

MPIRE ย่อมาจาก MultiProcessing Is Really Easy เป็นแพ็คเกจ Python สำหรับการประมวลผลหลายตัว MPIRE ทำงานได้เร็วกว่าในสถานการณ์ส่วนใหญ่ อัดแน่นไปด้วยฟีเจอร์ต่างๆ มากมาย และโดยทั่วไปแล้วเป็นมิตรกับผู้ใช้มากกว่าแพ็คเกจมัลติโปรเซสเซอร์เริ่มต้น โดยผสมผสานแผนที่ที่สะดวกสบาย เช่น ฟังก์ชันของ multiprocessing.Pool ด้วยกัน รวมเข้ากับประโยชน์ของการใช้อ็อบเจ็กต์ที่ใช้ร่วมกันแบบคัดลอกเมื่อเขียนของ multiprocessing.Process กระบวนการ ร่วมกับสถานะผู้ปฏิบัติงานที่ใช้งานง่าย ข้อมูลเชิงลึกของผู้ปฏิบัติงาน ฟังก์ชันเริ่มต้นและออกของผู้ปฏิบัติงาน การหมดเวลา และ ฟังก์ชั่นแถบความคืบหน้า
มีเอกสารฉบับเต็มอยู่ที่https://sybrenjansen.github.io/mpire/
map / map_unordered / imap / imap_unordered / apply / apply_asyncfork เท่านั้น)rich และโน้ตบุ๊ก)daemonMPIRE ได้รับการทดสอบบน Linux, macOS และ Windows สำหรับผู้ใช้ Windows และ macOS มีคำเตือนเล็กๆ น้อยๆ บางประการที่ทราบ ซึ่งมีบันทึกไว้ในบทการแก้ไขปัญหา
ผ่าน pip (PyPi):
pip install mpireMPIRE มีให้บริการผ่าน conda-forge:
conda install -c conda-forge mpire สมมติว่าคุณมีฟังก์ชันที่ใช้เวลานานซึ่งรับอินพุตบางส่วนและส่งกลับผลลัพธ์ ฟังก์ชันง่ายๆ เช่นนี้เรียกว่าปัญหาคู่ขนานที่น่าอับอาย ซึ่งเป็นฟังก์ชันที่ต้องใช้ความพยายามเพียงเล็กน้อยหรือไม่ต้องออกแรงเลยในการเปลี่ยนเป็นงานคู่ขนาน การทำให้ฟังก์ชันธรรมดาขนานกันสามารถทำได้ง่ายเหมือนกับการนำเข้า multiprocessing และการใช้ multiprocessing.Pool คลาสพูล:
import time
from multiprocessing import Pool
def time_consuming_function ( x ):
time . sleep ( 1 ) # Simulate that this function takes long to complete
return ...
with Pool ( processes = 5 ) as pool :
results = pool . map ( time_consuming_function , range ( 10 )) MPIRE สามารถนำมาใช้แทน multiprocessing แบบดรอปอินได้เกือบทั้งหมด เราใช้คลาส mpire.WorkerPool และเรียกใช้หนึ่งในฟังก์ชัน map ที่มีอยู่:
from mpire import WorkerPool
with WorkerPool ( n_jobs = 5 ) as pool :
