหรือปี เห็นได้ชัดว่าวงดนตรีที่ไม่ได้สุ่มตัวอย่างจะไม่สอดคล้องกันและเริ่มจากวันเกิดของโปรเจ็กต์
hercules --burndown --burndown-files
labours -m burndown-file
สถิติการเบิร์นดาวน์สำหรับทุกไฟล์ในพื้นที่เก็บข้อมูลซึ่งยังมีอยู่ในเวอร์ชันล่าสุด
หมายเหตุ: มันจะสร้างกราฟแยกต่างหากสำหรับทุกไฟล์ คุณไม่ต้องการรันบนพื้นที่เก็บข้อมูลที่มีไฟล์จำนวนมาก
hercules --burndown --burndown-people [--people-dict=/path/to/identities]
labours -m burndown-person
สถิติการเบิร์นดาวน์สำหรับผู้มีส่วนร่วมในพื้นที่เก็บข้อมูล หากไม่ได้ระบุ --people-dict ตัวตนจะถูกค้นพบโดยอัลกอริทึมต่อไปนี้:
หากระบุ --people-dict ก็ควรชี้ไปที่ไฟล์ข้อความที่มีข้อมูลเฉพาะตัวที่กำหนดเอง รูปแบบคือ: ทุกบรรทัดคือนักพัฒนารายเดียว โดยประกอบด้วยอีเมลและชื่อที่ตรงกันทั้งหมดคั่นด้วย | - กรณีนี้จะถูกละเลย
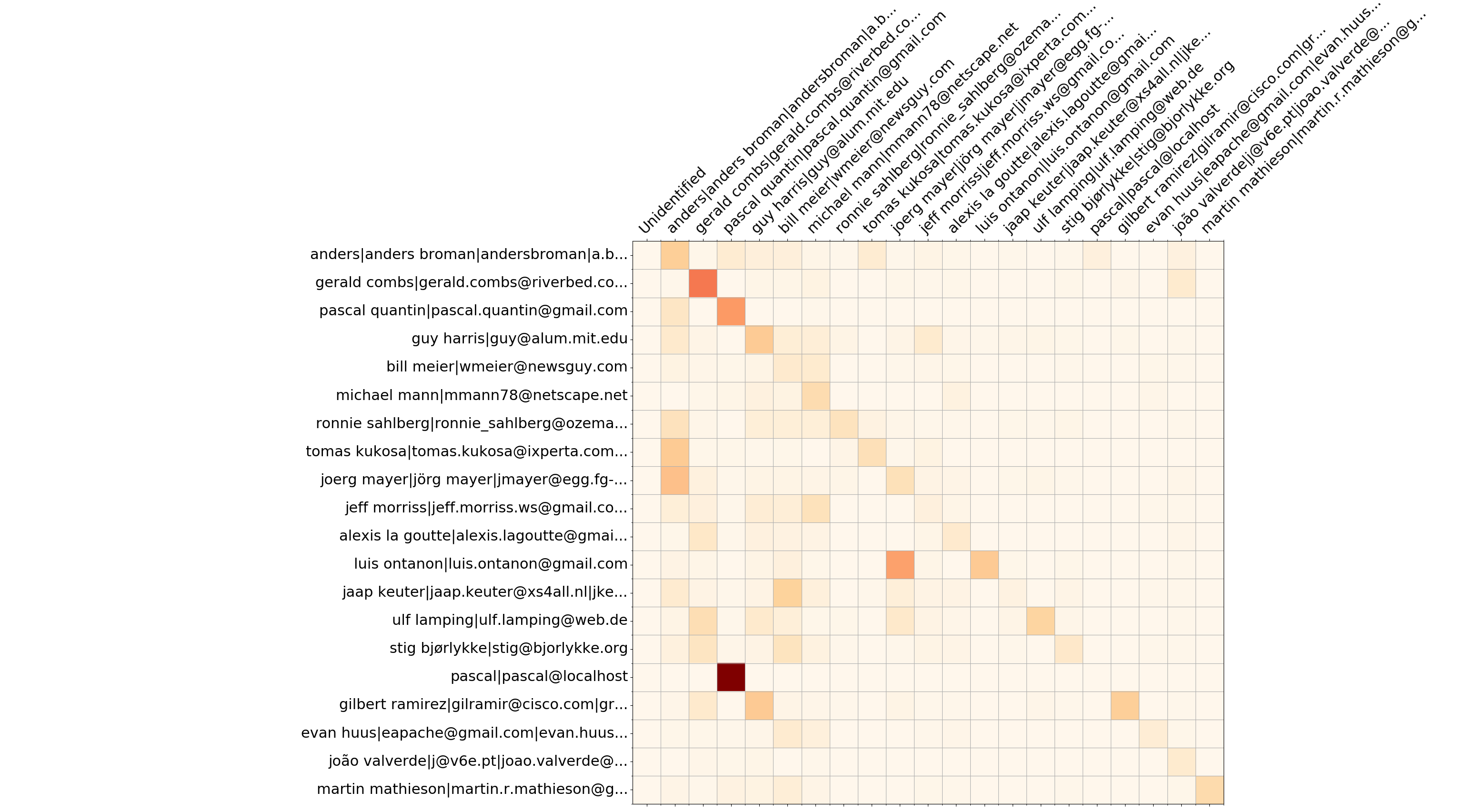
Wireshark 20 อันดับแรก - เขียนทับเมทริกซ์
hercules --burndown --burndown-people [--people-dict=/path/to/identities]
labours -m overwrites-matrix
นอกเหนือจากข้อมูลการเบิร์นดาวน์แล้ว --burndown-people ยังรวบรวมสถิติบรรทัดที่เพิ่มและลบต่อนักพัฒนาแต่ละราย ดังนั้นจึงสามารถมองเห็นได้ว่ามีกี่บรรทัดที่นักพัฒนา A เขียนถูกลบออกโดยนักพัฒนา B ซึ่งบ่งชี้ถึงการทำงานร่วมกันระหว่างผู้คนและกำหนดทีมที่เชี่ยวชาญ
