Candle เป็นเฟรมเวิร์ก ML ที่เรียบง่ายสำหรับ Rust โดยเน้นไปที่ประสิทธิภาพ (รวมถึงการรองรับ GPU) และความสะดวกในการใช้งาน ลองสาธิตออนไลน์ของเรา: กระซิบ, LLaMA2, T5, yolo, เซ็กเมนต์อะไรก็ได้
ตรวจสอบให้แน่ใจว่าคุณได้ติดตั้ง candle-core อย่างถูกต้องตามที่อธิบายไว้ใน การติดตั้ง
มาดูวิธีการคูณเมทริกซ์อย่างง่ายกัน เขียนสิ่งต่อไปนี้ลงในไฟล์ myapp/src/main.rs ของคุณ:
use candle_core :: { Device , Tensor } ;
fn main ( ) -> Result < ( ) , Box < dyn std :: error :: Error > > {
let device = Device :: Cpu ;
let a = Tensor :: randn ( 0f32 , 1. , ( 2 , 3 ) , & device ) ? ;
let b = Tensor :: randn ( 0f32 , 1. , ( 3 , 4 ) , & device ) ? ;
let c = a . matmul ( & b ) ? ;
println ! ( "{c}" ) ;
Ok ( ( ) )
} cargo run ควรแสดงเทนเซอร์ของรูปร่าง Tensor[[2, 4], f32]
เมื่อติดตั้ง candle พร้อมรองรับ Cuda แล้ว เพียงกำหนด device ให้อยู่บน GPU:
- let device = Device::Cpu;
+ let device = Device::new_cuda(0)?;สำหรับตัวอย่างขั้นสูงเพิ่มเติม โปรดดูที่ส่วนต่อไปนี้
การสาธิตออนไลน์เหล่านี้ทำงานในเบราว์เซอร์ของคุณทั้งหมด:
นอกจากนี้เรายังจัดเตรียมตัวอย่างตามบรรทัดคำสั่งโดยใช้โมเดลล้ำสมัย:
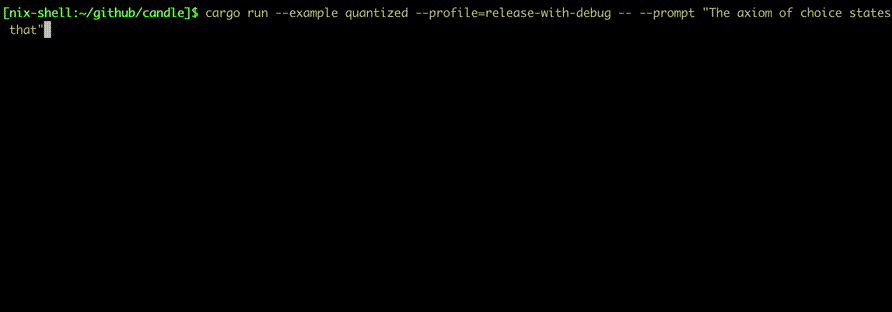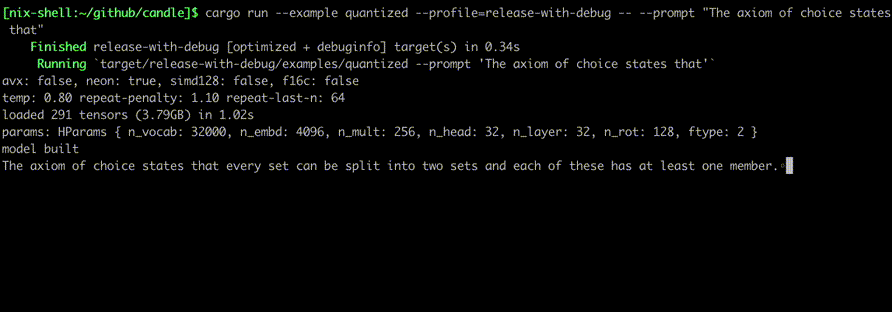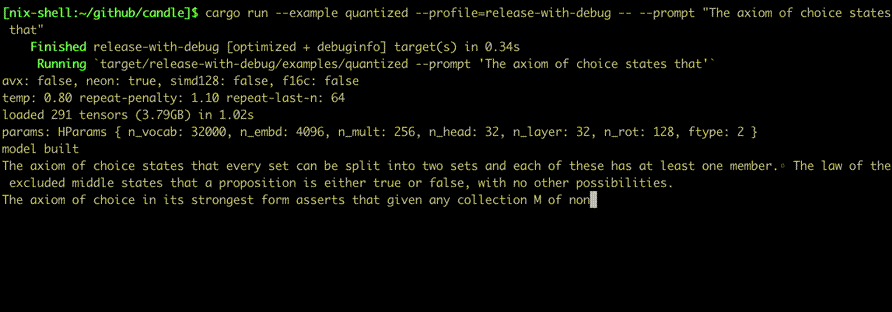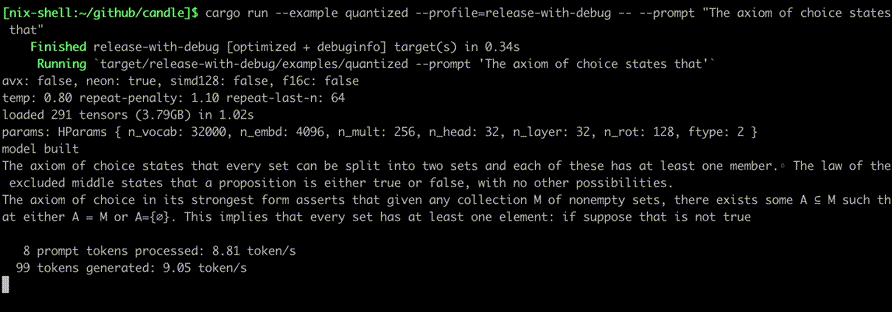





รันโดยใช้คำสั่งเช่น:
cargo run --example quantized --release
เพื่อที่จะใช้ CUDA ให้เพิ่ม --features cuda ลงในบรรทัดคำสั่งตัวอย่าง หากคุณติดตั้ง cuDNN ไว้ ให้ใช้ --features cudnn เพื่อเพิ่มความเร็วให้มากยิ่งขึ้น
นอกจากนี้ยังมีตัวอย่าง wasm สำหรับกระซิบและ llama2.c คุณสามารถสร้างมันด้วย trunk หรือลองออนไลน์: กระซิบ, llama2, T5, Phi-1.5 และ Phi-2, Segment Anything Model
สำหรับ LLaMA2 ให้รันคำสั่งต่อไปนี้เพื่อดึงไฟล์น้ำหนักและเริ่มเซิร์ฟเวอร์ทดสอบ:
cd candle-wasm-examples/llama2-c
wget https://huggingface.co/spaces/lmz/candle-llama2/resolve/main/model.bin
wget https://huggingface.co/spaces/lmz/candle-llama2/resolve/main/tokenizer.json
trunk serve --release --port 8081จากนั้นตรงไปที่ http://localhost:8081/