results = pool . map ( time_consuming_function , range ( 10 )) ความแตกต่างในโค้ดมีเพียงเล็กน้อย: ไม่จำเป็นต้องเรียนรู้ไวยากรณ์การประมวลผลหลายตัวใหม่ทั้งหมด หากคุณคุ้นเคยกับ vanilla multiprocessing ฟังก์ชันการทำงานเพิ่มเติมที่มีให้คือสิ่งที่ทำให้ MPIRE แตกต่าง
สมมติว่าเราต้องการทราบสถานะของงานปัจจุบัน: มีงานกี่ชิ้นที่เสร็จสมบูรณ์, นานแค่ไหนก่อนที่งานจะพร้อม? ง่ายพอ ๆ กับการตั้งค่าพารามิเตอร์ progress_bar เป็น True :
with WorkerPool ( n_jobs = 5 ) as pool :
results = pool . map ( time_consuming_function , range ( 10 ), progress_bar = True )และมันจะส่งออกแถบความคืบหน้า tqdm ที่จัดรูปแบบอย่างสวยงาม
MPIRE ยังมีแดชบอร์ดซึ่งคุณต้องติดตั้งการขึ้นต่อกันเพิ่มเติม ดูแดชบอร์ดสำหรับข้อมูลเพิ่มเติม
หมายเหตุ: อ็อบเจ็กต์ที่แชร์แบบ Copy-on-write ใช้ได้เฉพาะกับ start method fork เท่านั้น สำหรับ threading เกลียวออบเจ็กต์จะถูกแชร์ตามที่เป็นอยู่ สำหรับวิธีการเริ่มต้นอื่นๆ ออบเจ็กต์ที่ใช้ร่วมกันจะถูกคัดลอกหนึ่งครั้งสำหรับผู้ปฏิบัติงานแต่ละคน ซึ่งยังคงดีกว่าหนึ่งครั้งต่องาน
หากคุณมีออบเจ็กต์ตั้งแต่หนึ่งรายการขึ้นไปที่คุณต้องการแชร์ระหว่างผู้ปฏิบัติงานทั้งหมด คุณสามารถใช้ตัวเลือก copy-on-write shared_objects ของ MPIRE ได้ MPIRE จะส่งผ่านออบเจ็กต์เหล่านี้เพียงครั้งเดียวสำหรับผู้ปฏิบัติงานแต่ละคน โดยไม่มีการคัดลอก/ทำให้เป็นอนุกรม เฉพาะเมื่อคุณแก้ไขวัตถุในฟังก์ชันของผู้ปฏิบัติงานเท่านั้น มันจึงจะเริ่มคัดลอกวัตถุนั้นให้กับผู้ปฏิบัติงานนั้น
def time_consuming_function ( some_object , x ):
time . sleep ( 1 ) # Simulate that this function takes long to complete
return ...
def main ():
some_object = ...
with WorkerPool ( n_jobs = 5 , shared_objects = some_object ) as pool :
results = pool . map ( time_consuming_function , range ( 10 ), progress_bar = True )ดู shared_objects สำหรับรายละเอียดเพิ่มเติม
ผู้ปฏิบัติงานสามารถเริ่มต้นได้โดยใช้คุณลักษณะ worker_init เมื่อใช้ร่วมกับ worker_state คุณสามารถโหลดโมเดลหรือตั้งค่าการเชื่อมต่อฐานข้อมูล ฯลฯ :
def init ( worker_state ):
# Load a big dataset or model and store it in a worker specific worker_state
worker_state [ 'dataset' ] = ...