รูปแบบคือเมทริกซ์ที่มี N แถวและคอลัมน์ (N+2) โดยที่ N คือจำนวนนักพัฒนา
--people-dict จะเป็น 0 เสมอ) ลำดับของนักพัฒนาจะถูกเก็บไว้ในโหนด YAML people_sequence
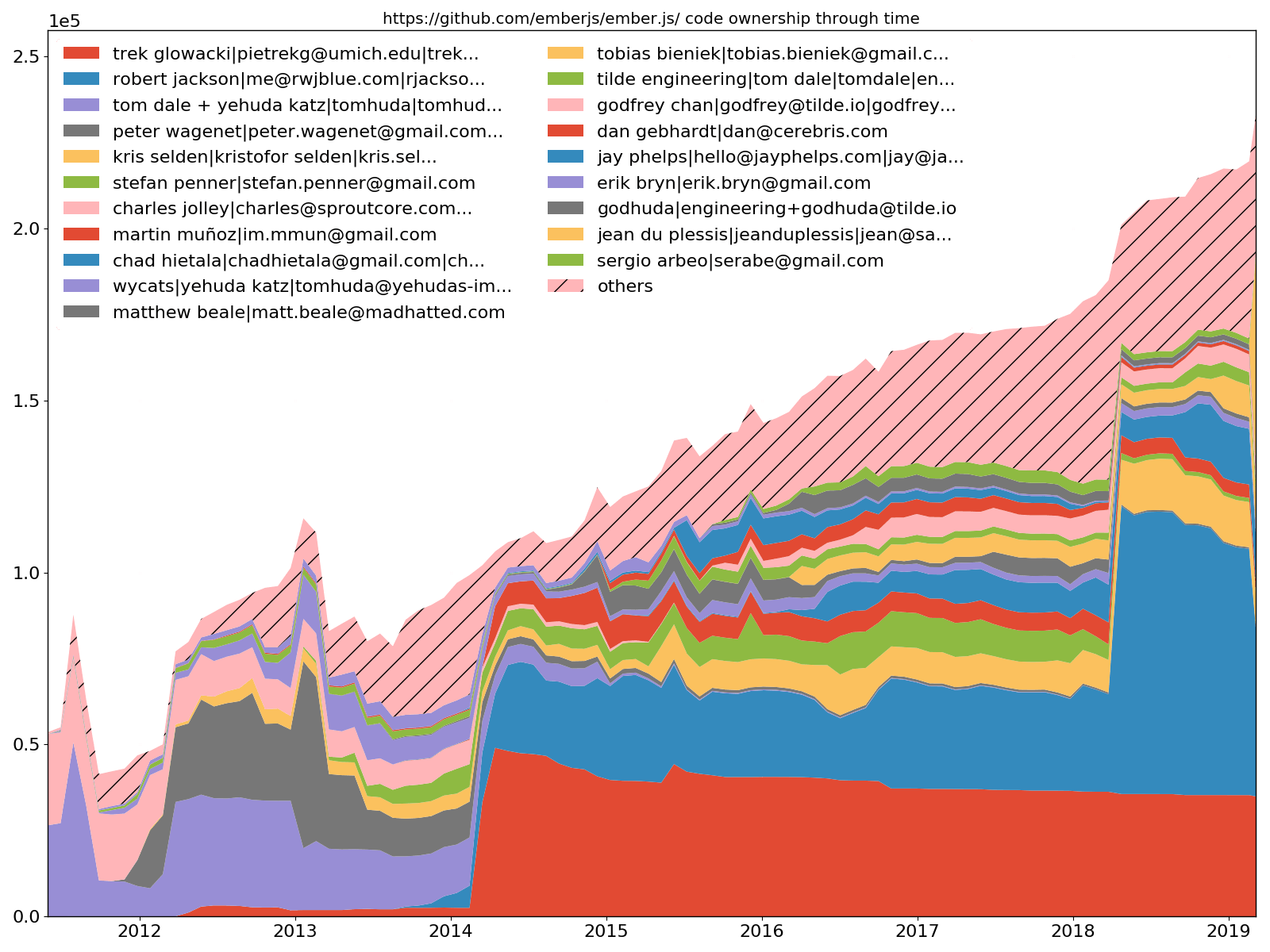
Ember.js 20 อันดับแรกของนักพัฒนา - ความเป็นเจ้าของโค้ด
hercules --burndown --burndown-people [--people-dict=/path/to/identities]
labours -m ownership
--burndown-people ยังอนุญาตให้วาดการแบ่งปันโค้ดผ่านพล็อตพื้นที่แบบซ้อนเวลา นั่นคือจำนวนบรรทัดที่ยังมีชีวิตอยู่ ณ ช่วงเวลาที่สุ่มตัวอย่างทันเวลาสำหรับนักพัฒนาที่ระบุแต่ละคน
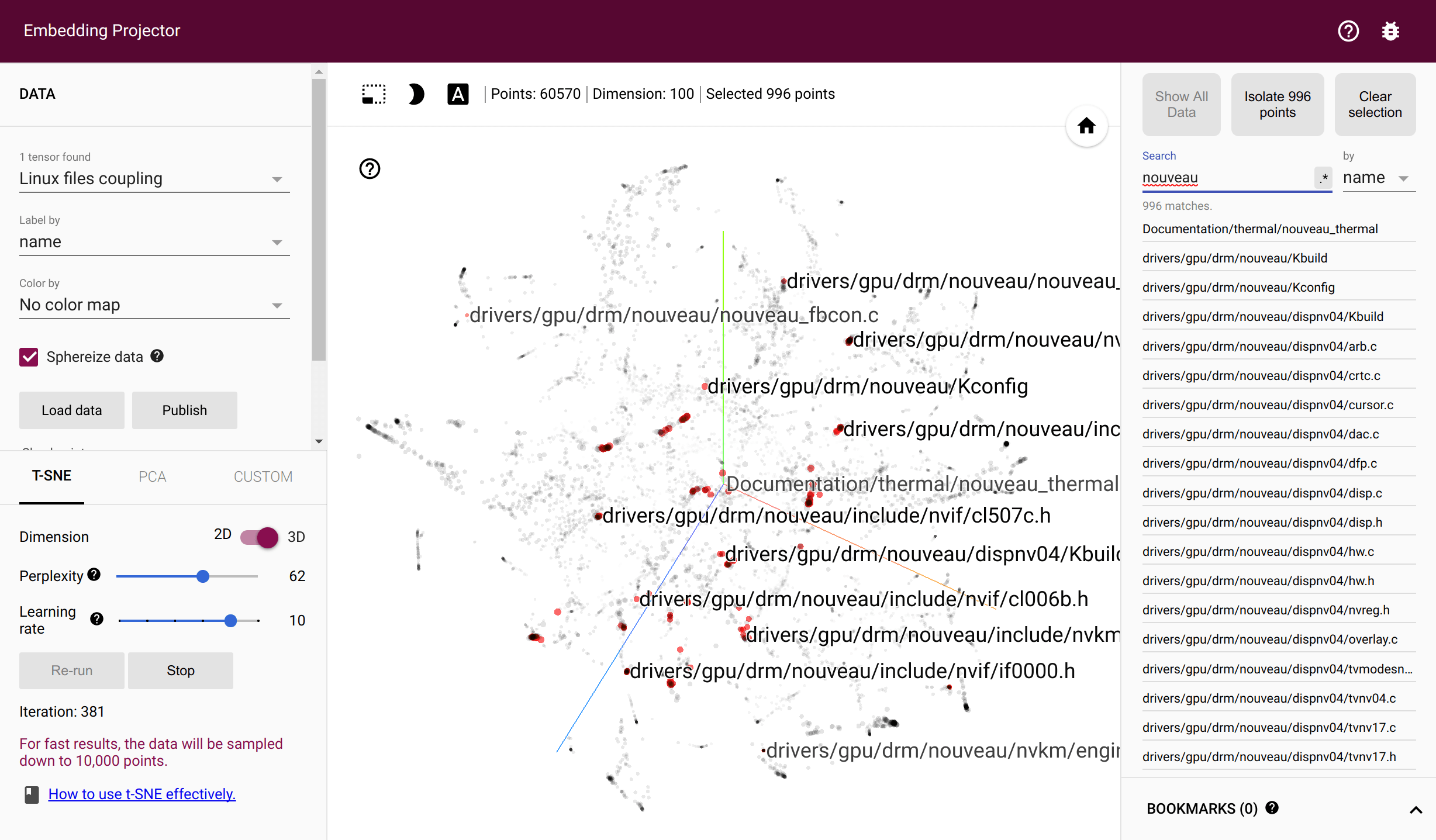
การเชื่อมต่อไฟล์ torvalds / linux ใน Tensorflow Projector
hercules --couples [--people-dict=/path/to/identities]
labours -m couples -o <name> [--couples-tmp-dir=/tmp]
สำคัญ : จำเป็นต้องติดตั้ง Tensorflow โปรดปฏิบัติตามคำแนะนำอย่างเป็นทางการ
ไฟล์จะถูกเชื่อมต่อหากมีการเปลี่ยนแปลงในการคอมมิตเดียวกัน นักพัฒนาจะเชื่อมต่อกันหากพวกเขาเปลี่ยนไฟล์เดียวกัน hercules บันทึกจำนวนคู่ตลอดประวัติการกระทำทั้งหมด และส่งออกเมทริกซ์การเกิดร่วมที่สอดคล้องกันสองรายการ จากนั้น labours จะฝึกการฝังแบบหมุนได้ - เวกเตอร์หนาแน่นซึ่งสะท้อนถึงความน่าจะเป็นที่เกิดขึ้นร่วมกันผ่านระยะทางแบบยุคลิด การฝึกอบรมต้องมีการติดตั้ง Tensorflow ที่ใช้งานได้ ไฟล์ระดับกลางจะถูกจัดเก็บไว้ในไดเร็กทอรีชั่วคราวของระบบหรือ --couples-tmp-dir หากมีการระบุไว้ การฝังที่ได้รับการฝึกจะถูกเขียนไปยังไดเร็กทอรีการทำงานปัจจุบันโดยมีชื่อขึ้นอยู่กับ -o รูปแบบเอาต์พุตคือ TSV และจับคู่ Tensorflow Projector เพื่อให้ไฟล์และบุคคลสามารถมองเห็นได้ด้วยการใช้ t-SNE ใน TF Projector
46 jinja2/compiler.py:visit_Template [FunctionDef]
42 jinja2/compiler.py:visit_For [FunctionDef]
34 jinja2/compiler.py:visit_Output [FunctionDef]
29 jinja2/environment.py:compile [FunctionDef]
27 jinja2/compiler.py:visit_Include [FunctionDef]
22 jinja2/compiler.py:visit_Macro [FunctionDef]
22 jinja2/compiler.py:visit_FromImport [FunctionDef]
21 jinja2/compiler.py:visit_Filter [FunctionDef]
21 jinja2/runtime.py:__call__ [FunctionDef]
20 jinja2/compiler.py:visit_Block [FunctionDef]
ต้องขอบคุณ Babelfish ที่ทำให้ Hercules สามารถวัดจำนวนครั้งที่แต่ละหน่วยโครงสร้างได้รับการแก้ไข โดยค่าเริ่มต้น จะดูที่ฟังก์ชันต่างๆ อ้างถึงคู่มือ Semantic UAST XPath เพื่อสลับไปใช้อย่างอื่น
