หลักสูตรตัวอย่างภาษาขนาดใหญ่
- ติดตามฉันทาง X • ? การกอดใบหน้า • บล็อก • ? GNN เชิงปฏิบัติ
หลักสูตร LLM แบ่งออกเป็นสามส่วน:
- - LLM Fundamentals ครอบคลุมความรู้ที่จำเป็นเกี่ยวกับคณิตศาสตร์ Python และโครงข่ายประสาทเทียม
- ?? นักวิทยาศาสตร์ LLM มุ่งเน้นไปที่การสร้าง LLM ที่ดีที่สุดเท่าที่จะเป็นไปได้โดยใช้เทคนิคล่าสุด
- - วิศวกร LLM มุ่งเน้นไปที่การสร้างแอปพลิเคชันที่ใช้ LLM และปรับใช้
สำหรับหลักสูตรแบบโต้ตอบนี้ ฉันได้สร้าง ผู้ช่วย LLM สองคนที่จะตอบคำถามและทดสอบความรู้ของคุณในแบบที่เป็นส่วนตัว:
- - HuggingChat Assistant : เวอร์ชันฟรีโดยใช้ Mixtral-8x7B
- - ChatGPT Assistant : ต้องมีบัญชีพรีเมียม
โน๊ตบุ๊ค
รายชื่อสมุดบันทึกและบทความที่เกี่ยวข้องกับโมเดลภาษาขนาดใหญ่
เครื่องมือ
| โน๊ตบุ๊ค | คำอธิบาย | โน๊ตบุ๊ค |
|---|
| - LLM การประเมินอัตโนมัติ | ประเมิน LLM ของคุณโดยอัตโนมัติโดยใช้ RunPod | |
| - LazyMergekit | ผสานโมเดลได้อย่างง่ายดายโดยใช้ MergeKit ในคลิกเดียว | |
| - ขี้เกียจAxolotl | ปรับแต่งโมเดลในระบบคลาวด์โดยใช้ Axolotl ได้ในคลิกเดียว | |
| ⚡ ออโต้ควอนท์ | หาปริมาณ LLM ในรูปแบบ GGUF, GPTQ, EXL2, AWQ และ HQQ ได้ในคลิกเดียว | |
| - โมเดลต้นไม้ครอบครัว | แสดงภาพแผนผังลำดับวงศ์ตระกูลของโมเดลที่ผสานกัน | |
| ซีโร่สเปซ | สร้างอินเทอร์เฟซแชท Gradio โดยอัตโนมัติโดยใช้ ZeroGPU ฟรี | |
การปรับแต่งแบบละเอียด
| โน๊ตบุ๊ค | คำอธิบาย | บทความ | โน๊ตบุ๊ค |
|---|
| ปรับแต่ง Llama 2 ด้วย QLoRA | คำแนะนำทีละขั้นตอนเพื่อควบคุมการปรับแต่ง Llama 2 ใน Google Colab | บทความ | |
| ปรับแต่ง CodeLlama โดยใช้ Axolotl | คำแนะนำแบบครบวงจรเกี่ยวกับเครื่องมือล้ำสมัยสำหรับการปรับแต่งแบบละเอียด | บทความ | |
| ปรับแต่ง Mistral-7b ด้วย QLoRA | ควบคุมดูแลการปรับแต่ง Mistral-7b ใน Google Colab ระดับฟรีพร้อม TRL | | |
| ปรับแต่ง Mistral-7b ด้วย DPO | เพิ่มประสิทธิภาพของโมเดลที่ได้รับการปรับแต่งอย่างละเอียดภายใต้การดูแลด้วย DPO | บทความ | |
| ปรับแต่ง Llama 3 ด้วย ORPO | การปรับแต่งแบบละเอียดที่ถูกกว่าและเร็วขึ้นในขั้นตอนเดียวด้วย ORPO | บทความ | |
| ปรับแต่ง Llama 3.1 ด้วย Unsloth | การปรับแต่งแบบละเอียดภายใต้การดูแลที่มีประสิทธิภาพเป็นพิเศษใน Google Colab | บทความ | |
การหาปริมาณ
| โน๊ตบุ๊ค | คำอธิบาย | บทความ | โน๊ตบุ๊ค |
|---|
| ความรู้เบื้องต้นเกี่ยวกับการหาปริมาณ | การเพิ่มประสิทธิภาพโมเดลภาษาขนาดใหญ่โดยใช้การหาปริมาณ 8 บิต | บทความ | |
| การหาปริมาณ 4 บิตโดยใช้ GPTQ | กำหนดปริมาณ LLM แบบโอเพ่นซอร์สของคุณเองเพื่อรันบนฮาร์ดแวร์สำหรับผู้บริโภค | บทความ | |
| การหาปริมาณด้วย GGUF และ llama.cpp | จัดปริมาณโมเดล Llama 2 ด้วย llama.cpp และอัปโหลดเวอร์ชัน GGUF ไปยัง HF Hub | บทความ | |
| ExLlamaV2: ไลบรารีที่เร็วที่สุดในการรัน LLM | หาปริมาณและรันโมเดล EXL2 แล้วอัปโหลดไปยัง HF Hub | บทความ | |
อื่น
| โน๊ตบุ๊ค | คำอธิบาย | บทความ | โน๊ตบุ๊ค |
|---|
| กลยุทธ์การถอดรหัสในโมเดลภาษาขนาดใหญ่ | คำแนะนำในการสร้างข้อความตั้งแต่การค้นหาบีมไปจนถึงการสุ่มตัวอย่างนิวเคลียส | บทความ | |
| ปรับปรุง ChatGPT ด้วยกราฟความรู้ | เพิ่มคำตอบของ ChatGPT ด้วยกราฟความรู้ | บทความ | |
| ผสาน LLM เข้ากับ MergeKit | สร้างโมเดลของคุณเองได้ง่ายๆ ไม่ต้องใช้ GPU! | บทความ | |
| สร้าง MoE ด้วย MergeKit | รวมผู้เชี่ยวชาญหลายคนไว้ใน frankenMoE เดียว | บทความ | |
| Uncensor LLM ใด ๆ ที่มีการลบล้าง | การปรับแต่งแบบละเอียดโดยไม่ต้องฝึกอบรมซ้ำ | บทความ | |
- ความรู้พื้นฐาน LLM
ส่วนนี้จะแนะนำความรู้ที่จำเป็นเกี่ยวกับคณิตศาสตร์ Python และโครงข่ายประสาทเทียม คุณอาจไม่ต้องการเริ่มต้นที่นี่แต่อ้างอิงตามความจำเป็น
สลับส่วน
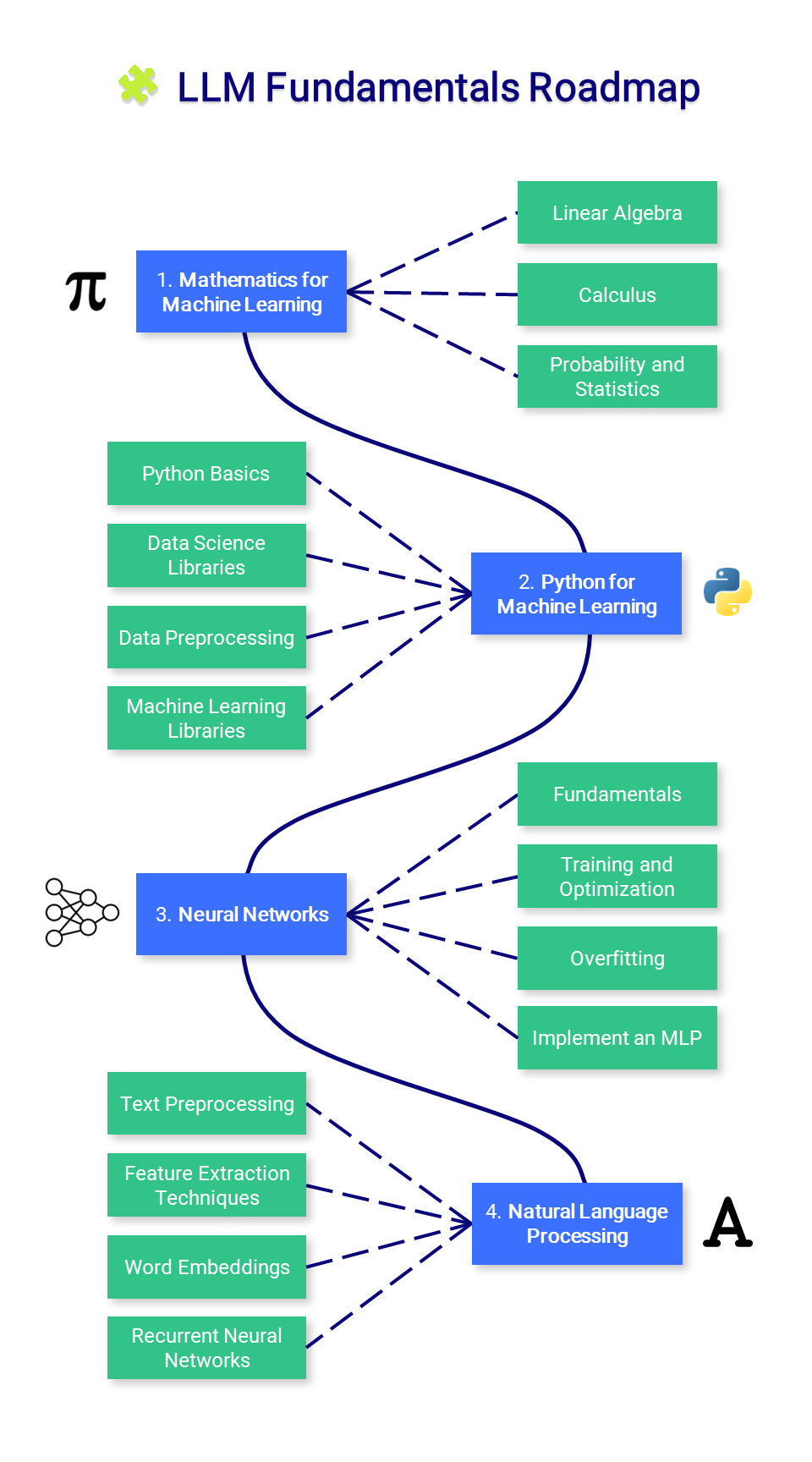
1. คณิตศาสตร์เพื่อการเรียนรู้ของเครื่อง
ก่อนที่จะเชี่ยวชาญการเรียนรู้ของเครื่อง สิ่งสำคัญคือต้องเข้าใจแนวคิดทางคณิตศาสตร์พื้นฐานที่ขับเคลื่อนอัลกอริธึมเหล่านี้
- พีชคณิตเชิงเส้น : นี่เป็นสิ่งสำคัญสำหรับการทำความเข้าใจอัลกอริธึมต่างๆ โดยเฉพาะอัลกอริธึมที่ใช้ในการเรียนรู้เชิงลึก แนวคิดหลักได้แก่ เวกเตอร์ เมทริกซ์ ดีเทอร์มิแนนต์ ค่าลักษณะเฉพาะและเวกเตอร์ลักษณะเฉพาะ ปริภูมิเวกเตอร์ และการแปลงเชิงเส้น
- แคลคูลัส : อัลกอริธึมการเรียนรู้ของเครื่องจำนวนมากเกี่ยวข้องกับการปรับฟังก์ชันต่อเนื่องให้เหมาะสม ซึ่งต้องใช้ความเข้าใจเกี่ยวกับอนุพันธ์ ปริพันธ์ ลิมิต และอนุกรม แคลคูลัสหลายตัวแปรและแนวคิดเรื่องการไล่ระดับสีก็มีความสำคัญเช่นกัน
- ความน่าจะเป็นและสถิติ : สิ่งเหล่านี้มีความสำคัญอย่างยิ่งต่อการทำความเข้าใจว่าแบบจำลองเรียนรู้จากข้อมูลและคาดการณ์ได้อย่างไร แนวคิดหลัก ได้แก่ ทฤษฎีความน่าจะเป็น ตัวแปรสุ่ม การแจกแจงความน่าจะเป็น การคาดหวัง ความแปรปรวน ความแปรปรวนร่วม ความสัมพันธ์ การทดสอบสมมติฐาน ช่วงความเชื่อมั่น การประมาณค่าความน่าจะเป็นสูงสุด และการอนุมานแบบเบย์
