LARS
v2.0-beta8:

LARS เป็นแอปพลิเคชันที่ช่วยให้คุณสามารถเรียกใช้ LLM (โมเดลภาษาขนาดใหญ่) ภายในอุปกรณ์ของคุณ อัปโหลดเอกสารของคุณเอง และมีส่วนร่วมในการสนทนาโดยที่ LLM จะใช้พื้นฐานในการตอบสนองต่อเนื้อหาที่คุณอัปโหลด การต่อสายดินนี้ช่วยเพิ่มความแม่นยำและลดปัญหาทั่วไปเกี่ยวกับความไม่ถูกต้องที่ AI สร้างขึ้นหรือ "ภาพหลอน" เทคนิคนี้เรียกกันทั่วไปว่า "Retriever Augmented Generation" หรือ RAG
มีแอปพลิเคชันเดสก์ท็อปจำนวนมากสำหรับการเรียกใช้ LLM ภายในเครื่อง และ LARS ตั้งเป้าที่จะเป็นแอปพลิเคชัน LLM แบบโอเพนซอร์สที่เน้น RAG เป็นหลัก ในการบรรลุเป้าหมายนี้ LARS นำแนวคิดของ RAG ก้าวไปไกลยิ่งขึ้นด้วยการเพิ่มการอ้างอิงโดยละเอียดให้กับทุกคำตอบ โดยจัดหาชื่อเอกสาร หมายเลขหน้า การเน้นข้อความ และรูปภาพที่เกี่ยวข้องกับคำถามของคุณโดยเฉพาะ และแม้แต่การนำเสนอโปรแกรมอ่านเอกสารภายใน หน้าต่างตอบกลับ แม้ว่าการอ้างอิงทั้งหมดอาจไม่ปรากฏสำหรับทุกคำตอบเสมอไป แต่แนวคิดก็คือต้องมีการอ้างอิงผสมกันอย่างน้อยสำหรับคำตอบ RAG ทุกครั้ง และโดยทั่วไปจะพบว่าเป็นเช่นนั้น
วิดีโอสาธิตคุณสมบัติ LARS
Python v3.10.x หรือสูงกว่า: https://www.python.org/downloads/
ไพทอร์ช:
หากคุณวางแผนที่จะใช้ GPU เพื่อรัน LLM ตรวจสอบให้แน่ใจว่าได้ติดตั้งไดรเวอร์ GPU และชุดเครื่องมือ CUDA/ROCm ตามความเหมาะสมสำหรับการตั้งค่าของคุณ จากนั้นจึงดำเนินการตั้งค่า PyTorch ด้านล่างเท่านั้น
ดาวน์โหลดและติดตั้งเวอร์ชัน PyTorch ที่เหมาะกับระบบของคุณ: https://pytorch.org/get-started/locally/
โคลนที่เก็บ:
git clone https://github.com/abgulati/LARS
cd LARS
GitHub Settings -> Developer settings (located on the bottom left!) -> Personal access tokensติดตั้งการพึ่งพา Python:
Windows ผ่าน PIP:
pip install -r .requirements.txt
ลินุกซ์ผ่าน PIP:
pip3 install -r ./requirements.txt
หมายเหตุเกี่ยวกับ Azure: ไลบรารี Azure ที่จำเป็นบางอันไม่มีให้บริการบนแพลตฟอร์ม MacOS! ดังนั้นจึงรวมไฟล์ข้อกำหนดแยกต่างหากสำหรับ MacOS ยกเว้นไลบรารีเหล่านี้:
แมคโอเอส:
pip3 install -r ./requirements_mac.txt
กลับไปที่สารบัญ
หลังจากติดตั้งแล้ว ให้รัน LARS โดยใช้:
cd web_app
python app.py # Use 'python3' on Linux/macOS
ไปที่ http://localhost:5000/ ในเบราว์เซอร์ของคุณ
ไดเร็กทอรีแอปพลิเคชันทั้งหมดที่ LARS ต้องการจะถูกสร้างขึ้นบนดิสก์
เซิร์ฟเวอร์ HF-Waitress จะเริ่มทำงานโดยอัตโนมัติและจะดาวน์โหลด LLM (Microsoft Phi-3-Mini-Instruct-44) ในการรันครั้งแรก ซึ่งอาจใช้เวลาสักครู่ขึ้นอยู่กับความเร็วการเชื่อมต่ออินเทอร์เน็ตของคุณ
ในการสืบค้นครั้งแรก โมเดลการฝัง (all-mpnet-base-v2) จะถูกดาวน์โหลดจาก HuggingFace Hub ซึ่งน่าจะใช้เวลาสั้นๆ
กลับไปที่สารบัญ
บนวินโดวส์:
ดาวน์โหลด Microsoft Visual Studio Build Tools 2022 จากเว็บไซต์อย่างเป็นทางการ - "เครื่องมือสำหรับ Visual Studio"
หมายเหตุ: เมื่อทำการติดตั้งข้างต้น ตรวจสอบให้แน่ใจว่าได้เลือกส่วนประกอบต่อไปนี้:
Desktop development with C++
# Then from the "Optional" category on the right, make sure to select the following:
MSVC C++ x64/x86 build tools
C++ CMake tools for Windows
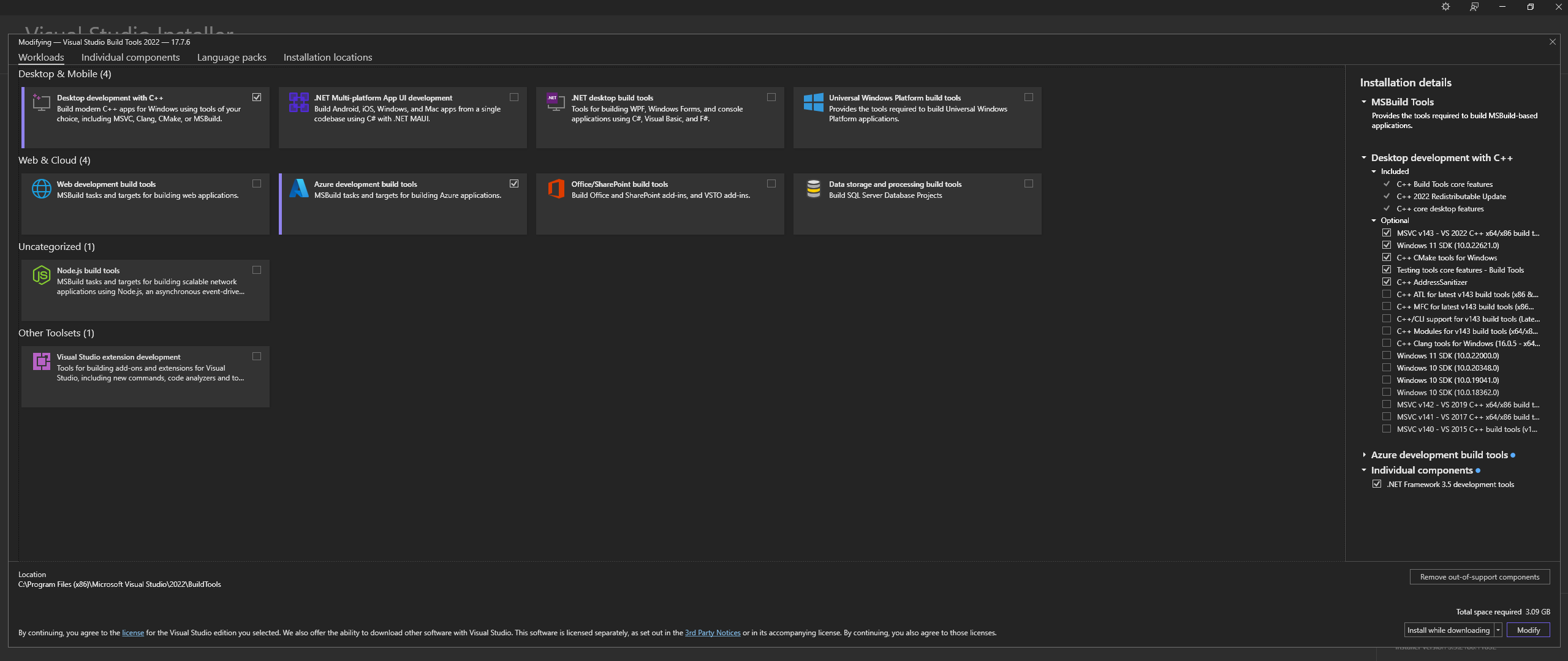
Desktop development with C++ และเลือก MSVC and C++ CMake Optionals ตามที่ระบุไว้ข้างต้นบน Linux (บน Ubuntu และ Debian) ให้ติดตั้งแพ็คเกจต่อไปนี้:
sudo apt-get update
sudo apt-get install -y software-properties-common build-essential libffi-dev libssl-dev cmake
ดาวน์โหลดจาก Repo อย่างเป็นทางการ:
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
ติดตั้ง CMAKE บน Windows จากเว็บไซต์อย่างเป็นทางการ
C:Program FilesCMakebinสร้าง llama.cpp ด้วย CMAKE:
หมายเหตุ: เพื่อการคอมไพล์ที่เร็วขึ้น ให้เพิ่มอาร์กิวเมนต์ -j เพื่อรันหลายงานพร้อมกัน ตัวอย่างเช่น cmake --build build --config Release -j 8 จะรัน 8 งานแบบขนาน
สร้างด้วย CUDA:
cmake -B build -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES="52;61;70;75;80;86"
cmake --build build --config Release
cmake -B build
cmake --build build --config Release
หากคุณประสบปัญหาเมื่อพยายามเรียกใช้ CMake -B build ให้ตรวจสอบขั้นตอนการแก้ไขปัญหาการติดตั้ง CMake โดยละเอียดด้านล่าง
เพิ่มในเส้นทาง:
path_to_cloned_repollama.cppbuildbinRelease
ตรวจสอบการติดตั้งผ่านทางเทอร์มินัล:
llama-server
ติดตั้งไดรเวอร์ NVIDIA GPU
ติดตั้ง Nvidia CUDA Toolkit - LARS ที่สร้างและทดสอบกับ v12.2 และ v12.4
ตรวจสอบการติดตั้งผ่านทางเทอร์มินัล:
nvcc -V
nvidia-smi
แก้ไข CMAKE-CUDA (สำคัญมาก!):
คัดลอกไฟล์ทั้งสี่ไฟล์จากไดเร็กทอรีต่อไปนี้:
C:Program FilesNVIDIA GPU Computing ToolkitCUDAv12.2extrasvisual_studio_integrationMSBuildExtensions
และวางลงในไดเร็กทอรีต่อไปนี้:
C:Program Files (x86)Microsoft Visual Studio2022BuildToolsMSBuildMicrosoftVCv170BuildCustomizations
นี่เป็นทางเลือกเสริม แต่ขอแนะนำอย่างยิ่ง - รองรับเฉพาะ PDF เท่านั้น หากการตั้งค่านี้ไม่สมบูรณ์
หน้าต่าง:
ดาวน์โหลดจากเว็บไซต์อย่างเป็นทางการ
เพิ่มใน PATH ไม่ว่าจะผ่านทาง:
การตั้งค่าระบบขั้นสูง -> ตัวแปรสภาพแวดล้อม -> ตัวแปรระบบ -> แก้ไขตัวแปรเส้นทาง -> เพิ่มด้านล่าง (เปลี่ยนตามตำแหน่งการติดตั้งของคุณ):
C:Program FilesLibreOfficeprogram
หรือผ่าน PowerShell:
Set PATH=%PATH%;C:Program FilesLibreOfficeprogram
Linux บน Ubuntu และ Debian - ดาวน์โหลดจากเว็บไซต์อย่างเป็นทางการหรือติดตั้งผ่านเทอร์มินัล:
sudo apt-get update
sudo apt-get install -y libreoffice
Fedora และ distro ที่ใช้ RPM อื่นๆ - ดาวน์โหลดจากเว็บไซต์อย่างเป็นทางการหรือติดตั้งผ่านเทอร์มินัล:
sudo dnf update
sudo dnf install libreoffice
MacOS - ดาวน์โหลดจากเว็บไซต์อย่างเป็นทางการหรือติดตั้งผ่าน Homebrew:
brew install --cask libreoffice
ตรวจสอบการติดตั้ง:
บน Windows และ MacOS: เรียกใช้แอปพลิเคชัน LibreOffice
บน Linux ผ่านทางเทอร์มินัล:
libreoffice --version
LARS ใช้ไลบรารี pdf2image Python เพื่อแปลงแต่ละหน้าของเอกสารให้เป็นรูปภาพตามที่จำเป็นสำหรับ OCR ไลบรารีนี้เป็นตัวห่อหุ้มยูทิลิตี้ Poppler ซึ่งจัดการกระบวนการแปลง
หน้าต่าง:
ดาวน์โหลดจาก Repo อย่างเป็นทางการ
เพิ่มใน PATH ไม่ว่าจะผ่านทาง:
การตั้งค่าระบบขั้นสูง -> ตัวแปรสภาพแวดล้อม -> ตัวแปรระบบ -> แก้ไขตัวแปรเส้นทาง -> เพิ่มด้านล่าง (เปลี่ยนตามตำแหน่งการติดตั้งของคุณ):
path_to_installationpoppler_versionLibrarybin
หรือผ่าน PowerShell:
Set PATH=%PATH%;path_to_installationpoppler_versionLibrarybin
ลินุกซ์:
sudo apt-get update
sudo apt-get install -y poppler-utils wget
นี่เป็นการพึ่งพาเพิ่มเติม - Tesseract-OCR ไม่ได้ใช้งานใน LARS แต่วิธีการใช้งานนั้นมีอยู่ในซอร์สโค้ด
หน้าต่าง:
ดาวน์โหลด Tesseract-OCR สำหรับ Windows ผ่าน UB-Mannheim
เพิ่มใน PATH ไม่ว่าจะผ่านทาง:
การตั้งค่าระบบขั้นสูง -> ตัวแปรสภาพแวดล้อม -> ตัวแปรระบบ -> แก้ไขตัวแปรเส้นทาง -> เพิ่มด้านล่าง (เปลี่ยนตามตำแหน่งการติดตั้งของคุณ):
C:Program FilesTesseract-OCR
หรือผ่าน PowerShell:
Set PATH=%PATH%;C:Program FilesTesseract-OCR
กลับไปที่สารบัญ
LARS ได้รับการสร้างและทดสอบด้วย Python v3.11.x
ติดตั้ง Python v3.11.x บน Windows:
ดาวน์โหลด v3.11.9 จากเว็บไซต์อย่างเป็นทางการ
ระหว่างการติดตั้ง ตรวจสอบให้แน่ใจว่าคุณได้ทำเครื่องหมายที่ "เพิ่ม Python 3.11 ไปยัง PATH" หรือเพิ่มด้วยตนเองในภายหลัง โดยผ่านทาง:
การตั้งค่าระบบขั้นสูง -> ตัวแปรสภาพแวดล้อม -> ตัวแปรระบบ -> แก้ไขตัวแปรเส้นทาง -> เพิ่มด้านล่าง (เปลี่ยนตามตำแหน่งการติดตั้งของคุณ):
