ฉันใช้พจนานุกรมเป็นประจำ ทั้งในขณะที่เขียนสำเนาสำหรับเอกสารประกอบและ README และในขณะที่เขียนโค้ดสำหรับการตั้งชื่อตัวแปรและฟังก์ชัน
ฉันเคยใช้พจนานุกรมออนไลน์ โดยเฉพาะ thesaurus.com แต่ฉันเกลียดประสบการณ์นี้ แม้ว่าผลลัพธ์จะมีประโยชน์และมีการจัดระเบียบอย่างดี แต่ก็ไม่เหมาะกับแป้นพิมพ์และนำทางได้ช้า โดยเฉพาะอย่างยิ่งเมื่อผลลัพธ์ขยายไปยังหลายหน้า
ฉันจึงสร้างอรรถาภิธานของตัวเองขึ้นมา ฉันใช้บ่อยกว่าที่เคยใช้ thesaurus.com มีคุณสมบัติน้อยกว่า แต่เข้าถึงได้เร็วกว่ามากและรบกวนกระบวนการสร้างสรรค์น้อยกว่ามาก
ในหน้าต่างเทอร์มินัล ให้พิมพ์ th ตามด้วยคำ ตัวอย่างเช่น เมื่อต้องการค้นหาคำว่า Attention :
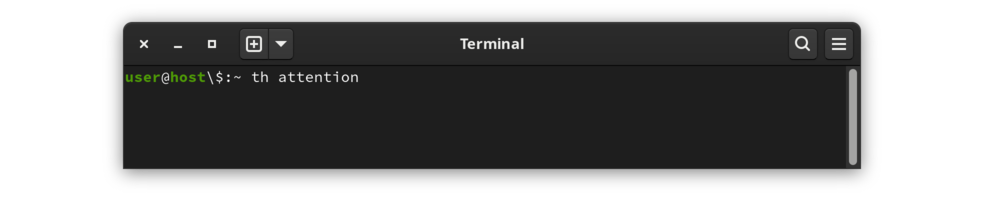 |
|---|
เรียกร้อง th สนใจ |
ผลลัพธ์คือรายการคำและวลีที่เกี่ยวข้อง ซึ่งจัดเป็นคอลัมน์ โดยมีบรรทัดบริบทด้านบนและด้านล่าง และรายการตัวเลือกการนำทางที่ด้านล่าง
 |
|---|
| ผลการค้นหา ความสนใจ |
บรรทัดล่างสุดของการแสดงผลลัพธ์จะแสดงรายการการดำเนินการที่พร้อมใช้งาน เริ่มต้นการกระทำโดยพิมพ์ตัวอักษรตัวแรกของการกระทำ (เน้นบนหน้าจอเพื่อเน้น)
ข้อมูลจะถูกจัดเรียงเป็นรายการอรรถาภิธาน โดยแต่ละรายการจะรวบรวมคำและวลีที่เกี่ยวข้องกัน รายการคือ ส่วนท้าย และคำและวลีที่เกี่ยวข้องคือ สาขา
มุมมองเริ่มต้นอยู่ในโหมดสาขา คำที่แสดงคือคำและวลีที่แสดงต่อจากรายการในอรรถาภิธานต้นฉบับ การสลับไปที่โหมด Trunks จะแสดงรายการที่มีคำนั้น สิ่งนี้แสดงให้เห็นอย่างชัดเจนที่สุดโดยตัวอย่างที่ไม่มีสาขาใด ๆ :
 |
|---|
| trigger คือคำที่ไม่มีรายการ |
ไม่มีรายการพจนานุกรมสำหรับคำว่า trigger อย่างไรก็ตาม คำว่า trigger อยู่ในพจนานุกรม แต่เป็นสาขาย่อยของรายการอื่นๆ สลับไปที่โหมด trunks เพื่อดูรายการที่มี trigger :
 |
|---|
| รายการคำที่ ทริกเกอร์ เป็นคำที่เกี่ยวข้อง |
โปรแกรมนี้ไม่มีให้บริการในรูปแบบแพ็คเกจ ต้องดาวน์โหลดซอร์สโค้ดและสร้างโครงการ ขั้นตอนต่อไปนี้จะสร้างอรรถาภิธานที่ใช้งานได้:
git clone https://www.github.com/cjungmann/th.gitcd thmakemake thesaurus.dbเล่นกับโปรแกรมเพื่อดูว่าคุณชอบหรือไม่ หากคุณต้องการติดตั้งเพื่อให้พร้อมใช้งานภายนอกไดเร็กทอรี build ให้เรียกใช้คำสั่งต่อไปนี้:
sudo make install
มันง่ายที่จะลบโปรแกรมคือถ้าคุณตัดสินใจว่าคุณไม่ต้องการโปรแกรม
หากคุณได้ติดตั้งโปรแกรมแล้ว ให้ถอนการติดตั้งด้วย sudo make uninstall ก่อน
การดำเนินการนี้จะลบโปรแกรม ไฟล์สนับสนุน และไดเร็กทอรีที่ติดตั้งไฟล์สนับสนุนไว้
หากไม่ได้ติดตั้งโปรแกรม คุณสามารถลบไดเร็กทอรีที่โคลนได้อย่างปลอดภัย
เนื้อหาต่อไปนี้จะดึงดูดนักพัฒนาเป็นหลักหากใครก็ตาม
โปรเจ็กต์นี้สร้างได้ง่าย แต่ขึ้นอยู่กับซอฟต์แวร์อื่น ต่อไปนี้เป็นรายการการขึ้นต่อกัน ซึ่งเฉพาะรายการแรก (ฐานข้อมูล Berkeley) เท่านั้นที่อาจต้องมีการแทรกแซง รายการที่ 3 และ 4 ด้านล่างนี้จะถูกดาวน์โหลดลงในไดเร็กทอรีย่อยภายใต้ไดเร็กทอรี build และโค้ดที่พบมีการเชื่อมโยงแบบคงที่กับไฟล์ปฏิบัติการ ดังนั้นจึงไม่ส่งผลกระทบต่อสภาพแวดล้อมของคุณ
db เวอร์ชัน 5 (ฐานข้อมูล Berkeley) จำเป็นสำหรับฐานข้อมูล B-Tree ในโครงการ หากคุณใช้ git คุณควรมีสิ่งนี้อยู่แล้ว แม้แต่บน FreeBSD ซึ่งจะรวมเฉพาะ db เวอร์ชันเก่ากว่าเท่านั้น Make จะสิ้นสุดด้วยข้อความทันทีหากไม่พบ db ที่เหมาะสม ซึ่งในกรณีนี้ ขึ้นอยู่กับคุณว่าจะใช้ตัวจัดการแพ็คเกจเพื่อติดตั้ง db หรือสร้างจากแหล่งที่มา
git ใช้เพื่อดาวน์โหลดการอ้างอิงบางอย่าง แม้ว่าการขึ้นต่อกันของโปรเจ็กต์จะสามารถดาวน์โหลดได้โดยตรงโดยไม่ต้องใช้ git แต่การทำเช่นนี้ต้องอาศัยความรู้ที่ไม่มีเอกสารเกี่ยวกับไฟล์ต้นฉบับ ปัญหาที่หลีกเลี่ยงได้เมื่อ make สามารถใช้ git เพื่อดาวน์โหลดการขึ้นต่อกันได้
readargs เป็นหนึ่งในโครงการของฉันที่ประมวลผลอาร์กิวเมนต์บรรทัดคำสั่ง ในขณะที่โปรเจ็กต์นี้ยังคงใช้โดย th ก็ไม่จำเป็นต้องติดตั้งไลบรารีนี้อีกต่อไปเพื่อให้ th ทำงานได้ ตอน นี้ Makefile จะดาวน์โหลดโปรเจ็กต์ readargs ลงในไดเร็กทอรีย่อย สร้างและใช้ไลบรารีแบบคงที่แทน