hercules --shotness [--shotness-xpath-*]
labours -m shotness
การวิเคราะห์คู่จะโหลดข้อมูล "ช็อตเนส" โดยอัตโนมัติ หากมี
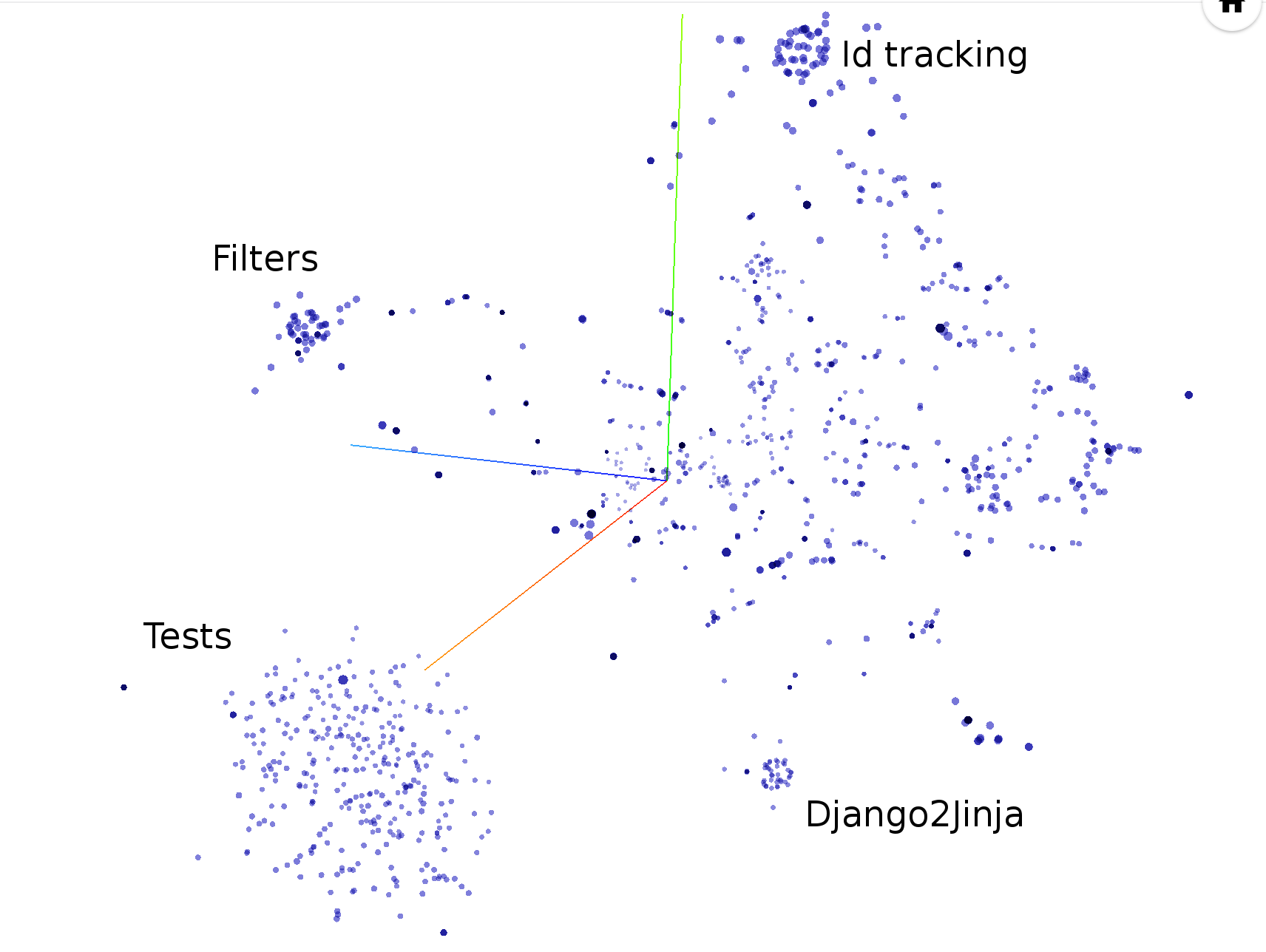
hercules --shotness --pb https://github.com/pallets/jinja | labours -m couples -f pb
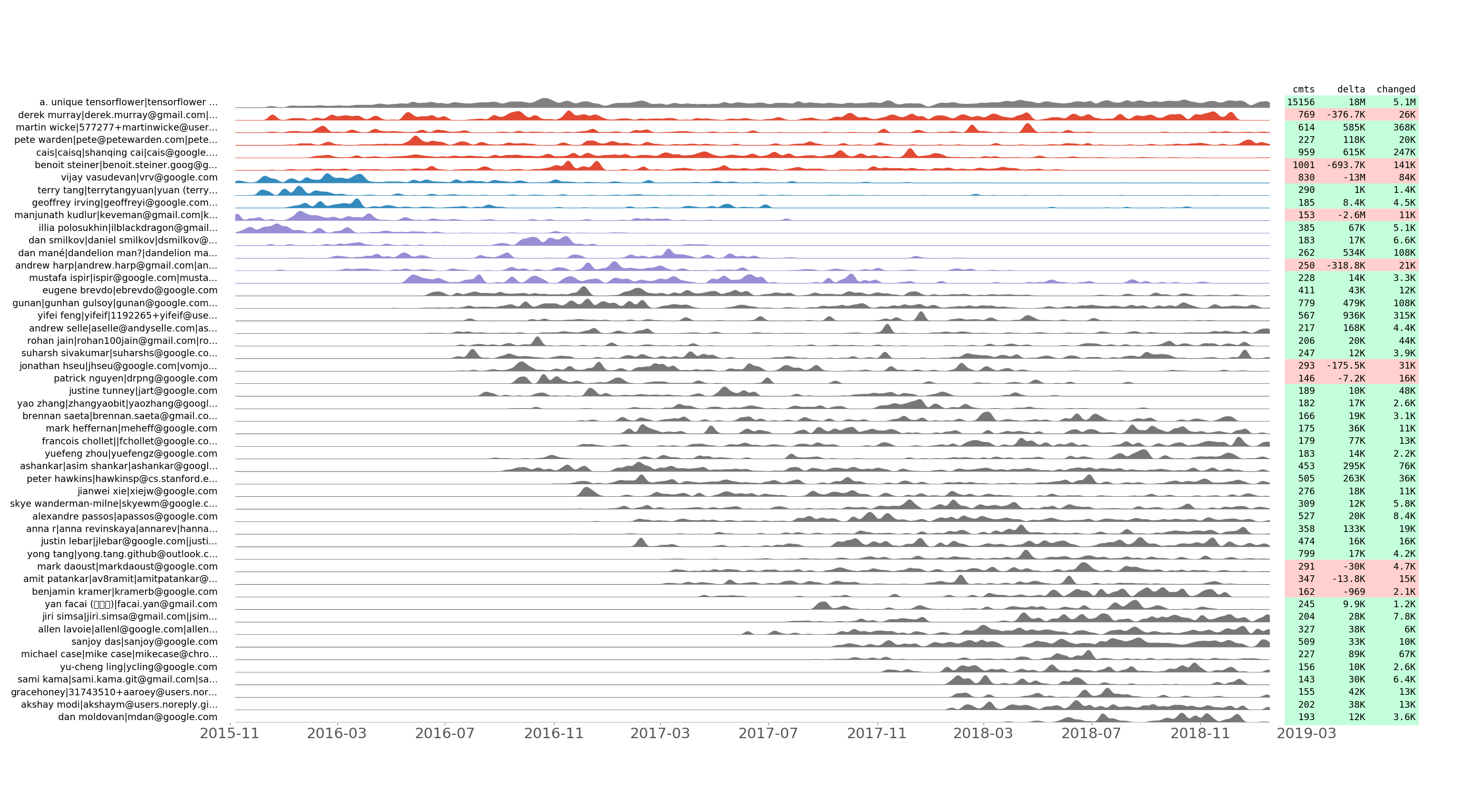
tensorflow/tensorflow สอดคล้องกับชุดคอมมิตของนักพัฒนา 50 อันดับแรกตามหมายเลขคอมมิต
hercules --devs [--people-dict=/path/to/identities]
labours -m devs -o <name>
เราบันทึกจำนวนการคอมมิต รวมถึงบรรทัดที่เพิ่ม ลบ และเปลี่ยนแปลงต่อวันสำหรับนักพัฒนาแต่ละคน เราพล็อตลำดับเวลาคอมมิตผลลัพธ์โดยใช้เทคนิคเล็กๆ น้อยๆ เพื่อแสดงการจัดกลุ่มชั่วคราว กล่าวอีกนัยหนึ่ง ชุดการคอมมิตสองชุดที่อยู่ติดกันควรมีลักษณะคล้ายกันหลังจากการทำให้เป็นมาตรฐาน
เนื้อเรื่องนี้ช่วยให้ค้นพบว่าทีมพัฒนาพัฒนาไปตามกาลเวลาอย่างไร นอกจากนี้ยังแสดง "commit flashmobs" เช่น Hacktoberfest ตัวอย่างเช่น ต่อไปนี้เป็นข้อมูลเชิงลึกที่เปิดเผยจากพล็อต tensorflow/tensorflow ด้านบน:
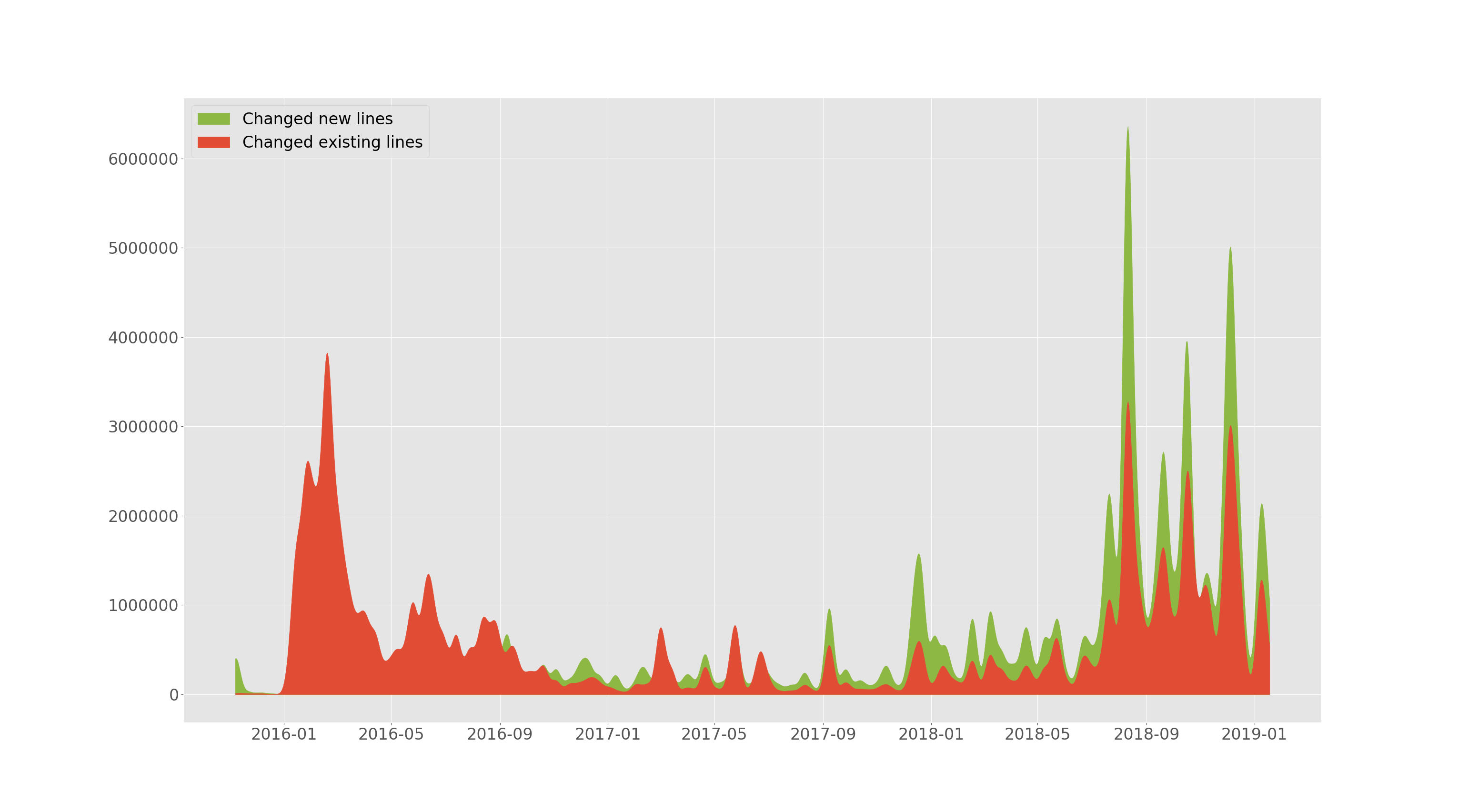
เทนเซอร์โฟลว์/เทนเซอร์โฟลว์เพิ่มและเปลี่ยนบรรทัดตามเวลา