C:Usersuser_nameAppDataLocalProgramsPythonPython311
หรือผ่าน PowerShell:
Set PATH=%PATH%;C:Usersuser_nameAppDataLocalProgramsPythonPython311
ติดตั้ง Python v3.11.x บน Linux (บน Ubuntu และ Debian):
sudo add-apt-repository ppa:deadsnakes/ppa -y
sudo apt-get update
sudo apt-get install -y python3.11 python3.11-venv python3.11-dev
sudo python3.11 -m ensurepip
ตรวจสอบการติดตั้งผ่านทางเทอร์มินัล:
python3 --version
หากคุณพบข้อผิดพลาดกับ pip install ให้ลองดังต่อไปนี้:
ลบหมายเลขเวอร์ชัน:
==version.number ตัวอย่างเช่น:urllib3==2.0.4urllib3สร้างและใช้สภาพแวดล้อมเสมือน Python:
ขอแนะนำให้ใช้สภาพแวดล้อมเสมือนเพื่อหลีกเลี่ยงความขัดแย้งกับโครงการ Python อื่น ๆ
หน้าต่าง:
สร้างสภาพแวดล้อมเสมือน Python (venv):
python -m venv larsenv
เปิดใช้งานและใช้งาน venv ในภายหลัง:
.larsenvScriptsactivate
ปิดการใช้งาน venv เมื่อเสร็จแล้ว:
deactivate
ลินุกซ์และแมคโอเอส:
สร้างสภาพแวดล้อมเสมือน Python (venv):
python3 -m venv larsenv
เปิดใช้งานและใช้งาน venv ในภายหลัง:
source larsenv/bin/activate
ปิดการใช้งาน venv เมื่อเสร็จแล้ว:
deactivate
หากปัญหายังคงมีอยู่ ให้พิจารณาเปิดปัญหาบนที่เก็บ LARS GitHub เพื่อรับการสนับสนุน
CMake nmake failed เมื่อพยายามสร้าง llama.cpp ดังต่อไปนี้: 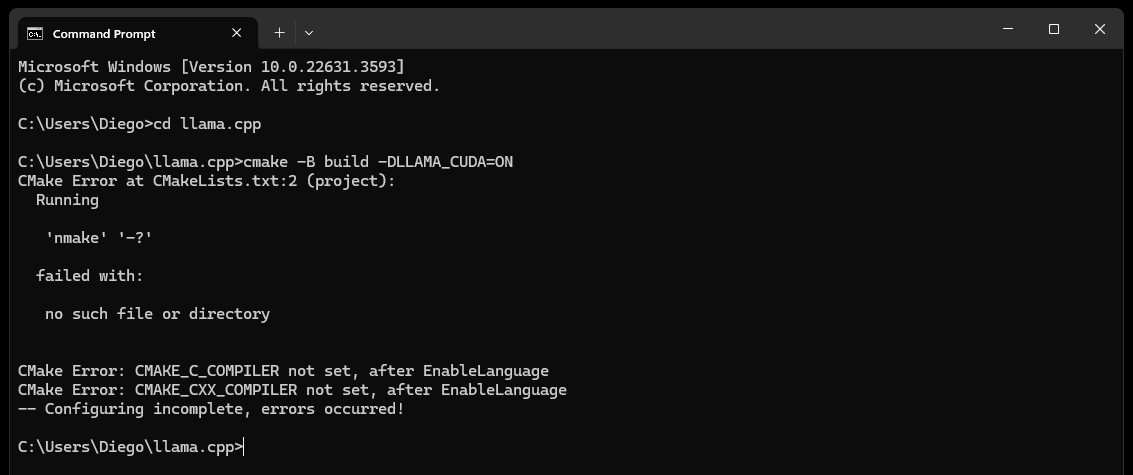
โดยทั่วไปจะบ่งชี้ปัญหาเกี่ยวกับเครื่องมือสร้าง Microsoft Visual Studio ของคุณ เนื่องจาก CMake ไม่พบเครื่องมือ nmake ซึ่งเป็นส่วนหนึ่งของเครื่องมือสร้าง Microsoft Visual Studio ลองทำตามขั้นตอนด้านล่างเพื่อแก้ไขปัญหา:
ตรวจสอบให้แน่ใจว่าได้ติดตั้งเครื่องมือสร้าง Visual Studio แล้ว:
ตรวจสอบให้แน่ใจว่าคุณได้ติดตั้งเครื่องมือสร้าง Visual Studio รวมถึง nmake คุณสามารถติดตั้งเครื่องมือเหล่านี้ผ่าน Visual Studio Installer โดยเลือก Desktop development with C++ และ MSVC and C++ CMake Optionals
ตรวจสอบขั้นตอนที่ 0 ของส่วนการพึ่งพา โดยเฉพาะภาพหน้าจอในนั้น
ตรวจสอบตัวแปรสภาพแวดล้อม:
C:Program Files (x86)Microsoft Visual Studio2019CommunityVCAuxiliaryBuild
C:Program Files (x86)Microsoft Visual Studio2019CommunityCommon7IDE
C:Program Files (x86)Microsoft Visual Studio2019CommunityCommon7Tools
ใช้พรอมต์คำสั่งสำหรับนักพัฒนา:
เปิด "พรอมต์คำสั่งสำหรับนักพัฒนาซอฟต์แวร์สำหรับ Visual Studio" ซึ่งตั้งค่าตัวแปรสภาพแวดล้อมที่จำเป็นสำหรับคุณ
คุณสามารถค้นหาพร้อมท์นี้ได้จากเมนูเริ่มภายใต้ Visual Studio
ตั้งค่าตัวสร้าง CMake:
cmake -G "NMake Makefiles" -B build -DLLAMA_CUDA=ON
หากปัญหายังคงมีอยู่ ให้พิจารณาเปิดปัญหาบนที่เก็บ LARS GitHub เพื่อรับการสนับสนุน
ในที่สุด (หลังจากผ่านไปประมาณ 60 วินาที) คุณจะเห็นการแจ้งเตือนบนหน้าเว็บที่ระบุข้อผิดพลาด:
Failed to start llama.cpp local-server
สิ่งนี้บ่งชี้ว่าการเรียกใช้ครั้งแรกเสร็จสมบูรณ์แล้ว มีการสร้างไดเร็กทอรีแอปทั้งหมดแล้ว แต่ไม่มี LLM อยู่ในไดเร็กทอรี models และตอนนี้อาจถูกย้ายไปยังไดเร็กทอรีนั้นแล้ว
ย้าย LLM ของคุณ (รูปแบบไฟล์ใดๆ ที่ llama.cpp สนับสนุน โดยเฉพาะอย่างยิ่ง GGUF) ไปยัง models ที่สร้างขึ้นใหม่ ซึ่งอยู่ในตำแหน่งเริ่มต้นตามค่าเริ่มต้น:
C:/web_app_storage/models/app/storage/models/app/models เมื่อคุณวาง LLM ของคุณใน models ที่เหมาะสมแล้ว ให้รีเฟรช http://localhost:5000/
คุณจะได้รับการแจ้งเตือนข้อผิดพลาดอีกครั้งว่า Failed to start llama.cpp local-server หลังจากผ่านไปประมาณ 60 วินาที
เนื่องจากตอนนี้คุณต้องเลือก LLM ของคุณในเมนู Settings LARS
ยอมรับการแจ้งเตือนและคลิกที่ไอคอนรูปเฟือง Settings ที่มุมขวาบน
