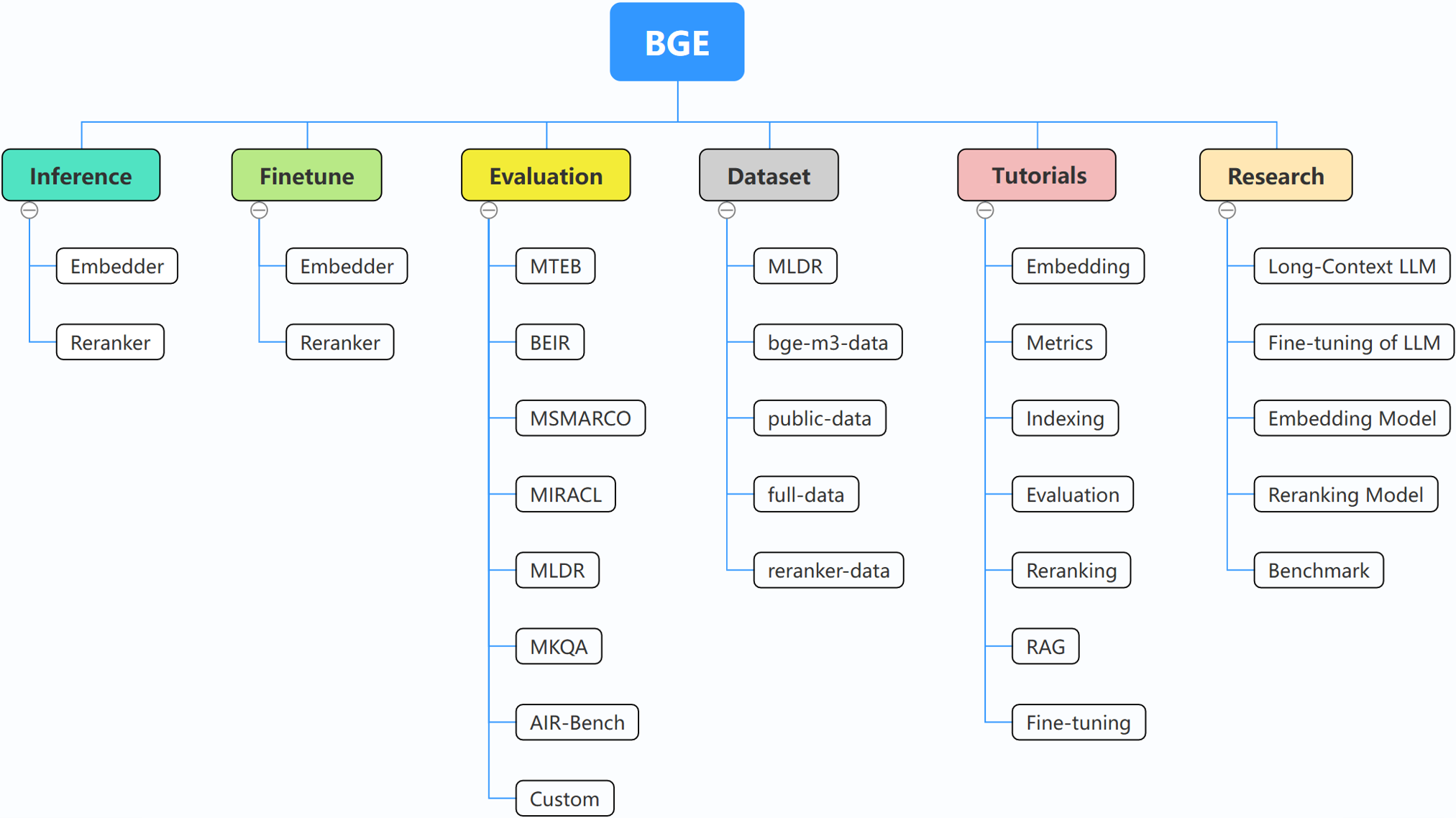
FlagEmbedding
1.3.2


ข่าว | การติดตั้ง | เริ่มต้นอย่างรวดเร็ว | ชุมชน | โครงการ | รายการรุ่น | ผู้ร่วมให้ข้อมูล | การอ้างอิง | ใบอนุญาต
อังกฤษ | 中文
BGE (BAAI General Embedding) มุ่งเน้นไปที่ LLM ที่ดึงข้อมูลมาเสริม ซึ่งประกอบด้วยโครงการต่อไปนี้ในปัจจุบัน:
29/10/2024: ? เราสร้างกลุ่ม WeChat สำหรับ BGE สแกนรหัส QR เพื่อเข้าร่วมแชทกลุ่ม! หากต้องการรับข้อความโดยตรงเกี่ยวกับการอัปเดตและการเปิดตัวใหม่ของเรา หรือมีคำถามหรือแนวคิดใด ๆ เข้าร่วมกับเราตอนนี้!

