พื้นที่เก็บข้อมูลนี้มีโค้ด PyTorch สำหรับ Motif ซึ่งฝึกอบรมเจ้าหน้าที่ AI บน NetHack ด้วยฟังก์ชันการให้รางวัลที่ได้มาจากการตั้งค่าของ LLM
บรรทัดฐาน: แรงจูงใจภายในจากการตอบรับของปัญญาประดิษฐ์
โดย Martin Klissarov* และ Pierluca D'Oro*, Shagun Sodhani, Roberta Raileanu, Pierre-Luc Bacon, Pascal Vincent, Amy Zhang และ Mikael Henaff
Motif ดึงเอาการตั้งค่าของ Large Language Model (LLM) จากการสังเกตคำบรรยายคู่จากชุดข้อมูลของการโต้ตอบที่รวบรวมบน NetHack โดยจะกลั่นสามัญสำนึกของ LLM ให้เป็นฟังก์ชันการให้รางวัลโดยอัตโนมัติ ซึ่งจะใช้ในการฝึกอบรมตัวแทนด้วยการเรียนรู้แบบเสริมกำลัง
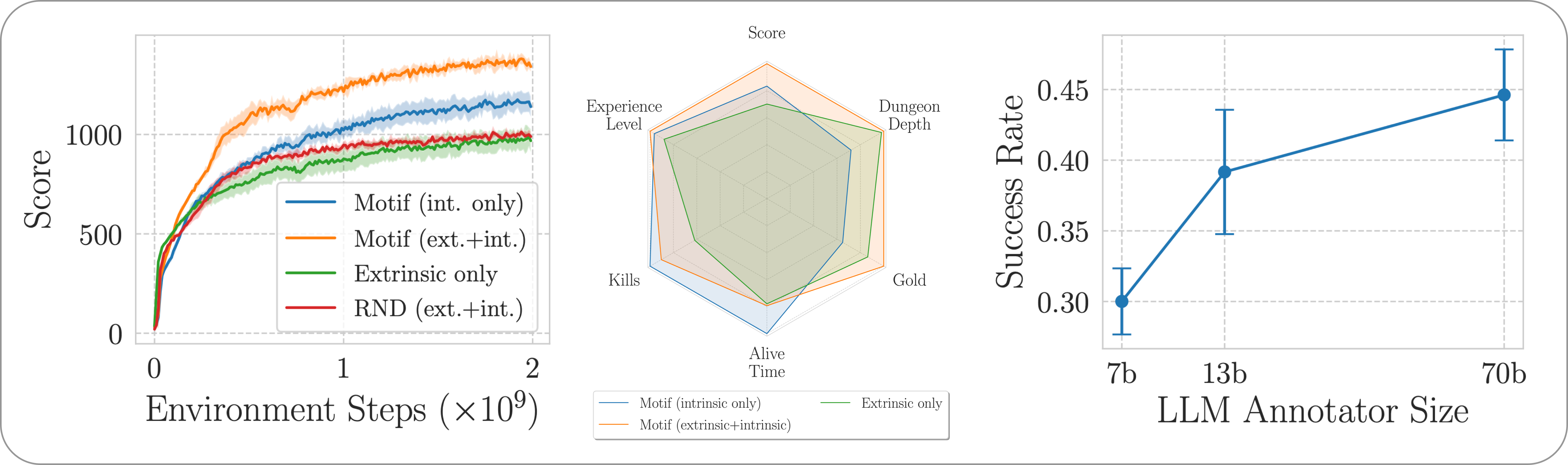
เพื่ออำนวยความสะดวกในการเปรียบเทียบ เราได้จัดเตรียมกราฟการฝึกอบรมไว้ในไฟล์ดอง motif_results.pkl ซึ่งมีพจนานุกรมที่มีงานเป็นกุญแจ สำหรับแต่ละงาน เราจัดเตรียมรายการการก้าวเวลาและผลตอบแทนเฉลี่ยสำหรับ Motif และเส้นพื้นฐานสำหรับหลายเมล็ด
ดังที่แสดงในภาพต่อไปนี้ Motif มีสามขั้นตอน:
เราให้รายละเอียดแต่ละขั้นตอนโดยจัดเตรียมชุดข้อมูล คำสั่ง และผลลัพธ์ดิบที่จำเป็นเพื่อสร้างการทดลองซ้ำในรายงาน
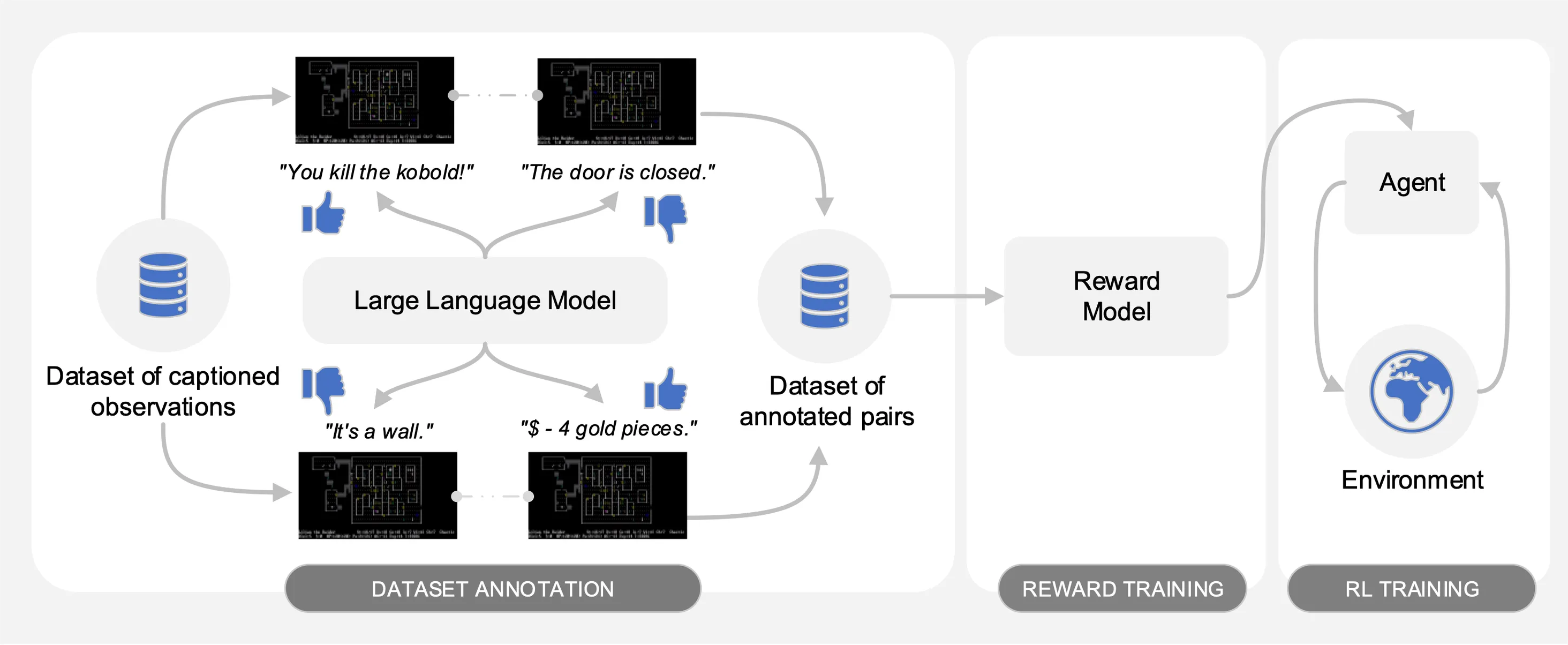
เราประเมินประสิทธิภาพของ Motif ในเกม NetHack ปลายเปิดที่ท้าทาย และสร้างตามขั้นตอนผ่านสภาพแวดล้อมการเรียนรู้ของ NetHack เราตรวจสอบว่า Motif ส่วนใหญ่สร้างพฤติกรรมที่สอดคล้องกับสัญชาตญาณของมนุษย์ได้อย่างไร ซึ่งสามารถนำทางได้อย่างง่ายดายผ่านการปรับเปลี่ยนอย่างรวดเร็ว รวมถึงคุณสมบัติการปรับขนาด

หากต้องการติดตั้งการขึ้นต่อกันที่จำเป็นสำหรับไปป์ไลน์ทั้งหมด เพียงเรียกใช้ pip install -r requirements.txt
สำหรับระยะแรก เราใช้ชุดข้อมูลของการสังเกตคู่พร้อมคำบรรยาย (เช่น ข้อความจากเกม) ที่รวบรวมโดยตัวแทนที่ได้รับการฝึกอบรมพร้อมการเรียนรู้แบบเสริมเพื่อเพิ่มคะแนนเกมให้สูงสุด เราจัดเตรียมชุดข้อมูลไว้ในที่เก็บนี้ เราจัดเก็บส่วนต่างๆ ไว้ในไดเร็กทอรี motif_dataset_zipped ซึ่งสามารถแตกไฟล์ได้โดยใช้คำสั่งต่อไปนี้