ทรัพยากร:
- 3Blue1Brown - สาระสำคัญของพีชคณิตเชิงเส้น: ชุดวิดีโอที่ให้สัญชาตญาณทางเรขาคณิตกับแนวคิดเหล่านี้
- StatQuest กับ Josh Starmer - ความรู้พื้นฐานด้านสถิติ: ให้คำอธิบายที่เรียบง่ายและชัดเจนสำหรับแนวคิดทางสถิติมากมาย
- AP Statistics Intuition โดย Ms Aerin: รายการบทความขนาดกลางที่ให้สัญชาตญาณเบื้องหลังการแจกแจงความน่าจะเป็นทุกครั้ง
- พีชคณิตเชิงเส้นแบบดื่มด่ำ: อีกการตีความพีชคณิตเชิงเส้นด้วยภาพ
- Khan Academy - พีชคณิตเชิงเส้น: เหมาะสำหรับผู้เริ่มต้นเนื่องจากอธิบายแนวคิดด้วยวิธีที่ใช้งานง่าย
- Khan Academy - แคลคูลัส: หลักสูตรเชิงโต้ตอบที่ครอบคลุมพื้นฐานแคลคูลัสทั้งหมด
- Khan Academy - ความน่าจะเป็นและสถิติ: นำเสนอเนื้อหาในรูปแบบที่เข้าใจง่าย
2. Python สำหรับการเรียนรู้ของเครื่อง
Python เป็นภาษาโปรแกรมที่ทรงพลังและยืดหยุ่นซึ่งดีสำหรับการเรียนรู้ของเครื่องเป็นพิเศษ เนื่องจากสามารถอ่านได้ ความสม่ำเสมอ และระบบนิเวศที่แข็งแกร่งของไลบรารีวิทยาศาสตร์ข้อมูล
- พื้นฐาน Python : การเขียนโปรแกรม Python จำเป็นต้องมีความเข้าใจที่ดีเกี่ยวกับไวยากรณ์พื้นฐาน ประเภทข้อมูล การจัดการข้อผิดพลาด และการเขียนโปรแกรมเชิงวัตถุ
- ไลบรารีวิทยาศาสตร์ข้อมูล : ประกอบด้วยความคุ้นเคยกับ NumPy สำหรับการดำเนินการเชิงตัวเลข, Pandas สำหรับการจัดการและวิเคราะห์ข้อมูล, Matplotlib และ Seaborn สำหรับการแสดงภาพข้อมูล
- การประมวลผลข้อมูลล่วงหน้า : สิ่งนี้เกี่ยวข้องกับการปรับขนาดฟีเจอร์และการทำให้เป็นมาตรฐาน การจัดการข้อมูลที่ขาดหายไป การตรวจจับค่าผิดปกติ การเข้ารหัสข้อมูลแบบหมวดหมู่ และการแบ่งข้อมูลออกเป็นชุดการฝึก การตรวจสอบ และชุดการทดสอบ
- ห้องสมุดการเรียนรู้ของเครื่อง : ความชำนาญกับ Scikit-learn ซึ่งเป็นห้องสมุดที่มีอัลกอริธึมการเรียนรู้แบบมีผู้ดูแลและไม่ได้รับการดูแลให้เลือกมากมายถือเป็นสิ่งสำคัญ การทำความเข้าใจวิธีการใช้อัลกอริธึม เช่น การถดถอยเชิงเส้น การถดถอยโลจิสติก แผนผังการตัดสินใจ ฟอเรสต์สุ่ม เพื่อนบ้านที่ใกล้ที่สุด k (K-NN) และการจัดกลุ่มเคมีนเป็นสิ่งสำคัญ เทคนิคการลดขนาด เช่น PCA และ t-SNE ยังมีประโยชน์ในการแสดงภาพข้อมูลที่มีมิติสูงอีกด้วย
ทรัพยากร:
- Real Python: แหล่งข้อมูลที่ครอบคลุมพร้อมบทความและบทช่วยสอนสำหรับแนวคิด Python ระดับเริ่มต้นและขั้นสูง
- freeCodeCamp - เรียนรู้ Python: วิดีโอขนาดยาวที่ให้ข้อมูลเบื้องต้นอย่างครบถ้วนเกี่ยวกับแนวคิดหลักทั้งหมดใน Python
- คู่มือ Python Data Science: หนังสือดิจิทัลฟรีที่เป็นแหล่งข้อมูลที่ดีสำหรับการเรียนรู้แพนด้า, NumPy, Matplotlib และ Seaborn
- freeCodeCamp - การเรียนรู้ของเครื่องสำหรับทุกคน: บทนำเชิงปฏิบัติเกี่ยวกับอัลกอริธึมการเรียนรู้ของเครื่องต่างๆ สำหรับผู้เริ่มต้น
- Udacity - ข้อมูลเบื้องต้นเกี่ยวกับ Machine Learning: หลักสูตรฟรีที่ครอบคลุม PCA และแนวคิด Machine Learning อื่นๆ อีกมากมาย
3. โครงข่ายประสาทเทียม
โครงข่ายประสาทเทียมเป็นส่วนพื้นฐานของโมเดลการเรียนรู้ของเครื่องหลายๆ โมเดล โดยเฉพาะอย่างยิ่งในขอบเขตของการเรียนรู้เชิงลึก เพื่อให้ใช้งานได้อย่างมีประสิทธิภาพ ความเข้าใจอย่างครอบคลุมเกี่ยวกับการออกแบบและกลไกเป็นสิ่งสำคัญ
- พื้นฐาน : ซึ่งรวมถึงการทำความเข้าใจโครงสร้างของโครงข่ายประสาทเทียม เช่น เลเยอร์ น้ำหนัก อคติ และฟังก์ชันการเปิดใช้งาน (sigmoid, tanh, ReLU ฯลฯ)
- การฝึกอบรมและการเพิ่มประสิทธิภาพ : ทำความคุ้นเคยกับการเผยแพร่กลับและฟังก์ชันการสูญเสียประเภทต่างๆ เช่น Mean Squared Error (MSE) และ Cross-Entropy ทำความเข้าใจอัลกอริธึมการปรับให้เหมาะสมต่างๆ เช่น Gradient Descent, Stochastic Gradient Descent, RMSprop และ Adam
- การติดตั้งมากเกินไป : ทำความเข้าใจแนวคิดของการติดตั้งมากเกินไป (โดยที่แบบจำลองทำงานได้ดีกับข้อมูลการฝึกอบรมแต่มีข้อมูลที่มองไม่เห็นไม่ดี) และเรียนรู้เทคนิคการทำให้เป็นมาตรฐานต่างๆ (การออกกลางคัน การทำให้เป็นมาตรฐาน L1/L2 การหยุดก่อนกำหนด การเพิ่มข้อมูล) เพื่อป้องกันสิ่งนี้
- ใช้งาน Multilayer Perceptron (MLP) : สร้าง MLP หรือที่เรียกว่าเครือข่ายที่เชื่อมต่อโดยสมบูรณ์ โดยใช้ PyTorch
ทรัพยากร:
- 3Blue1Brown - แต่โครงข่ายประสาทเทียมคืออะไร: วิดีโอนี้ให้คำอธิบายที่เข้าใจง่ายเกี่ยวกับโครงข่ายประสาทเทียมและการทำงานภายในของโครงข่ายประสาทเทียม
- freeCodeCamp - Deep Learning Crash Course: วิดีโอนี้แนะนำแนวคิดที่สำคัญที่สุดทั้งหมดในการเรียนรู้เชิงลึกอย่างมีประสิทธิภาพ
- Fast.ai - การเรียนรู้เชิงลึกเชิงปฏิบัติ: หลักสูตรฟรีที่ออกแบบมาสำหรับผู้ที่มีประสบการณ์การเขียนโค้ดที่ต้องการเรียนรู้เกี่ยวกับการเรียนรู้เชิงลึก
- Patrick Loeber - บทช่วยสอน PyTorch: ชุดวิดีโอสำหรับผู้เริ่มต้นที่สมบูรณ์เพื่อเรียนรู้เกี่ยวกับ PyTorch
4. การประมวลผลภาษาธรรมชาติ (NLP)