candle-tutorial : บทช่วยสอนที่มีรายละเอียดมากซึ่งแสดงวิธีแปลงโมเดล PyTorch เป็น Candlecandle-lora : การใช้งาน LoRA ที่มีประสิทธิภาพและถูกหลักการยศาสตร์สำหรับ Candle candle-lora มีoptimisers : ชุดเครื่องมือเพิ่มประสิทธิภาพรวมถึง SGD พร้อมโมเมนตัม, AdaGrad, AdaDelta, AdaMax, NAdam, RAdam และ RMSpropcandle-vllm : แพลตฟอร์มที่มีประสิทธิภาพสำหรับการอนุมานและให้บริการ LLM ในพื้นที่ รวมถึงเซิร์ฟเวอร์ API ที่เข้ากันได้กับ OpenAIcandle-ext : ไลบรารีส่วนขยายของ Candle ที่ให้ฟังก์ชัน PyTorch ที่ไม่สามารถใช้งานได้ใน Candle ในปัจจุบันcandle-coursera-ml : การใช้อัลกอริธึม ML จากหลักสูตร Machine Learning Specialization ของ Courserakalosm : เมตาเฟรมเวิร์กแบบหลายโมดัลใน Rust สำหรับการเชื่อมต่อกับโมเดลที่ได้รับการฝึกอบรมล่วงหน้าในพื้นที่ พร้อมการสนับสนุนสำหรับการสร้างแบบควบคุม ตัวอย่างแบบกำหนดเอง ฐานข้อมูลเวกเตอร์ในหน่วยความจำ การถอดเสียง และอื่นๆcandle-sampling : เทคนิคการสุ่มตัวอย่างเทียนgpt-from-scratch-rs : พอร์ตของ Andrej Karpathy's มาสร้างบทช่วยสอน GPT บน YouTube เพื่อแสดง Candle API เกี่ยวกับปัญหาของเล่นcandle-einops : การใช้งานที่เป็นสนิมอย่างแท้จริงของไลบรารี python einopsatoma-infer : ไลบรารี Rust เพื่อการอนุมานอย่างรวดเร็วในวงกว้าง ใช้ประโยชน์จาก FlashAttention2 เพื่อการคำนวณความสนใจที่มีประสิทธิภาพ PagedAttention สำหรับการจัดการหน่วยความจำแคช KV ที่มีประสิทธิภาพ และการรองรับ multi-GPU รองรับ OpenAI APIหากคุณมีรายการเพิ่มเติม โปรดส่งคำขอดึง
สูตรโกง:
| การใช้ PyTorch | การใช้เทียน | |
|---|---|---|
| การสร้าง | torch.Tensor([[1, 2], [3, 4]]) | Tensor::new(&[[1f32, 2.], [3., 4.]], &Device::Cpu)? |
| การสร้าง | torch.zeros((2, 2)) | Tensor::zeros((2, 2), DType::F32, &Device::Cpu)? |
| การจัดทำดัชนี | tensor[:, :4] | tensor.i((.., ..4))? |
| การดำเนินงาน | tensor.view((2, 2)) | tensor.reshape((2, 2))? |
| การดำเนินงาน | a.matmul(b) | a.matmul(&b)? |
| เลขคณิต | a + b | &a + &b |
| อุปกรณ์ | tensor.to(device="cuda") | tensor.to_device(&Device::new_cuda(0)?)? |
| ประเภทD | tensor.to(dtype=torch.float16) | tensor.to_dtype(&DType::F16)? |
| ประหยัด | torch.save({"A": A}, "model.bin") | candle::safetensors::save(&HashMap::from([("A", A)]), "model.safetensors")? |
