ระบบการจัดการเมโทร
โครงการหลักสูตร CS307 - Principles of Database System ที่นำโดย Yuxin MA
Shenzhen-Metro
├── Project1 # part 1 of project (database design and data import)
│ ├── ShenzhenMetroDatabaseDesign
│ │ ├── src
│ │ │ ├── main
│ │ │ │ ├── java # import script in java
│ │ │ │ ├── resources # data in json
│ │ │ │ └── sql # ddl
│ └── ShenzhenMetroDatabaseDesignPython
│ ├── import_script.py # import script in python
│ └── resources # data in json
├── Project2 # part 2 of project (building an api)
│ ├── DataImport # updated data import
│ │ ├── src
│ │ │ ├── main
│ │ │ │ ├── java # updated import script in java
│ │ │ │ ├── resources # updated data
│ │ │ │ └── sql # updated ddl
│ └── ShenzhenMetro # spring boot project
│ ├── src
│ │ ├── main
│ │ │ ├── java # backend logic
│ │ │ │ └── com/sustech/cs307/project2/shenzhenmetro
│ │ │ │ ├── ShenzhenMetroApplication.java # main application driver
│ │ │ │ ├── controller # api route mapping
│ │ │ │ ├── dto # dto between client and server
│ │ │ │ ├── object # orm between database tables and application code
│ │ │ │ ├── repository # interfaces for data access
│ │ │ │ └── service # service layer containing business logic
│ │ │ └── resources # frontend logic
│ │ │ ├── application.properties # configuration file for spring boot application
│ │ │ ├── static
│ │ │ │ ├── assets
│ │ │ │ │ ├── css
│ │ │ │ │ ├── img
│ │ │ │ │ ├── js
│ │ │ │ │ └── vendor
│ │ │ │ │ ├── aos
│ │ │ │ │ ├── bootstrap
│ │ │ │ │ ├── bootstrap-icons
│ │ │ │ │ ├── glightbox
│ │ │ │ │ └── swiper
│ │ │ │ └── index.html # main html
│ │ │ └── templates
│ │ │ ├── buses
│ │ │ │ ├── create_bus.html
│ │ │ │ ├── index.html
│ │ │ │ └── update_bus.html
│ │ │ ├── landmarks