NLP เป็นสาขาที่น่าสนใจของปัญญาประดิษฐ์ที่เชื่อมช่องว่างระหว่างภาษามนุษย์และความเข้าใจของเครื่องจักร ตั้งแต่การประมวลผลข้อความธรรมดาไปจนถึงการทำความเข้าใจความแตกต่างทางภาษา NLP มีบทบาทสำคัญในแอปพลิเคชันมากมาย เช่น การแปล การวิเคราะห์ความรู้สึก แชทบอท และอื่นๆ อีกมากมาย
- การประมวลผลข้อความล่วงหน้า : เรียนรู้ขั้นตอนต่างๆ ในการประมวลผลข้อความล่วงหน้า เช่น การทำให้เป็นโทเค็น (การแยกข้อความออกเป็นคำหรือประโยค) การกั้นคำ (การลดคำให้อยู่ในรูปราก) การย่อคำ (คล้ายกับการกั้นคำแต่คำนึงถึงบริบท) การหยุดการลบคำ เป็นต้น
- เทคนิคการแยกคุณสมบัติ : ทำความคุ้นเคยกับเทคนิคในการแปลงข้อมูลข้อความเป็นรูปแบบที่อัลกอริธึมการเรียนรู้ของเครื่องสามารถเข้าใจได้ วิธีการหลัก ได้แก่ Bag-of-words (BoW), ความถี่ของคำ-ความถี่เอกสารผกผัน (TF-IDF) และ n-grams
- การฝังคำ : การฝังคำเป็นรูปแบบหนึ่งของการแสดงคำที่ช่วยให้คำที่มีความหมายคล้ายกันสามารถมีการแสดงที่คล้ายกันได้ วิธีการหลัก ได้แก่ Word2Vec, GloVe และ FastText
- โครงข่ายประสาทเทียมที่เกิดซ้ำ (RNN) : ทำความเข้าใจการทำงานของ RNN ซึ่งเป็นโครงข่ายประสาทเทียมประเภทหนึ่งที่ออกแบบมาเพื่อทำงานกับข้อมูลลำดับ สำรวจ LSTM และ GRU ซึ่งเป็น RNN 2 สายพันธุ์ที่สามารถเรียนรู้การพึ่งพาในระยะยาว
ทรัพยากร:
- RealPython - NLP พร้อม spaCy ใน Python: คำแนะนำโดยละเอียดเกี่ยวกับไลบรารี spaCy สำหรับงาน NLP ใน Python
- Kaggle - คู่มือ NLP: สมุดบันทึกและแหล่งข้อมูลบางส่วนสำหรับคำอธิบาย NLP ใน Python แบบลงมือปฏิบัติจริง
- Jay Alammar - ภาพประกอบ Word2Vec: ข้อมูลอ้างอิงที่ดีในการทำความเข้าใจสถาปัตยกรรม Word2Vec ที่มีชื่อเสียง
- Jake Tae - PyTorch RNN จาก Scratch: การใช้งานโมเดล RNN, LSTM และ GRU ใน PyTorch ในทางปฏิบัติและง่ายดาย
- บล็อกของ colah - การทำความเข้าใจเครือข่าย LSTM: บทความเชิงทฤษฎีเพิ่มเติมเกี่ยวกับเครือข่าย LSTM
?? นักวิทยาศาสตร์ LLM
เนื้อหาในส่วนนี้ของหลักสูตรมุ่งเน้นไปที่การเรียนรู้วิธีสร้าง LLM ที่ดีที่สุดเท่าที่จะเป็นไปได้โดยใช้เทคนิคล่าสุด
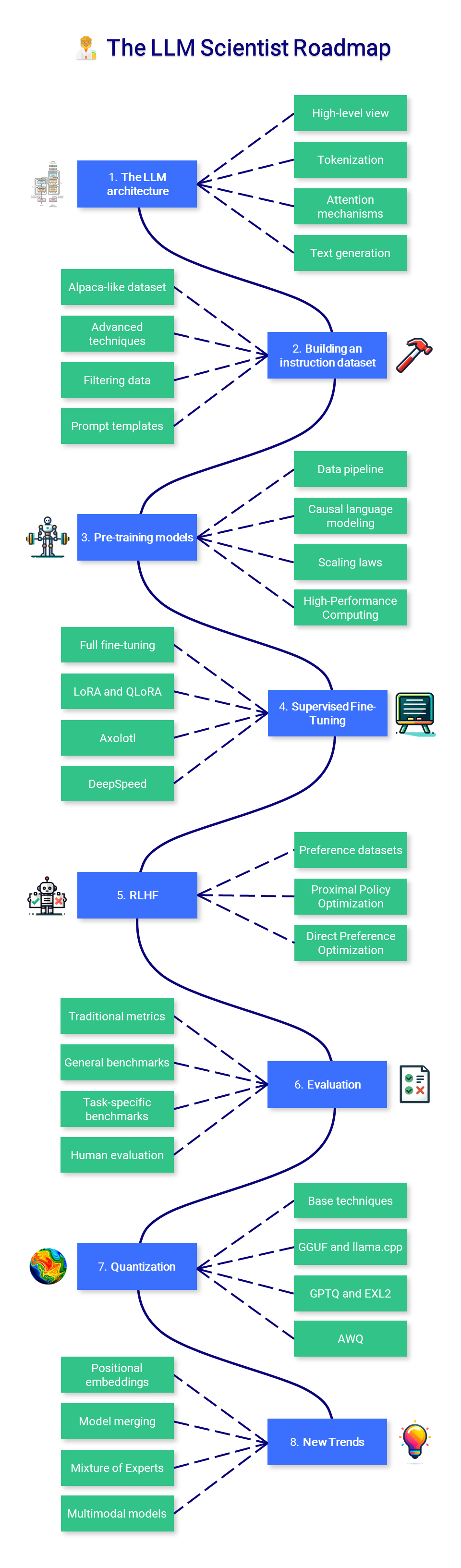
1. สถาปัตยกรรม LLM
แม้ว่าไม่จำเป็นต้องมีความรู้เชิงลึกเกี่ยวกับสถาปัตยกรรม Transformer แต่สิ่งสำคัญคือต้องมีความเข้าใจที่ดีเกี่ยวกับอินพุต (โทเค็น) และเอาต์พุต (บันทึก) กลไกการดึงดูดความสนใจแบบวานิลลาเป็นอีกองค์ประกอบสำคัญที่ต้องฝึกฝน เนื่องจากเวอร์ชันที่ได้รับการปรับปรุงจะถูกนำมาใช้ในภายหลัง
- มุมมองระดับสูง : ทบทวนสถาปัตยกรรม Transformer ของตัวเข้ารหัส-ตัวถอดรหัส และโดยเฉพาะเจาะจงมากขึ้นคือสถาปัตยกรรม GPT ของตัวถอดรหัสเท่านั้น ซึ่งใช้ใน LLM สมัยใหม่ทุกตัว
- Tokenization : ทำความเข้าใจวิธีแปลงข้อมูลข้อความดิบเป็นรูปแบบที่โมเดลสามารถเข้าใจได้ ซึ่งเกี่ยวข้องกับการแยกข้อความออกเป็นโทเค็น (โดยปกติจะเป็นคำหรือคำย่อย)
- กลไกความสนใจ : เข้าใจทฤษฎีเบื้องหลังกลไกความสนใจ ซึ่งรวมถึงความสนใจในตนเองและความสนใจแบบ dot-product ที่ปรับขนาดได้ ซึ่งช่วยให้แบบจำลองมุ่งเน้นไปที่ส่วนต่างๆ ของอินพุตเมื่อสร้างเอาต์พุต
- การสร้างข้อความ : เรียนรู้เกี่ยวกับวิธีการต่างๆ ที่โมเดลสามารถสร้างลำดับเอาต์พุตได้ กลยุทธ์ทั่วไป ได้แก่ การถอดรหัสอย่างละโมบ การค้นหาลำแสง การสุ่มตัวอย่าง top-k และการสุ่มตัวอย่างนิวเคลียส
อ้างอิง :
- The Illustrated Transformer โดย Jay Alammar: คำอธิบายด้วยภาพและใช้งานง่ายของโมเดล Transformer
- Illustrated GPT-2 โดย Jay Alammar: สำคัญยิ่งกว่าบทความที่แล้ว โดยมุ่งเน้นไปที่สถาปัตยกรรม GPT ซึ่งคล้ายกับของ Llama มาก
- ภาพแนะนำ Transformers โดย 3Blue1Brown: ภาพแนะนำ Transformers ที่เรียบง่ายและเข้าใจง่าย
- การสร้างภาพ LLM โดย Brendan Bycroft: การสร้างภาพ 3 มิติที่น่าทึ่งของสิ่งที่เกิดขึ้นภายใน LLM
- nanoGPT โดย Andrej Karpathy: วิดีโอ YouTube ยาว 2 ชั่วโมงเพื่อปรับใช้ GPT ใหม่ตั้งแต่ต้น (สำหรับโปรแกรมเมอร์)
- ความสนใจ? ความสนใจ! โดย Lilian Weng: แนะนำความต้องการความสนใจอย่างเป็นทางการมากขึ้น
- กลยุทธ์การถอดรหัสใน LLM: จัดเตรียมโค้ดและภาพแนะนำกลยุทธ์การถอดรหัสต่างๆ เพื่อสร้างข้อความ
2. การสร้างชุดข้อมูลคำสั่ง
แม้ว่าการค้นหาข้อมูลดิบจากวิกิพีเดียและเว็บไซต์อื่นๆ จะเป็นเรื่องง่าย แต่การรวบรวมคำแนะนำและคำตอบแบบเดิมๆ เป็นเรื่องยาก เช่นเดียวกับในการเรียนรู้ของเครื่องแบบดั้งเดิม คุณภาพของชุดข้อมูลจะส่งผลโดยตรงต่อคุณภาพของแบบจำลอง ซึ่งเป็นเหตุผลว่าทำไมจึงอาจเป็นองค์ประกอบที่สำคัญที่สุดในกระบวนการปรับแต่งอย่างละเอียด
- ชุดข้อมูลคล้ายอัลปาก้า : สร้างข้อมูลสังเคราะห์ตั้งแต่ต้นด้วย OpenAI API (GPT) คุณสามารถระบุข้อมูลเริ่มต้นและข้อความแจ้งเตือนของระบบเพื่อสร้างชุดข้อมูลที่หลากหลายได้
- เทคนิคขั้นสูง : เรียนรู้วิธีปรับปรุงชุดข้อมูลที่มีอยู่ด้วย Evol-Instruct วิธีสร้างข้อมูลสังเคราะห์คุณภาพสูง เช่น ในเอกสาร Orca และ phi-1
- การกรองข้อมูล : เทคนิคดั้งเดิมที่เกี่ยวข้องกับ regex, การลบข้อมูลที่ซ้ำกัน, เน้นไปที่คำตอบที่มีโทเค็นจำนวนมาก ฯลฯ