cat motif_dataset_zipped/motif_dataset_part_* > motif_dataset.zip; unzip motif_dataset.zip; rm motif_dataset.zip
ชุดข้อมูลที่เรามีให้ประกอบด้วยชุดการตั้งค่าที่กำหนดโดยโมเดล Llama 2 ซึ่งอยู่ในไดเร็กทอรี preference/ โดยใช้ข้อความแจ้งต่างๆ ที่อธิบายไว้ในรายงาน ชื่อของไฟล์ .npy ที่มีคำอธิบายประกอบเป็นไปตามเทมเพลต llama{size}b_msg_{instruction}_{version} โดยที่ size คือขนาด LLM จากชุด {7,13,70} instruction คือคำสั่งที่นำมาใช้กับ พรอมต์ที่มอบให้กับ LLM จากชุด {defaultgoal, zeroknowledge, combat, gold, stairs} version คือเวอร์ชันของเทมเพลตพร้อมต์ที่จะใช้จากชุด {default, reworded} ที่นี่เราให้ข้อมูลสรุปของคำอธิบายประกอบที่มีอยู่:
| คำอธิบายประกอบ | ใช้กรณีจากกระดาษ |
|---|---|
llama70b_msg_defaultgoal_default | การทดลองหลัก |
llama70b_msg_combat_default | มุ่งสู่พฤติกรรม The Monster Slayer |
llama70b_msg_gold_default | มุ่งสู่พฤติกรรม นักสะสมทองคำ |
llama70b_msg_stairs_default | มุ่งสู่พฤติกรรม The Descender |
llama7b_msg_defaultgoal_default | การทดลองปรับขนาด |
llama13b_msg_defaultgoal_default | การทดลองปรับขนาด |
llama70b_msg_zeroknowledge_default | การทดลองพร้อมท์ความรู้เป็นศูนย์ |
llama70b_msg_defaultgoal_reworded | การทดลองเปลี่ยนคำใหม่ทันที |
ในการสร้างคำอธิบายประกอบ เราใช้ vLLM และเวอร์ชันแชทของ Llama 2 หากคุณต้องการสร้างคำอธิบายประกอบของคุณเองด้วย Llama 2 หรือทำซ้ำขั้นตอนคำอธิบายประกอบของเรา ตรวจสอบให้แน่ใจว่าจะสามารถดาวน์โหลดโมเดลได้โดยทำตามคำแนะนำอย่างเป็นทางการ (ซึ่งสามารถทำได้ ใช้เวลาสองสามวันในการเข้าถึงตุ้มน้ำหนักโมเดล)
