shap
v0.46.0
SHAP (คำอธิบายเพิ่มเติมของ SHapley) เป็นแนวทางทางทฤษฎีเกมที่ใช้อธิบายผลลัพธ์ของโมเดลการเรียนรู้ของเครื่อง โดยเชื่อมโยงการจัดสรรเครดิตที่เหมาะสมกับคำอธิบายในท้องถิ่นโดยใช้ค่า Shapley แบบคลาสสิกจากทฤษฎีเกมและส่วนขยายที่เกี่ยวข้อง (ดูเอกสารสำหรับรายละเอียดและการอ้างอิง)
SHAP สามารถติดตั้งได้จาก PyPI หรือ conda-forge:
pip ติดตั้ง shap หรือ conda ติดตั้ง -c conda-forge shap
แม้ว่า SHAP จะสามารถอธิบายผลลัพธ์ของโมเดลการเรียนรู้ของเครื่องใดๆ ได้ แต่เราก็ได้พัฒนาอัลกอริธึมที่แม่นยำความเร็วสูงสำหรับวิธีการประกอบต้นไม้ (ดูเอกสาร Nature MI ของเรา) การใช้งาน C++ ที่รวดเร็วได้รับการสนับสนุนสำหรับโมเดลต้นไม้ XGBoost , LightGBM , CatBoost , scikit-learn และ pyspark :
import xgboost
import shap
# train an XGBoost model
X , y = shap . datasets . california ()
model = xgboost . XGBRegressor (). fit ( X , y )
# explain the model's predictions using SHAP
# (same syntax works for LightGBM, CatBoost, scikit-learn, transformers, Spark, etc.)
explainer = shap . Explainer ( model )
shap_values = explainer ( X )
# visualize the first prediction's explanation
shap . plots . waterfall ( shap_values [ 0 ])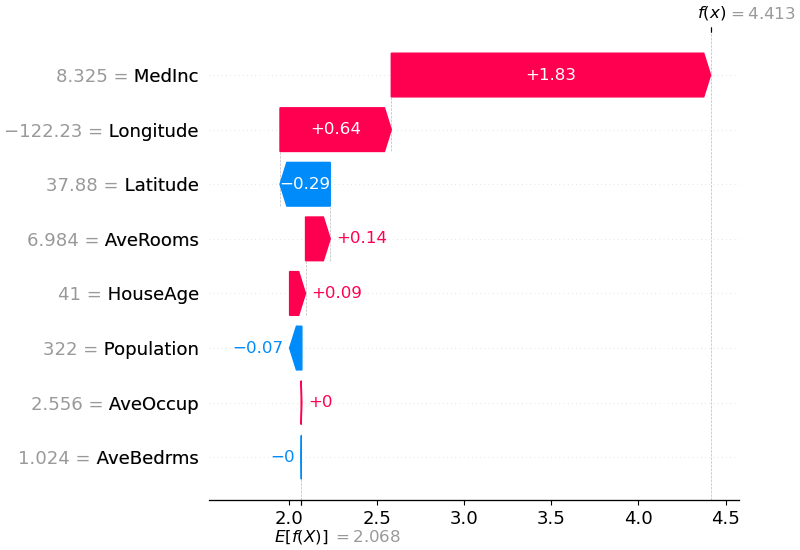
คำอธิบายข้างต้นแสดงคุณลักษณะต่างๆ ที่แต่ละส่วนมีส่วนในการผลักเอาท์พุตของโมเดลจากค่าฐาน (เอาท์พุตของโมเดลโดยเฉลี่ยเหนือชุดข้อมูลการฝึกที่เราส่งผ่าน) ไปยังเอาท์พุตของโมเดล คุณลักษณะที่ผลักดันการทำนายให้สูงขึ้นจะแสดงเป็นสีแดง ส่วนฟีเจอร์ที่ผลักดันการทำนายให้ต่ำลงจะแสดงเป็นสีน้ำเงิน อีกวิธีหนึ่งในการแสดงภาพคำอธิบายเดียวกันคือการใช้แผนภาพบังคับ (ซึ่งแนะนำไว้ในรายงาน Nature BME ของเรา):
# visualize the first prediction's explanation with a force plot
shap . plots . force ( shap_values [ 0 ])
หากเราใช้คำอธิบายของ Force Plot หลายๆ อย่างดังที่แสดงไว้ด้านบน หมุนมัน 90 องศา แล้วซ้อนมันในแนวนอน เราจะเห็นคำอธิบายสำหรับชุดข้อมูลทั้งหมด (ในสมุดบันทึก พล็อตนี้เป็นแบบโต้ตอบได้):