c_patterns เป็นอีกหนึ่งโครงการของฉัน ซึ่งเป็นการทดลองในการจัดการโค้ดที่นำมาใช้ซ้ำได้โดยไม่ต้องใช้ไลบรารี Makefile ใช้ git เพื่อดาวน์โหลดโปรเจ็กต์ จากนั้นสร้างลิงก์ไปยังโมดูล c_patterns บางตัวในไดเร็กทอรี src เพื่อรวมไว้ในบิลด์ th
โปรเจ็กต์นี้แม้จะมีประโยชน์ (อย่างน้อยสำหรับฉัน) แต่ก็เป็นการทดลองเช่นกัน เป้าหมายประการหนึ่งของฉันที่นี่คือการพัฒนาทักษะการเขียน makefile การตัดสินใจสร้างและติดตั้งบางอย่างที่ฉันได้ทำอาจไม่ใช่แนวปฏิบัติที่ดีที่สุด หรืออาจถูกนักพัฒนาที่มีประสบการณ์มากกว่าขมวดคิ้วด้วยซ้ำ หากคุณกังวลเกี่ยวกับสิ่งที่จะเกิดขึ้นกับระบบของคุณหากคุณติดตั้ง th ฉันหวังว่าข้อมูลต่อไปนี้จะแจ้งการตัดสินใจของคุณ
ตามที่คาดไว้ make จะรวบรวมแอปพลิเคชัน th บางที อาจทำ ภารกิจอื่น ๆ ที่อาจต้องใช้เวลาบ้างโดยไม่ได้ตั้งใจ:
ดาวน์โหลดที่เก็บโมดูล C ของฉันและใช้หลายโมดูลโดยการสร้างลิงก์ลงในไดเร็กทอรี src
แทนที่จะใช้ configure เพื่อตรวจสอบการขึ้นต่อกัน makefile จะระบุและสิ้นสุดทันทีด้วยข้อความที่เป็นประโยชน์หากตรวจพบการขึ้นต่อกันที่หายไป
ดาวน์โหลดและนำเข้าอรรถาภิธาน moby ซึ่งเป็นสาธารณสมบัติจาก The Gutenberg Project ซึ่งจะเติมฐานข้อมูลคำของแอปพลิเคชัน
ละทิ้ง การดาวน์โหลดและนำเข้าฐานข้อมูลการนับจำนวนคำ แนวคิดคือการเสนอลำดับการเรียงลำดับแบบอื่นเพื่อให้ง่ายต่อการค้นหาคำจากรายการที่ยาวกว่า สิ่งนี้ไม่ทำงานในขณะนี้ ฉันไม่แน่ใจว่าฉันจะกลับมาที่นี่อีกเพราะฉันพบว่าประโยชน์ของการอ่านรายการตัวอักษรมีมากกว่าประโยชน์ที่น่าสงสัยของการพยายามใส่คำที่ใช้บ่อยมากขึ้นเป็นอันดับแรก เหตุผลก็คือ การติดตามคำศัพท์ในการพิจารณาทำได้ง่ายกว่ามาก เมื่อคำศัพท์เหล่านั้นไม่ได้กระจัดกระจายแบบสุ่มในรายการคำที่ยาวเหยียด
ฉันเพิ่งสังเกตเห็นว่ามีทรัพยากรรายการ Moby Part of Speech ที่สามารถช่วยจัดระเบียบผลลัพธ์ได้ มันน่าสนใจ แต่ฉันไม่แน่ใจว่ามันจะมีประโยชน์หรือไม่ โดยพิจารณาจากจำนวนการเรียงลำดับตัวอักษรที่ช่วยในการใช้ผลลัพธ์ เราจะเห็น.