22/10/2024: เราเปิดตัวโมเดลที่น่าสนใจอีกรุ่นหนึ่งคือ OmniGen ซึ่งเป็นโมเดลการสร้างรูปภาพแบบครบวงจรที่รองรับงานต่างๆ OmniGen สามารถทำงานสร้างภาพที่ซับซ้อนให้สำเร็จได้โดยไม่จำเป็นต้องใช้ปลั๊กอินเพิ่มเติม เช่น ControlNet, IP-Adapter หรือโมเดลเสริม เช่น การตรวจจับท่าทาง และการตรวจจับใบหน้า
10/9/2024: ขอแนะนำ MemoRAG ก้าวไปข้างหน้าสู่ RAG 2.0 นอกเหนือจากการค้นพบความรู้ที่ได้รับแรงบันดาลใจจากหน่วยความจำ (repo: https://github.com/qhjqhj00/MemoRAG กระดาษ: https://arxiv.org/pdf/ 2409.05591v1)
2/9/2024: เริ่มดูแลรักษาบทแนะนำ เนื้อหาภายในจะได้รับการอัปเดตและปรับปรุงอย่างต่อเนื่อง คอยติดตาม!
26/07/2024: เปิดตัวโมเดลการฝังใหม่ bge-en-icl ซึ่งเป็นโมเดลการฝังที่รวมเอาความสามารถในการเรียนรู้ในบริบท ซึ่งโดยการให้ตัวอย่างการตอบสนองต่อแบบสอบถามที่เกี่ยวข้องกับงาน สามารถเข้ารหัสการสืบค้นที่สมบูรณ์ยิ่งขึ้นทางความหมาย เพิ่มประสิทธิภาพความหมายให้ดียิ่งขึ้น ความสามารถในการเป็นตัวแทนของการฝัง
26/07/2024: เปิดตัวโมเดลการฝังใหม่ bge-multilingual-gemma2 ซึ่งเป็นโมเดลการฝังหลายภาษาที่ใช้ gemma-2-9b ซึ่งรองรับหลายภาษาและงานดาวน์สตรีมที่หลากหลาย บรรลุ SOTA ใหม่บนการวัดประสิทธิภาพหลายภาษา (MIRACL, MTEB-fr และ MTEB-pl)
26/07/2024: เปิดตัว reranker แบบน้ำหนักเบาใหม่ bge-reranker-v2.5-gemma2-lightweight ซึ่งเป็น reranker แบบน้ำหนักเบาที่ใช้ gemma-2-9b ซึ่งรองรับการบีบอัดโทเค็นและการดำเนินการแบบน้ำหนักเบาแบบเลเยอร์ต่างๆ ยังคงสามารถรับประกันประสิทธิภาพที่ดีในขณะที่ประหยัด ทรัพยากรจำนวนมาก
BAAI/bge-reranker-base และ BAAI/bge-reranker-large ซึ่งมีประสิทธิภาพมากกว่าโมเดลแบบฝัง เราขอแนะนำให้ใช้/ปรับแต่งเอกสารเพื่อจัดอันดับเอกสาร top-k ที่ส่งคืนโดยการฝังโมเดลใหม่bge-*-v1.5 เพื่อบรรเทาปัญหาการกระจายความคล้ายคลึงกัน และเพิ่มความสามารถในการดึงข้อมูลโดยไม่ต้องมีคำแนะนำbge-large-* (ย่อมาจาก BAAI General Embedding) ซึ่งติดอันดับ 1 ในเกณฑ์มาตรฐาน MTEB และ C-MTEB! - -หากคุณไม่ต้องการปรับแต่งโมเดลอย่างละเอียด คุณสามารถติดตั้งแพ็คเกจโดยไม่ต้องพึ่งพาการปรับแต่งอย่างละเอียด:
pip install -U FlagEmbedding
หากคุณต้องการปรับแต่งโมเดลอย่างละเอียด คุณสามารถติดตั้งแพ็คเกจด้วยการพึ่งพาการปรับแต่งอย่างละเอียด:
pip install -U FlagEmbedding[finetune]
โคลนที่เก็บและติดตั้ง
git clone https://github.com/FlagOpen/FlagEmbedding.git
cd FlagEmbedding
# If you do not want to finetune the models, you can install the package without the finetune dependency:
pip install .
# If you want to finetune the models, you can install the package with the finetune dependency:
# pip install .[finetune]
สำหรับการพัฒนาในโหมดแก้ไขได้:
# If you do not want to finetune the models, you can install the package without the finetune dependency:
pip install -e .
# If you want to finetune the models, you can install the package with the finetune dependency:
# pip install -e .[finetune]
ขั้นแรก โหลดหนึ่งในโมเดลการฝัง BGE:
from FlagEmbedding import FlagAutoModel
model = FlagAutoModel.from_finetuned('BAAI/bge-base-en-v1.5',
query_instruction_for_retrieval="Represent this sentence for searching relevant passages:",
use_fp16=True)
จากนั้น ป้อนบางประโยคให้กับโมเดลและรับการฝัง:
sentences_1 = ["I love NLP", "I love machine learning"]
sentences_2 = ["I love BGE", "I love text retrieval"]
embeddings_1 = model.encode(sentences_1)
embeddings_2 = model.encode(sentences_2)
เมื่อเราได้ embeddings แล้ว เราก็สามารถคำนวณความคล้ายคลึงกันตามผลคูณภายในได้:
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
สำหรับรายละเอียดเพิ่มเติม คุณสามารถอ้างอิงถึงการอนุมานแบบฝัง การอนุมานอันดับใหม่ การปรับแต่งแบบฝัง, Fintune อันดับใหม่ และการประเมินผล
หากคุณไม่คุ้นเคยกับแนวคิดที่เกี่ยวข้องใดๆ โปรดดูบทช่วยสอน หากไม่มีโปรดแจ้งให้เราทราบ
หากต้องการหัวข้อที่น่าสนใจเพิ่มเติมเกี่ยวกับ BGE โปรดดูงานวิจัย
เรากำลังรักษาชุมชนของ BGE และ FlagEmbedding อย่างแข็งขัน แจ้งให้เราทราบหากคุณมีข้อเสนอแนะหรือความคิดเห็น!
