whisperX
3.1.1
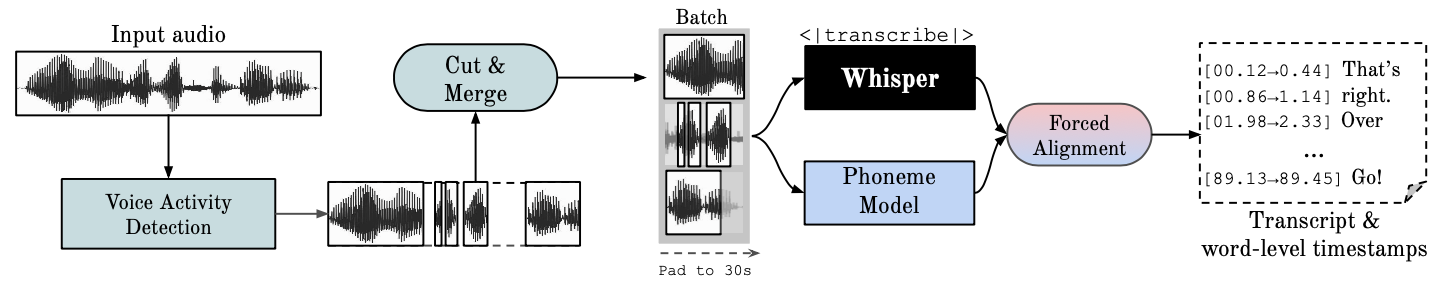
พื้นที่เก็บข้อมูลนี้ให้การรู้จำคำพูดอัตโนมัติที่รวดเร็ว (เรียลไทม์ 70x พร้อม large-v2) พร้อมการประทับเวลาระดับคำและการแยกเสียงของผู้พูด
Whisper เป็นโมเดล ASR ที่พัฒนาโดย OpenAI ซึ่งได้รับการฝึกฝนเกี่ยวกับชุดข้อมูลขนาดใหญ่ที่มีเสียงที่หลากหลาย แม้ว่าจะสร้างการถอดเสียงที่มีความแม่นยำสูง แต่การประทับเวลาที่สอดคล้องกันจะอยู่ที่ระดับคำพูด ไม่ใช่ต่อคำ และอาจคลาดเคลื่อนได้หลายวินาที เสียงกระซิบของ OpenAI ไม่รองรับการแบทช์
Phoneme-Based ASR ชุดแบบจำลองที่ได้รับการปรับแต่งให้จดจำหน่วยคำพูดที่เล็กที่สุดเพื่อแยกแยะคำหนึ่งจากอีกคำหนึ่ง เช่น องค์ประกอบ p ใน "แตะ" โมเดลตัวอย่างยอดนิยมคือ wav2vec2.0
Forced Alignment หมายถึงกระบวนการที่การถอดเสียงแบบออโธกราฟิกสอดคล้องกับการบันทึกเสียงเพื่อสร้างการแบ่งส่วนระดับโทรศัพท์โดยอัตโนมัติ
Voice Activity Detection (VAD) คือการตรวจหาการมีอยู่หรือไม่มีคำพูดของมนุษย์
การแยกเสียงของผู้พูด เป็นกระบวนการแบ่งพาร์ติชันสตรีมเสียงที่มีคำพูดของมนุษย์ออกเป็นส่วนที่เป็นเนื้อเดียวกันตามเอกลักษณ์ของผู้พูดแต่ละคน
การทำงานของ GPU จำเป็นต้องติดตั้งไลบรารี NVIDIA cuBLAS 11.x และ cuDNN 8.x บนระบบ โปรดดูเอกสารประกอบของ CTranslate2
conda create --name whisperx python=3.10
conda activate whisperx
conda install pytorch==2.0.0 torchaudio==2.0.0 pytorch-cuda=11.8 -c pytorch -c nvidia
ดูวิธีอื่นๆ ที่นี่
pip install git+https://github.com/m-bain/whisperx.git
หากติดตั้งแล้ว ให้อัพเดตแพ็คเกจเป็นคอมมิตล่าสุด
pip install git+https://github.com/m-bain/whisperx.git --upgrade
หากต้องการแก้ไขแพ็คเกจนี้ ให้โคลนและติดตั้งในโหมดแก้ไขได้:
$ git clone https://github.com/m-bain/whisperX.git
$ cd whisperX
$ pip install -e .