│ │ │ │ ├── create_landmark.html
│ │ │ │ ├── index.html
│ │ │ │ └── update_landmark.html
│ │ │ ├── lineDetails
│ │ │ │ ├── create_line_detail.html
│ │ │ │ ├── index.html
│ │ │ │ ├── navigate_routes.html
│ │ │ │ └── search_line_detail.html
│ │ │ ├── lines
│ │ │ │ ├── create_line.html
│ │ │ │ ├── index.html
│ │ │ │ └── update_line.html
│ │ │ ├── ongoingRides
│ │ │ │ └── index.html
│ │ │ ├── rides
│ │ │ │ ├── create_ride.html
│ │ │ │ ├── filter_ride.html
│ │ │ │ ├── index.html
│ │ │ │ └── update_ride.html
│ │ │ ├── stations
│ │ │ │ ├── create_station.html
│ │ │ │ ├── index.html
│ │ │ │ └── update_station.html
│ │ │ └── users
│ │ │ ├── card.html
│ │ │ └── passenger.html
└── README.md
ส่วนแรกของโครงการส่วนใหญ่เกี่ยวกับการออกแบบสคีมาฐานข้อมูลที่ตอบสนองหลักการของฐานข้อมูลเชิงสัมพันธ์โดยอิงตามพื้นหลังของข้อมูลที่ให้มา เมื่อขั้นตอนการออกแบบเสร็จสมบูรณ์ เราจะเขียนสคริปต์เพื่อนำเข้าชุดข้อมูลขนาดใหญ่เหล่านั้น เพื่อรับรองความถูกต้องของข้อมูลที่นำเข้า เราจึงต้องดำเนินการคำสั่งสืบค้นและตรวจสอบผลลัพธ์การสืบค้นในวันที่ป้องกัน นอกจากนี้เรายังทำการทดลองกับข้อมูลเพื่อให้ได้ข้อมูลเชิงลึกที่ยอดเยี่ยม ดังที่แสดงในภายหลัง
[อ่านข้อกำหนดโดยละเอียด]
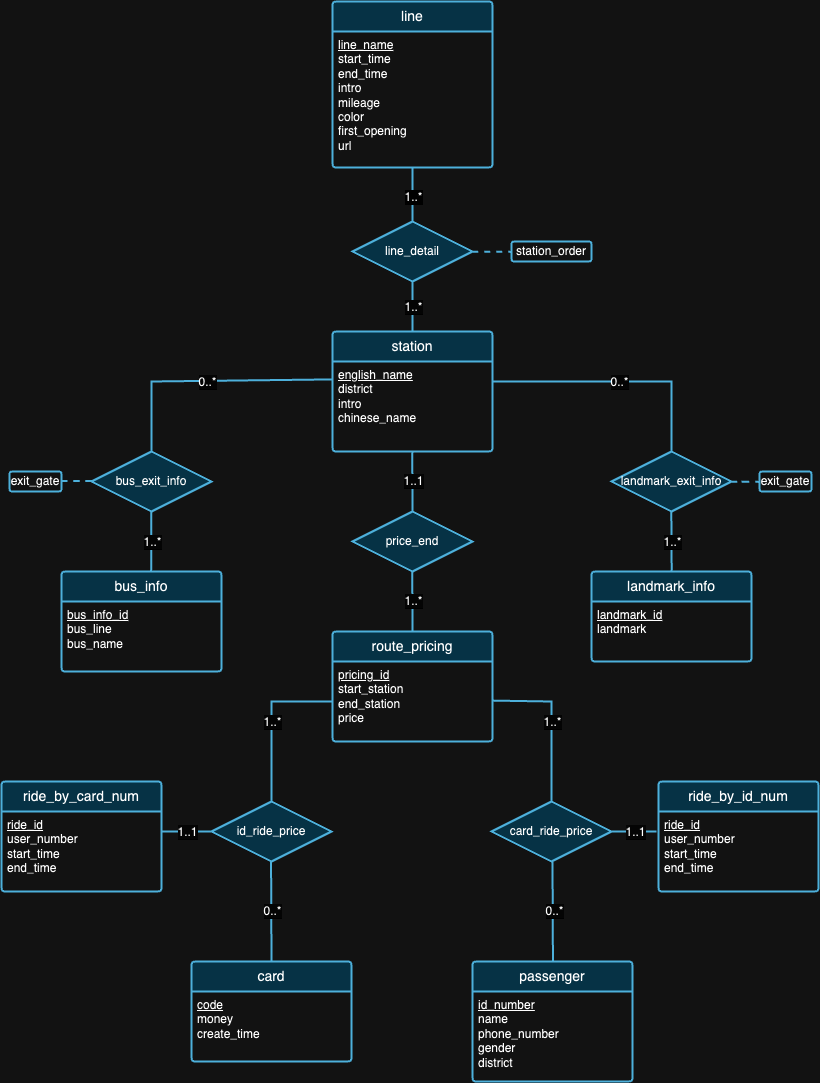
เราเชื่อว่าไม่มีการออกแบบฐานข้อมูลที่สมบูรณ์แบบ ในความเป็นจริง มีข้อบกพร่องกับการออกแบบที่เราเสนอในแผนภาพ ER ด้านบน หลังจากดูชุดข้อมูลและพื้นหลังของแต่ละชุดข้อมูลแล้ว เราหวังว่าคุณจะลองสังเกตข้อบกพร่องด้านการออกแบบได้ด้วยตัวเอง -
หมายเหตุ : สำหรับการตีความรูป
| บัตรประจำตัวประชาชน | ระบบปฏิบัติการ | ชิป | หน่วยความจำ | เอสเอสดี | เครื่องมือ |
|---|---|---|---|---|---|
| 1 | macOS โซโนมา 14.4.1 | แอปเปิ้ล M3 โปร | 18GB | 1TB | IDEA 2024.1 (CE), PyCharm 2023.3.4 (CE), แถบข้อมูล 2024.1 |
