
รวมข้อมูลในวงจรการเรียนรู้ของเครื่องทั้งหมดของคุณด้วย Space ซึ่งเป็นโซลูชันพื้นที่จัดเก็บข้อมูลที่ครอบคลุมที่จัดการข้อมูลตั้งแต่การนำเข้าไปจนถึงการฝึกได้อย่างราบรื่น
คุณสมบัติที่สำคัญ:
space.core.schema.types.files )space.TfFeatures เป็นประเภทฟิลด์ในตัวที่ให้ซีเรียลไลเซอร์สำหรับ dicts ที่ซ้อนกันของอาร์เรย์ numpy โดยยึดตาม TFDS FeaturesDictติดตั้ง:
pip install space-datasetsหรือติดตั้งจากรหัส:
cd python
pip install .[dev]ดูเอกสารการตั้งค่าและประสิทธิภาพ
สร้างชุดข้อมูล Space ที่มีฟิลด์ดัชนีสองช่อง ( id , image_name ) (จัดเก็บใน Parquet) และฟิลด์บันทึก ( feature ) (จัดเก็บใน ArrayRecord)
ตัวอย่างนี้ใช้ประเภท binary ธรรมดาสำหรับฟิลด์เรกคอร์ด Space รองรับประเภท space.TfFeatures ที่รวมเข้ากับตัวซีเรียลไลเซอร์ฟีเจอร์ TFDS ดูรายละเอียดเพิ่มเติมในตัวอย่าง TFDS
import pyarrow as pa
from space import Dataset
schema = pa . schema ([
( "id" , pa . int64 ()),
( "image_name" , pa . string ()),
( "feature" , pa . binary ())])
ds = Dataset . create (
"/path/to/<mybucket>/example_ds" ,
schema ,
primary_keys = [ "id" ],
record_fields = [ "feature" ]) # Store this field in ArrayRecord files
# Load the dataset from files later:
ds = Dataset . load ( "/path/to/<mybucket>/example_ds" ) หรือคุณสามารถใช้ catalogs เพื่อจัดการชุดข้อมูลตามชื่อแทนตำแหน่งที่ตั้งได้:
from space import DirCatalog
# DirCatalog manages datasets in a directory.
catalog = DirCatalog ( "/path/to/<mybucket>" )
# Same as the creation above.
ds = catalog . create_dataset ( "example_ds" , schema ,
primary_keys = [ "id" ], record_fields = [ "feature" ])
# Same as the load above.
ds = catalog . dataset ( "example_ds" )
# List all datasets and materialized views.
print ( catalog . datasets ())ผนวกลบข้อมูลบางส่วน การกลายพันธุ์แต่ละครั้งจะสร้างข้อมูลเวอร์ชันใหม่ ซึ่งแสดงด้วย ID จำนวนเต็มที่เพิ่มขึ้น ผู้ใช้สามารถเพิ่มแท็กให้กับรหัสเวอร์ชันเป็นนามแฝงได้
import pyarrow . compute as pc
from space import RayOptions
# Create a local runner:
runner = ds . local ()
# Or create a Ray runner:
runner = ds . ray ( ray_options = RayOptions ( max_parallelism = 8 ))
# To avoid https://github.com/ray-project/ray/issues/41333, wrap the runner
# with @ray.remote when running in a remote Ray cluster.
#
# @ray.remote
# def run():
# return runner.read_all()
#
# Appending data generates a new dataset version `snapshot_id=1`
# Write methods:
# - append(...): no primary key check.
# - insert(...): fail if primary key exists.
# - upsert(...): overwrite if primary key exists.
ids = range ( 100 )
runner . append ({
"id" : ids ,
"image_name" : [ f" { i } .jpg" for i in ids ],
"feature" : [ f"somedata { i } " . encode ( "utf-8" ) for i in ids ]
})
ds . add_tag ( "after_append" ) # Version management: add tag to snapshot
# Deletion generates a new version `snapshot_id=2`
runner . delete ( pc . field ( "id" ) == 1 )
ds . add_tag ( "after_delete" )
# Show all versions
ds . versions (). to_pandas ()
# >>>
# snapshot_id create_time tag_or_branch
# 0 2 2024-01-12 20:23:57+00:00 after_delete
# 1 1 2024-01-12 20:23:38+00:00 after_append
# 2 0 2024-01-12 20:22:51+00:00 None
# Read options:
# - filter_: optional, apply a filter (push down to reader).
# - fields: optional, field selection.
# - version: optional, snapshot_id or tag, time travel back to an old version.
# - batch_size: optional, output size.
runner . read_all (
filter_ = pc . field ( "image_name" ) == "2.jpg" ,
fields = [ "feature" ],
version = "after_add" # or snapshot ID `1`
)
# Read the changes between version 0 and 2.
for change in runner . diff ( 0 , "after_delete" ):
print ( change . change_type )
print ( change . data )
print ( "===============" )สร้างสาขาใหม่และทำการเปลี่ยนแปลงในสาขาใหม่:
# The default branch is "main"
ds . add_branch ( "dev" )
ds . set_current_branch ( "dev" )