hercules --devs [--people-dict=/path/to/identities]
labours -m old-vs-new -o <name>
--devs จากส่วนก่อนหน้านี้ช่วยให้สามารถพล็อตจำนวนบรรทัดที่ถูกเพิ่มและจำนวนการเปลี่ยนแปลงที่มีอยู่ (ลบหรือแทนที่) เมื่อเวลาผ่านไป โครงเรื่องนี้เรียบขึ้น
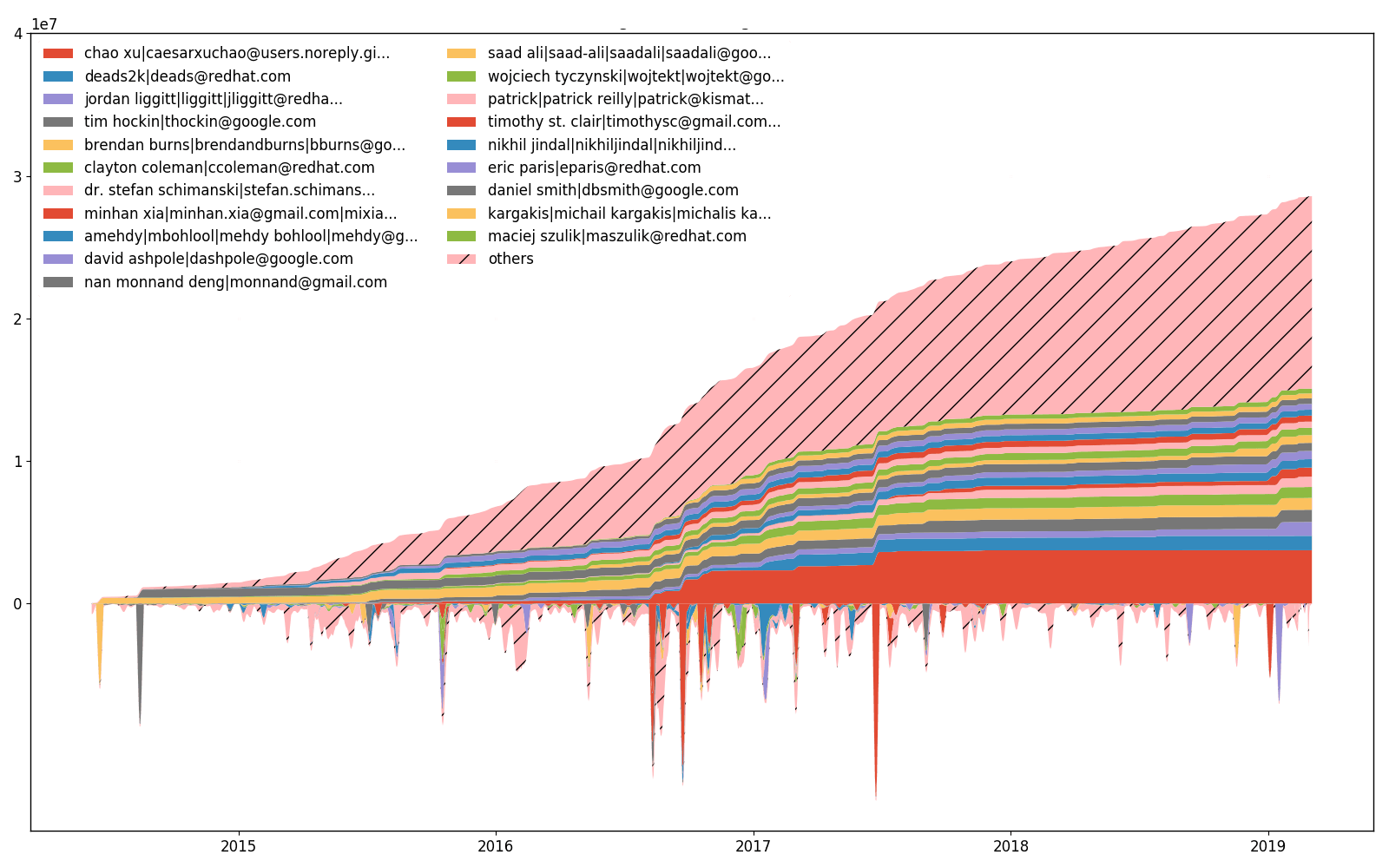
ความพยายามของ kubernetes/kubernetes เมื่อเวลาผ่านไป
hercules --devs [--people-dict=/path/to/identities]
labours -m devs-efforts -o <name>
นอกจากนี้ --devs ยังอนุญาตให้พล็อตจำนวนบรรทัดที่นักพัฒนาแต่ละคนเปลี่ยนแปลง (เพิ่มหรือลบ) ส่วนบนของแปลงเป็นส่วนล่างสะสม (บูรณาการ) เป็นไปไม่ได้ที่จะมีมาตราส่วนเท่ากันสำหรับทั้งสองส่วน ดังนั้นค่าที่ต่ำกว่าจะถูกปรับขนาด และด้วยเหตุนี้จึงไม่มีการทำเครื่องหมายที่แกน Y ที่ต่ำกว่า มีความแตกต่างระหว่างแผนความพยายามและแผนความเป็นเจ้าของ แม้ว่าการเปลี่ยนบรรทัดจะมีความสัมพันธ์กับเส้นการเป็นเจ้าของก็ตาม
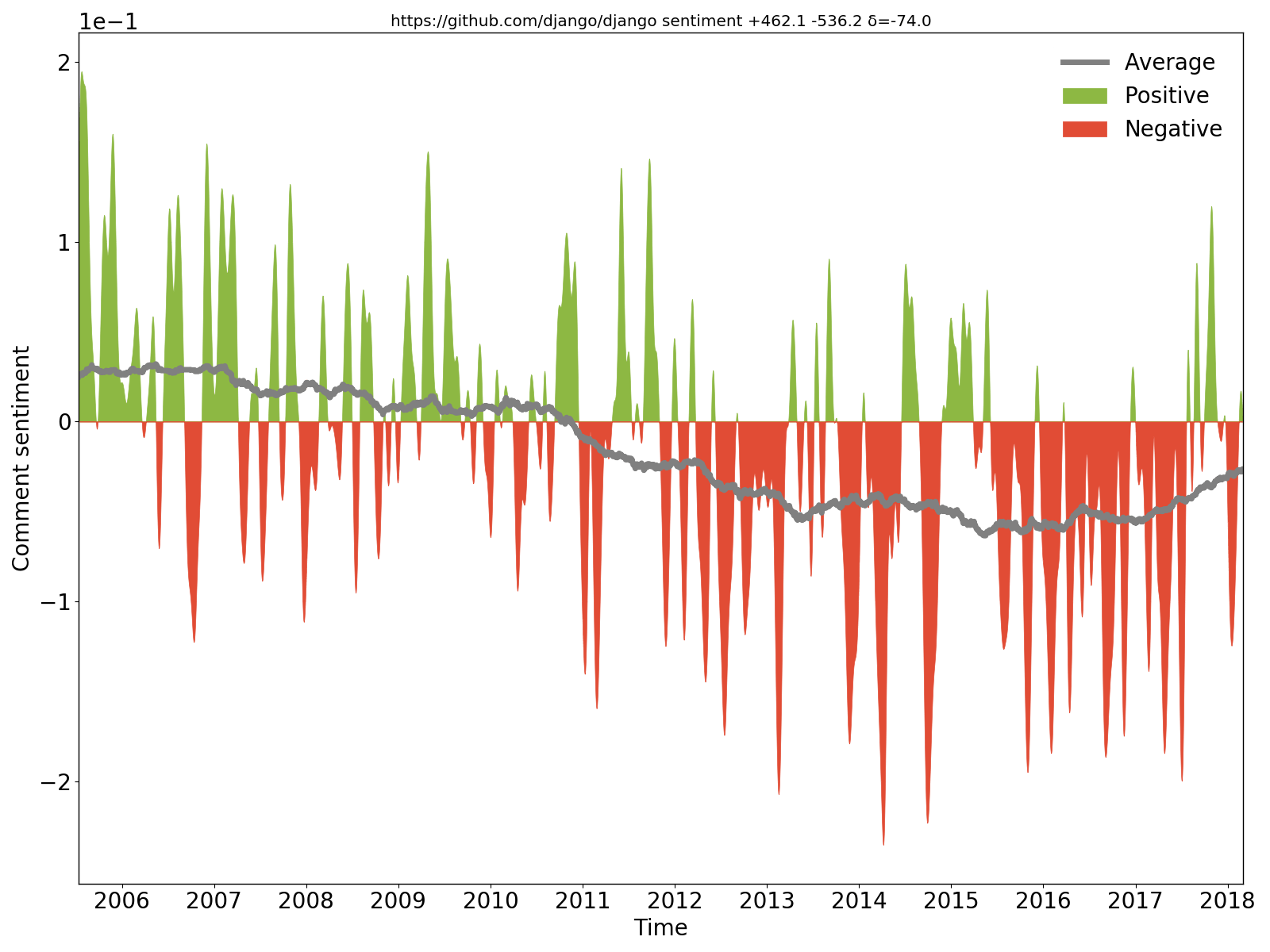
จะเห็นได้อย่างชัดเจนว่าความคิดเห็นของ Django นั้นเป็นเชิงบวก/ในแง่ดีในตอนแรก แต่ต่อมากลายเป็นเชิงลบ/ในแง่ร้าย
hercules --sentiment --pb https://github.com/django/django | labours -m sentiment -f pb