คุณอาจต้องติดตั้ง ffmpeg, สนิม ฯลฯ ทำตามคำแนะนำของ openAI ที่นี่ https://github.com/openai/whisper#setup
หากต้องการ เปิดใช้งาน Speaker Diarization ให้รวมโทเค็นการเข้าถึง Hugging Face ของคุณ (อ่าน) ที่คุณสามารถสร้างได้จากที่นี่ หลังจากอาร์กิวเมนต์ --hf_token และยอมรับข้อตกลงผู้ใช้สำหรับรุ่นต่อไปนี้: Segmentation และ Speaker-Diarization-3.1 (หากคุณเลือกใช้ Speaker -Diarization 2.x ปฏิบัติตามข้อกำหนดที่นี่แทน)
บันทึก
ณ วันที่ 11 ต.ค. 2023 เกิดปัญหาที่ทราบเกี่ยวกับประสิทธิภาพที่ช้าของ pyannote/Speaker-Diarization-3.0 ใน WhisperX เนื่องจากมีความขัดแย้งในการพึ่งพาระหว่าง Fast-whisper และ pyannote-audio 3.0.0 โปรดดูปัญหานี้สำหรับรายละเอียดเพิ่มเติมและวิธีแก้ปัญหาที่เป็นไปได้
เรียกใช้กระซิบในส่วนตัวอย่าง (โดยใช้พารามิเตอร์เริ่มต้น กระซิบขนาดเล็ก) เพิ่ม --highlight_words True เพื่อแสดงภาพการกำหนดเวลาของคำในไฟล์ .srt
whisperx examples/sample01.wav
ผลลัพธ์โดยใช้ WhisperX โดยบังคับให้จัดตำแหน่งเป็น wav2vec2.0 ใหญ่:
เปรียบเทียบสิ่งนี้กับเสียงกระซิบต้นฉบับ ซึ่งการถอดเสียงหลายรายการไม่ตรงกัน:
เพื่อความแม่นยำในการประทับเวลาที่เพิ่มขึ้น โดยมีค่าใช้จ่าย GPU Mem ที่สูงขึ้น ให้ใช้โมเดลที่ใหญ่กว่า (พบว่าโมเดลการจัดตำแหน่งที่ใหญ่กว่านั้นไม่มีประโยชน์ ดูกระดาษ) เช่น
whisperx examples/sample01.wav --model large-v2 --align_model WAV2VEC2_ASR_LARGE_LV60K_960H --batch_size 4
หากต้องการติดป้ายกำกับการถอดเสียงด้วยรหัสผู้พูด (กำหนดจำนวนผู้พูดหากทราบ เช่น --min_speakers 2 --max_speakers 2 ):
whisperx examples/sample01.wav --model large-v2 --diarize --highlight_words True
หากต้องการทำงานบน CPU แทน GPU (และสำหรับการทำงานบน Mac OS X):
whisperx examples/sample01.wav --compute_type int8
โมเดลการจัดตำแหน่ง ASR ของฟอนิมเป็น แบบเฉพาะภาษา สำหรับภาษาที่ทดสอบ โมเดลเหล่านี้จะถูกเลือกโดยอัตโนมัติจากท่อส่งเสียงคบเพลิงหรือหน้ากอด เพียงส่งรหัส --language และใช้เสียงกระซิบ --model large
โมเดลเริ่มต้นในปัจจุบันมีให้สำหรับ {en, fr, de, es, it, ja, zh, nl, uk, pt} หากภาษาที่ตรวจพบไม่อยู่ในรายการนี้ คุณจะต้องค้นหาโมเดล ASR ที่ใช้ฟอนิมจากฮับโมเดล Huggingface และทดสอบกับข้อมูลของคุณ
whisperx --model large-v2 --language de examples/sample_de_01.wav
ดูตัวอย่างเพิ่มเติมในภาษาอื่นๆ ที่นี่
import whisperx
import gc
device = "cuda"
audio_file = "audio.mp3"
batch_size = 16 # reduce if low on GPU mem
compute_type = "float16" # change to "int8" if low on GPU mem (may reduce accuracy)
# 1. Transcribe with original whisper (batched)
model = whisperx . load_model ( "large-v2" , device , compute_type = compute_type )
# save model to local path (optional)
# model_dir = "/path/"
# model = whisperx.load_model("large-v2", device, compute_type=compute_type, download_root=model_dir)
audio = whisperx . load_audio ( audio_file )
result = model . transcribe ( audio , batch_size = batch_size )
print ( result [ "segments" ]) # before alignment
# delete model if low on GPU resources
# import gc; gc.collect(); torch.cuda.empty_cache(); del model
# 2. Align whisper output
model_a , metadata = whisperx . load_align_model ( language_code = result [ "language" ], device = device )
result = whisperx . align ( result [ "segments" ], model_a , metadata , audio , device , return_char_alignments = False )
