เครื่องมือสำหรับส่วนขยายอรรถาภิธานโดยใช้วิธีการขยายพันธุ์ฉลาก จากคลังข้อความและอรรถาภิธานที่มีอยู่ สร้างคำแนะนำสำหรับการขยายชุดคำพ้องความหมายที่มีอยู่ เครื่องมือนี้ได้รับการพัฒนาในระหว่างวิทยานิพนธ์ระดับปริญญาโท " การเผยแพร่ฉลากสำหรับการขยายอรรถาภิธานกฎหมายภาษี " ที่เก้าอี้ "วิศวกรรมซอฟต์แวร์สำหรับระบบสารสนเทศธุรกิจ (sebis)" มหาวิทยาลัยเทคนิคแห่งมิวนิค (TUM)
บทคัดย่อวิทยานิพนธ์. ด้วยการเพิ่มขึ้นของระบบดิจิทัล การเรียกค้นข้อมูลจะต้องรับมือกับปริมาณเนื้อหาดิจิทัลที่เพิ่มขึ้น ผู้ให้บริการเนื้อหาด้านกฎหมายลงทุนเงินเป็นจำนวนมากเพื่อสร้างออนโทโลยีเฉพาะโดเมน เช่น พจนานุกรม เพื่อเรียกค้นเอกสารที่เกี่ยวข้องในจำนวนที่เพิ่มขึ้นอย่างมาก ตั้งแต่ปี 2002 เป็นต้นมา ได้มีการพัฒนาวิธีการเผยแพร่ฉลากหลายวิธี เช่น เพื่อระบุกลุ่มของโหนดที่คล้ายกันในกราฟ การเผยแพร่ฉลากคือกลุ่มอัลกอริธึมการเรียนรู้ของเครื่องแบบกึ่งควบคุมโดยใช้กราฟ ในวิทยานิพนธ์นี้ เราจะทดสอบความเหมาะสมของวิธีการเผยแพร่ฉลากเพื่อขยายอรรถาภิธานจากขอบเขตกฎหมายภาษี กราฟที่ใช้เผยแพร่ฉลากคือกราฟความคล้ายคลึงที่สร้างขึ้นจากการฝังคำ เราครอบคลุมกระบวนการตั้งแต่ต้นจนจบและดำเนินการศึกษาพารามิเตอร์หลายอย่างเพื่อทำความเข้าใจผลกระทบของไฮเปอร์พารามิเตอร์บางตัวต่อประสิทธิภาพโดยรวม ผลลัพธ์จะได้รับการประเมินในการศึกษาด้วยตนเองและเปรียบเทียบกับแนวทางพื้นฐาน