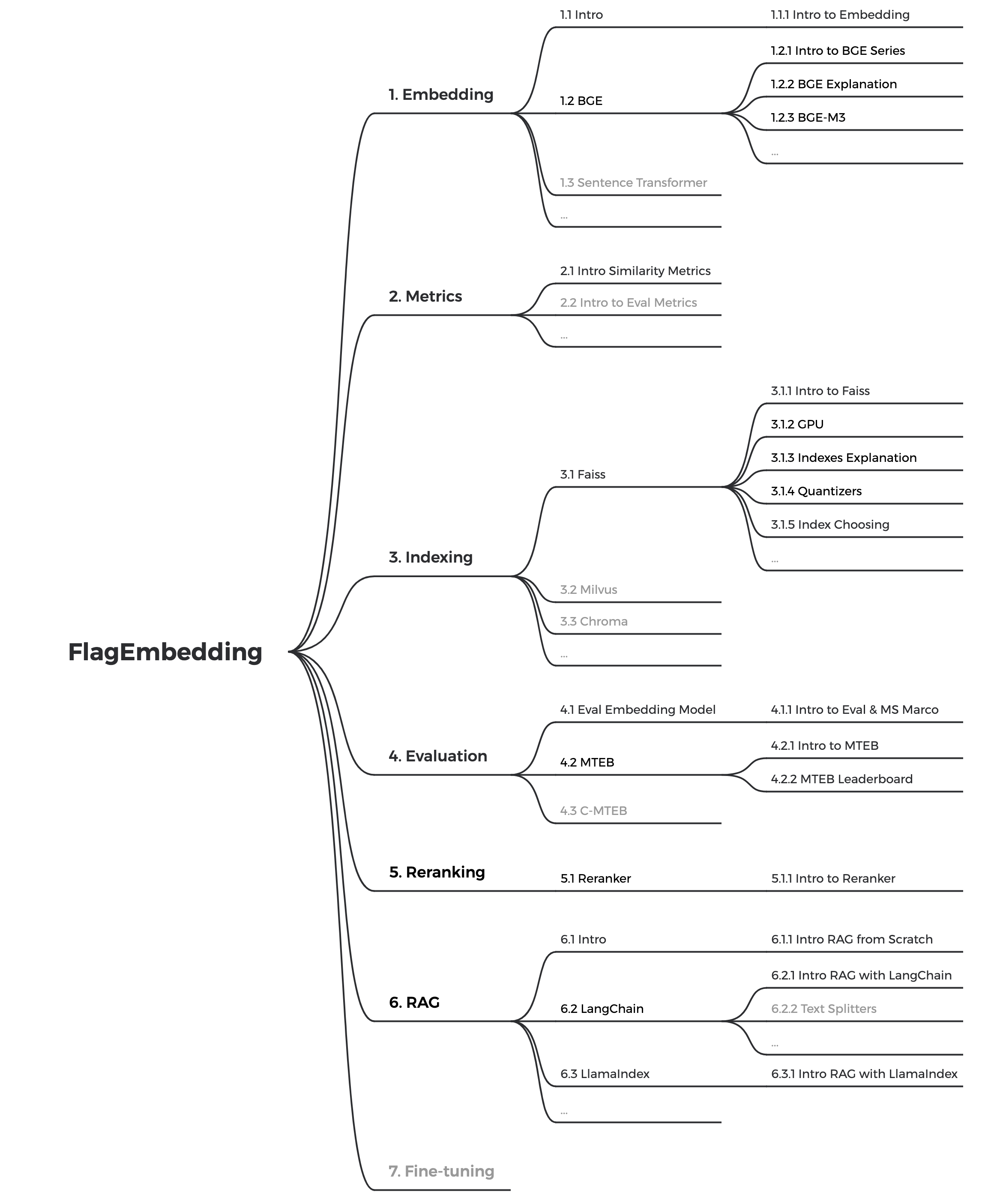
ขณะนี้เรากำลังอัปเดตบทช่วยสอน เรามุ่งมั่นที่จะสร้างบทช่วยสอนที่ครอบคลุมและมีรายละเอียดสำหรับผู้เริ่มต้นในการดึงข้อความและ RAG คอยติดตาม!