ในแท็บ LLM Selection ให้เลือก LLM ของคุณและรูปแบบ Prompt-Template ที่เหมาะสมจากเมนูแบบเลื่อนลงที่เหมาะสม
แก้ไขการตั้งค่าขั้นสูงเพื่อตั้งค่าตัวเลือก GPU อย่างถูกต้อง Context-Length และทางเลือก ขีดจำกัดการสร้างโทเค็น ( Maximum tokens to predict ) สำหรับ LLM ที่คุณเลือก
กด Save และหากไม่มีการทริกเกอร์การรีเฟรชอัตโนมัติ ให้รีเฟรชเพจด้วยตนเอง
หากดำเนินการทุกขั้นตอนอย่างถูกต้อง การตั้งค่าครั้งแรกจะเสร็จสมบูรณ์ และ LARS ก็พร้อมใช้งานแล้ว
LARS จะจดจำการตั้งค่า LLM ของคุณเพื่อใช้ในภายหลัง
กลับไปที่สารบัญ
รูปแบบเอกสารที่รองรับ:
หากติดตั้งและเพิ่ม LibreOffice ลงใน PATH ตามรายละเอียดในขั้นตอนที่ 4 ของส่วนการพึ่งพา รูปแบบต่อไปนี้จะได้รับการสนับสนุน:
หากไม่ได้ตั้งค่า LibreOffice ระบบจะรองรับเฉพาะ PDF เท่านั้น
ตัวเลือก OCR สำหรับการแยกข้อความ:
LARS มีสามวิธีในการแยกข้อความจากเอกสาร ซึ่งรองรับประเภทเอกสารและคุณภาพต่างๆ:
การแยกข้อความในเครื่อง: ใช้ PyPDF2 เพื่อการแยกข้อความจาก PDF ที่ไม่ได้สแกนอย่างมีประสิทธิภาพ เหมาะสำหรับการประมวลผลที่รวดเร็วเมื่อความแม่นยำสูงไม่สำคัญ หรือจำเป็นต้องมีการประมวลผลเฉพาะที่
Azure ComputerVision OCR - เพิ่มความแม่นยำในการแยกข้อความและรองรับเอกสารที่สแกน มีประโยชน์สำหรับการจัดการเค้าโครงเอกสารมาตรฐาน เสนอ Tier ฟรีที่เหมาะสำหรับการทดลองใช้ครั้งแรกและการใช้งานปริมาณน้อย โดยจำกัดไว้ที่ 5,000 ธุรกรรม/เดือน ที่ 20 ธุรกรรม/นาที
Azure AI Document Intelligence OCR - ดีที่สุดสำหรับเอกสารที่มีโครงสร้างที่ซับซ้อน เช่น ตาราง ตัวแยกวิเคราะห์แบบกำหนดเองใน LARS ปรับกระบวนการแยกให้เหมาะสม
หมายเหตุ:
ตัวเลือก Azure OCR มีค่าใช้จ่าย API ในกรณีส่วนใหญ่ และไม่ได้รวมเข้ากับ LARS
รุ่นฟรีที่จำกัดสำหรับ ComputerVision OCR มีให้ใช้งานตามลิงก์ด้านบน บริการนี้มีราคาถูกกว่าโดยรวมแต่ช้ากว่าและอาจใช้ไม่ได้กับรูปแบบเอกสารที่ไม่ได้มาตรฐาน (นอกเหนือจาก A4 เป็นต้น)
พิจารณาประเภทเอกสารและความต้องการด้านความแม่นยำของคุณเมื่อเลือกตัวเลือก OCR
LLM:
ปัจจุบันรองรับเฉพาะ LLM ท้องถิ่นเท่านั้น
เมนู Settings มีตัวเลือกมากมายสำหรับผู้ใช้ขั้นสูงในการกำหนดค่าและเปลี่ยนแปลง LLM ผ่านแท็บ LLM Selection
หมายเหตุหากใช้ llama.cpp: สำคัญมาก: เลือกรูปแบบเทมเพลตพร้อมท์ที่เหมาะสมสำหรับ LLM ที่คุณใช้งานอยู่
LLM ที่ได้รับการฝึกอบรมสำหรับรูปแบบเทมเพลตพร้อมท์ต่อไปนี้ได้รับการสนับสนุนผ่านทาง llama.cpp:
ปรับแต่งการตั้งค่าการกำหนดค่า Core ผ่าน Advanced Settings (ทริกเกอร์ LLM-reload และ page-refresh):
ปรับแต่งการตั้งค่าเพื่อเปลี่ยนพฤติกรรมการตอบสนองได้ตลอดเวลา:
การฝังโมเดลและฐานข้อมูลเวกเตอร์:
LARS มีโมเดลการฝังสี่โมเดล:
ยกเว้นการฝัง Azure-OpenAI โมเดลอื่นๆ ทั้งหมดจะทำงานภายในเครื่องและไม่มีค่าใช้จ่าย ในการรันครั้งแรก โมเดลเหล่านี้จะถูกดาวน์โหลดจาก HuggingFace Hub นี่เป็นการดาวน์โหลดเพียงครั้งเดียว และจะมีการนำเสนอในเครื่องในภายหลัง
ผู้ใช้สามารถสลับระหว่างโมเดลการฝังเหล่านี้ได้ตลอดเวลาผ่านแท็บ VectorDB & Embedding Models ในเมนู Settings
ตารางที่โหลดเอกสาร: ในเมนู Settings ตารางจะแสดงสำหรับโมเดลการฝังที่เลือก โดยแสดงรายการเอกสารที่ฝังอยู่ในฐานข้อมูลเวกเตอร์ที่เกี่ยวข้อง หากมีการโหลดเอกสารหลายครั้ง ตารางนี้จะมีรายการหลายรายการ ซึ่งอาจเป็นประโยชน์สำหรับการแก้ไขข้อบกพร่องใดๆ
การล้าง VectorDB: ใช้ปุ่ม Reset และให้การยืนยันเพื่อล้างฐานข้อมูลเวกเตอร์ที่เลือก ซึ่งจะสร้าง vectorDB บนดิสก์ใหม่สำหรับโมเดลการฝังที่เลือก vectorDB เก่ายังคงถูกเก็บรักษาไว้และอาจเปลี่ยนกลับเป็นได้โดยการแก้ไขไฟล์ config.json ด้วยตนเอง
แก้ไขระบบพร้อมท์:
System-Prompt ทำหน้าที่เป็นคำสั่งให้กับ LLM สำหรับการสนทนาทั้งหมด
LARS ให้ผู้ใช้สามารถแก้ไข System-Prompt ผ่านทางเมนู Settings โดยเลือกตัวเลือก Custom จากเมนูแบบเลื่อนลงในแท็บ System Prompt