- เทมเพลตพร้อมท์ : ไม่มีวิธีมาตรฐานในการจัดรูปแบบคำแนะนำและคำตอบ ซึ่งเป็นเหตุผลว่าทำไมการทราบเกี่ยวกับเทมเพลตการแชทต่างๆ เช่น ChatML, Alpaca เป็นต้น จึงเป็นเรื่องสำคัญ
อ้างอิง :
- การเตรียมชุดข้อมูลสำหรับการปรับแต่งคำสั่งโดย Thomas Capelle: การสำรวจชุดข้อมูล Alpaca และ Alpaca-GPT4 และวิธีการจัดรูปแบบ
- การสร้างชุดข้อมูลคำแนะนำทางคลินิกโดย Solano Todeschini: บทช่วยสอนเกี่ยวกับวิธีสร้างชุดข้อมูลคำแนะนำแบบสังเคราะห์โดยใช้ GPT-4
- GPT 3.5 สำหรับการจัดหมวดหมู่ข่าวโดย Kshitiz Sahay: ใช้ GPT 3.5 เพื่อสร้างชุดข้อมูลคำสั่งเพื่อปรับแต่ง Llama 2 สำหรับการจัดหมวดหมู่ข่าว
- การสร้างชุดข้อมูลสำหรับการปรับแต่ง LLM อย่างละเอียด: สมุดบันทึกที่มีเทคนิคบางประการในการกรองชุดข้อมูลและอัปโหลดผลลัพธ์
- เทมเพลตการแชทโดย Matthew Carrigan: หน้า Hugging Face เกี่ยวกับเทมเพลตพร้อมท์
3. โมเดลก่อนการฝึกอบรม
การฝึกอบรมก่อนการฝึกอบรมเป็นกระบวนการที่ยาวและมีค่าใช้จ่ายสูง ซึ่งเป็นเหตุผลว่าทำไมหลักสูตรนี้จึงไม่ได้เน้นไปที่หลักสูตรนี้ การมีความเข้าใจในระดับหนึ่งเกี่ยวกับสิ่งที่เกิดขึ้นระหว่างการฝึกก่อนการฝึกอบรมถือเป็นเรื่องดี แต่ไม่จำเป็นต้องมีประสบการณ์ตรง
- ไปป์ไลน์ข้อมูล : การฝึกอบรมล่วงหน้าต้องใช้ชุดข้อมูลขนาดใหญ่ (เช่น Llama 2 ได้รับการฝึกฝนบนโทเค็น 2 ล้านล้านโทเค็น) ซึ่งจำเป็นต้องกรอง สร้างโทเค็น และจัดเรียงด้วยคำศัพท์ที่กำหนดไว้ล่วงหน้า
- การสร้างแบบจำลองภาษาเชิงสาเหตุ : เรียนรู้ความแตกต่างระหว่างการสร้างแบบจำลองภาษาเชิงสาเหตุและแบบมาสก์ รวมถึงฟังก์ชันการสูญเสียที่ใช้ในกรณีนี้ เพื่อการฝึกอบรมล่วงหน้าที่มีประสิทธิภาพ เรียนรู้เพิ่มเติมเกี่ยวกับ Megatron-LM หรือ gpt-neox
- กฎการปรับขนาด : กฎการปรับขนาดจะอธิบายประสิทธิภาพของโมเดลที่คาดหวังโดยพิจารณาจากขนาดโมเดล ขนาดชุดข้อมูล และปริมาณการประมวลผลที่ใช้สำหรับการฝึกอบรม
- คอมพิวเตอร์ประสิทธิภาพสูง : อยู่นอกขอบเขตที่นี่ แต่ความรู้เพิ่มเติมเกี่ยวกับ HPC ถือเป็นพื้นฐาน หากคุณวางแผนที่จะสร้าง LLM ของคุณเองตั้งแต่เริ่มต้น (ฮาร์ดแวร์ ปริมาณงานแบบกระจาย ฯลฯ)
อ้างอิง :
- LLMDataHub โดย Junhao Zhao: รายการชุดข้อมูลที่รวบรวมไว้สำหรับการฝึกล่วงหน้า การปรับแต่งอย่างละเอียด และ RLHF
- การฝึกอบรมโมเดลภาษาเชิงสาเหตุตั้งแต่เริ่มต้นโดย Hugging Face: ฝึกอบรมโมเดล GPT-2 ล่วงหน้าตั้งแต่เริ่มต้นโดยใช้ไลบรารี Transformers
- TinyLlama โดย Zhang และคณะ: ตรวจสอบโปรเจ็กต์นี้เพื่อทำความเข้าใจให้ดีว่าโมเดล Llama ได้รับการฝึกฝนตั้งแต่เริ่มต้นอย่างไร
- การสร้างแบบจำลองภาษาเชิงสาเหตุโดย Hugging Face: อธิบายความแตกต่างระหว่างการสร้างแบบจำลองภาษาเชิงสาเหตุและแบบมาสก์ และวิธีการปรับแต่งโมเดล DistilGPT-2 อย่างรวดเร็ว
- ผลกระทบอันรุนแรงของ Chinchilla โดยนักคิดถึงความคิดถึง: อภิปรายเกี่ยวกับกฎมาตราส่วนและอธิบายว่ากฎหมายเหล่านี้มีความหมายต่อ LLM โดยทั่วไปอย่างไร
- BLOOM โดย BigScience: หน้าแนวคิดที่อธิบายวิธีสร้างโมเดล BLOOM พร้อมข้อมูลที่เป็นประโยชน์มากมายเกี่ยวกับส่วนวิศวกรรมและปัญหาที่พบ
- OPT-175 สมุดบันทึกโดย Meta: บันทึกการวิจัยที่แสดงให้เห็นว่ามีอะไรผิดพลาดและมีอะไรถูกต้อง มีประโยชน์หากคุณวางแผนที่จะฝึกโมเดลภาษาที่มีขนาดใหญ่มากล่วงหน้า (ในกรณีนี้คือพารามิเตอร์ 175B)
- LLM 360: เฟรมเวิร์กสำหรับ LLM แบบโอเพ่นซอร์สพร้อมการฝึกอบรมและโค้ดการเตรียมข้อมูล ข้อมูล หน่วยวัด และแบบจำลอง
4. การปรับแต่งแบบละเอียดภายใต้การดูแล
โมเดลที่ได้รับการฝึกล่วงหน้าจะได้รับการฝึกเฉพาะงานการทำนายโทเค็นถัดไปเท่านั้น ซึ่งเป็นสาเหตุที่โมเดลเหล่านี้ไม่ใช่ผู้ช่วยที่เป็นประโยชน์ SFT ช่วยให้คุณปรับแต่งให้ตอบสนองต่อคำแนะนำได้ ยิ่งไปกว่านั้น ยังช่วยให้คุณปรับแต่งโมเดลของคุณกับข้อมูลใดๆ ก็ได้ (ส่วนตัว GPT-4 ไม่เห็น ฯลฯ) และใช้งานได้โดยไม่ต้องเสียเงินซื้อ API เช่น OpenAI
- การปรับแต่งแบบละเอียดทั้งหมด : การปรับแต่งแบบละเอียดแบบเต็มหมายถึงการฝึกพารามิเตอร์ทั้งหมดในโมเดล ไม่ใช่เทคนิคที่มีประสิทธิภาพ แต่ให้ผลลัพธ์ที่ดีกว่าเล็กน้อย
- LoRA : เทคนิคการใช้พารามิเตอร์อย่างมีประสิทธิภาพ (PEFT) ที่ใช้อะแดปเตอร์ระดับต่ำ แทนที่จะฝึกพารามิเตอร์ทั้งหมด เราจะฝึกเฉพาะอะแดปเตอร์เหล่านี้เท่านั้น
- QLoRA : PEFT อีกตัวหนึ่งที่ใช้ LoRA ซึ่งคำนวณปริมาณน้ำหนักของโมเดลเป็น 4 บิตและแนะนำเครื่องมือเพิ่มประสิทธิภาพแบบเพจเพื่อจัดการหน่วยความจำที่เพิ่มขึ้นอย่างรวดเร็ว ใช้ร่วมกับ Unsloth เพื่อรันอย่างมีประสิทธิภาพบนสมุดบันทึก Colab ฟรี
- Axolotl : เครื่องมือปรับแต่งอย่างละเอียดที่ใช้งานง่ายและทรงพลังซึ่งใช้ในโมเดลโอเพ่นซอร์สที่ล้ำสมัยจำนวนมาก
- DeepSpeed : การฝึกอบรมล่วงหน้าที่มีประสิทธิภาพและการปรับแต่ง LLM อย่างละเอียดสำหรับการตั้งค่า GPU หลายตัวและหลายโหนด (ใช้งานใน Axolotl)
อ้างอิง :