# visualize all the training set predictions
shap . plots . force ( shap_values [: 500 ])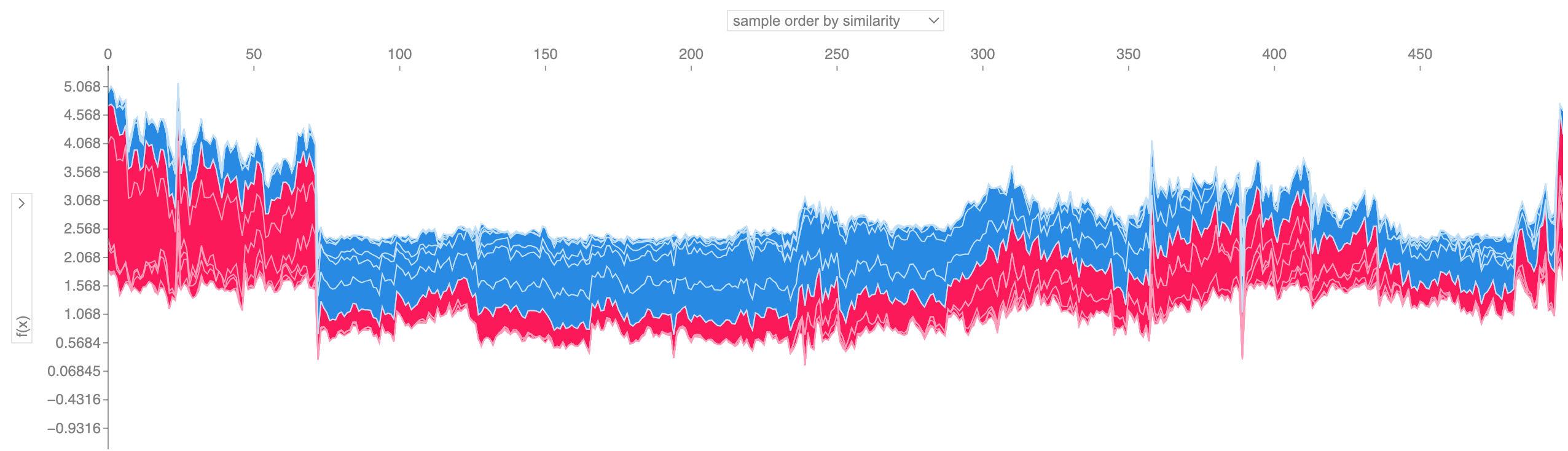
เพื่อทำความเข้าใจว่าฟีเจอร์เดียวส่งผลต่อเอาท์พุตของโมเดลอย่างไร เราสามารถพล็อตค่า SHAP ของฟีเจอร์นั้นเทียบกับค่าของฟีเจอร์สำหรับตัวอย่างทั้งหมดในชุดข้อมูลได้ เนื่องจากค่า SHAP แสดงถึงความรับผิดชอบของคุณลักษณะต่อการเปลี่ยนแปลงในเอาต์พุตของแบบจำลอง โครงด้านล่างจึงแสดงถึงการเปลี่ยนแปลงของราคาบ้านที่คาดการณ์เมื่อละติจูดเปลี่ยนแปลง การกระจายตัวในแนวตั้งที่ค่าละติจูดเดียวแสดงถึงเอฟเฟกต์การโต้ตอบกับคุณลักษณะอื่นๆ เพื่อช่วยเปิดเผยการโต้ตอบเหล่านี้ เราสามารถระบายสีตามคุณสมบัติอื่นได้ หากเราส่งเทนเซอร์คำอธิบายทั้งหมดไปยังอาร์กิวเมนต์ color แผนภาพกระจายจะเลือกคุณลักษณะที่ดีที่สุดในการใช้สี ในกรณีนี้จะเลือกลองจิจูด
# create a dependence scatter plot to show the effect of a single feature across the whole dataset
shap . plots . scatter ( shap_values [:, "Latitude" ], color = shap_values )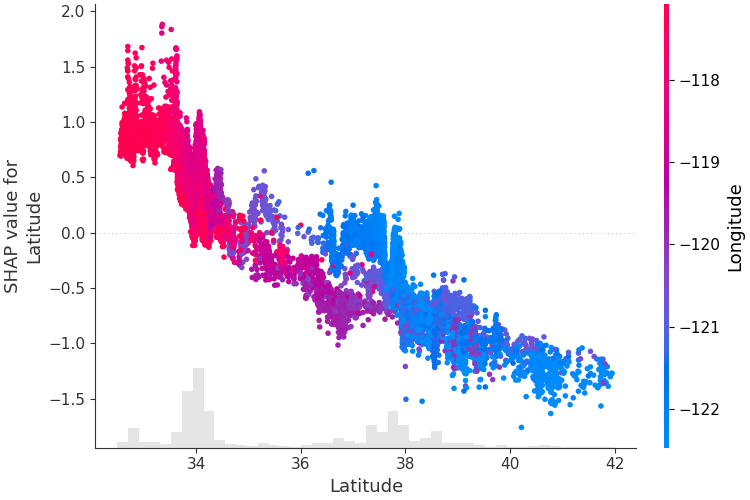
เพื่อให้ได้ภาพรวมว่าคุณลักษณะใดที่สำคัญที่สุดสำหรับแบบจำลอง เราสามารถพล็อตค่า SHAP ของทุกคุณลักษณะสำหรับทุกตัวอย่างได้ โครงเรื่องด้านล่างจัดเรียงคุณลักษณะต่างๆ เป็นผลรวมของขนาดค่า SHAP จากตัวอย่างทั้งหมด และใช้ค่า SHAP เพื่อแสดงการกระจายผลกระทบที่แต่ละคุณลักษณะมีต่อเอาต์พุตของโมเดล สีแสดงถึงค่าคุณลักษณะ (สูงสีแดง ต่ำสีน้ำเงิน) สิ่งนี้เผยให้เห็นว่ารายได้เฉลี่ยที่สูงขึ้นจะช่วยปรับปรุงราคาบ้านที่คาดการณ์ไว้
# summarize the effects of all the features
shap . plots . beeswarm ( shap_values )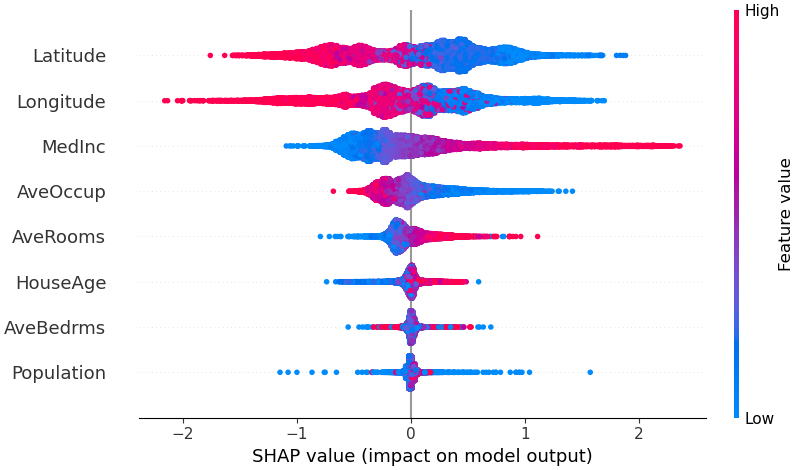
นอกจากนี้เรายังสามารถใช้ค่าเฉลี่ยสัมบูรณ์ของค่า SHAP สำหรับแต่ละคุณลักษณะเพื่อรับพล็อตแท่งมาตรฐาน (สร้างแท่งแบบเรียงซ้อนสำหรับเอาต์พุตหลายคลาส):
shap . plots . bar ( shap_values )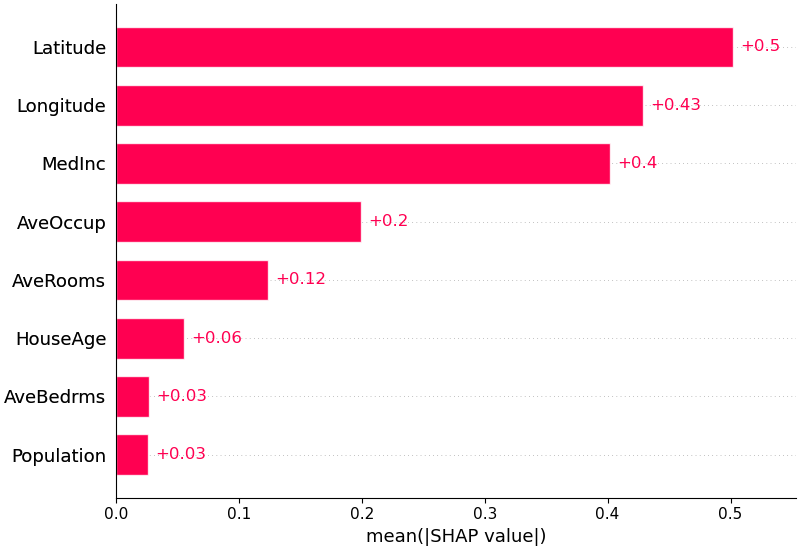