เราแยกความคิดเห็นใหม่และที่เปลี่ยนแปลงออกจากซอร์สโค้ดในทุกคอมมิต ใช้ BiDiSentiment ความรู้สึกทั่วไปของโครงข่ายประสาทเทียมที่เกิดซ้ำ และวางแผนผลลัพธ์ ต้องใช้ libtensorflow เช่น sadly, we need to hide the rect from the documentation finder for now เป็นค่าลบ และ Theano has a built-in optimization for logsumexp (...) so we can just write the expression directly เป็นค่าบวก อย่าคาดหวังมากเกินไป ตามที่เขียนไว้ โมเดลความรู้สึกนั้นมีจุดประสงค์ทั่วไป และความคิดเห็นของโค้ดมีลักษณะที่แตกต่างกัน ดังนั้นจึงไม่มีเวทย์มนตร์ (สำหรับตอนนี้)
Hercules ต้องสร้างด้วยแท็ก "tensorflow" - ไม่ใช่ตามค่าเริ่มต้น:
make TAGS=tensorflow
บิลด์ดังกล่าวต้องการ libtensorflow
hercules --burndown --burndown-files --burndown-people --couples --shotness --devs [--people-dict=/path/to/identities]
labours -m all
Hercules มีระบบปลั๊กอินและอนุญาตให้เรียกใช้การวิเคราะห์แบบกำหนดเองได้ ดูที่ PLUGINS.md
hercules combine เป็นคำสั่งที่รวมผลการวิเคราะห์หลายรายการในรูปแบบ Protocol Buffers เข้าด้วยกัน
hercules --burndown --pb https://github.com/go-git/go-git > go-git.pb
hercules --burndown --pb https://github.com/src-d/hercules > hercules.pb
hercules combine go-git.pb hercules.pb | labours -f pb -m burndown-project --resample M