worker_state [ 'model' ] = ...
def task ( worker_state , idx ):
# Let the model predict a specific instance of the dataset
return worker_state [ 'model' ]. predict ( worker_state [ 'dataset' ][ idx ])
with WorkerPool ( n_jobs = 5 , use_worker_state = True ) as pool :
results = pool . map ( task , range ( 10 ), worker_init = init ) ในทำนองเดียวกัน คุณสามารถใช้ฟีเจอร์ worker_exit เพื่อให้ MPIRE เรียกใช้ฟังก์ชันเมื่อใดก็ตามที่ผู้ปฏิบัติงานยุติการทำงาน คุณยังสามารถปล่อยให้ฟังก์ชัน exit นี้ส่งคืนผลลัพธ์ ซึ่งสามารถรับได้ในภายหลัง ดูส่วน worker_init และ worker_exit สำหรับข้อมูลเพิ่มเติม
เมื่อการตั้งค่าการประมวลผลหลายตัวของคุณไม่ทำงานตามที่คุณต้องการ และคุณไม่รู้ว่าอะไรเป็นสาเหตุ ก็มีฟังก์ชันข้อมูลเชิงลึกของผู้ปฏิบัติงาน สิ่งนี้จะให้ข้อมูลเชิงลึกเกี่ยวกับการตั้งค่าของคุณ แต่จะไม่แสดงโปรไฟล์ฟังก์ชันที่คุณใช้งานอยู่ (มีไลบรารีอื่นสำหรับสิ่งนั้น) แต่จะบันทึกประวัติเวลาเริ่มต้น เวลารอ และเวลาทำงานของผู้ปฏิบัติงานแทน เมื่อมีการระบุฟังก์ชันเข้าและออกของผู้ปฏิบัติงาน ระบบจะกำหนดเวลาเหล่านั้นด้วย
บางทีคุณอาจส่งข้อมูลจำนวนมากไปยังคิวงาน ซึ่งทำให้เวลาในการรอนานขึ้น ไม่ว่าในกรณีใด คุณสามารถเปิดใช้งานและรับข้อมูลเชิงลึกได้โดยใช้แฟล็ก enable_insights และฟังก์ชัน mpire.WorkerPool.get_insights ตามลำดับ:
with WorkerPool ( n_jobs = 5 , enable_insights = True ) as pool :
results = pool . map ( time_consuming_function , range ( 10 ))
insights = pool . get_insights ()ดูข้อมูลเชิงลึกของผู้ปฏิบัติงานสำหรับตัวอย่างโดยละเอียดเพิ่มเติมและผลลัพธ์ที่คาดหวัง
การหมดเวลาสามารถตั้งค่าแยกกันสำหรับฟังก์ชันเป้าหมาย worker_init และ worker_exit เมื่อตั้งค่าและถึงการหมดเวลาแล้ว มันจะเกิด TimeoutError :
def init ():
...
def exit_ ():
...
# Will raise TimeoutError, provided that the target function takes longer
# than half a second to complete
with WorkerPool ( n_jobs = 5 ) as pool :
pool . map ( time_consuming_function , range ( 10 ), task_timeout = 0.5 )