# Make changes in the new branch, the main branch is not updated.
# Switch back to the main branch.
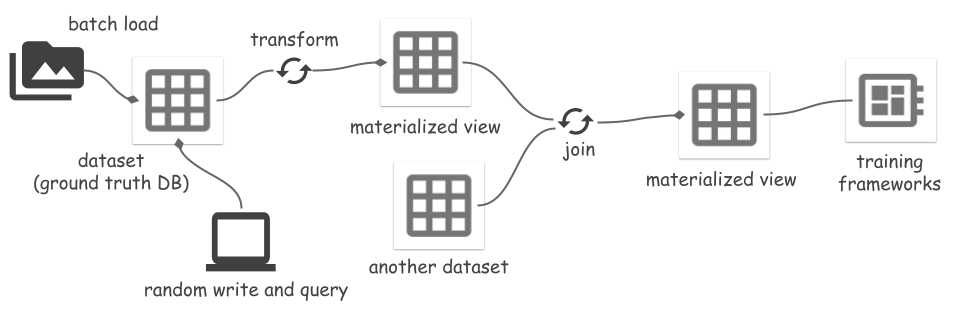
ds . set_current_branch ( "main" )Space รองรับการแปลงชุดข้อมูลเป็นมุมมอง และทำให้มุมมองเป็นรูปธรรมเป็นไฟล์ การเปลี่ยนแปลงได้แก่:
เมื่อชุดข้อมูลต้นทางได้รับการแก้ไข การรีเฟรชมุมมองที่เป็นรูปธรรมจะซิงโครไนซ์การเปลี่ยนแปลงแบบค่อยเป็นค่อยไป ซึ่งจะช่วยประหยัดต้นทุนการประมวลผลและ IO ดูรายละเอียดเพิ่มเติมในตัวอย่าง Segment Anything การอ่านหรือการรีเฟรชมุมมองต้องเป็น Ray runner เนื่องจากมีการใช้งานตามการแปลง Ray
Materialized view mv สามารถใช้เป็น view mv.view หรือชุดข้อมูล mv.dataset แบบแรกจะอ่านข้อมูลจากไฟล์ของชุดข้อมูลต้นทางเสมอและประมวลผลข้อมูลทั้งหมดได้ทันที ส่วนหลังจะอ่านข้อมูลที่ประมวลผลโดยตรงจากไฟล์ของ MV ข้ามการประมวลผลข้อมูล
# A sample transform UDF.
# Input is {"field_name": [values, ...], ...}
def modify_feature_udf ( batch ):
batch [ "feature" ] = [ d + b"123" for d in batch [ "feature" ]]
return batch
# Create a view and materialize it.
view = ds . map_batches (
fn = modify_feature_udf ,
output_schema = ds . schema ,
output_record_fields = [ "feature" ]
)
view_runner = view . ray ()
# Reading a view will read the source dataset and apply transforms on it.
# It processes all data using `modify_feature_udf` on the fly.
for d in view_runner . read ():
print ( d )
mv = view . materialize ( "/path/to/<mybucket>/example_mv" )
# Or use a catalog:
# mv = catalog.materialize("example_mv", view)
mv_runner = mv . ray ()
# Refresh the MV up to version tag `after_add` of the source.
mv_runner . refresh ( "after_add" , batch_size = 64 ) # Reading batch size
# Or, mv_runner.refresh() refresh to the latest version
# Use the MV runner instead of view runner to directly read from materialized
# view files, no data processing any more.
mv_runner . read_all ()ดูตัวอย่างแบบเต็มในตัวอย่าง Segment Anything ยังไม่รองรับการสร้างมุมมองที่เป็นรูปธรรมของผลลัพธ์การเข้าร่วม
# If input is a materialized view, using `mv.dataset` instead of `mv.view`
# Only support 1 join key, it must be primary key of both left and right.
joined_view = mv_left . dataset . join ( mv_right . dataset , keys = [ "id" ])มีหลายวิธีในการผสานรวม Space Storage เข้ากับเฟรมเวิร์ก ML Space จัดเตรียมแหล่งข้อมูลการเข้าถึงแบบสุ่มสำหรับการอ่านข้อมูลในไฟล์ ArrayRecord:
from space import RandomAccessDataSource
datasource = RandomAccessDataSource (
# <field-name>: <storage-location>, for reading data from ArrayRecord files.
{
"feature" : "/path/to/<mybucket>/example_mv" ,
},
# Don't auto deserialize data, because we store them as plain bytes.
deserialize = False )
len ( datasource )
datasource [ 2 ]ชุดข้อมูลหรือมุมมองสามารถอ่านเป็นชุดข้อมูล Ray ได้:
ray_ds = ds . ray_dataset ()
ray_ds . take ( 2 )ข้อมูลในไฟล์ Parquet สามารถอ่านเป็นชุดข้อมูล HuggingFace ได้:
from datasets import load_dataset
huggingface_ds = load_dataset ( "parquet" , data_files = { "train" : ds . index_files ()})รายการเส้นทางไฟล์ของไฟล์ดัชนี (Parquet) ทั้งหมด:
ds . index_files ()
# Or show more statistics information of Parquet files.
ds . storage . index_manifest () # Accept filter and snapshot_idแสดงข้อมูลสถิติของไฟล์ ArrayRecord ทั้งหมด:
ds . storage . record_manifest () # Accept filter and snapshot_id Space เป็นโครงการใหม่ภายใต้การพัฒนาอย่างแข็งขัน
- งานที่กำลังดำเนินอยู่:
นี่ไม่ใช่ผลิตภัณฑ์ของ Google ที่ได้รับการสนับสนุนอย่างเป็นทางการ