YAML ไม่รองรับอักขระ Unicode ทั้งช่วง และตัวแยกวิเคราะห์ฝั่ง labours อาจทำให้เกิดข้อยกเว้น กรองเอาต์พุตจาก hercules ผ่าน fix_yaml_unicode.py เพื่อละทิ้งอักขระที่ไม่เหมาะสมดังกล่าว
hercules --burndown --burndown-people https://github.com/... | python3 fix_yaml_unicode.py | labours -m people
ตัวเลือกเหล่านี้มีผลกับแปลงทั้งหมด:
labours [--style=white|black] [--backend=] [--size=Y,X]
--style กำหนดรูปแบบทั่วไปของโครงเรื่อง (ดูที่ labours --help ) --background เปลี่ยนพื้นหลังพล็อตเป็นสีขาวหรือสีดำ --backend เลือกแบ็กเอนด์ Matplotlib --size กำหนดขนาดของตัวเลขเป็นนิ้ว ค่าเริ่มต้นคือ 12,9
(จำเป็นใน macOS) คุณสามารถปักหมุดแบ็กเอนด์ Matplotlib เริ่มต้นได้
echo "backend: TkAgg" > ~/.matplotlib/matplotlibrc
ตัวเลือกเหล่านี้มีผลกับแผนภูมิ Burndown เท่านั้น:
labours [--text-size] [--relative]
--text-size เปลี่ยนขนาดตัวอักษร --relative เปิดใช้งานเค้าโครงเบิร์นดาวน์แบบขยาย
สามารถส่งออกข้อมูลทั้งหมดที่จำเป็นในการวาดแปลงในรูปแบบ JSON เพียงต่อท้าย .json เข้ากับเอาต์พุต ( -o ) เท่านี้ก็เสร็จแล้ว รูปแบบข้อมูลไม่ได้ระบุอย่างครบถ้วนและขึ้นอยู่กับโค้ด Python ที่สร้างรูปแบบดังกล่าว ไฟล์ JSON แต่ละไฟล์ควรมี "type" ซึ่งแสดงถึงประเภทการลงจุด