SHAP มีการรองรับโมเดลภาษาธรรมชาติโดยเฉพาะ เช่นเดียวกับในไลบรารีหม้อแปลง Hugging Face ด้วยการเพิ่มกฎแนวร่วมให้กับค่า Shapley แบบดั้งเดิม เราสามารถสร้างเกมที่อธิบายโมเดล NLP สมัยใหม่ขนาดใหญ่โดยใช้การประเมินฟังก์ชันเพียงเล็กน้อย การใช้ฟังก์ชันนี้ทำได้ง่ายเพียงแค่ส่งไปป์ไลน์หม้อแปลงที่รองรับไปยัง SHAP:
import transformers
import shap
# load a transformers pipeline model
model = transformers . pipeline ( 'sentiment-analysis' , return_all_scores = True )
# explain the model on two sample inputs
explainer = shap . Explainer ( model )
shap_values = explainer ([ "What a great movie! ...if you have no taste." ])
# visualize the first prediction's explanation for the POSITIVE output class
shap . plots . text ( shap_values [ 0 , :, "POSITIVE" ])Deep SHAP เป็นอัลกอริธึมการประมาณความเร็วสูงสำหรับค่า SHAP ในโมเดลการเรียนรู้เชิงลึกที่สร้างขึ้นจากการเชื่อมต่อกับ DeepLIFT ที่อธิบายไว้ในเอกสาร SHAP NIPS การใช้งานที่นี่แตกต่างจาก DeepLIFT ดั้งเดิมโดยใช้การกระจายตัวอย่างพื้นหลังแทนค่าอ้างอิงเดียว และใช้สมการ Shapley เพื่อทำให้ส่วนประกอบเป็นเส้นตรง เช่น max, softmax, ผลิตภัณฑ์, การแบ่ง ฯลฯ โปรดทราบว่าการปรับปรุงบางส่วนเหล่านี้ยังได้รับการปรับปรุงด้วย ตั้งแต่รวมเข้ากับ DeepLIFT รองรับโมเดล TensorFlow และโมเดล Keras ที่ใช้แบ็กเอนด์ TensorFlow (ยังมีการสนับสนุนเบื้องต้นสำหรับ PyTorch):
# ...include code from https://github.com/keras-team/keras/blob/master/examples/demo_mnist_convnet.py
import shap
import numpy as np
# select a set of background examples to take an expectation over
background = x_train [ np . random . choice ( x_train . shape [ 0 ], 100 , replace = False )]
# explain predictions of the model on four images
e = shap . DeepExplainer ( model , background )
# ...or pass tensors directly
# e = shap.DeepExplainer((model.layers[0].input, model.layers[-1].output), background)
shap_values = e . shap_values ( x_test [ 1 : 5 ])