เนื้อหาต่อไปนี้จะเปิดตัวในอีกไม่กี่สัปดาห์ข้างหน้า:
bge ย่อมาจาก BAAI general embedding
| แบบอย่าง | ภาษา | คำอธิบาย | คำแนะนำในการสืบค้นสำหรับการดึงข้อมูล |
|---|---|---|---|
| BAAI/bge-en-icl | ภาษาอังกฤษ | โมเดลการฝังที่ใช้ LLM พร้อมความสามารถในการเรียนรู้ในบริบท ซึ่งสามารถใช้ประโยชน์จากศักยภาพของโมเดลได้อย่างเต็มที่โดยอิงจากตัวอย่างช็อตบางส่วน | ให้คำแนะนำและตัวอย่างสั้นๆ ตามงานที่กำหนดได้อย่างอิสระ |
| BAAI/bge-หลายภาษา-gemma2 | พูดได้หลายภาษา | โมเดลการฝังหลายภาษาที่ใช้ LLM ซึ่งได้รับการฝึกฝนในภาษาและงานที่หลากหลาย | ให้คำแนะนำตามงานที่ได้รับมอบหมาย |
| บัว/บีจี-m3 | พูดได้หลายภาษา | มัลติฟังก์ชั่น (การดึงข้อมูลหนาแน่น การดึงข้อมูลแบบเบาบาง เวกเตอร์หลายตัว (โคลแบร์)) หลายภาษา และหลายรายละเอียด (โทเค็น 8192) | |
| LM-ค็อกเทล | ภาษาอังกฤษ | โมเดลที่ได้รับการปรับแต่งอย่างละเอียด (Llama และ BGE) ซึ่งสามารถใช้เพื่อสร้างผลลัพธ์ของ LM-Cocktail | |
| BAAI/llm-ตัวฝัง | ภาษาอังกฤษ | โมเดลการฝังแบบครบวงจรเพื่อรองรับความต้องการเพิ่มการดึงข้อมูลที่หลากหลายสำหรับ LLM | ดูอ่านมี |
| BAAI/bge-reranker-v2-m3 | พูดได้หลายภาษา | รุ่น cross-encoder น้ำหนักเบา มีความสามารถหลายภาษาที่แข็งแกร่ง ปรับใช้ง่าย พร้อมการอนุมานที่รวดเร็ว | |
| BAAI/bge-reranker-v2-เจมม่า | พูดได้หลายภาษา | โมเดลตัวเข้ารหัสข้ามซึ่งเหมาะสำหรับบริบทหลายภาษา ทำงานได้ดีทั้งในด้านความสามารถทางภาษาอังกฤษและความสามารถหลายภาษา | |
| BAAI/bge-reranker-v2-minicpm-แบบเลเยอร์ | พูดได้หลายภาษา | โมเดลตัวเข้ารหัสข้ามซึ่งเหมาะสำหรับบริบทหลายภาษา ทำงานได้ดีทั้งในด้านภาษาอังกฤษและภาษาจีน ช่วยให้มีอิสระในการเลือกเลเยอร์สำหรับเอาต์พุต อำนวยความสะดวกในการอนุมานแบบเร่ง | |
| BAAI/bge-reranker-v2.5-gemma2-น้ำหนักเบา | พูดได้หลายภาษา | โมเดลตัวเข้ารหัสข้ามซึ่งเหมาะสำหรับบริบทหลายภาษา ทำงานได้ดีทั้งในด้านภาษาอังกฤษและภาษาจีน ช่วยให้มีอิสระในการเลือกเลเยอร์ อัตราส่วนการบีบอัด และเลเยอร์การบีบอัดสำหรับเอาต์พุต อำนวยความสะดวกในการอนุมานแบบเร่ง | |
| BAAI/bge-reranker-ขนาดใหญ่ | จีนและอังกฤษ | โมเดลตัวเข้ารหัสข้ามซึ่งมีความแม่นยำมากกว่าแต่มีประสิทธิภาพน้อยกว่า | |
| BAAI/bge-reranker-base | จีนและอังกฤษ | โมเดลตัวเข้ารหัสข้ามซึ่งมีความแม่นยำมากกว่าแต่มีประสิทธิภาพน้อยกว่า | |
| BAAI/bge-ขนาดใหญ่-en-v1.5 | ภาษาอังกฤษ | เวอร์ชัน 1.5 พร้อมการกระจายความคล้ายคลึงที่สมเหตุสมผลมากกว่า | Represent this sentence for searching relevant passages: |
| BAAI/bge-base-en-v1.5 | ภาษาอังกฤษ | เวอร์ชัน 1.5 พร้อมการกระจายความคล้ายคลึงที่สมเหตุสมผลมากกว่า | Represent this sentence for searching relevant passages: |
| BAAI/bge-ขนาดเล็ก-en-v1.5 | ภาษาอังกฤษ | เวอร์ชัน 1.5 พร้อมการกระจายความคล้ายคลึงที่สมเหตุสมผลมากกว่า | Represent this sentence for searching relevant passages: |