การเปลี่ยนแปลง System-Prompt จะเริ่มการแชทใหม่
บังคับเปิด/ปิด RAG:
ผ่านเมนู Settings ผู้ใช้สามารถบังคับเปิดหรือปิดใช้งาน RAG (Retrieval Augmented Generation - การใช้เนื้อหาจากเอกสารของคุณเพื่อปรับปรุงการตอบสนองที่สร้างโดย LLM) เมื่อใดก็ตามที่จำเป็น
ซึ่งมักจะมีประโยชน์สำหรับวัตถุประสงค์ในการประเมินการตอบสนองของ LLM ในทั้งสองสถานการณ์
การบังคับปิดใช้จะปิดคุณลักษณะการระบุแหล่งที่มาด้วย
การตั้งค่าเริ่มต้นซึ่งใช้ NLP เพื่อพิจารณาว่าเมื่อใดควรและไม่ควรดำเนินการ RAG เป็นตัวเลือกที่แนะนำ
การตั้งค่านี้สามารถเปลี่ยนแปลงได้ตลอดเวลา
ประวัติการแชท:
ใช้เมนูประวัติการแชทที่ด้านซ้ายบนเพื่อเรียกดูและสนทนาต่อก่อนหน้านี้
สำคัญมาก: โปรดระวังเทมเพลตพรอมต์ที่ไม่ตรงกันเมื่อสนทนาต่อก่อนหน้านี้! ใช้ไอคอน Information ที่ด้านบนขวาเพื่อให้แน่ใจว่า LLM ที่ใช้ในการสนทนาก่อนหน้า และ LLM ที่ใช้งานอยู่ในปัจจุบัน ทั้งคู่ใช้รูปแบบเทมเพลตพร้อมท์เดียวกัน!
การให้คะแนนของผู้ใช้:
คำตอบแต่ละรายการอาจได้รับการจัดอันดับในระดับ 5 คะแนนโดยผู้ใช้เมื่อใดก็ได้
ข้อมูลการให้คะแนนจะถูกเก็บไว้ในฐานข้อมูล chat-history.db SQLite3 ที่อยู่ในไดเร็กทอรีแอป:
C:/web_app_storage/app/storage/appข้อมูลการให้คะแนนมีค่ามากสำหรับการประเมินและปรับแต่งเครื่องมือสำหรับขั้นตอนการทำงานของคุณ
สิ่งที่ควรทำและไม่ควรทำ:
กลับไปที่สารบัญ
หากการแชทผิดพลาดหรือมีการตอบสนองแปลกๆ เพียงลองเริ่ม New Chat ผ่านเมนูด้านซ้ายบน
หรือเริ่มต้นการแชทใหม่โดยเพียงแค่รีเฟรชหน้า
หากประสบปัญหากับการอ้างอิงหรือประสิทธิภาพของ RAG ให้ลองรีเซ็ต vectorDB ตามที่อธิบายไว้ในขั้นตอนที่ 4 ของคู่มือผู้ใช้ทั่วไปด้านบน
หากปัญหาแอปพลิเคชันใด ๆ เกิดขึ้นและไม่ได้รับการแก้ไขโดยการเริ่มแชทใหม่หรือรีสตาร์ท LARS ให้ลองลบไฟล์ config.json โดยทำตามขั้นตอนด้านล่าง:
CTRL+Cconfig.json ที่อยู่ใน LARS/web_app (ไดเรกทอรีเดียวกันกับ app.py )สำหรับปัญหาข้อมูลและการอ้างอิงที่รุนแรงซึ่งไม่ได้รับการแก้ไขแม้จะรีเซ็ต VectorDB ตามที่อธิบายไว้ในขั้นตอนที่ 4 ของคู่มือผู้ใช้ทั่วไปข้างต้น ให้ทำตามขั้นตอนต่อไปนี้:
CTRL+CC:/web_app_storage/app/storage/appหากปัญหายังคงมีอยู่ ให้พิจารณาเปิดปัญหาบนที่เก็บ LARS GitHub เพื่อรับการสนับสนุน
กลับไปที่สารบัญ
LARS ได้รับการปรับให้เข้ากับสภาพแวดล้อมการใช้งานคอนเทนเนอร์ Docker ผ่านอิมเมจสองภาพที่แยกจากกันดังต่อไปนี้:
ทั้งสองมีข้อกำหนดที่แตกต่างกัน โดยแบบแรกคือการปรับใช้ที่ง่ายกว่า แต่ประสบปัญหาประสิทธิภาพในการอนุมานที่ช้ากว่ามากเนื่องจาก CPU และหน่วยความจำ DDR ทำหน้าที่เป็นคอขวด
แม้ว่าจะไม่จำเป็นอย่างชัดเจน แต่ประสบการณ์บางอย่างกับคอนเทนเนอร์ Docker และความคุ้นเคยกับแนวคิดของคอนเทนเนอร์และการจำลองเสมือนจะมีประโยชน์มากในส่วนนี้
เริ่มต้นด้วยขั้นตอนการตั้งค่าทั่วไปสำหรับทั้งสอง:
การติดตั้งนักเทียบท่า
CPU ของคุณควรรองรับการจำลองเสมือนและควรเปิดใช้งานใน BIOS/UEFI ของระบบของคุณ
ดาวน์โหลดและติดตั้ง Docker Desktop
หากบน Windows คุณอาจต้องติดตั้ง Windows Subsystem สำหรับ Linux หากยังไม่มี โดยเปิด PowerShell ในฐานะผู้ดูแลระบบแล้วเรียกใช้สิ่งต่อไปนี้:
wsl --install
ตรวจสอบให้แน่ใจว่า Docker Desktop เปิดใช้งานอยู่ จากนั้นเปิด Command Prompt / Terminal และดำเนินการคำสั่งต่อไปนี้เพื่อให้แน่ใจว่า Docker ได้รับการติดตั้งและเปิดใช้งานอย่างถูกต้อง:
docker ps
สร้างโวลุ่มพื้นที่จัดเก็บ Docker ซึ่งจะแนบกับคอนเทนเนอร์ LARS ขณะรันไทม์:
การสร้างโวลุ่มพื้นที่จัดเก็บข้อมูลเพื่อใช้กับคอนเทนเนอร์ LARS มีข้อได้เปรียบอย่างมาก เนื่องจากจะทำให้คุณสามารถอัปเกรดคอนเทนเนอร์ LARS ให้เป็นเวอร์ชันที่ใหม่กว่า หรือสลับระหว่างตัวแปรคอนเทนเนอร์ CPU และ GPU ในขณะที่คงการตั้งค่า ประวัติการแชท และฐานข้อมูลเวกเตอร์ทั้งหมดของคุณได้อย่างราบรื่น .