print ( result [ "segments" ]) # after alignment
# delete model if low on GPU resources
# import gc; gc.collect(); torch.cuda.empty_cache(); del model_a
# 3. Assign speaker labels
diarize_model = whisperx . DiarizationPipeline ( use_auth_token = YOUR_HF_TOKEN , device = device )
# add min/max number of speakers if known
diarize_segments = diarize_model ( audio )
# diarize_model(audio, min_speakers=min_speakers, max_speakers=max_speakers)
result = whisperx . assign_word_speakers ( diarize_segments , result )
print ( diarize_segments )
print ( result [ "segments" ]) # segments are now assigned speaker IDs หากคุณไม่สามารถเข้าถึง GPU ของคุณเองได้ ให้ใช้ลิงก์ด้านบนเพื่อทดลองใช้ WhisperX
สำหรับรายละเอียดเฉพาะเกี่ยวกับการจัดชุดและการจัดตำแหน่ง ผลกระทบของ VAD รวมถึงโมเดลการจัดตำแหน่งที่เลือก โปรดดูกระดาษที่พิมพ์ล่วงหน้า
หากต้องการลดความต้องการหน่วยความจำ GPU ให้ลองทำสิ่งใดสิ่งหนึ่งต่อไปนี้ (2. และ 3. อาจส่งผลต่อคุณภาพ):
--batch_size 4--model base--compute_type int8ความแตกต่างในการถอดความจากเสียงกระซิบของ openai:
--without_timestamps True ซึ่งจะทำให้มั่นใจได้ว่าจะมีการส่งต่อ 1 ครั้งต่อตัวอย่างในชุดงาน อย่างไรก็ตาม สิ่งนี้อาจทำให้เกิดความคลาดเคลื่อนกับเอาต์พุตเสียงกระซิบเริ่มต้น--condition_on_prev_text ถูกตั้งค่าเป็น False ตามค่าเริ่มต้น (ลดอาการประสาทหลอน) หากคุณพูดได้หลายภาษา วิธีสำคัญที่คุณสามารถมีส่วนร่วมในโปรเจ็กต์นี้คือการค้นหาแบบจำลองหน่วยเสียงบนหน้ากอด (หรือฝึกฝนของคุณเอง) และทดสอบคำพูดสำหรับภาษาเป้าหมาย หากผลลัพธ์ดูดี ให้ส่งคำขอดึงและตัวอย่างบางส่วนที่แสดงถึงความสำเร็จ
การค้นหาจุดบกพร่องและคำขอดึงข้อมูลยังได้รับการชื่นชมอย่างมากเพื่อให้โครงการนี้ดำเนินต่อไปได้ เนื่องจากโครงการนี้แตกต่างจากขอบเขตการวิจัยเดิมอยู่แล้ว
เริ่มต้นหลายภาษา
การเลือกแบบจำลองการจัดแนวอัตโนมัติตามการตรวจจับภาษา
การใช้งานหลาม
รวมการแยกเสียงของผู้พูด
โมเดลฟลัช สำหรับทรัพยากรหน่วยความจำ GPU ต่ำ
แบ็กเอนด์ที่เร็วกว่ากระซิบ
เพิ่ม max-line ฯลฯ ดู (utils.py เสียงกระซิบของ openai)
ส่วนระดับประโยค (กล่องเครื่องมือ nltk)
ปรับปรุงตรรกะการจัดตำแหน่ง
อัปเดตตัวอย่างด้วยการเน้นคำและการเน้นคำ
คำบรรยาย .ass เอาต์พุต <- นำสิ่งนี้กลับมา (ลบออกใน v3)
เพิ่มโค้ดการเปรียบเทียบ (TEDLIUM สำหรับ spd/WER และการแบ่งส่วนคำ)
อนุญาตให้ silero-vad เป็นตัวเลือก VAD สำรอง
ปรับปรุง diariization (ระดับคำ) ยากกว่าที่คิด...
ติดต่อ [email protected] เพื่อสอบถามข้อมูล
งานนี้และปริญญาเอกของฉันได้รับการสนับสนุนจาก VGG (Visual Geometry Group) และมหาวิทยาลัยออกซ์ฟอร์ด
แน่นอนว่าสิ่งนี้สร้างขึ้นจากเสียงกระซิบของ openAI ยืมรหัสการจัดตำแหน่งที่สำคัญจากบทช่วยสอนของ PyTorch เกี่ยวกับการจัดตำแหน่งแบบบังคับ และใช้ pyannote VAD / Diarization ที่ยอดเยี่ยม https://github.com/pyannote/pyannote-audio
โมเดล VAD และ Diarization ที่มีคุณค่าจาก [pyannote audio] [https://github.com/pyannote/pyannote-audio]
แบ็กเอนด์ที่ยอดเยี่ยมจาก faster-whisper และ CTranslate2
ผู้ที่สนับสนุนงานนี้ทางการเงิน
สุดท้ายนี้ ขอขอบคุณผู้ร่วมสนับสนุน OS ของโปรเจ็กต์นี้ที่ทำให้โครงการดำเนินต่อไปและระบุจุดบกพร่อง
@article { bain2022whisperx ,
title = { WhisperX: Time-Accurate Speech Transcription of Long-Form Audio } ,
author = { Bain, Max and Huh, Jaesung and Han, Tengda and Zisserman, Andrew } ,
journal = { INTERSPEECH 2023 } ,
year = { 2023 }
}