| 2 | วินโดวส์ 11 โฮม 23H2 | Intel(R) Core(TM) เจนเนอเรชั่น 12 i9-12900H | 32GB | 1TB | IDEA 2024.1 (CE), ดาต้ากริป 2024.1 |
| 3 | อูบุนตู 22.04.4 (VM) | แอปเปิ้ล M1 โปร | 16GB | 512GB | IDEA 2024.1 (CE), ดาต้ากริป 2024.1 |
Experiment 1: Different Import Methods วิธีที่ 1 (สคริปต์ต้นฉบับ): วิธีนี้ใช้ไลบรารี java.sql ประการแรก เราสร้างการเชื่อมต่อกับเซิร์ฟเวอร์ PostgreSQL ของเรา จากนั้นเราจะอ่านข้อมูลทั้งหมดจากไฟล์ JSON ต่อไป เราวนซ้ำแต่ละ datum และสร้าง PreparedStatement สำหรับแต่ละคำสั่ง insert สุดท้ายนี้ เราเรียกเมธอด executeUpdate() เพื่อดำเนินการแต่ละคำสั่งแยกกัน
วิธีที่ 2 (สคริปต์ที่ปรับให้เหมาะสม): วิธีนี้ยังใช้ไลบรารี java.sql และใช้อัลกอริธึมการอ่านข้อมูลเดียวกันกับวิธีที่ 1 ความแตกต่างคือตอนนี้เราใช้วิธี executeBatch() ดังนั้นเราจึงวนซ้ำข้อมูลทั้งหมด สร้างคำสั่ง insert แต่ละคำสั่งด้วย PreparedStatement และเพิ่ม PreparedStatement แต่ละรายการลงในแบตช์สำหรับการประมวลผลแบบแบตช์
วิธีที่ 3 (เรียกใช้ไฟล์ .sql): เราใช้โปรแกรม Java เพื่อสร้างคำสั่งแทรก SQL และเขียนลงในไฟล์ .sql โดยใช้อัลกอริธึมการอ่านข้อมูลเดียวกันกับที่กล่าวไว้ข้างต้น จากนั้นเราเรียกใช้ไฟล์ใน DataGrip
เนื่องจากเราใช้อัลกอริธึมการอ่านข้อมูลเดียวกันในทั้งสามวิธี เราจะใช้รันไทม์เฉลี่ยสำหรับการทดสอบครั้งต่อไป ในตอนแรก เรารวบรวมรันไทม์ที่แตกต่างกันสามแบบ — 504 ms, 546 ms และ 552 ms — และคำนวณรันไทม์เฉลี่ยที่ 534 ms
| สภาพแวดล้อมการทดสอบ | วิธี | เวลาอ่านเฉลี่ย (มิลลิวินาที) | เวลาในการเขียน (มิลลิวินาที) | เวลาทั้งหมด (มิลลิวินาที) | ปริมาณงาน (คำสั่ง/วินาที) |
|---|---|---|---|---|---|
| 1 | 1 | 534 | 206396 | 206930 | 8636.91 |
| 1 | 2 | 534 | 2114 | 2648 | 97632.92 |
| 1 | 3 | 534 | 13581 | 14115 | 15197.41 |
ตารางที่ 2 แสดงการวัดประสิทธิภาพที่แตกต่างกันในวิธีการต่างๆ โดยวิธีที่ 2 แสดงปริมาณงานสูงสุด และวิธีที่ 1 มีเวลารวมที่ช้าที่สุด ซึ่งทำให้วิธีที่ 2 เป็นวิธีการทดสอบมาตรฐานในการทดลองที่กำลังจะมีขึ้น