# plot the feature attributions
shap . image_plot ( shap_values , - x_test [ 1 : 5 ])โครงเรื่องด้านบนอธิบายเอาต์พุต 10 รายการ (ตัวเลข 0-9) สำหรับรูปภาพสี่รูปที่แตกต่างกัน พิกเซลสีแดงจะเพิ่มเอาท์พุตของโมเดล ในขณะที่พิกเซลสีน้ำเงินจะลดเอาท์พุต รูปภาพอินพุตจะแสดงทางด้านซ้าย และมีพื้นหลังสีเทาเกือบโปร่งใสอยู่ด้านหลังคำอธิบายแต่ละรายการ ผลรวมของค่า SHAP เท่ากับความแตกต่างระหว่างเอาท์พุตโมเดลที่คาดหวัง (ค่าเฉลี่ยเหนือชุดข้อมูลพื้นหลัง) และเอาท์พุตโมเดลปัจจุบัน โปรดทราบว่าสำหรับรูปภาพ 'ศูนย์' ช่องตรงกลางที่ว่างเป็นสิ่งสำคัญ ในขณะที่รูปภาพ 'สี่' การขาดการเชื่อมต่อที่ด้านบนทำให้เป็นสี่แทนที่จะเป็นเก้า
การไล่ระดับสีที่คาดหวังจะรวมแนวคิดจากการไล่ระดับสีแบบรวม, SHAP และ SmoothGrad ไว้ในสมการค่าที่คาดหวังเพียงค่าเดียว ซึ่งช่วยให้ชุดข้อมูลทั้งหมดสามารถใช้เป็นการกระจายพื้นหลังได้ (ตรงข้ามกับค่าอ้างอิงเดียว) และช่วยให้การปรับเรียบในเครื่องได้ หากเราประมาณโมเดลด้วยฟังก์ชันเชิงเส้นระหว่างตัวอย่างข้อมูลพื้นหลังแต่ละรายการกับอินพุตปัจจุบันที่จะอธิบาย และเราถือว่าคุณลักษณะอินพุตนั้นมีความเป็นอิสระ การไล่ระดับสีที่คาดหวังจะคำนวณค่า SHAP โดยประมาณ ในตัวอย่างด้านล่าง เราได้อธิบายว่าเลเยอร์กลางที่ 7 ของโมเดล VGG16 ImageNet ส่งผลต่อความน่าจะเป็นของเอาต์พุตอย่างไร
from keras . applications . vgg16 import VGG16
from keras . applications . vgg16 import preprocess_input
import keras . backend as K
import numpy as np
import json
import shap
# load pre-trained model and choose two images to explain
model = VGG16 ( weights = 'imagenet' , include_top = True )
X , y = shap . datasets . imagenet50 ()
to_explain = X [[ 39 , 41 ]]
# load the ImageNet class names
url = "https://s3.amazonaws.com/deep-learning-models/image-models/imagenet_class_index.json"
fname = shap . datasets . cache ( url )
with open ( fname ) as f :
class_names = json . load ( f )
# explain how the input to the 7th layer of the model explains the top two classes
def map2layer ( x , layer ):
feed_dict = dict ( zip ([ model . layers [ 0 ]. input ], [ preprocess_input ( x . copy ())]))