# Will raise TimeoutError, provided that the worker_init function takes longer
# than 3 seconds to complete or the worker_exit function takes longer than
# 150.5 seconds to complete
with WorkerPool ( n_jobs = 5 ) as pool :
pool . map ( time_consuming_function , range ( 10 ), worker_init = init , worker_exit = exit_ ,
worker_init_timeout = 3.0 , worker_exit_timeout = 150.5 ) เมื่อใช้ threading เป็นวิธีการเริ่มต้น MPIRE จะไม่สามารถขัดจังหวะฟังก์ชันบางอย่าง เช่น time.sleep ได้
ดูการหมดเวลาสำหรับรายละเอียดเพิ่มเติม
MPIRE ได้รับการวัดประสิทธิภาพจากการวัดประสิทธิภาพที่แตกต่างกันสามแบบ: การคำนวณเชิงตัวเลข การคำนวณแบบมีสถานะ และการกำหนดค่าเริ่มต้นที่มีราคาแพง รายละเอียดเพิ่มเติมเกี่ยวกับการวัดประสิทธิภาพเหล่านี้สามารถพบได้ในบล็อกโพสต์นี้ รหัสทั้งหมดสำหรับการวัดประสิทธิภาพเหล่านี้สามารถพบได้ในโปรเจ็กต์นี้
โดยสรุป สาเหตุหลักที่ทำให้ MPIRE เร็วขึ้นคือ:
fork พร้อมใช้งาน เราสามารถใช้ประโยชน์จากอ็อบเจ็กต์ที่แชร์แบบ copy-on-write ซึ่งช่วยลดความจำเป็นในการคัดลอกอ็อบเจ็กต์ที่จำเป็นต้องแชร์ผ่านกระบวนการลูกกราฟต่อไปนี้แสดงผลลัพธ์ที่เป็นมาตรฐานโดยเฉลี่ยของการวัดประสิทธิภาพทั้งสามแบบ ผลลัพธ์สำหรับการวัดประสิทธิภาพแต่ละรายการสามารถพบได้ในโพสต์บนบล็อก การวัดประสิทธิภาพทำงานบนเครื่อง Linux ที่มี 20 คอร์ โดยปิดใช้งานไฮเปอร์เธรดและ RAM ขนาด 200GB สำหรับแต่ละงาน การทดลองดำเนินการด้วยจำนวนกระบวนการ/ผู้ปฏิบัติงานที่แตกต่างกัน และผลลัพธ์ได้รับค่าเฉลี่ยจากการรัน 5 ครั้ง
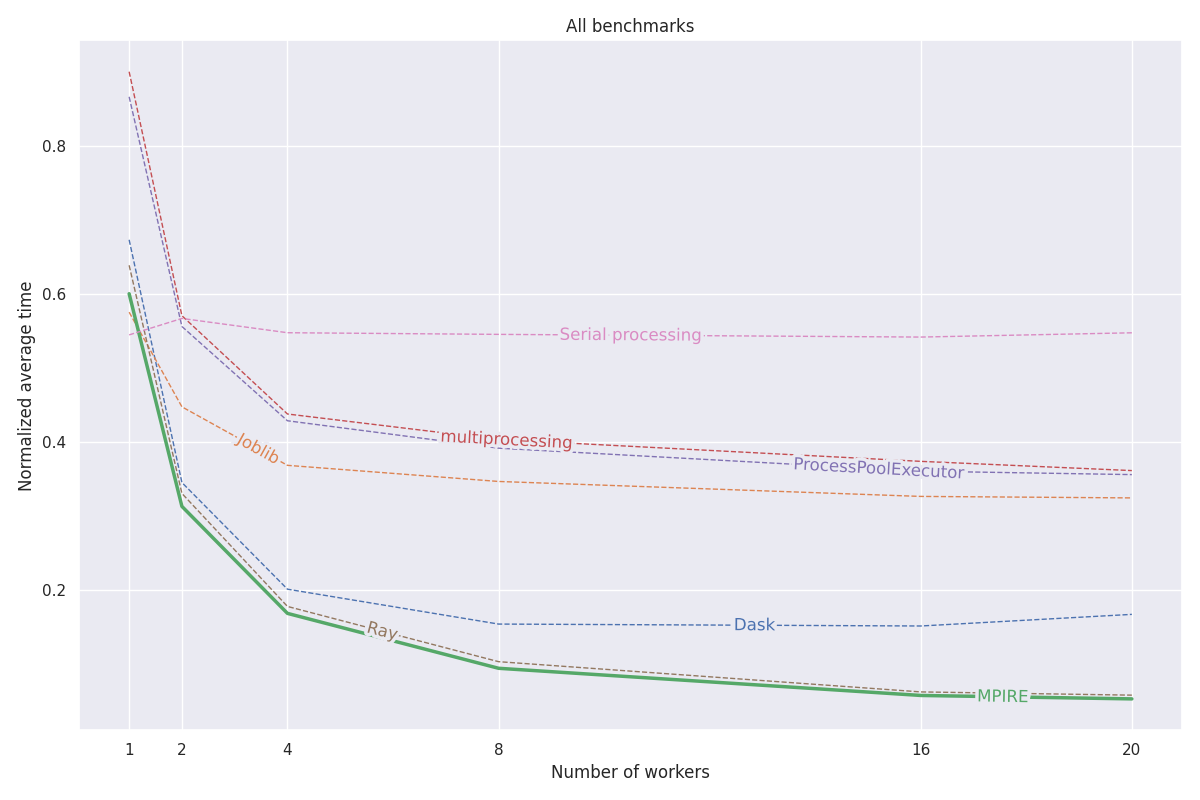
ดูเอกสารฉบับเต็มได้ที่ https://sybrenjansen.github.io/mpire/ สำหรับข้อมูลเกี่ยวกับคุณสมบัติอื่นๆ ทั้งหมดของ MPIRE
หากคุณต้องการสร้างเอกสารประกอบด้วยตนเอง โปรดติดตั้งการขึ้นต่อกันของเอกสารโดยดำเนินการ:
pip install mpire[docs]หรือ
pip install .[docs]เอกสารสามารถสร้างได้โดยใช้ Python <= 3.9 และดำเนินการ:
python setup.py build_docs เอกสารยังสามารถสร้างจากโฟลเดอร์ docs ได้โดยตรง ในกรณีนั้น MPIRE ควรได้รับการติดตั้งและพร้อมใช้งานในสภาพแวดล้อมการทำงานปัจจุบันของคุณ จากนั้นดำเนินการ:
make html ในโฟลเดอร์ docs