Experiment 2: Data Import with Different Data Volumesการจัดการและการนำเข้าข้อมูลในปริมาณที่แตกต่างกันเป็นสิ่งสำคัญในการรับรองประสิทธิภาพ ความสามารถในการปรับขนาด และความน่าเชื่อถือของระบบฐานข้อมูล
ก่อนกระบวนการนำเข้า เราสังเกตเห็นว่าข้อมูล "การขับขี่" มีปริมาณมากกว่าอย่างเห็นได้ชัดเมื่อเทียบกับข้อมูลอื่นๆ จากแนวคิดนี้ เราจึงตัดสินใจทดสอบการนำเข้าข้อมูลด้วยปริมาณที่แตกต่างกันบน ride.json เท่านั้น เนื่องจากน้ำหนักของข้อมูลไม่สอดคล้องกัน การนำเข้าปริมาณน้อยลงสำหรับตารางอื่นๆ อาจส่งผลให้เกิดปัญหาร้ายแรงเนื่องจากการเชื่อมต่อระหว่างตาราง
ในตอนแรก เราเริ่มต้นด้วยการนำเข้าข้อมูลทั้งหมด (ปริมาณ 100%) สำหรับตารางอื่นๆ ทั้งหมด ยกเว้นตาราง rides_by_id_num และ rides_by_card_num เพื่อให้มั่นใจว่าการออกแบบของเรามีความสอดคล้องกัน เพื่อจัดการสิ่งนี้อย่างมีประสิทธิภาพ เราได้ใช้กลยุทธ์การนำเข้าแบบเป็นช่วงสำหรับข้อมูล ride โดยเริ่มจากชุดย่อย 20% ของข้อมูล ซึ่งเท่ากับ 20,000 บันทึก ระยะเริ่มต้นนี้ช่วยให้เราสามารถประเมินผลกระทบต่อประสิทธิภาพของระบบและทำการปรับเปลี่ยนที่จำเป็นต่อกระบวนการนำเข้าโดยไม่กระทบต่อเสถียรภาพของฐานข้อมูล หลังจากการตรวจสอบและปรับแต่งประสิทธิภาพสำเร็จแล้ว เราก็ดำเนินการนำเข้าข้อมูล 50% และสุดท้ายคือส่วนที่เหลือเพื่อนำเข้าข้อมูลให้เสร็จสมบูรณ์ 100% โปรดทราบว่าเราใช้วิธีที่ 2 สำหรับการนำเข้าทั้งหมดเนื่องจากเป็นวิธีที่เร็วที่สุด
| สภาพแวดล้อมการทดสอบ | วิธี | ปริมาณ | เวลาในการอ่าน (มิลลิวินาที) | เวลาในการเขียน (มิลลิวินาที) | เวลาทั้งหมด (มิลลิวินาที) | จำนวนใบแจ้งยอด | ปริมาณงาน (คำสั่ง/วินาที) |
|---|---|---|---|---|---|---|---|
| 1 | 2 | 20% | 507 | 808 | 1315 | 80165 | 99214.11 |
| 1 | 2 | 50% | 521 | 1338 | พ.ศ. 2402 | 130849 | 97794.47 |
| 1 | 2 | 100% | 534 | 2114 | 2648 | 203502 | 96263.95 |