- คู่มือการฝึกอบรม LLM สำหรับมือใหม่โดย Alpin: ภาพรวมของแนวคิดหลักและพารามิเตอร์ที่ต้องพิจารณาเมื่อปรับแต่ง LLM อย่างละเอียด
- ข้อมูลเชิงลึกของ LoRA โดย Sebastian Raschka: ข้อมูลเชิงลึกเชิงปฏิบัติเกี่ยวกับ LoRA และวิธีเลือกพารามิเตอร์ที่ดีที่สุด
- ปรับแต่งโมเดล Llama 2 ของคุณเอง: บทช่วยสอนแบบลงมือปฏิบัติจริงเกี่ยวกับวิธีการปรับแต่งโมเดล Llama 2 โดยใช้ไลบรารี Hugging Face
- การเสริมโมเดลภาษาขนาดใหญ่โดย Benjamin Marie: แนวปฏิบัติที่ดีที่สุดในการเสริมตัวอย่างการฝึกอบรมสำหรับ LLM ที่เป็นสาเหตุ
- คู่มือสำหรับผู้เริ่มต้นสู่การปรับแต่ง LLM แบบละเอียด: บทช่วยสอนเกี่ยวกับวิธีปรับแต่งโมเดล CodeLlama โดยใช้ Axolotl
5. การจัดตำแหน่งการตั้งค่า
หลังจากการปรับแต่งอย่างละเอียดภายใต้การดูแลแล้ว RLHF เป็นขั้นตอนที่ใช้ในการจัดคำตอบของ LLM ให้สอดคล้องกับความคาดหวังของมนุษย์ แนวคิดคือการเรียนรู้ความชอบจากความคิดเห็นของมนุษย์ (หรือเทียม) ซึ่งสามารถใช้เพื่อลดอคติ โมเดลเซ็นเซอร์ หรือทำให้สิ่งเหล่านั้นมีประโยชน์มากขึ้น มันซับซ้อนกว่า SFT และมักถูกมองว่าเป็นทางเลือก
- ชุดข้อมูลการตั้งค่า : โดยทั่วไปชุดข้อมูลเหล่านี้ประกอบด้วยคำตอบหลายคำตอบและมีการจัดอันดับบางประเภท ซึ่งทำให้ยากต่อการสร้างมากกว่าชุดข้อมูลคำสั่ง
- การเพิ่มประสิทธิภาพนโยบายใกล้เคียง : อัลกอริธึมนี้ใช้ประโยชน์จากโมเดลการให้รางวัลที่คาดการณ์ว่าข้อความที่กำหนดได้รับการจัดอันดับสูงโดยมนุษย์หรือไม่ จากนั้นการคาดการณ์นี้จะใช้เพื่อปรับโมเดล SFT ให้เหมาะสมด้วยการปรับค่าปรับตามความแตกต่างของ KL
- การเพิ่มประสิทธิภาพการกำหนดลักษณะโดยตรง : DPO ทำให้กระบวนการง่ายขึ้นโดยจัดกรอบใหม่ให้เป็นปัญหาการจำแนกประเภท โดยจะใช้โมเดลอ้างอิงแทนโมเดลการให้รางวัล (ไม่จำเป็นต้องมีการฝึกอบรม) และต้องการเพียงไฮเปอร์พารามิเตอร์เพียงตัวเดียว ทำให้มีเสถียรภาพและมีประสิทธิภาพมากขึ้น
อ้างอิง :
- Distilabel โดย Argilla: เครื่องมือที่ยอดเยี่ยมในการสร้างชุดข้อมูลของคุณเอง ได้รับการออกแบบมาเป็นพิเศษสำหรับชุดข้อมูลการตั้งค่าแต่ก็สามารถทำ SFT ได้เช่นกัน
- ข้อมูลเบื้องต้นเกี่ยวกับการฝึกอบรม LLM โดยใช้ RLHF โดย Ayush Thakur: อธิบายว่าเหตุใด RLHF จึงเป็นที่พึงปรารถนาในการลดอคติและเพิ่มประสิทธิภาพใน LLM
- ภาพประกอบ RLHF โดย Hugging Face: ความรู้เบื้องต้นเกี่ยวกับ RLHF พร้อมการฝึกอบรมโมเดลรางวัลและการปรับแต่งอย่างละเอียดด้วยการเรียนรู้แบบเสริมกำลัง
- การปรับแต่งค่ากำหนด LLM โดย Hugging Face: การเปรียบเทียบอัลกอริธึม DPO, IPO และ KTO เพื่อดำเนินการจัดตำแหน่งการตั้งค่า
- การฝึกอบรม LLM: RLHF และทางเลือกอื่น โดย Sebastian Rashcka: ภาพรวมของกระบวนการ RLHF และทางเลือกอื่น เช่น RLAIF
- ปรับแต่ง Mistral-7b ด้วย DPO: บทช่วยสอนเพื่อปรับแต่งโมเดล Mistral-7b ด้วย DPO และสร้าง NeuralHermes-2.5 ขึ้นมาใหม่
6. การประเมินผล
การประเมิน LLM ถือเป็นส่วนที่ประเมินค่าต่ำเกินไปในขั้นตอนการทำงาน ซึ่งใช้เวลานานและเชื่อถือได้ปานกลาง งานปลายน้ำของคุณควรกำหนดสิ่งที่คุณต้องการประเมิน แต่จำไว้เสมอว่ากฎของ Goodhart: "เมื่อการวัดกลายเป็นเป้าหมาย มันก็จะยุติการเป็นการวัดที่ดี"
- ตัวชี้วัดแบบดั้งเดิม : ตัวชี้วัด เช่น ความฉงนสนเท่ห์และคะแนน BLEU นั้นไม่ได้รับความนิยมเท่าที่ควร เนื่องจากมีข้อบกพร่องในบริบทส่วนใหญ่ สิ่งสำคัญคือต้องเข้าใจสิ่งเหล่านี้และเมื่อใดจึงจะสามารถนำไปใช้ได้
- เกณฑ์มาตรฐานทั่วไป : ขึ้นอยู่กับชุดควบคุมการประเมินโมเดลภาษา Open LLM Leaderboard เป็นเกณฑ์มาตรฐานหลักสำหรับ LLM เอนกประสงค์ (เช่น ChatGPT) มีการวัดประสิทธิภาพยอดนิยมอื่น ๆ เช่น BigBench, MT-Bench เป็นต้น
- เกณฑ์มาตรฐานเฉพาะงาน : งานต่างๆ เช่น การสรุป การแปล และการตอบคำถามมีเกณฑ์มาตรฐาน ตัวชี้วัด และแม้แต่โดเมนย่อย (ทางการแพทย์ การเงิน ฯลฯ) โดยเฉพาะ เช่น PubMedQA สำหรับการตอบคำถามด้านชีวการแพทย์
- การประเมินโดยมนุษย์ : การประเมินที่น่าเชื่อถือที่สุดคืออัตราการยอมรับจากผู้ใช้หรือการเปรียบเทียบโดยมนุษย์ การบันทึกความคิดเห็นของผู้ใช้นอกเหนือจากการติดตามการแชท (เช่น การใช้ LangSmith) ช่วยในการระบุพื้นที่ที่อาจต้องปรับปรุง
อ้างอิง :
- ความฉงนสนเท่ห์ของโมเดลที่มีความยาวคงที่โดย Hugging Face: ภาพรวมของความฉงนสนเท่ห์ด้วยโค้ดเพื่อนำไปใช้กับไลบรารีของ Transformers
- BLEU ยอมรับความเสี่ยงของคุณเอง โดย Rachael Tatman: ภาพรวมของคะแนน BLEU และประเด็นต่างๆ พร้อมตัวอย่าง
- แบบสำรวจการประเมิน LLM โดย Chang และคณะ: บทความที่ครอบคลุมเกี่ยวกับสิ่งที่จะประเมิน สถานที่ที่จะประเมิน และวิธีการประเมิน
- กระดานผู้นำ Chatbot Arena โดย lmsys: การจัดอันดับ Elo ของ LLM เอนกประสงค์ โดยอิงจากการเปรียบเทียบโดยมนุษย์
7. การหาปริมาณ
การหาปริมาณเป็นกระบวนการแปลงน้ำหนัก (และการเปิดใช้งาน) ของแบบจำลองโดยใช้ความแม่นยำที่ต่ำกว่า ตัวอย่างเช่น น้ำหนักที่จัดเก็บโดยใช้ 16 บิตสามารถแปลงเป็นตัวแทน 4 บิตได้ เทคนิคนี้มีความสำคัญมากขึ้นในการลดต้นทุนด้านการคำนวณและหน่วยความจำที่เกี่ยวข้องกับ LLM