เครื่องมือนี้ถูกนำมาใช้โดยใช้สถาปัตยกรรมไปป์และตัวกรองต่อไปนี้:
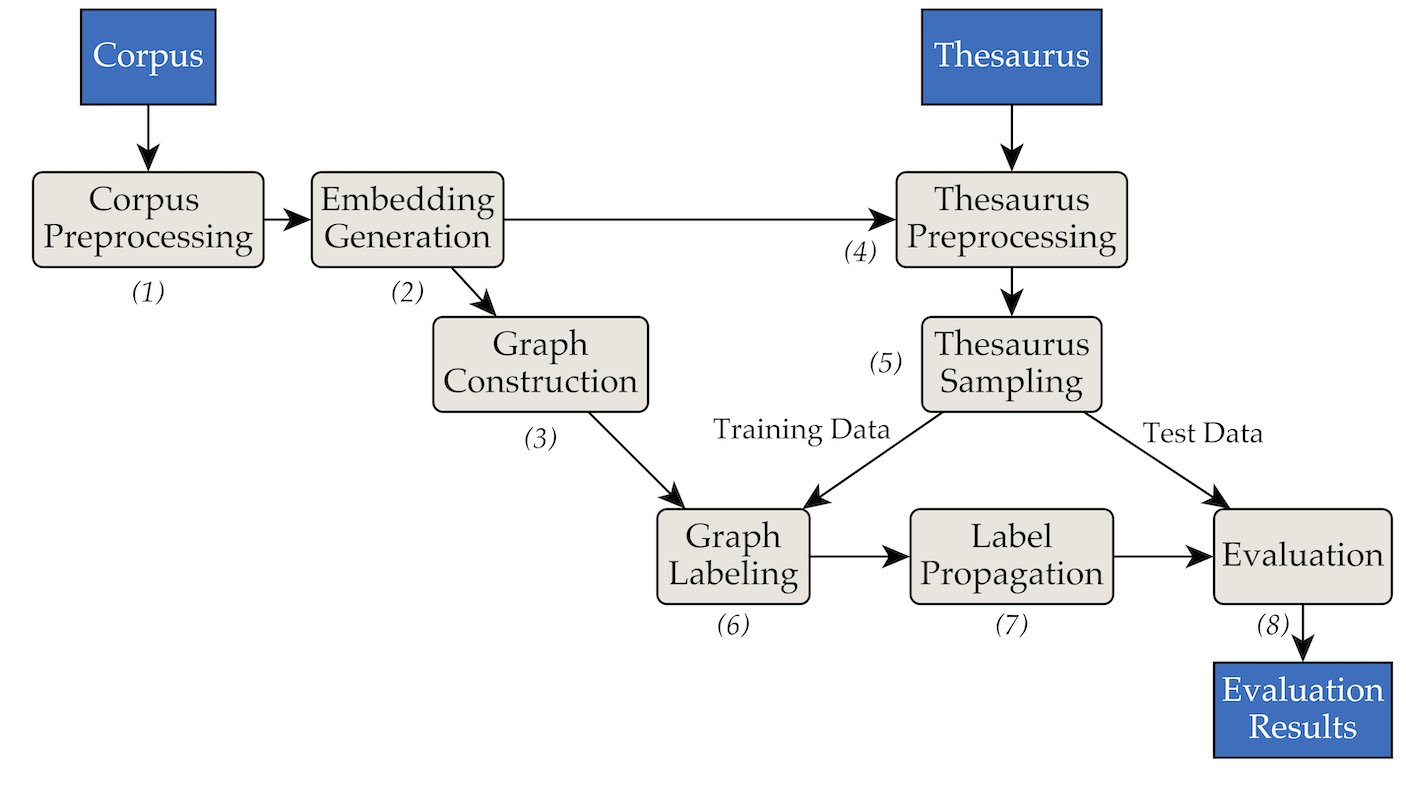
pipenv (คู่มือการติดตั้ง)pipenv install data/RW40jsons และอรรถาภิธานใน data/german_relat_pretty-20180605.json ดู Phase1.py และ Phase4.py สำหรับข้อมูลเกี่ยวกับรูปแบบไฟล์ที่ต้องการoutput/<PHASE_FOLDER>/<DATE> ที่สำคัญที่สุดคือ 08_propagation_evaluation และ XX_runs ใน 08_propagation_evaluation สถิติการประเมินจะถูกจัดเก็บเป็น stats.json ร่วมกับตารางที่มีการคาดคะเน การฝึกอบรม และชุดการทดสอบ ( main.txt ในสคริปต์อื่นๆ ที่มักเรียกว่า df_evaluation ) ใน XX_runs บันทึกการรันจะถูกจัดเก็บ หากมีการเรียกใช้หลายรันผ่าน multi_runs.py (แต่ละรันมีชุดการฝึก/การทดสอบที่แตกต่างกัน) สถิติรวมของการรันแต่ละครั้งทั้งหมดจะถูกจัดเก็บเป็น all_stats.json เช่นกัน ผ่าน purew2v_parameter_studies.py คุณสามารถดำเนินการ synset vector baseline ที่เราแนะนำในวิทยานิพนธ์ของเราได้ ต้องใช้ชุดของการฝังคำและการแยกการฝึกอบรม/การทดสอบอรรถาภิธานหนึ่งหรือหลายรายการ ดูตัวอย่าง_commands.md
ใน ipynbs เราได้จัดเตรียมสมุดบันทึก Jupyter ที่เป็นแบบอย่างซึ่งใช้ในการสร้าง (ก) สถิติ (ข) ไดอะแกรม และ (ค) ไฟล์ Excel สำหรับการประเมินด้วยตนเอง คุณสามารถสำรวจพวกมันได้ด้วยการรัน pipenv shell จากนั้นเริ่ม Jupyter ด้วย jupyter notebook
main.py หรือ multi_run.py