ฉันมีวัตถุประสงค์หลายประการเมื่อเริ่มโครงการนี้
ฉันต้องการประสบการณ์เพิ่มเติมกับ Berkeley Database ฐานข้อมูลที่เก็บคีย์นี้รองรับแอปพลิเคชันอื่นๆ มากมาย รวมถึง git และ sqlite
ฉันต้องการฝึกใช้โมดูลโปรเจ็กต์ c_patterns ของฉัน การใช้โมดูลเหล่านี้ในโครงการจริงช่วยให้ฉันเข้าใจข้อบกพร่องในการออกแบบและคุณสมบัติที่ขาดหายไป ฉันใช้
columnize.c เพื่อสร้างเอาต์พุตเรียงเป็นแนว
prompter.c สำหรับเมนูตัวเลือกขั้นต่ำที่ด้านล่างของเอาต์พุต
get_keypress.c สำหรับการกดปุ่มแบบไม่สะท้อน ส่วนใหญ่ใช้โดย prompter.c
ฉันต้องการฝึกออกแบบกระบวนการสร้างที่ทำงานได้ทั้งใน Gnu Linux และ BSD ซึ่งรวมถึงการระบุโมดูลที่หายไป (โดยเฉพาะ db ซึ่ง BSD มีไลบรารีเก่าเกินไป) และการออกแบบการประมวลผลแบบมีเงื่อนไขใหม่
ฉันไม่ได้กำหนดเป้าหมายไปที่ Windows เพราะมันแตกต่างจาก Linux มากกว่า BSD อย่างมีนัยสำคัญ และฉันไม่คาดหวังว่าผู้ใช้ Windows จำนวนมากจะสบายใจที่จะเปลี่ยนไปใช้แอปพลิเคชันบรรทัดคำสั่ง
Berkeley Database ( bdb ) ดูเหมือนเป็นผลิตภัณฑ์ฐานข้อมูลที่น่าสนใจ แนวทาง C-library ระดับต่ำของมันดูคล้ายกับกลไก FairCom DB ที่ฉันเคยใช้ในช่วงปลายทศวรรษ 1990
Berkeley Database มีความน่าสนใจเนื่องจากเป็นส่วนหนึ่งของการแจกจ่าย Linux และ BSD และมีขนาดเล็ก ให้รางวัลแก่การวางแผนข้อมูลโดยละเอียด และเป็นข้ออ้างในการสำรวจแนวคิดเกี่ยวกับภาษา C ของฉัน
โปรเจ็กต์นี้เป็นการรีสตาร์ทโปรเจ็กต์คำศัพท์ของฉัน ซึ่งตั้งใจให้เป็นพจนานุกรมและพจนานุกรมบรรทัดคำสั่ง โปรเจ็กต์นั้นเป็นการใช้ bdb ครั้งแรกของฉัน ดังนั้นงานของฉันบางส่วนจึงดูงุ่มง่ามเล็กน้อย ฉันต้องการออกแบบโค้ด bdb อีกครั้งตั้งแต่เริ่มต้น ฉันจะคัดลอกโค้ดแยกวิเคราะห์ข้อความบางส่วนจาก คำว่า project ที่จะใช้ได้ที่นี่
เมื่อใช้ชุดข้อมูลขนาดใหญ่ที่เป็นพจนานุกรมและพจนานุกรม ฉันยังต้องการทดสอบความแตกต่างด้านประสิทธิภาพระหว่างวิธีการเข้าถึงข้อมูล Queue และ Recno ฉันคาดหวังว่าคิวจะเร็วขึ้นเมื่อสามารถคำนวณจุดเริ่มต้นและจุดสิ้นสุดของบันทึกที่มีความยาวคงที่ได้ การเข้าถึงด้วยหมายเลขบันทึกของบันทึกที่มีความยาวผันแปรได้จะต้องมีการค้นหาตำแหน่งไฟล์ ฉันต้องการวัดความแตกต่างของประสิทธิภาพเพื่อชั่งน้ำหนักความได้เปรียบนั้นเทียบกับประสิทธิภาพการจัดเก็บของบันทึกที่มีความยาวผันแปรได้