- เทคนิคพื้นฐาน : เรียนรู้ระดับความแม่นยำต่างๆ (FP32, FP16, INT8 ฯลฯ) และวิธีการดำเนินการหาปริมาณแบบไร้เดียงสาด้วยเทคนิค Absmax และจุดศูนย์
- GGUF และ llama.cpp : เดิมทีออกแบบมาเพื่อทำงานบน CPU llama.cpp และรูปแบบ GGUF ได้กลายเป็นเครื่องมือยอดนิยมที่สุดในการรัน LLM บนฮาร์ดแวร์ระดับผู้บริโภค
- GPTQ และ EXL2 : GPTQ และโดยเฉพาะอย่างยิ่ง รูปแบบ EXL2 ให้ความเร็วอันเหลือเชื่อ แต่สามารถทำงานได้บน GPU เท่านั้น นอกจากนี้ โมเดลยังใช้เวลานานในการหาปริมาณอีกด้วย
- AWQ : รูปแบบใหม่นี้มีความแม่นยำมากกว่า GPTQ (ความฉงนสนเท่ห์ต่ำกว่า) แต่ใช้ VRAM มากกว่ามากและไม่จำเป็นต้องเร็วกว่าเสมอไป
อ้างอิง :
- การหาปริมาณเบื้องต้น: ภาพรวมของการหาปริมาณ การหาปริมาณแบบ Absmax และ Zero-Point และ LLM.int8() พร้อมโค้ด
- หาปริมาณโมเดล Llama ด้วย llama.cpp: บทช่วยสอนเกี่ยวกับวิธีหาปริมาณโมเดล Llama 2 โดยใช้ llama.cpp และรูปแบบ GGUF
- การหาปริมาณ LLM 4 บิตด้วย GPTQ: บทช่วยสอนเกี่ยวกับวิธีหาปริมาณ LLM โดยใช้อัลกอริทึม GPTQ ด้วย AutoGPTQ
- ExLlamaV2: ไลบรารีที่เร็วที่สุดในการรัน LLM: คำแนะนำเกี่ยวกับวิธีหาปริมาณโมเดล Mistral โดยใช้รูปแบบ EXL2 และรันด้วยไลบรารี ExLlamaV2
- ทำความเข้าใจกับการเปิดใช้งาน-Aware Weight Quantization โดย FriendliAI: ภาพรวมของเทคนิค AWQ และคุณประโยชน์ของเทคนิค
8. เทรนด์ใหม่
- การฝังตำแหน่ง : เรียนรู้ว่า LLM เข้ารหัสตำแหน่งอย่างไร โดยเฉพาะรูปแบบการเข้ารหัสตำแหน่งที่สัมพันธ์กัน เช่น RoPE ใช้ YaRN (คูณเมทริกซ์ความสนใจด้วยปัจจัยอุณหภูมิ) หรือ ALiBi (การปรับความสนใจตามระยะทางโทเค็น) เพื่อขยายความยาวของบริบท
- การรวมโมเดล : การรวมโมเดลที่ได้รับการฝึกได้กลายเป็นวิธียอดนิยมในการสร้างโมเดลที่มีประสิทธิภาพโดยไม่ต้องปรับแต่งใดๆ ไลบรารีผสานที่ได้รับความนิยมใช้วิธีการผสานที่ได้รับความนิยมมากที่สุด เช่น SLERP, DARE และ TIES
- การผสมผสานของผู้เชี่ยวชาญ : Mixtral ทำให้สถาปัตยกรรม MoE ได้รับความนิยมอีกครั้งด้วยประสิทธิภาพที่ยอดเยี่ยม ในขณะเดียวกัน frankenMoE ประเภทหนึ่งก็เกิดขึ้นในชุมชน OSS โดยการผสานโมเดลอย่าง Phixtral ซึ่งเป็นตัวเลือกที่ถูกกว่าและมีประสิทธิภาพ
- โมเดลหลายรูปแบบ : โมเดลเหล่านี้ (เช่น CLIP, Stable Diffusion หรือ LLaVA) ประมวลผลอินพุตหลายประเภท (ข้อความ รูปภาพ เสียง ฯลฯ) ด้วยพื้นที่ฝังแบบรวม ซึ่งจะปลดล็อกแอปพลิเคชันที่มีประสิทธิภาพ เช่น ข้อความเป็นรูปภาพ
อ้างอิง :
- การขยาย RoPE โดย EleutherAI: บทความที่สรุปเทคนิคการเข้ารหัสตำแหน่งต่างๆ
- ทำความเข้าใจ YaRN โดย Rajat Chawla: Introduction to YaRN
- ผสาน LLM เข้ากับ Mergekit: บทช่วยสอนเกี่ยวกับการผสานโมเดลโดยใช้ Mergekit
- การผสมผสานของผู้เชี่ยวชาญที่อธิบายโดย Hugging Face: คำแนะนำโดยละเอียดเกี่ยวกับ MoE และวิธีการทำงาน
- โมเดลหลายรูปแบบขนาดใหญ่โดย Chip Huyen: ภาพรวมของระบบหลายรูปแบบและประวัติล่าสุดของสาขานี้
- วิศวกร LLM
เนื้อหาในส่วนนี้ของหลักสูตรมุ่งเน้นไปที่การเรียนรู้วิธีสร้างแอปพลิเคชันที่ขับเคลื่อนด้วย LLM ซึ่งสามารถนำไปใช้ในการผลิตได้ โดยเน้นที่การเพิ่มโมเดลและการปรับใช้
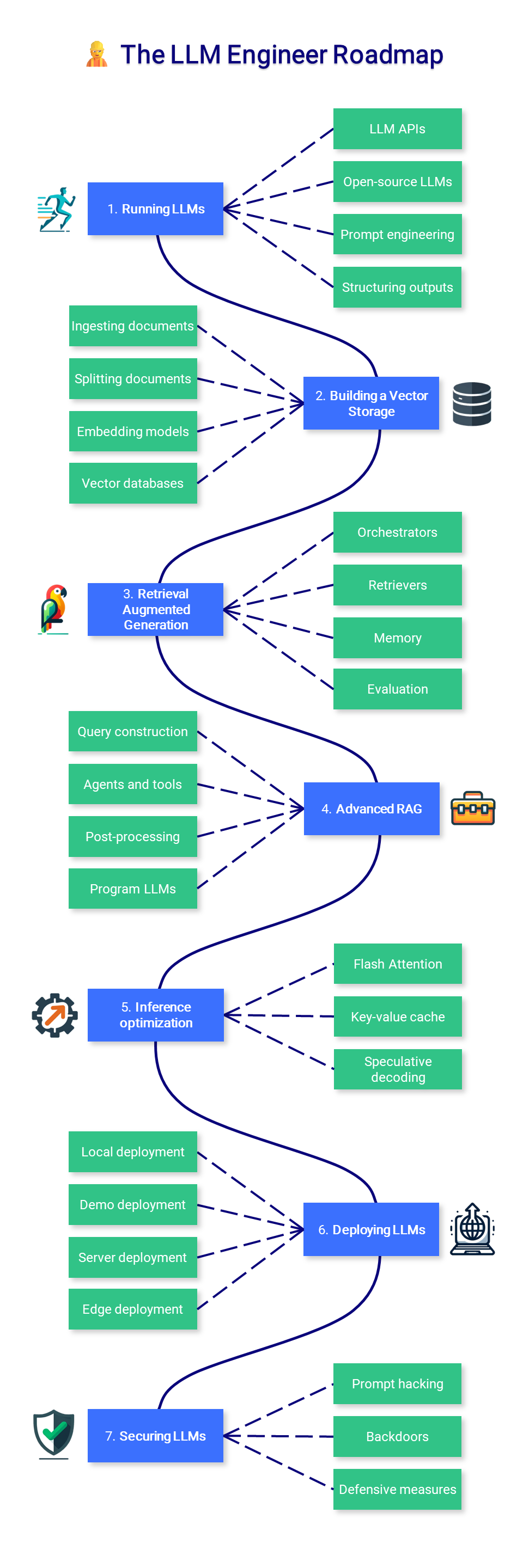
1. การเรียกใช้ LLM
การเรียกใช้ LLM อาจเป็นเรื่องยากเนื่องจากมีข้อกำหนดด้านฮาร์ดแวร์สูง ขึ้นอยู่กับกรณีการใช้งานของคุณ คุณอาจต้องการใช้โมเดลผ่าน API (เช่น GPT-4) หรือเรียกใช้ในเครื่อง ไม่ว่าในกรณีใด เทคนิคการแจ้งและคำแนะนำเพิ่มเติมสามารถปรับปรุงและจำกัดผลลัพธ์สำหรับแอปพลิเคชันของคุณได้
- LLM API : API เป็นวิธีที่สะดวกในการปรับใช้ LLM พื้นที่นี้ถูกแบ่งระหว่าง LLM ส่วนตัว (OpenAI, Google, Anthropic, Cohere ฯลฯ) และ LLM แบบโอเพ่นซอร์ส (OpenRouter, Hugging Face, Together AI ฯลฯ)
- LLM แบบโอเพ่นซอร์ส : Hugging Face Hub เป็นสถานที่ที่ดีเยี่ยมในการค้นหา LLM คุณสามารถเรียกใช้บางส่วนได้โดยตรงใน Hugging Face Spaces หรือดาวน์โหลดและเรียกใช้ในแอปอย่าง LM Studio หรือผ่าน CLI ด้วย llama.cpp หรือ Ollama
- วิศวกรรมพร้อมท์ : เทคนิคทั่วไป ได้แก่ การเตือนแบบ Zero-shot, การเตือนแบบไม่กี่นัด, ห่วงโซ่แห่งความคิด และ ReAct ทำงานได้ดีกว่ากับรุ่นที่ใหญ่กว่า แต่สามารถปรับให้เข้ากับรุ่นที่เล็กกว่าได้
- การจัดโครงสร้างเอาต์พุต : งานจำนวนมากจำเป็นต้องมีเอาต์พุตที่มีโครงสร้าง เช่น เทมเพลตที่เข้มงวดหรือรูปแบบ JSON ไลบรารีเช่น LMQL, Outlines, Guidance ฯลฯ สามารถใช้เพื่อชี้แนะการสร้างและเคารพโครงสร้างที่กำหนด
อ้างอิง :
- เรียกใช้ LLM ในเครื่องด้วย LM Studio โดย Nisha Arya: คำแนะนำสั้นๆ เกี่ยวกับวิธีใช้ LM Studio
- คำแนะนำด้านวิศวกรรมพร้อมท์โดย DAIR.AI: รายการเทคนิคพร้อมท์พร้อมตัวอย่างโดยละเอียด
- โครงร่าง - การเริ่มต้นอย่างรวดเร็ว: รายการเทคนิคการสร้างคำแนะนำที่ Outlines เปิดใช้งาน
- LMQL - ภาพรวม: ความรู้เบื้องต้นเกี่ยวกับภาษา LMQL
2. สร้างที่เก็บข้อมูลเวกเตอร์