สคริปต์คำอธิบายประกอบจะถือว่าชุดข้อมูลจะได้รับการใส่คำอธิบายประกอบในส่วนต่างๆ โดยใช้อาร์กิวเมนต์ n-annotation-chunks ซึ่งช่วยให้กระบวนการสามารถดำเนินการแบบขนานได้ขึ้นอยู่กับความพร้อมใช้งานของทรัพยากร และมีความเข้มงวดในการรีสตาร์ท/การจองล่วงหน้า หากต้องการรันด้วยก้อนเดียว (เช่น เพื่อประมวลผลชุดข้อมูลทั้งหมด) และใส่คำอธิบายประกอบด้วยเทมเพลตพร้อมท์เริ่มต้นและข้อกำหนดเฉพาะของงาน ให้รันคำสั่งต่อไปนี้
python -m scripts.annotate_pairs_dataset --directory motif_dataset
--prompt-version default --goal-key defaultgoal
--n-annotation-chunks 1 --chunk-number 0
--llm-size 70 --num-gpus 8
โปรดทราบว่าพฤติกรรมเริ่มต้นจะดำเนินกระบวนการคำอธิบายประกอบต่อไปโดยผนวกคำอธิบายประกอบเข้ากับไฟล์ที่ระบุการกำหนดค่า เว้นแต่จะระบุไว้เป็นอย่างอื่นด้วยแฟล็ก --ignore-existing ชื่อของไฟล์ '.npy' ที่สร้างขึ้นสำหรับคำอธิบายประกอบสามารถเลือกได้ด้วยตนเองโดยใช้แฟล็ก --custom-annotator-string เป็นไปได้ที่จะใส่คำอธิบายประกอบโดยใช้ --llm-size 7 และ --llm-size 13 โดยใช้ GPU ตัวเดียวที่มีหน่วยความจำ 32GB คุณสามารถใส่คำอธิบายประกอบโดยใช้ --llm-size 70 กับโหนด 8-GPUs เราจัดเตรียมการประมาณเวลาคำอธิบายประกอบคร่าวๆ ด้วย GPU NVIDIA V100s 32G ที่นี่ สำหรับชุดข้อมูล 100,000 คู่ ซึ่งน่าจะสามารถสร้างผลลัพธ์ส่วนใหญ่ของเราขึ้นมาใหม่โดยประมาณได้ (ซึ่งได้มาจาก 500,000 คู่)
| แบบอย่าง | ทรัพยากรสำหรับใส่คำอธิบายประกอบ |
|---|---|
| ลามะ 2 7b | ~32 ชั่วโมง GPU |
| ลามะ 2 13บี | ~40 ชั่วโมง GPU |
| ลามะ 2 70b | ~72 ชั่วโมง GPU |
ในระยะที่สอง เราจะกลั่นความชอบของ LLM ให้เป็นฟังก์ชันการให้รางวัลผ่านเอนโทรปีข้าม หากต้องการเริ่มการฝึกอบรมการให้รางวัลด้วยไฮเปอร์พารามิเตอร์เริ่มต้น ให้ใช้คำสั่งต่อไปนี้
python -m scripts.train_reward --batch_size 1024 --num_workers 40