จากตารางที่ 3 เมื่อปริมาณข้อมูลเพิ่มขึ้น (จาก 20% เป็น 50% และเป็น 100%) ทั้งเวลาในการอ่านและเขียนมีแนวโน้มที่จะเพิ่มขึ้น ส่งผลให้เวลารวมในการดำเนินการนานขึ้น อย่างไรก็ตาม ตัวเลขเหล่านี้ไม่ได้ให้ความหมายเชิงลึกใดๆ เนื่องจากเรามีปริมาณการนำเข้าที่แตกต่างกัน หากเราดูที่จำนวนทรูพุตแทน ทรูพุต (คำสั่ง/วินาที) จะค่อยๆ ลดลงตามปริมาณข้อมูลที่เพิ่มขึ้น ซึ่งบ่งชี้ว่าระบบจะมีประสิทธิภาพน้อยลงในการประมวลผลคำสั่งเมื่อเวิร์กโหลดเพิ่มขึ้น
Experiment 3: Data Import on Different Operating Systemsในการทดสอบกระบวนการนำเข้าข้อมูลบนระบบปฏิบัติการที่แตกต่างกัน เราใช้วิธีการนำเข้าที่เร็วที่สุด ซึ่งก็คือวิธีที่ 2 โดยมีปริมาณการนำเข้า 100%
โปรดทราบว่าเมื่อรันสคริปต์นำเข้า Java บน Linux ผ่านเครื่องเสมือน จำเป็นต้องคำนึงถึงข้อเสียที่ไม่ยุติธรรมในด้านประสิทธิภาพและการจัดสรรทรัพยากร เนื่องจากการจำลองเสมือนอาจทำให้เกิดโอเวอร์เฮดและส่งผลต่อประสิทธิภาพของระบบ
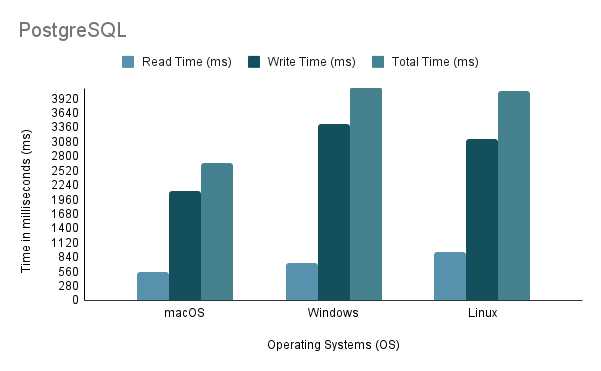
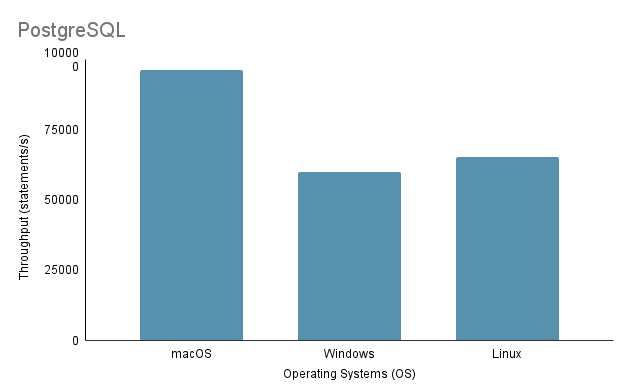
จากการวิเคราะห์ข้างต้น เป็นที่ชัดเจนว่าสภาพแวดล้อม 1 (macOS) แสดงประสิทธิภาพที่ดีที่สุดด้วยเวลารวมที่สั้นที่สุดที่ 2648 ms และปริมาณงานสูงสุดที่ 97,632.92 คำสั่ง/วินาที ในทางตรงกันข้าม สภาพแวดล้อม 2 (Windows) จะช้าที่สุดด้วยเวลารวม 4117 มิลลิวินาที และปริมาณการประมวลผลต่ำสุดที่ 60,669.02 คำสั่ง/วินาที เป็นที่น่าสังเกตว่า Linux Ubuntu ในขณะที่ทำงานเป็น VM ยังคงมีประสิทธิภาพเหนือกว่า Windows แบบ Bare-Metal
Experiment 4: Data Import with Various Programming Languagesในการทดลองนี้ เราใช้วิธีที่ 2 ที่กล่าวถึงข้างต้นสำหรับโค้ด Java เนื่องจากเป็นวิธีที่เร็วที่สุด ในขณะเดียวกัน สำหรับ Python เราได้เขียนวิธีการนำเข้าที่ใช้ Psycopg2 เพื่อสื่อสารกับเซิร์ฟเวอร์ฐานข้อมูล PostgreSQL
| สภาพแวดล้อมการทดสอบ | ภาษาโปรแกรม | เวลาในการอ่าน (มิลลิวินาที) | เวลาในการเขียน (มิลลิวินาที) | เวลาทั้งหมด (มิลลิวินาที) | ปริมาณงาน (คำสั่ง/วินาที) |