return K . get_session (). run ( model . layers [ layer ]. input , feed_dict )
e = shap . GradientExplainer (
( model . layers [ 7 ]. input , model . layers [ - 1 ]. output ),
map2layer ( X , 7 ),
local_smoothing = 0 # std dev of smoothing noise
)
shap_values , indexes = e . shap_values ( map2layer ( to_explain , 7 ), ranked_outputs = 2 )
# get the names for the classes
index_names = np . vectorize ( lambda x : class_names [ str ( x )][ 1 ])( indexes )
# plot the explanations
shap . image_plot ( shap_values , to_explain , index_names ) การคาดการณ์สำหรับภาพที่ป้อนเข้าสองภาพมีการอธิบายไว้ในโครงเรื่องด้านบน พิกเซลสีแดงแสดงถึงค่า SHAP เชิงบวกที่เพิ่มความน่าจะเป็นของคลาส ในขณะที่พิกเซลสีน้ำเงินแสดงถึงค่า SHAP เชิงลบซึ่งจะลดความน่าจะเป็นของคลาส เมื่อใช้ ranked_outputs=2 เราจะอธิบายเฉพาะคลาสที่เป็นไปได้มากที่สุดสองคลาสสำหรับแต่ละอินพุต (ซึ่งทำให้เราไม่สามารถอธิบายคลาสทั้งหมด 1,000 คลาสได้)
Kernel SHAP ใช้การถดถอยเชิงเส้นเฉพาะที่ถ่วงน้ำหนักเป็นพิเศษเพื่อประมาณค่า SHAP สำหรับโมเดลใดๆ ด้านล่างนี้คือตัวอย่างง่ายๆ สำหรับการอธิบาย SVM แบบหลายคลาสบนชุดข้อมูลม่านตาแบบคลาสสิก
import sklearn
import shap
from sklearn . model_selection import train_test_split
# print the JS visualization code to the notebook
shap . initjs ()
# train a SVM classifier
X_train , X_test , Y_train , Y_test = train_test_split ( * shap . datasets . iris (), test_size = 0.2 , random_state = 0 )
svm = sklearn . svm . SVC ( kernel = 'rbf' , probability = True )
svm . fit ( X_train , Y_train )
# use Kernel SHAP to explain test set predictions
explainer = shap . KernelExplainer ( svm . predict_proba , X_train , link = "logit" )
shap_values = explainer . shap_values ( X_test , nsamples = 100 )