มีแหล่งข้อมูลสาธารณสมบัติสองแหล่งของ thesauri:
ฉันใช้อรรถาภิธานของ Moby เนื่องจากการจัดระเบียบนั้นง่ายกว่ามากและแยกวิเคราะห์ได้ง่ายกว่า ปัญหาคือคำพ้องความหมายมีมากมาย และขาดการจัดระเบียบ ทำให้สแกนได้ยากกว่ามากเมื่อค้นหาคำพ้องความหมายที่เหมาะสม
ด้วยคำพ้องความหมายหลายร้อยคำสำหรับหลายคำ จึงเป็นเรื่องยากมากที่จะสแกนรายการเพื่อค้นหาคำที่เหมาะสม ฉันจะพยายามกำหนดลำดับบางอย่างในรายการเพื่อให้ใช้งานได้ง่ายขึ้น หลังจากใช้เครื่องมือมาระยะหนึ่งแล้ว ฉันจึงสรุปได้ว่าการเรียงลำดับตัวอักษรดีที่สุด การกลับไปใช้คำในรายการตัวอักษรนั้นง่ายกว่ามาก ฉันได้ลบตัวเลือกในการเลือกลำดับคำอื่นแล้ว
การจำแนกประเภทที่ง่ายที่สุดคือความถี่ในการใช้คำ ฉันวางแผนที่จะแสดงรายการคำจากความถี่ในการใช้งานมากไปหาน้อย สันนิษฐานว่าคำที่ได้รับความนิยมมากกว่าอาจเป็นตัวเลือกที่ดีที่สุด ในขณะที่คำที่ได้รับความนิยมน้อยกว่าอาจล้าสมัย
ความถี่ของคำมีแหล่งที่มาหลายแหล่ง สิ่งที่ฉันใช้นั้นใช้พื้นฐานของ Google ngrams:
ข้อมูลคอร์ปัสภาษาธรรมชาติ: ข้อมูลที่สวยงาม
ฉันไม่ได้ศึกษาแหล่งที่มาของ Norvig จริงๆ ดังนั้นจึงเป็นไปได้ว่าอาจมีเรื่องไร้สาระมากมาย มีอีกแหล่งหนึ่งที่อาจมีรายการที่ปลอดภัยกว่า นั่นคือ hackerb9/gwordlist หาก Norvig เป็นปัญหา ฉันต้องการจำรายการสำรองนี้ซึ่งฉันจะแทนที่ได้
ส่วนนี้ไม่ได้พยายามอีกต่อไป การตีความข้อมูลต้นฉบับมีความซับซ้อนเนื่องจากจำเป็นต้องจดจำและแปลงสัญลักษณ์เฉพาะของพจนานุกรมให้เป็นอักขระยูนิโค้ด ฉันแก้ไขปัญหาเหล่านี้ได้หลายอย่างแล้ว แต่ยังมีอีกหลายอย่างที่ยังคงอยู่ Makefile ยังคงมีคำแนะนำในการดาวน์โหลดข้อมูลนี้ และที่เก็บข้อมูลจะเก็บสคริปต์การแปลงบางส่วนไว้ในกรณีที่ฉันต้องการกลับมาที่สิ่งนี้
การจัดกลุ่มคำพ้องความหมายตามส่วนของคำพูด (เช่น คำนาม กริยา คำคุณศัพท์ ฯลฯ) ก็มีประโยชน์เช่นกัน ปัญหาแรกคือการระบุส่วนของคำพูดที่แสดงโดยแต่ละคำ ปัญหาที่สองอยู่ในการนำเสนอ: มันจะดีกว่า แต่ยากกว่าในการเขียนโปรแกรม มีอินเทอร์เฟซที่ผู้ใช้เลือกส่วนของคำพูดก่อนแสดงคำ
พจนานุกรมอิเล็กทรอนิกส์ที่เป็นสาธารณสมบัติ
ความพยายามครั้งแรกของฉันคือการใช้ GNU Collaborative International Dictionary of English (GCIDE) มีพื้นฐานมาจาก Webster's เวอร์ชันเก่า (พ.ศ. 2457) โดยมีคำบางคำเพิ่มเติมโดยบรรณาธิการสมัยใหม่