--reward_lr 1e-5 --num_epochs 10 --seed 777
--dataset_dir motif_dataset --annotator llama70b_msg_defaultgoal_default
--experiment standard_reward --train_dir train_dir/reward_saving_dir
ฟังก์ชันการให้รางวัลจะได้รับการฝึกผ่านคำอธิบายประกอบของ annotator ที่อยู่ใน --dataset_dir ฟังก์ชั่นผลลัพธ์จะถูกบันทึกไว้ใน train_dir ใต้โฟลเดอร์ย่อย --experiment
สุดท้ายนี้ เราฝึกอบรมตัวแทนด้วยฟังก์ชันการให้รางวัลที่ได้รับผ่านการเรียนรู้แบบเสริมกำลัง หากต้องการฝึกเอเจนต์ในงาน NetHackScore-v1 โดยใช้ไฮเปอร์พารามิเตอร์เริ่มต้นสำหรับการทดลองที่รวมรางวัลภายในและภายนอก คุณสามารถใช้คำสั่งต่อไปนี้
python -m scripts.main --algo APPO --env nle_fixed_eat_action --num_workers 24
--num_envs_per_worker 20 --batch_size 4096 --reward_scale 0.1 --obs_scale 255.0
--train_for_env_steps 2_000_000_000 --save_every_steps 10_000_000
--keep_checkpoints 5 --stats_avg 1000 --seed 777 --reward_dir train_dir/reward_saving_dir/standard_reward/
--experiment standard_motif --train_dir train_dir/rl_saving_dir
--extrinsic_reward 0.1 --llm_reward 0.1 --reward_encoder nle_torchbeast_encoder
--root_env NetHackScore-v1 --beta_count_exponent 3 --eps_threshold_quantile 0.5
หากต้องการเปลี่ยนงาน เพียงแก้ไขอาร์กิวเมนต์ --root_env ตารางต่อไปนี้ระบุค่าที่จำเป็นเพื่อให้ตรงกับการทดลองที่นำเสนอในรายงานอย่างชัดเจน งาน NetHackScore-v1 ได้รับการเรียนรู้ด้วยค่า extrinsic_reward ที่เป็น 0.1 ในขณะที่งานอื่นๆ ทั้งหมดจะใช้ค่า 10.0 เพื่อที่จะจูงใจให้ตัวแทนบรรลุเป้าหมาย
| สิ่งแวดล้อม | root_env |
|---|---|
| คะแนน | NetHackScore-v1 |
| บันได | NetHackStaircase-v1 |
| บันได (ชั้น 3) | NetHackStaircaseLvl3-v1 |