| กำลังโหลด | weights = torch.load("model.bin") | candle::safetensors::load("model.safetensors", &device) |
Tensorเป้าหมายหลักของ Candle คือ ทำให้การอนุมานแบบไร้เซิร์ฟเวอร์เป็นไปได้ เฟรมเวิร์กแมชชีนเลิร์นนิงเต็มรูปแบบ เช่น PyTorch มีขนาดใหญ่มาก ซึ่งทำให้การสร้างอินสแตนซ์บนคลัสเตอร์ช้า Candle อนุญาตให้ปรับใช้ไบนารีน้ำหนักเบา
ประการที่สอง Candle ช่วยให้คุณสามารถ ลบ Python ออก จากปริมาณงานการผลิตได้ ค่าใช้จ่ายของ Python อาจส่งผลเสียต่อประสิทธิภาพการทำงานอย่างรุนแรง และ GIL ก็เป็นสาเหตุของอาการปวดหัวอย่างฉาวโฉ่
ในที่สุด Rust ก็เจ๋ง! ระบบนิเวศของ HF จำนวนมากมีลังแบบ Rust อยู่แล้ว เช่น ตัวเซฟเทนเซอร์และตัวโทเค็น
dfdx เป็นลังที่น่าเกรงขาม โดยมีรูปร่างต่างๆ รวมอยู่ในประเภทต่างๆ วิธีนี้จะช่วยป้องกันอาการปวดหัวได้มากโดยให้คอมไพเลอร์บ่นเกี่ยวกับรูปร่างที่ไม่ตรงกันทันที อย่างไรก็ตาม เราพบว่าคุณสมบัติบางอย่างยังต้องใช้ทุกคืน และการเขียนโค้ดอาจเป็นเรื่องน่ากังวลเล็กน้อยสำหรับผู้เชี่ยวชาญที่ไม่เป็นสนิม
เรากำลังใช้ประโยชน์และสนับสนุนลังหลักอื่นๆ สำหรับรันไทม์ ดังนั้นหวังว่าทั้งสองลังจะได้รับประโยชน์จากกันและกัน
Burn เป็นลังทั่วไปที่สามารถใช้ประโยชน์จากแบ็กเอนด์ได้หลายตัว เพื่อให้คุณสามารถเลือกกลไกที่ดีที่สุดสำหรับปริมาณงานของคุณได้
tch-rs เชื่อมโยงกับไลบรารีคบเพลิงใน Rust มีความหลากหลายอย่างมาก แต่นำไลบรารีคบเพลิงทั้งหมดมาสู่รันไทม์ ผู้สนับสนุนหลักของ tch-rs ยังมีส่วนร่วมในการพัฒนา candle อีกด้วย
หากคุณได้รับสัญลักษณ์ที่หายไปเมื่อรวบรวมไบนารี/การทดสอบโดยใช้คุณสมบัติ mkl หรือเร่งความเร็ว เช่น สำหรับ mkl คุณจะได้รับ:
= note: /usr/bin/ld: (....o): in function `blas::sgemm':
.../blas-0.22.0/src/lib.rs:1944: undefined reference to `sgemm_' collect2: error: ld returned 1 exit status
= note: some `extern` functions couldn't be found; some native libraries may need to be installed or have their path specified
= note: use the `-l` flag to specify native libraries to link
= note: use the `cargo:rustc-link-lib` directive to specify the native libraries to link with Cargo
หรือเพื่อเร่งความเร็ว:
Undefined symbols for architecture arm64:
"_dgemm_", referenced from:
candle_core::accelerate::dgemm::h1b71a038552bcabe in libcandle_core...