ดำเนินการคำสั่งต่อไปนี้ใน Command Prompt / Terminal:
docker volume create lars_storage_volue
วอลุ่มนี้จะถูกแนบกับคอนเทนเนอร์ LARS ในภายหลังขณะรันไทม์ สำหรับตอนนี้ให้ดำเนินการสร้างอิมเมจ LARS ในขั้นตอนด้านล่าง
ใน Command Prompt / Terminal ให้รันคำสั่งต่อไปนี้:
git clone https://github.com/abgulati/LARS # skip if already done
cd LARS # skip if already done
cd dockerized
docker build -t lars-no-gpu .
# Once the build is complete, run the container:
docker run -p 5000:5000 -p 8080:8080 -v lars_storage:/app/storage lars-no-gpu
เมื่อเสร็จแล้ว ไปที่ http://localhost:5000/ ในเบราว์เซอร์ของคุณ และปฏิบัติตามส่วนที่เหลือของขั้นตอนการรันครั้งแรกและคู่มือผู้ใช้
ส่วนการแก้ไขปัญหามีผลกับ Container-LARS เช่นกัน
ข้อกำหนด (นอกเหนือจาก Docker):
Compatible Nvidia GPU(s)
Nvidia GPU drivers
Nvidia CUDA Toolkit v12.2
สำหรับ Linux คุณตั้งค่าทั้งหมดตามข้างต้นแล้ว ดังนั้นข้ามขั้นตอนถัดไปและตรงไปยังขั้นตอนการสร้างและรันเพิ่มเติมด้านล่าง
หากใช้บน Windows และหากนี่เป็นครั้งแรกที่คุณใช้งานคอนเทนเนอร์ Nvidia GPU บน Docker ให้รัดเข็มขัดไว้เพราะนี่จะเป็นการนั่งที่ค่อนข้างสนุก (เครื่องดื่มสุดโปรดหรือสามอย่างขอแนะนำ!)
เสี่ยงต่อความซ้ำซ้อนอย่างมาก ก่อนดำเนินการต่อ ตรวจสอบให้แน่ใจว่ามีการขึ้นต่อกันต่อไปนี้:
Compatible Nvidia GPU(s)
Nvidia GPU drivers
Nvidia CUDA Toolkit v12.2
Docker Desktop
Windows Subsystem for Linux (WSL)
โปรดดูส่วนการพึ่งพาของ Nvidia CUDA และส่วนการตั้งค่า Docker ด้านบนหากไม่แน่ใจ
หากมีสิ่งข้างต้นและตั้งค่าแล้ว คุณก็ดำเนินการต่อไปได้อย่างชัดเจน
เปิดแอป Microsoft Store บนพีซีของคุณ และดาวน์โหลดและติดตั้ง Ubuntu 22.04.3 LTS (ต้องตรงกับเวอร์ชันออนไลน์ 2 ใน dockerfile)
ใช่ คุณอ่านข้อความข้างต้นแล้ว: ดาวน์โหลดและติดตั้ง Ubuntu จากแอป Microsoft store โปรดดูภาพหน้าจอด้านล่าง:
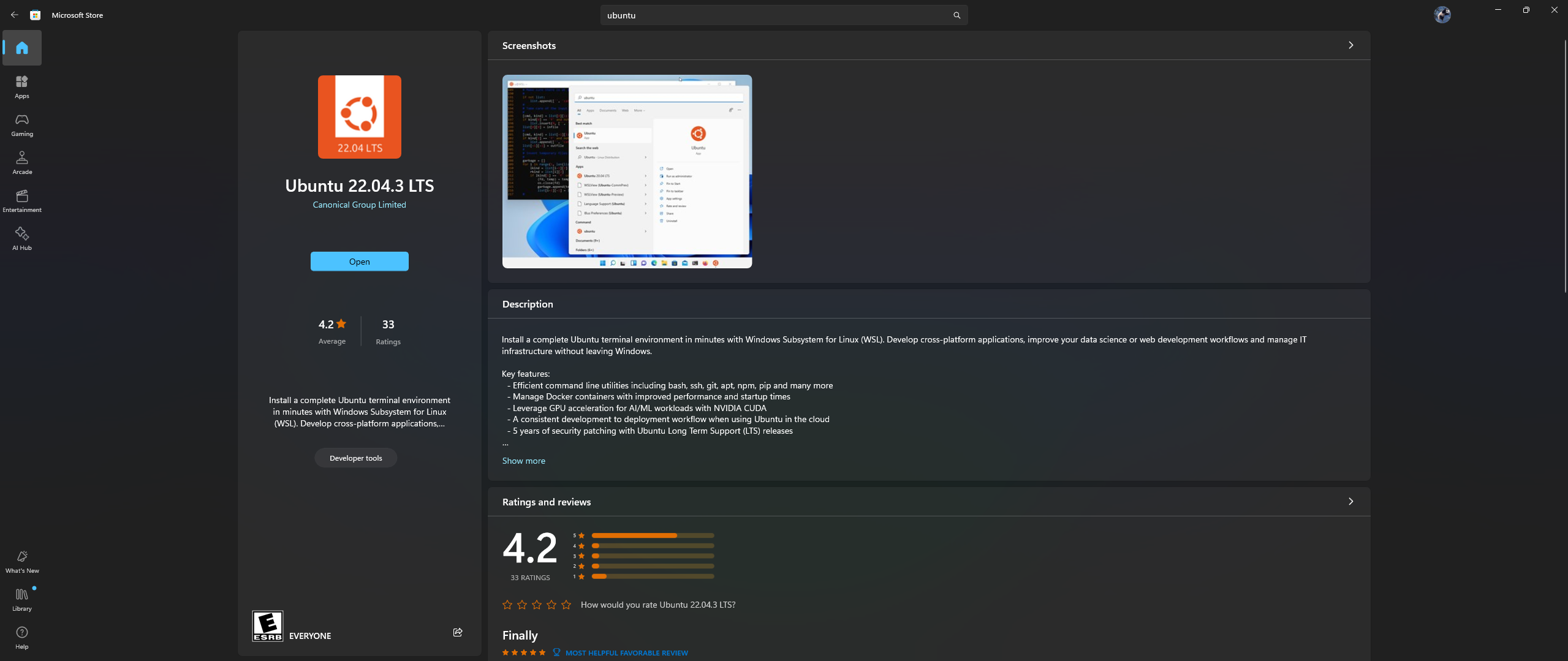
ถึงเวลาติดตั้ง Nvidia Container Toolkit ภายใน Ubuntu แล้วทำตามขั้นตอนด้านล่าง:
เปิดเชลล์ Ubuntu ใน Windows โดยค้นหา Ubuntu ในเมนู Start หลังจากการติดตั้งด้านบนเสร็จสิ้น
ในบรรทัดคำสั่ง Ubuntu ที่เปิดขึ้น ให้ทำตามขั้นตอนต่อไปนี้:
กำหนดค่าพื้นที่เก็บข้อมูลที่ใช้งานจริง:
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list |
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' |
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
อัปเดตรายการแพ็กเกจจากพื้นที่เก็บข้อมูล & ติดตั้งแพ็คเกจ Nvidia Container Toolkit:
sudo apt-get update && apt-get install -y nvidia-container-toolkit
กำหนดค่ารันไทม์คอนเทนเนอร์โดยใช้คำสั่ง nvidia-ctk ซึ่งจะแก้ไขไฟล์ /etc/docker/daemon.json เพื่อให้ Docker สามารถใช้ Nvidia Container Runtime ได้:
sudo nvidia-ctk runtime configure --runtime=docker
รีสตาร์ท Docker daemon:
sudo systemctl restart docker
ตอนนี้การตั้งค่า Ubuntu ของคุณเสร็จสมบูรณ์แล้ว ถึงเวลาดำเนินการรวม WSL และ Docker ให้เสร็จสมบูรณ์:
เปิดหน้าต่าง PowerShell ใหม่และตั้งค่าการติดตั้ง Ubuntu นี้เป็นค่าเริ่มต้น WSL:
wsl --list
wsl --set-default Ubuntu-22.04 # if not already marked as Default
ไปที่ Docker Desktop -> Settings -> Resources -> WSL Integration -> ตรวจสอบค่าเริ่มต้นและการรวม Ubuntu 22.04 อ้างถึงภาพหน้าจอด้านล่าง:
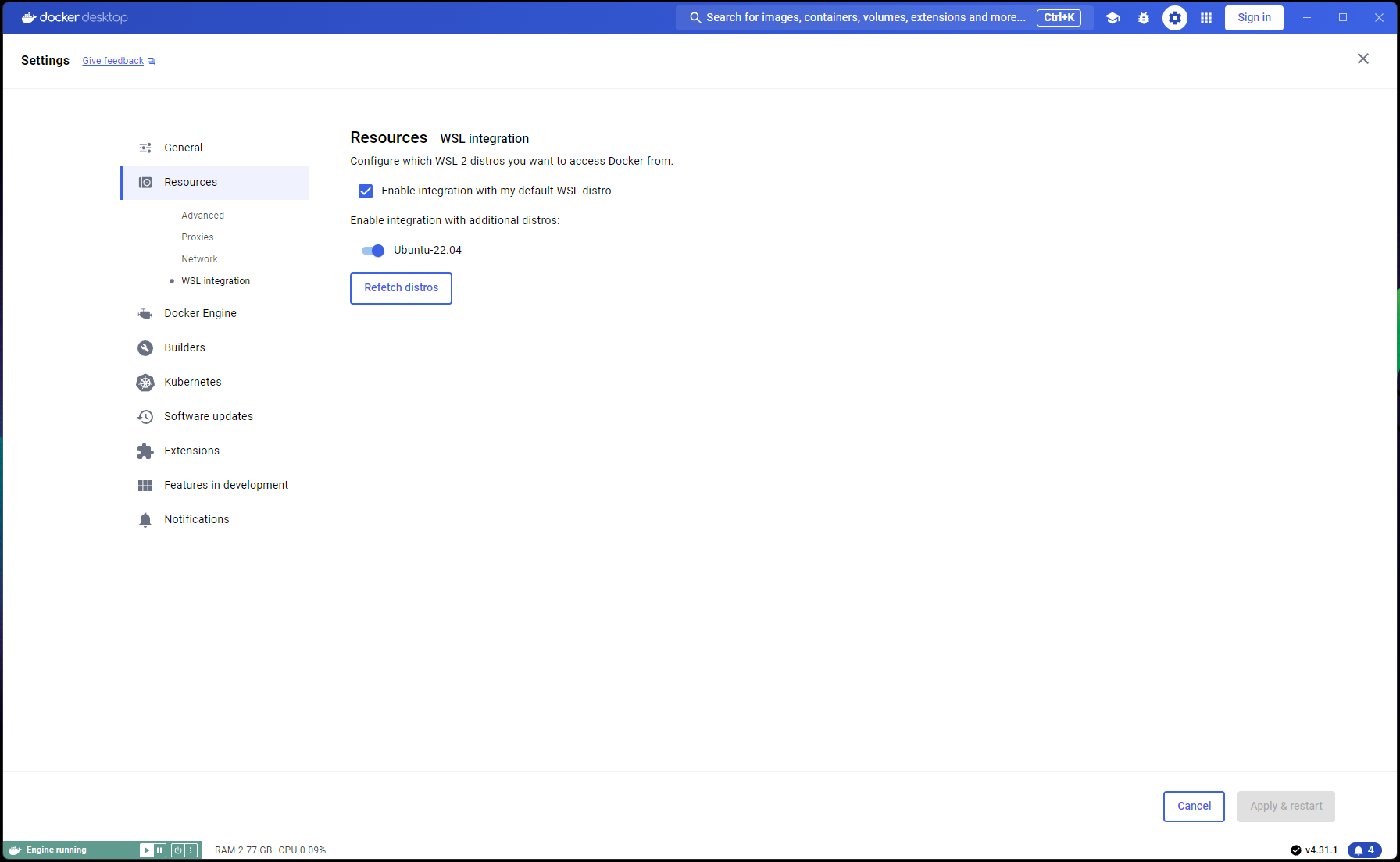
ตอนนี้หากทุกอย่างถูกต้องแล้ว คุณก็พร้อมที่จะสร้างและใช้งานคอนเทนเนอร์แล้ว!
ใน Command Prompt / Terminal ให้รันคำสั่งต่อไปนี้:
git clone https://github.com/abgulati/LARS # skip if already done
cd LARS # skip if already done
cd dockerized_nvidia_cuda_gpu
docker build -t lars-nvcuda .