การสร้างพื้นที่เก็บข้อมูลเวกเตอร์เป็นขั้นตอนแรกในการสร้างไปป์ไลน์การดึงข้อมูล Augmented Generation (RAG) เอกสารจะถูกโหลด แยก และส่วนที่เกี่ยวข้องจะใช้เพื่อสร้างการแสดงเวกเตอร์ (การฝัง) ที่เก็บไว้เพื่อใช้ในอนาคตระหว่างการอนุมาน
- การนำเข้าเอกสาร : ตัวโหลดเอกสารเป็น Wrapper ที่สะดวกซึ่งสามารถรองรับได้หลายรูปแบบ: PDF, JSON, HTML, Markdown ฯลฯ นอกจากนี้ยังสามารถดึงข้อมูลจากฐานข้อมูลและ API บางตัวได้โดยตรง (GitHub, Reddit, Google Drive ฯลฯ)
- การแยกเอกสาร : ตัวแยกข้อความจะแบ่งเอกสารออกเป็นส่วนเล็กๆ ที่มีความหมายตามความหมาย แทนที่จะแบ่งข้อความตามอักขระ n ตัว มักจะดีกว่าถ้าแยกตามส่วนหัวหรือแยกซ้ำพร้อมข้อมูลเมตาเพิ่มเติมบางส่วน
- โมเดลการฝัง : โมเดลการฝังจะแปลงข้อความเป็นการแสดงเวกเตอร์ ช่วยให้เข้าใจภาษาได้ลึกซึ้งและละเอียดยิ่งขึ้น ซึ่งจำเป็นต่อการค้นหาความหมาย
- ฐานข้อมูลเวกเตอร์ : ฐานข้อมูลเวกเตอร์ (เช่น Chroma, Pinecone, Milvus, FAISS, Annoy ฯลฯ) ได้รับการออกแบบมาเพื่อจัดเก็บเวกเตอร์ที่ฝังไว้ ช่วยให้ดึงข้อมูลที่ 'คล้ายกันมากที่สุด' กับการสืบค้นตามความคล้ายคลึงกันของเวกเตอร์ได้อย่างมีประสิทธิภาพ
อ้างอิง :
- LangChain - ตัวแยกข้อความ: รายการตัวแยกข้อความต่างๆ ที่ใช้งานใน LangChain
- ไลบรารี Sentence Transformers: ไลบรารียอดนิยมสำหรับการฝังโมเดล
- MTEB Leaderboard: ลีดเดอร์บอร์ดสำหรับการฝังโมเดล
- ฐานข้อมูลเวกเตอร์ 5 อันดับแรกโดย Moez Ali: การเปรียบเทียบฐานข้อมูลเวกเตอร์ที่ดีที่สุดและเป็นที่นิยมมากที่สุด
3. การดึงข้อมูลรุ่นเสริม
ด้วย RAG LLM จะดึงเอกสารเชิงบริบทจากฐานข้อมูลเพื่อปรับปรุงความแม่นยำของคำตอบ RAG เป็นวิธีที่ได้รับความนิยมในการเพิ่มพูนความรู้ของโมเดลโดยไม่ต้องปรับแต่งใดๆ
- Orchestrator : Orchestrator (เช่น LangChain, LlamaIndex, FastRAG ฯลฯ) เป็นเฟรมเวิร์กยอดนิยมสำหรับเชื่อมต่อ LLM ของคุณกับเครื่องมือ ฐานข้อมูล หน่วยความจำ ฯลฯ และเพิ่มความสามารถ
- ตัวดึงข้อมูล : คำแนะนำสำหรับผู้ใช้ไม่ได้รับการปรับให้เหมาะสมสำหรับการดึงข้อมูล สามารถใช้เทคนิคต่างๆ (เช่น มัลติคิวรีรีทรีฟเวอร์, HyDE ฯลฯ) เพื่อเรียบเรียง/ขยายและปรับปรุงประสิทธิภาพ
- หน่วยความจำ : เพื่อจดจำคำแนะนำและคำตอบก่อนหน้านี้ LLM และแชทบอท เช่น ChatGPT จะเพิ่มประวัตินี้ในหน้าต่างบริบท บัฟเฟอร์นี้สามารถปรับปรุงได้ด้วยการสรุป (เช่น การใช้ LLM ที่เล็กกว่า) vector store + RAG เป็นต้น
- การประเมิน : เราจำเป็นต้องประเมินทั้งการดึงเอกสาร (ความแม่นยำของบริบทและการเรียกคืน) และขั้นตอนการสร้าง (ความซื่อสัตย์และความเกี่ยวข้องของคำตอบ) สามารถทำให้ง่ายขึ้นด้วยเครื่องมือ Ragas และ DeepEval
อ้างอิง :
- Llamaindex - แนวคิดระดับสูง: แนวคิดหลักที่ควรทราบเมื่อสร้างไปป์ไลน์ RAG
- Pinecone - การเสริมการดึงข้อมูล: ภาพรวมของกระบวนการการเสริมการดึงข้อมูล
- LangChain - ถาม&ตอบด้วย RAG: บทช่วยสอนแบบทีละขั้นตอนเพื่อสร้างไปป์ไลน์ RAG ทั่วไป
- LangChain - ประเภทหน่วยความจำ: รายการความทรงจำประเภทต่างๆ พร้อมการใช้งานที่เกี่ยวข้อง
- ไปป์ไลน์ RAG - ตัวชี้วัด: ภาพรวมของตัวชี้วัดหลักที่ใช้ในการประเมินไปป์ไลน์ RAG
4. RAG ขั้นสูง
แอปพลิเคชันในชีวิตจริงอาจต้องใช้ไปป์ไลน์ที่ซับซ้อน รวมถึงฐานข้อมูล SQL หรือกราฟ รวมถึงการเลือกเครื่องมือและ API ที่เกี่ยวข้องโดยอัตโนมัติ เทคนิคขั้นสูงเหล่านี้สามารถปรับปรุงโซลูชันพื้นฐานและให้คุณลักษณะเพิ่มเติมได้
- การสร้างแบบสอบถาม : ข้อมูลที่มีโครงสร้างจัดเก็บไว้ในฐานข้อมูลแบบดั้งเดิมต้องใช้ภาษาการสืบค้นเฉพาะ เช่น SQL, Cypher, ข้อมูลเมตา ฯลฯ เราสามารถแปลคำสั่งผู้ใช้เป็นการสืบค้นได้โดยตรงเพื่อเข้าถึงข้อมูลด้วยการสร้างการสืบค้น
- ตัวแทนและเครื่องมือ : ตัวแทนขยาย LLM โดยการเลือกเครื่องมือที่เกี่ยวข้องมากที่สุดโดยอัตโนมัติเพื่อให้คำตอบ เครื่องมือเหล่านี้อาจทำได้ง่ายเพียงแค่ใช้ Google หรือ Wikipedia หรือซับซ้อนกว่าเช่นล่าม Python หรือ Jira
- หลังการประมวลผล : ขั้นตอนสุดท้ายที่ประมวลผลอินพุตที่ป้อนให้กับ LLM ช่วยเพิ่มความเกี่ยวข้องและความหลากหลายของเอกสารที่ดึงมาด้วยการจัดอันดับใหม่ RAG-fusion และการจัดหมวดหมู่
- โปรแกรม LLM : เฟรมเวิร์ก เช่น DSPy ช่วยให้คุณสามารถปรับคำแนะนำและน้ำหนักให้เหมาะสมตามการประเมินอัตโนมัติในลักษณะทางโปรแกรม
อ้างอิง :
- LangChain - การสร้างแบบสอบถาม: โพสต์ในบล็อกเกี่ยวกับการสร้างแบบสอบถามประเภทต่างๆ
- LangChain - SQL: บทช่วยสอนเกี่ยวกับวิธีการโต้ตอบกับฐานข้อมูล SQL ด้วย LLM ที่เกี่ยวข้องกับ Text-to-SQL และตัวแทน SQL เสริม
- Pinecone - ตัวแทน LLM: ข้อมูลเบื้องต้นเกี่ยวกับตัวแทนและเครื่องมือประเภทต่างๆ
- ตัวแทนอิสระที่ขับเคลื่อนด้วย LLM โดย Lilian Weng: บทความเชิงทฤษฎีเพิ่มเติมเกี่ยวกับตัวแทน LLM
- LangChain - RAG ของ OpenAI: ภาพรวมของกลยุทธ์ RAG ที่ใช้โดย OpenAI รวมถึงขั้นตอนหลังการประมวลผล