# plot the SHAP values for the Setosa output of the first instance
shap . force_plot ( explainer . expected_value [ 0 ], shap_values [ 0 ][ 0 ,:], X_test . iloc [ 0 ,:], link = "logit" )คำอธิบายข้างต้นแสดงคุณสมบัติสี่ประการที่แต่ละคุณสมบัติมีส่วนในการผลักเอาท์พุตของโมเดลจากค่าฐาน (เอาท์พุตของโมเดลโดยเฉลี่ยเหนือชุดข้อมูลการฝึกที่เราส่งผ่าน) ไปสู่ศูนย์ หากมีฟีเจอร์ใดที่ดันป้ายกำกับคลาสให้สูงขึ้น ก็จะแสดงเป็นสีแดง
หากเราใช้คำอธิบายหลายๆ อย่างดังที่แสดงไว้ด้านบน หมุนมัน 90 องศา แล้วซ้อนมันในแนวนอน เราจะเห็นคำอธิบายสำหรับชุดข้อมูลทั้งหมด นี่คือสิ่งที่เราทำด้านล่างนี้สำหรับตัวอย่างทั้งหมดในชุดทดสอบม่านตา:
# plot the SHAP values for the Setosa output of all instances
shap . force_plot ( explainer . expected_value [ 0 ], shap_values [ 0 ], X_test , link = "logit" ) ค่าการโต้ตอบของ SHAP เป็นการสรุปค่า SHAP ไปสู่การโต้ตอบในลำดับที่สูงกว่า การคำนวณการโต้ตอบแบบคู่ที่แม่นยำอย่างรวดเร็วถูกนำมาใช้กับโมเดลต้นไม้ด้วย shap.TreeExplainer(model).shap_interaction_values(X) ซึ่งจะส่งคืนเมทริกซ์สำหรับการคาดคะเนทุกครั้ง โดยที่เอฟเฟกต์หลักอยู่ที่เส้นทแยงมุม และเอฟเฟกต์การโต้ตอบจะอยู่นอกเส้นทแยงมุม ค่าเหล่านี้มักจะเผยให้เห็นความสัมพันธ์ที่ซ่อนอยู่ที่น่าสนใจ เช่น ความเสี่ยงที่เพิ่มขึ้นของการเสียชีวิตถึงจุดสูงสุดสำหรับผู้ชายอายุ 60 ปี (ดูรายละเอียดในสมุดบันทึกของ NHANES):
สมุดบันทึกด้านล่างสาธิตกรณีการใช้งานที่แตกต่างกันสำหรับ SHAP ดูภายในไดเร็กทอรีสมุดบันทึกของที่เก็บหากคุณต้องการลองเล่นกับสมุดบันทึกต้นฉบับด้วยตัวเอง
การใช้งาน Tree SHAP ซึ่งเป็นอัลกอริธึมที่รวดเร็วและแม่นยำในการคำนวณค่า SHAP สำหรับต้นไม้และชุดต้นไม้
แบบจำลองการอยู่รอดของ NHANES ที่มีค่าปฏิสัมพันธ์ของ XGBoost และ SHAP - การใช้ข้อมูลการเสียชีวิตจากการติดตามผล 20 ปี สมุดบันทึกนี้สาธิตวิธีใช้ XGBoost และ shap เพื่อค้นหาความสัมพันธ์ของปัจจัยเสี่ยงที่ซับซ้อน
การจัดประเภทรายได้ของการสำรวจสำมะโนประชากรด้วย LightGBM - การใช้ชุดข้อมูลรายได้การสำรวจสำมะโนผู้ใหญ่แบบมาตรฐาน สมุดบันทึกนี้จะฝึกโมเดลต้นไม้เสริมการไล่ระดับสีด้วย LightGBM จากนั้นอธิบายการคาดการณ์โดยใช้ shap