# Once the build is complete, run the container:
docker run --gpus all -p 5000:5000 -p 8080:8080 -v lars_storage:/app/storage lars-nvcuda
เมื่อเสร็จแล้ว ไปที่ http://localhost:5000/ ในเบราว์เซอร์ของคุณ และปฏิบัติตามส่วนที่เหลือของขั้นตอนการรันครั้งแรกและคู่มือผู้ใช้
ส่วนการแก้ไขปัญหามีผลกับ Container-LARS เช่นกัน
ในกรณีที่คุณพบข้อผิดพลาดเกี่ยวกับเครือข่าย โดยเฉพาะอย่างยิ่งเกี่ยวกับที่เก็บแพ็กเกจที่ไม่พร้อมใช้งานเมื่อสร้างคอนเทนเนอร์ นี่เป็นปัญหาด้านเครือข่ายในส่วนของคุณซึ่งมักจะเกี่ยวข้องกับปัญหาไฟร์วอลล์
บน Windows ให้ไปที่ Control PanelSystem and SecurityWindows Defender FirewallAllowed apps หรือค้นหา Firewall ใน Start-Menu และไปที่ Allow an app through the firewall และให้แน่ใจว่า ```Docker Desktop Backend`` ได้รับอนุญาตผ่าน
ครั้งแรกที่คุณรัน LARS โมเดลการฝังตัวแปลงประโยคจะถูกดาวน์โหลด
ในสภาพแวดล้อมแบบคอนเทนเนอร์ บางครั้งการดาวน์โหลดนี้อาจเกิดปัญหาและส่งผลให้เกิดข้อผิดพลาดเมื่อคุณถามคำถาม
หากสิ่งนี้เกิดขึ้น เพียงไปที่เมนูการตั้งค่า LARS: Settings->VectorDB & Embedding Models และเปลี่ยน Embedding Model เป็น BGE-Base หรือ BGE-Large ซึ่งจะบังคับให้โหลดซ้ำและดาวน์โหลดซ้ำ
เมื่อเสร็จแล้วให้ถามคำถามอีกครั้งและการตอบกลับควรจะเกิดขึ้นตามปกติ
คุณสามารถเปลี่ยนกลับไปใช้โมเดลการฝังตัวแปลงประโยคได้ และปัญหาควรได้รับการแก้ไข
ตามที่ระบุไว้ในส่วนการแก้ไขปัญหาข้างต้น โมเดลที่ฝังไว้จะถูกดาวน์โหลดในครั้งแรกที่ LARS ทำงาน
ทางที่ดีควรบันทึกสถานะของคอนเทนเนอร์ก่อนปิดระบบ เพื่อไม่ให้ขั้นตอนการดาวน์โหลดนี้ซ้ำทุกครั้งที่เปิดใช้คอนเทนเนอร์ในภายหลัง
ในการทำเช่นนั้น ให้เปิด Command Prompt / Terminal อื่นและยอมรับการเปลี่ยนแปลงก่อนที่จะปิดคอนเทนเนอร์ LARS ที่ทำงานอยู่:
docker ps # note the container_id here
docker commit <container_ID> <new_image_name> # for new_image_name, I simply add 'pfr', for 'post-first-run' to the current image name, example: lars-nvcuda-pfr
สิ่งนี้จะสร้างรูปภาพที่อัปเดตซึ่งคุณสามารถใช้ในการรันครั้งต่อไป:
docker run --gpus all -p 5000:5000 -p 8080:8080 -v lars_storage:/app/storage lars-nvcuda-pfr
หมายเหตุ: เมื่อดำเนินการข้างต้นแล้ว หากคุณตรวจสอบพื้นที่ที่รูปภาพใช้ด้วย docker images คุณจะสังเกตเห็นว่ามีการใช้พื้นที่จำนวนมาก แต่อย่าใช้ขนาดที่นี่อย่างแท้จริง! ขนาดที่แสดงสำหรับแต่ละรูปภาพจะรวมขนาดรวมของเลเยอร์ทั้งหมดด้วย แต่เลเยอร์เหล่านั้นหลายเลเยอร์จะถูกแชร์ระหว่างรูปภาพ โดยเฉพาะอย่างยิ่งหากรูปภาพเหล่านั้นใช้รูปภาพพื้นฐานเดียวกัน หรือหากรูปภาพหนึ่งเป็นเวอร์ชันที่ผูกมัดกับอีกรูปภาพหนึ่ง หากต้องการดูว่าอิมเมจ Docker ของคุณใช้พื้นที่ดิสก์เท่าใด ให้ใช้:
docker system df
กลับไปที่สารบัญ
| หมวดหมู่ | งาน | สถานะ |
|---|---|---|
| การแก้ไขข้อบกพร่อง: | อันตรายจากการสร้างไฟล์ข้อความแบบ Zero-Byte - บางครั้งหาก OCR/Text-Extraction | - ภารกิจในอนาคต |
| คุณสมบัติที่เป็นประโยชน์: | ใช้งานง่ายเป็นศูนย์กลาง: | |
| การสลับ UI ระดับฟรีของ Azure CV-OCR | ✅ เสร็จเมื่อ 8 มิถุนายน 2567 | |
| ลบแชท | - ภารกิจในอนาคต | |
| เปลี่ยนชื่อแชท | - ภารกิจในอนาคต | |
| สคริปต์การติดตั้ง PowerShell | - ภารกิจในอนาคต | |
| สคริปต์การติดตั้ง Linux | - ภารกิจในอนาคต | |
| แบ็กเอนด์ที่อนุมาน Ollama LLM เป็นทางเลือกแทน llama.cpp | - ภารกิจในอนาคต | |
| การบูรณาการบริการ OCR จากผู้ให้บริการคลาวด์รายอื่น (GCP, AWS, OCI ฯลฯ) | - ภารกิจในอนาคต | |
| สลับ UI เพื่อละเว้นการแยกข้อความก่อนหน้าเมื่ออัปโหลดเอกสาร | - ภารกิจในอนาคต | |
| Modal-popup สำหรับการอัพโหลดไฟล์: ตัวเลือกการแยกข้อความแบบมิเรอร์จากการตั้งค่า, เขียนทับการส่งทั่วโลก, สลับเพื่อยืนยันการตั้งค่า | - ภารกิจในอนาคต | |
| ประสิทธิภาพเป็นศูนย์กลาง: | ||
| รองรับ Nvidia TensorRT-LLM AWQ | - ภารกิจในอนาคต | |
| งานวิจัย: | ตรวจสอบ Nvidia TensorRT-LLM: จำเป็นต้องสร้างเครื่องยนต์ AWQ-LLM TRT โดยเฉพาะสำหรับ GPU เป้าหมาย NvTensorRT-LLM นั้นเป็นระบบนิเวศของตัวเองและใช้งานได้กับ Python v3.10 เท่านั้น | ✅ เสร็จเมื่อ 13 มิถุนายน 2567 |
| OCR ท้องถิ่นพร้อม Vision LLM: MS-TrOCR (เสร็จสิ้น), Kosmos-2.5 (ลำดับความสำคัญสูง), Llava, Florence-2 | - อยู่ระหว่างดำเนินการอัปเดตในวันที่ 5 กรกฎาคม 2024 | |
| การปรับปรุง RAG: อันดับใหม่, RAPTOR, T-RAG | - ภารกิจในอนาคต | |
| ตรวจสอบการรวม GraphDB: การใช้ LLM เพื่อแยกข้อมูลความสัมพันธ์เอนทิตีจากเอกสารและเติม อัปเดต และบำรุงรักษา GraphDB | - ภารกิจในอนาคต |
กลับไปที่สารบัญ
ฉันหวังว่า LARS มีคุณค่าในงานของคุณ และฉันขอเชิญคุณให้สนับสนุนการพัฒนาอย่างต่อเนื่อง! หากคุณชื่นชอบเครื่องมือนี้และต้องการสนับสนุนการปรับปรุงในอนาคต โปรดพิจารณาบริจาค การสนับสนุนของคุณช่วยให้ฉันปรับปรุง LARS และเพิ่มคุณสมบัติใหม่ๆ ต่อไป
วิธีการบริจาค หากต้องการบริจาค โปรดใช้ลิงก์ต่อไปนี้ไปยัง PayPal ของฉัน:
บริจาคผ่าน PayPal
การมีส่วนร่วมของคุณได้รับการชื่นชมอย่างมากและจะนำไปใช้เป็นทุนในการพัฒนาต่อไป
กลับไปที่สารบัญ