| บันได (ชั้น 4) | NetHackStaircaseLvl4-v1 |
| ออราเคิล | NetHackOracle-v1 |
| คำทำนายเงียบขรึม | NetHackOracleSober-v1 |
นอกจากนี้ หากคุณต้องการฝึกอบรมตัวแทนเพียงใช้รางวัลที่แท้จริงที่มาจาก LLM แต่ไม่มีรางวัลจากสภาพแวดล้อม เพียงตั้งค่า --extrinsic_reward 0.0 ในการทดลองที่ให้รางวัลอย่างแท้จริงเท่านั้น เราจะยุติตอนต่อเมื่อเจ้าหน้าที่เสียชีวิต แทนที่จะเป็นเมื่อเจ้าหน้าที่บรรลุเป้าหมาย สภาพแวดล้อมที่ปรับเปลี่ยนเหล่านี้มีการแจกแจงไว้ในตารางต่อไปนี้
| สิ่งแวดล้อม | root_env |
|---|---|
| บันได (ระดับ 3) - ภายในเท่านั้น | NetHackStaircaseLvl3Continual-v1 |
| บันได (ระดับ 4) - ภายในเท่านั้น | NetHackStaircaseLvl4Continual-v1 |
นอกจากนี้เรายังมีสคริปต์สำหรับการแสดงภาพตัวแทน RL ที่ได้รับการฝึกอบรมของคุณอีกด้วย ข้อมูลนี้สามารถให้ข้อมูลเชิงลึกที่สำคัญเกี่ยวกับพฤติกรรมของเนื้อหาได้ แต่ยังจะสร้างข้อความยอดนิยมสำหรับแต่ละตอนด้วย ซึ่งสามารถช่วยทำความเข้าใจได้ว่ากำลังพยายามเพิ่มประสิทธิภาพเพื่ออะไร คุณเพียงแค่ต้องเรียกใช้คำสั่งต่อไปนี้
python -m scripts.visualize --train_dir train_dir/rl_saving_dir --experiment standard_motif
หากคุณต่อยอดผลงานของเราหรือพบว่ามีประโยชน์ โปรดอ้างอิงโดยใช้ bibtex ต่อไปนี้
@article{klissarovdoro2023motif,
title={Motif: Intrinsic Motivation From Artificial Intelligence Feedback},
author={Klissarov, Martin and D’Oro, Pierluca and Sodhani, Shagun and Raileanu, Roberta and Bacon, Pierre-Luc and Vincent, Pascal and Zhang, Amy and Henaff, Mikael},
year={2023},
month={9},
journal={arXiv preprint arXiv:2310.00166}
}
Motif ส่วนใหญ่ได้รับใบอนุญาตภายใต้ CC-BY-NC อย่างไรก็ตาม บางส่วนของโครงการจะพร้อมใช้งานภายใต้เงื่อนไขใบอนุญาตที่แยกต่างหาก: โรงงานตัวอย่างได้รับใบอนุญาตภายใต้ใบอนุญาต MIT