"_sgemm_", referenced from:
candle_core::accelerate::sgemm::h2cf21c592cba3c47 in libcandle_core...
ld: symbol(s) not found for architecture arm64
อาจเป็นไปได้ว่าไม่มีแฟล็กตัวเชื่อมโยงที่จำเป็นในการเปิดใช้งานไลบรารี mkl คุณสามารถลองเพิ่มสิ่งต่อไปนี้สำหรับ mkl ที่ด้านบนของไบนารี่ของคุณ:
extern crate intel_mkl_src ;หรือเพื่อเร่งความเร็ว:
extern crate accelerate_src ; Error: request error: https://huggingface.co/meta-llama/Llama-2-7b-hf/resolve/main/tokenizer.json: status code 401
อาจเป็นเพราะคุณไม่ได้รับอนุญาตให้ใช้โมเดล LLaMA-v2 ในการแก้ไขปัญหานี้ คุณต้องลงทะเบียนบน Huggingface-hub ยอมรับเงื่อนไขโมเดล LLaMA-v2 และตั้งค่าโทเค็นการตรวจสอบสิทธิ์ของคุณ ดูปัญหา #350 สำหรับรายละเอียดเพิ่มเติม
In file included from kernels/flash_fwd_launch_template.h:11:0,
from kernels/flash_fwd_hdim224_fp16_sm80.cu:5:
kernels/flash_fwd_kernel.h:8:10: fatal error: cute/algorithm/copy.hpp: No such file or directory
#include <cute/algorithm/copy.hpp>
^~~~~~~~~~~~~~~~~~~~~~~~~
compilation terminated.
Error: nvcc error while compiling:
cutlass ถูกจัดเตรียมไว้เป็นโมดูลย่อยของ git ดังนั้นคุณอาจต้องการรันคำสั่งต่อไปนี้เพื่อตรวจสอบอย่างถูกต้อง
git submodule update --init /usr/include/c++/11/bits/std_function.h:530:146: error: parameter packs not expanded with ‘...’:
นี่เป็นจุดบกพร่องใน gcc-11 ที่ถูกทริกเกอร์โดยคอมไพเลอร์ Cuda หากต้องการแก้ไขปัญหานี้ ให้ติดตั้ง gcc เวอร์ชันอื่นที่รองรับ เช่น gcc-10 และระบุเส้นทางไปยังคอมไพลเลอร์ในตัวแปรสภาพแวดล้อม NVCC_CCBIN
env NVCC_CCBIN=/usr/lib/gcc/x86_64-linux-gnu/10 cargo ...
Couldn't compile the test.
---- .candle-booksrcinferencehub.md - Using_the_hub::Using_in_a_real_model_ (line 50) stdout ----
error: linking with `link.exe` failed: exit code: 1181
//very long chain of linking
= note: LINK : fatal error LNK1181: cannot open input file 'windows.0.48.5.lib'
ตรวจสอบให้แน่ใจว่าคุณเชื่อมโยงไลบรารีดั้งเดิมทั้งหมดที่อาจตั้งอยู่นอกเป้าหมายของโปรเจ็กต์ เช่น หากต้องการรันการทดสอบ mdbook คุณควรรัน:
mdbook test candle-book -L .targetdebugdeps `
-L native=$env:USERPROFILE.cargoregistrysrcindex.crates.io-6f17d22bba15001fwindows_x86_64_msvc-0.42.2lib `
-L native=$env:USERPROFILE.cargoregistrysrcindex.crates.io-6f17d22bba15001fwindows_x86_64_msvc-0.48.5lib
ปัญหานี้อาจเกิดจากการโหลดโมเดลจาก /mnt/c รายละเอียดเพิ่มเติมเกี่ยวกับ stackoverflow
คุณสามารถตั้งค่า RUST_BACKTRACE=1 ให้มี backtraces เมื่อมีการสร้างข้อผิดพลาดเทียน
หากคุณพบข้อผิดพลาดลักษณะนี้ called Result::unwrap() on an value: LoadLibraryExW { source: Os { code: 126, kind: Uncategorized, message: "The specified module could not be found." } } บนหน้าต่าง เพื่อแก้ไขการคัดลอกและเปลี่ยนชื่อไฟล์ทั้ง 3 ไฟล์นี้ (ตรวจสอบให้แน่ใจว่าไฟล์เหล่านั้นอยู่ในเส้นทาง) เส้นทางขึ้นอยู่กับเวอร์ชัน cuda ของคุณ c:WindowsSystem32nvcuda.dll -> cuda.dll c:Program FilesNVIDIA GPU Computing ToolkitCUDAv12.4bincublas64_12.dll -> cublas.dll c:Program FilesNVIDIA GPU Computing ToolkitCUDAv12.4bincurand64_10.dll -> curand.dll