League of Legends ทำนายชัยชนะด้วย XGBoost - การใช้ชุดข้อมูล Kaggle ของการแข่งขันอันดับ 180,000 รายการจาก League of Legends เราฝึกและอธิบายโมเดลต้นไม้เสริมการไล่ระดับสีด้วย XGBoost เพื่อทำนายว่าผู้เล่นจะชนะการแข่งขันหรือไม่
การใช้งาน Deep SHAP ซึ่งเป็นอัลกอริธึมที่เร็วกว่า (แต่เป็นเพียงการประมาณเท่านั้น) ในการคำนวณค่า SHAP สำหรับโมเดลการเรียนรู้เชิงลึกที่อิงตามการเชื่อมต่อระหว่าง SHAP และอัลกอริธึม DeepLIFT
การจัดหมวดหมู่ตัวเลข MNIST ด้วย Keras - การใช้ชุดข้อมูลการรู้จำลายมือของ MNIST สมุดบันทึกนี้จะฝึกโครงข่ายประสาทเทียมด้วย Keras จากนั้นอธิบายการคาดการณ์โดยใช้ shap
Keras LSTM สำหรับการจัดประเภทความรู้สึกของ IMDB - สมุดบันทึกนี้จะฝึก LSTM ด้วย Keras บนชุดข้อมูลการวิเคราะห์ความรู้สึกแบบข้อความ IMDB จากนั้นอธิบายการคาดการณ์โดยใช้ shap
การใช้การไล่ระดับสีที่คาดหวังกับค่า SHAP โดยประมาณสำหรับโมเดลการเรียนรู้เชิงลึก ขึ้นอยู่กับการเชื่อมต่อระหว่าง SHAP และอัลกอริธึม Integrated Gradients GradientExplainer ช้ากว่า DeepExplainer และตั้งสมมติฐานการประมาณที่แตกต่างกัน
สำหรับโมเดลเชิงเส้นที่มีคุณสมบัติอิสระ เราสามารถคำนวณค่า SHAP ที่แน่นอนในเชิงวิเคราะห์ได้ นอกจากนี้เรายังสามารถอธิบายความสัมพันธ์ของคุณลักษณะได้หากเรายินดีที่จะประมาณค่าเมทริกซ์ความแปรปรวนร่วมของคุณลักษณะ LinearExplainer รองรับทั้งสองตัวเลือกเหล่านี้
การใช้งาน Kernel SHAP ซึ่งเป็นวิธีการไม่เชื่อเรื่องพระเจ้าของโมเดลเพื่อประมาณค่า SHAP สำหรับโมเดลใดๆ เนื่องจากไม่มีสมมติฐานเกี่ยวกับประเภทโมเดล KernelExplainer จึงช้ากว่าอัลกอริธึมเฉพาะประเภทโมเดลอื่นๆ
การจำแนกรายได้ของการสำรวจสำมะโนประชากรด้วย scikit-learn - การใช้ชุดข้อมูลรายได้การสำรวจสำมะโนผู้ใหญ่แบบมาตรฐาน สมุดบันทึกนี้จะฝึกตัวแยกประเภทเพื่อนบ้านที่ใกล้ที่สุดโดยใช้ scikit-learn แล้วอธิบายการคาดการณ์โดยใช้ shap
โมเดล ImageNet VGG16 พร้อม Keras - อธิบายการคาดการณ์ของโครงข่ายประสาทเทียม VGG16 แบบคลาสสิกสำหรับรูปภาพ วิธีนี้ทำงานโดยใช้วิธี Kernel SHAP แบบไม่เชื่อเรื่องพระเจ้ากับรูปภาพที่แบ่งส่วนซุปเปอร์พิกเซล