- DSPy ใน 8 ขั้นตอน: คู่มือวัตถุประสงค์ทั่วไปสำหรับ DSPy ที่แนะนำโมดูล ลายเซ็น และเครื่องมือเพิ่มประสิทธิภาพ
5. การเพิ่มประสิทธิภาพการอนุมาน
การสร้างข้อความเป็นกระบวนการที่ต้องใช้ฮาร์ดแวร์ราคาแพง นอกเหนือจากการหาปริมาณแล้ว ยังมีการเสนอเทคนิคต่างๆ เพื่อเพิ่มปริมาณงานและลดต้นทุนการอนุมาน
- Flash Attention : การเพิ่มประสิทธิภาพกลไกความสนใจเพื่อเปลี่ยนความซับซ้อนจากกำลังสองเป็นเชิงเส้น เร่งทั้งการฝึกและการอนุมาน
- แคชคีย์-ค่า : ทำความเข้าใจแคชคีย์-ค่าและการปรับปรุงที่แนะนำใน Multi-Query Attention (MQA) และ Grouped-Query Attention (GQA)
- การถอดรหัสแบบเก็งกำไร : ใช้โมเดลขนาดเล็กเพื่อสร้างแบบร่าง จากนั้นโมเดลขนาดใหญ่จะตรวจสอบเพื่อเร่งการสร้างข้อความ
อ้างอิง :
- การอนุมาน GPU โดย Hugging Face: อธิบายวิธีเพิ่มประสิทธิภาพการอนุมานบน GPU
- การอนุมาน LLM โดย Databricks: แนวปฏิบัติที่ดีที่สุดสำหรับวิธีเพิ่มประสิทธิภาพการอนุมาน LLM ในการผลิต
- การเพิ่มประสิทธิภาพ LLM สำหรับความเร็วและหน่วยความจำด้วยการกอดใบหน้า: อธิบายเทคนิคหลักสามประการเพื่อเพิ่มประสิทธิภาพความเร็วและหน่วยความจำ ได้แก่ การหาปริมาณ ความสนใจแบบแฟลช และนวัตกรรมทางสถาปัตยกรรม
- Assisted Generation โดย Hugging Face: การถอดรหัสแบบเก็งกำไรในเวอร์ชัน HF เป็นโพสต์บล็อกที่น่าสนใจเกี่ยวกับวิธีการทำงานกับโค้ดเพื่อนำไปใช้
6. การปรับใช้ LLM
การปรับใช้ LLM ในวงกว้างถือเป็นความสำเร็จทางวิศวกรรมที่อาจต้องใช้ GPU หลายคลัสเตอร์ ในสถานการณ์อื่นๆ การสาธิตและแอปในเครื่องสามารถทำได้โดยมีความซับซ้อนน้อยกว่ามาก
- การปรับใช้ในพื้นที่ : ความเป็นส่วนตัวเป็นข้อได้เปรียบที่สำคัญที่ LLM แบบโอเพ่นซอร์สมีมากกว่าแบบส่วนตัว เซิร์ฟเวอร์ LLM ภายในเครื่อง (LM Studio, Ollama, oobabooga, kobold.cpp ฯลฯ) ใช้ประโยชน์จากข้อได้เปรียบนี้ในการขับเคลื่อนแอปภายในเครื่อง
- การสาธิตการใช้งาน : กรอบงานเช่น Gradio และ Streamlit มีประโยชน์ในการสร้างต้นแบบแอปพลิเคชันและแบ่งปันการสาธิต นอกจากนี้คุณยังสามารถโฮสต์ออนไลน์ได้อย่างง่ายดายเช่นการใช้ Hugging Face Spaces
- การปรับใช้เซิร์ฟเวอร์ : การปรับใช้ LLMS ในระดับที่ต้องการคลาวด์ (ดูเพิ่มเติม Skypilot) หรือโครงสร้างพื้นฐานในสถานที่และมักจะใช้ประโยชน์จากกรอบการสร้างข้อความที่ดีที่สุดเช่น TGI, VLLM ฯลฯ
- การปรับใช้ Edge : ในสภาพแวดล้อมที่มีข้อ จำกัด เฟรมเวิร์กประสิทธิภาพสูงเช่น MLC LLM และ MNN-LLM สามารถปรับใช้ LLM ในเว็บเบราว์เซอร์, Android และ iOS
อ้างอิง :
- Streamlit - สร้างแอพ LLM พื้นฐาน: บทช่วยสอนเพื่อสร้างแอพที่มีลักษณะคล้ายแชทพื้นฐานโดยใช้ Streamlit
- คอนเทนเนอร์การอนุมาน HF LLM: ปรับใช้ LLMs ใน Amazon Sagemaker โดยใช้คอนเทนเนอร์การอนุมานของ Hugging Face
- บล็อก Philschmid โดย Philipp Schmid: คอลเลกชันของบทความคุณภาพสูงเกี่ยวกับการปรับใช้ LLM โดยใช้ Amazon Sagemaker
- การเพิ่มประสิทธิภาพความล่าช้าโดย Hamel Husain: การเปรียบเทียบ TGI, VLLM, CTRANSLATE2 และ MLC ในแง่ของปริมาณงานและเวลาแฝง
7. การรักษาความปลอดภัย LLMS
นอกเหนือจากปัญหาความปลอดภัยแบบดั้งเดิมที่เกี่ยวข้องกับซอฟต์แวร์ LLM มีจุดอ่อนที่ไม่เหมือนใครเนื่องจากวิธีการฝึกอบรมและได้รับการฝึกฝน
- การแฮ็คพรอมต์ : เทคนิคต่าง ๆ ที่เกี่ยวข้องกับวิศวกรรมที่รวดเร็วรวมถึงการฉีดทันที (คำแนะนำเพิ่มเติมเพื่อจี้คำตอบของโมเดล), ข้อมูล/การรั่วไหลของข้อมูล (ดึงข้อมูล/พรอมต์ดั้งเดิม) และการเจลเบรค
- Backdoors : Attack Vectors สามารถกำหนดเป้าหมายข้อมูลการฝึกอบรมได้โดยการวางยาพิษข้อมูลการฝึกอบรม (เช่นด้วยข้อมูลเท็จ) หรือการสร้างแบ็คดอร์ (ทริกเกอร์ลับเพื่อเปลี่ยนพฤติกรรมของโมเดลในระหว่างการอนุมาน)
- มาตรการป้องกัน : วิธีที่ดีที่สุดในการปกป้องแอปพลิเคชัน LLM ของคุณคือการทดสอบพวกเขาจากช่องโหว่เหล่านี้ (เช่นการใช้การเป็นทีมสีแดงและตรวจสอบเช่น Garak) และสังเกตพวกเขาในการผลิต (ด้วยกรอบงานเช่น Langfuse)
อ้างอิง :
- OWASP LLM TOP 10 โดย Hego Wiki: รายการช่องโหว่ของนักวิจารณ์มากที่สุด 10 รายที่เห็นในแอปพลิเคชัน LLM
- ไพรเมอร์ฉีดทันทีโดย Joseph Thacker: คู่มือสั้น ๆ ที่อุทิศให้กับการฉีดสำหรับวิศวกร
- LLM Security โดย @LLM_SEC: รายการทรัพยากรที่เกี่ยวข้องกับ LLM Security
- Red Teaming LLMS โดย Microsoft: คู่มือเกี่ยวกับวิธีการทำงานเป็นทีมสีแดงด้วย LLMS
รับทราบ
แผนงานนี้ได้รับแรงบันดาลใจจากแผนงาน DevOps ที่ยอดเยี่ยมจาก Milan Milanovićและ Romano Roth
ขอขอบคุณเป็นพิเศษสำหรับ:
- Thomas Thelen สำหรับแรงจูงใจให้ฉันสร้างแผนงาน
- André Frade สำหรับการป้อนข้อมูลและตรวจสอบร่างแรกของเขา
- Dino Dunn สำหรับการจัดหาทรัพยากรเกี่ยวกับ LLM Security
- Magdalena Kuhn สำหรับการปรับปรุงส่วน "การประเมินผลของมนุษย์"
- Odoverdose สำหรับการแนะนำวิดีโอของ 3Blue1brown เกี่ยวกับ Transformers
ข้อจำกัดความรับผิดชอบ: ฉันไม่ได้มีส่วนเกี่ยวข้องกับแหล่งข้อมูลใด ๆ ที่ระบุไว้ที่นี่