|---|---|---|---|---|---|
| 1 | ชวา | 534 | 2114 | 2648 | 96263.95 |
| 1 | หลาม | 390 | 7237 | 7627 | 28119.66 |
ข้อมูลจากตารางที่ 4 แสดงให้เห็นว่า Java มีประสิทธิภาพเหนือกว่า Python ทั้งในด้านความเร็วและปริมาณงาน ซึ่งบ่งชี้ถึงประสิทธิภาพที่เหนือกว่าสำหรับการดำเนินการอ่าน-เขียน
Experiment 5: Data Import on Different Databasesเราได้พัฒนาวิธีการนำเข้าที่แตกต่างกันสามวิธีสำหรับทั้ง PostgreSQL และ MySQL แต่เราทำการทดลองเฉพาะวิธีที่ 2 เท่านั้น เนื่องจากเป็นทางเลือกของนักพัฒนาในการนำเข้าข้อมูล ทั้ง PostgreSQL และ MySQL มีการออกแบบการใช้งานฐานข้อมูลที่คล้ายกัน (DDL wise) และการออกแบบรหัสนำเข้าที่คล้ายกัน
| สภาพแวดล้อมการทดสอบ | วิธี | ฐานข้อมูล | เวลาในการอ่าน (มิลลิวินาที) | เวลาในการเขียน (มิลลิวินาที) | เวลาทั้งหมด (มิลลิวินาที) | ปริมาณงาน (คำสั่ง/วินาที) |
|---|---|---|---|---|---|---|
| 1 | 2 | PostgreSQL | 534 | 2114 | 2648 | 96263.95 |
| 1 | 2 | MySQL | 534 | 42315 | 42849 | 4809.22 |
แม้ว่าทั้งสองจะเป็นฐานข้อมูลบน SQL แต่ PostgreSQL ก็ยังเร็วกว่าประมาณ 16 เท่าเมื่อพูดถึงเวลาในการเขียน อาจเนื่องมาจากความแตกต่างในสถาปัตยกรรมกลไกฐานข้อมูลและการใช้งานไดรเวอร์ ( postgresql-42.2.5.jar สำหรับ PostgreSQL และ mysql-connector-j-8.3.0.jar สำหรับ MySQL)
ส่วนที่ 2 ของโครงการมุ่งเน้นไปที่การจัดหาฟังก์ชันพื้นฐานในการเข้าถึงระบบฐานข้อมูลโดยการสร้างไลบรารีแบ็กเอนด์ซึ่งเปิดเผยชุดของ Application Programming Interfaces (API) โปรดทราบว่าจำเป็นต้องมีชุดข้อมูลเพิ่มเติมที่จะนำเข้าด้วย ดังนั้นจึงต้องมีการใช้งานฐานข้อมูลที่อัปเดต (ดูได้ใน ./Project2/DataImport )
[อ่านข้อกำหนดโดยละเอียด]
./Project2/DataImport/src/main/sql/ddl.sql./Project2/DataImport/src/main/java/ImportScript.java./Project2/ShenzhenMetro ) ด้วย Maven (แนะนำให้ใช้ IntelliJ IDEA IDE)