การจำแนกประเภทไอริส - การสาธิตพื้นฐานโดยใช้ชุดข้อมูลสายพันธุ์ไอริสยอดนิยม มันอธิบายการคาดการณ์จากแบบจำลองที่แตกต่างกันหกแบบใน scikit-learn โดยใช้ shap
สมุดบันทึกเหล่านี้สาธิตวิธีการใช้ฟังก์ชันและออบเจ็กต์เฉพาะอย่างครอบคลุม
shap.decision_plot และ shap.multioutput_decision_plot
shap.dependence_plot
มะนาว: ริเบโร, มาร์โก ตูลิโอ, ซาเมียร์ ซิงห์ และคาร์ลอส เกสต์ริน "ทำไมฉันถึงเชื่อคุณ: อธิบายการทำนายของตัวแยกประเภทใด ๆ " การประชุมนานาชาติ ACM SIGKDD เรื่องการค้นพบองค์ความรู้และการทำเหมืองข้อมูล ครั้งที่ 22 พลอากาศเอก, 2559.
ค่าการสุ่มตัวอย่าง Shapley: Strumbelj, Erik และ Igor Kononenko "การอธิบายโมเดลการทำนายและการทำนายส่วนบุคคลพร้อมฟีเจอร์ต่างๆ" ระบบความรู้และข้อมูล 41.3 (2014): 647-665.
DeepLIFT: ชริกุมาร์, อาวานติ, เพย์ตัน กรีนไซด์ และอันชุล กุนดาเจ "การเรียนรู้คุณสมบัติที่สำคัญผ่านการเผยแพร่ความแตกต่างในการเปิดใช้งาน" arXiv พิมพ์ล่วงหน้า arXiv:1704.02685 (2017)
QII: ดัตตา, อนุปัม, ชายัค เซน และยาอีร์ ซิก "ความโปร่งใสของอัลกอริทึมผ่านอิทธิพลอินพุตเชิงปริมาณ: ทฤษฎีและการทดลองกับระบบการเรียนรู้" ความปลอดภัยและความเป็นส่วนตัว (SP) เปิดการประชุม IEEE Symposium ปี 2016 อีอีอี, 2016.
การเผยแพร่ความเกี่ยวข้องแบบเลเยอร์: Bach, Sebastian และคณะ "ในคำอธิบายแบบพิกเซลสำหรับการตัดสินใจแยกประเภทที่ไม่ใช่เชิงเส้นโดยการแพร่กระจายความเกี่ยวข้องแบบเลเยอร์" กรุณาหนึ่ง 10.7 (2015): e0130140
ค่าการถดถอยของแชปลีย์: ลิโปเวตสกี้ สแตน และไมเคิล คอนคลิน "การวิเคราะห์การถดถอยในแนวทางทฤษฎีเกม" แบบจำลองสุ่มประยุกต์ในธุรกิจและอุตสาหกรรม 17.4 (2544): 319-330
ล่ามต้นไม้: Saaba, Ando การตีความป่าสุ่ม http://blog.datadive.net/depending-random-forests/
อัลกอริธึมและการแสดงภาพที่ใช้ในแพ็คเกจนี้ส่วนใหญ่มาจากการวิจัยในห้องทดลองของ Su-In Lee ที่มหาวิทยาลัย Washington และ Microsoft Research หากคุณใช้ SHAP ในการวิจัยของคุณ เราขอขอบคุณการอ้างอิงบทความที่เหมาะสม:
force_plot และการใช้งานทางการแพทย์ คุณสามารถอ่าน/อ้างอิงรายงานวิศวกรรมชีวการแพทย์ธรรมชาติของเรา (bibtex เข้าถึงได้ฟรี)