| BAAI/bge-ขนาดใหญ่-zh-v1.5 | ชาวจีน | เวอร์ชัน 1.5 พร้อมการกระจายความคล้ายคลึงที่สมเหตุสมผลมากกว่า | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-ฐาน-zh-v1.5 | ชาวจีน | เวอร์ชัน 1.5 พร้อมการกระจายความคล้ายคลึงที่สมเหตุสมผลมากกว่า | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-ขนาดเล็ก-zh-v1.5 | ชาวจีน | เวอร์ชัน 1.5 พร้อมการกระจายความคล้ายคลึงที่สมเหตุสมผลมากกว่า | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-large-en | ภาษาอังกฤษ | การฝังโมเดลซึ่งจับคู่ข้อความเป็นเวกเตอร์ | Represent this sentence for searching relevant passages: |
| BAAI/bge-base-en | ภาษาอังกฤษ | แบบจำลองขนาดฐานแต่มีความสามารถคล้ายคลึงกับ bge-large-en | Represent this sentence for searching relevant passages: |
| BAAI/bge-small-en | ภาษาอังกฤษ | โมเดลขนาดเล็กแต่มีประสิทธิภาพการแข่งขัน | Represent this sentence for searching relevant passages: |
| BAAI/bge-ขนาดใหญ่-zh | ชาวจีน | การฝังโมเดลซึ่งจับคู่ข้อความเป็นเวกเตอร์ | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-ฐาน-zh | ชาวจีน | แบบจำลองขนาดฐาน แต่มีความสามารถคล้ายคลึงกับ bge-large-zh | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-ขนาดเล็ก-zh | ชาวจีน | โมเดลขนาดเล็กแต่มีประสิทธิภาพการแข่งขัน | 为这个句子生成表示以用于检索相关文章: |
ขอขอบคุณผู้มีส่วนร่วมของเราทุกคนสำหรับความพยายามและยินดีต้อนรับสมาชิกใหม่อย่างอบอุ่นที่จะเข้าร่วม!
หากคุณพบว่าพื้นที่เก็บข้อมูลนี้มีประโยชน์ โปรดให้ดาวและการอ้างอิง
@misc{bge_m3,
title={BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation},
author={Chen, Jianlv and Xiao, Shitao and Zhang, Peitian and Luo, Kun and Lian, Defu and Liu, Zheng},
year={2023},
eprint={2309.07597},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{cocktail,
title={LM-Cocktail: Resilient Tuning of Language Models via Model Merging},
author={Shitao Xiao and Zheng Liu and Peitian Zhang and Xingrun Xing},
year={2023},
eprint={2311.13534},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{llm_embedder,
title={Retrieve Anything To Augment Large Language Models},
author={Peitian Zhang and Shitao Xiao and Zheng Liu and Zhicheng Dou and Jian-Yun Nie},
year={2023},
eprint={2310.07554},
archivePrefix={arXiv},
primaryClass={cs.IR}
}
@misc{bge_embedding,
title={C-Pack: Packaged Resources To Advance General Chinese Embedding},
author={Shitao Xiao and Zheng Liu and Peitian Zhang and Niklas Muennighoff},
year={2023},
eprint={2309.07597},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
FlagEmbedding ได้รับอนุญาตภายใต้ใบอนุญาต MIT