--first-parent เป็นวิธีการแก้ปัญหาชั่วคราวhercules ' สำหรับเคอร์เนล Linux ในโหมด "คู่รัก" คือ 1.5 GB และใช้เวลามากกว่าหนึ่งชั่วโมง / RAM 180GB ในการแยกวิเคราะห์ อย่างไรก็ตาม พื้นที่เก็บข้อมูลส่วนใหญ่จะถูกแยกวิเคราะห์ภายในหนึ่งนาที ลองใช้ Protocol Buffers แทน ( hercules --pb และ labours -f pb ) # Debian, Ubuntu
apt install libyaml-dev
# macOS
brew install yaml-cpp libyaml
# you might need to re-install pyyaml for changes to make effect
pip uninstall pyyaml
pip --no-cache-dir install pyyaml
หากพื้นที่เก็บข้อมูลที่วิเคราะห์มีขนาดใหญ่และใช้การแยกสาขาอย่างกว้างขวาง การรวบรวมสถิติการเบิร์นดาวน์อาจล้มเหลวด้วย OOM คุณควรลองทำสิ่งต่อไปนี้:
--skip-blacklist เพื่อหลีกเลี่ยงการวิเคราะห์ไฟล์ที่ไม่ต้องการ นอกจากนี้ยังเป็นไปได้ที่จะจำกัด --language ภาษา--hibernation-distance 10 --burndown-hibernation-threshold=1000 เล่นกับตัวเลขสองตัวนั้นเพื่อเริ่มจำศีลก่อน OOM--burndown-hibernation-disk --burndown-hibernation-dir /path--first-parent คุณชนะ src-d/go-git เป็น go-git/go-git อัปเกรดโค้ดเบสให้เข้ากันได้กับเวอร์ชัน Go ล่าสุด 

