cambrian
1.0.0
เรื่องน่ารู้: การมองเห็นเกิดขึ้นในสัตว์ในยุคแคมเบรียน! นี่เป็นแรงบันดาลใจสำหรับชื่อโครงการ Cambrian ของเรา
eval/ โฟลเดอร์ย่อยสำหรับรายละเอียดเพิ่มเติมdataengine/ โฟลเดอร์ย่อยสำหรับรายละเอียดเพิ่มเติมปัจจุบันเรารองรับการฝึกอบรมเกี่ยวกับ TPU โดยใช้ TorchXLA
git clone https://github.com/cambrian-mllm/cambrian
cd cambrianconda create -n cambrian python=3.10 -y
conda activate cambrian
pip install --upgrade pip # enable PEP 660 support
pip install -e " .[tpu] " pip install torch~=2.2.0 torch_xla[tpu]~=2.2.0 -f https://storage.googleapis.com/libtpu-releases/index.html
git clone https://github.com/cambrian-mllm/cambrian
cd cambrianconda create -n cambrian python=3.10 -y
conda activate cambrian
pip install --upgrade pip # enable PEP 660 support
pip install " .[gpu] " ต่อไปนี้คือจุดตรวจ Cambrian ของเราพร้อมคำแนะนำวิธีใช้ตุ้มน้ำหนัก โมเดลของเรามีความเป็นเลิศในมิติต่างๆ ที่ระดับพารามิเตอร์ 8B, 13B และ 34B พวกเขาแสดงให้เห็นถึงประสิทธิภาพการแข่งขันเมื่อเทียบกับรุ่นที่เป็นกรรมสิทธิ์ของโอเพนซอร์ส เช่น GPT-4V, Gemini-Pro และ Grok-1.4V บนเกณฑ์มาตรฐานต่างๆ
| แบบอย่าง | #วิส. ต็อก | มม | SQA-I | คณิตวิสต้าเอ็ม | แผนภูมิQA | เอ็มเอ็มวีพี |
|---|---|---|---|---|---|---|
| GPT-4V | ยูเอ็นเค | 75.8 | - | 49.9 | 78.5 | 50.0 |
| ราศีเมถุน-1.0 โปร | ยูเอ็นเค | 73.6 | - | 45.2 | - | - |
| ราศีเมถุน-1.5 โปร | ยูเอ็นเค | - | - | 52.1 | 81.3 | - |
| กร็อค-1.5 | ยูเอ็นเค | - | - | 52.8 | 76.1 | - |
| เอ็มเอ็ม-1-8บี | 144 | 72.3 | 72.6 | 35.9 | - | - |
| เอ็มเอ็ม-1-30บี | 144 | 75.1 | 81.0 | 39.4 | - | - |
| ฐาน LLM: Phi-3-3.8B | ||||||
| แคมเบรียน-1-8B | 576 | 74.6 | 79.2 | 48.4 | 66.8 | 40.0 |
| ฐาน LLM: LLaMA3-8B-Instruct | ||||||
| มินิ-ราศีเมถุน-HD-8B | 2880 | 72.7 | 75.1 | 37.0 | 59.1 | 18.7 |
| แอลลาวา-เน็กซ์-8บี | 2880 | 72.1 | 72.8 | 36.3 | 69.5 | 38.7 |
| แคมเบรียน-1-8B | 576 | 75.9 | 80.4 | 49.0 | 73.3 | 51.3 |
| ฐาน LLM: Vicuna1.5-13B | ||||||
| มินิ-ราศีเมถุน-HD-13B | 2880 | 68.6 | 71.9 | 37.0 | 56.6 | 19.3 |
| แอลลาวา-เน็กซ์-13บี | 2880 | 70.0 | 73.5 | 35.1 | 62.2 | 36.0 |
| แคมเบรียน-1-13B | 576 | 75.7 | 79.3 | 48.0 | 73.8 | 41.3 |
| ฐาน LLM: Hermes2-Yi-34B | ||||||
| มินิ-ราศีเมถุน-HD-34B | 2880 | 80.6 | 77.7 | 43.4 | 67.6 | 37.3 |
| แอลลาวา-เน็กซ์-34บี | 2880 | 79.3 | 81.8 | 46.5 | 68.7 | 47.3 |
| แคมเบรียน-1-34B | 576 | 81.4 | 85.6 | 53.2 | 75.6 | 52.7 |
สำหรับตารางทั้งหมด โปรดดูรายงาน Cambrian-1 ของเรา
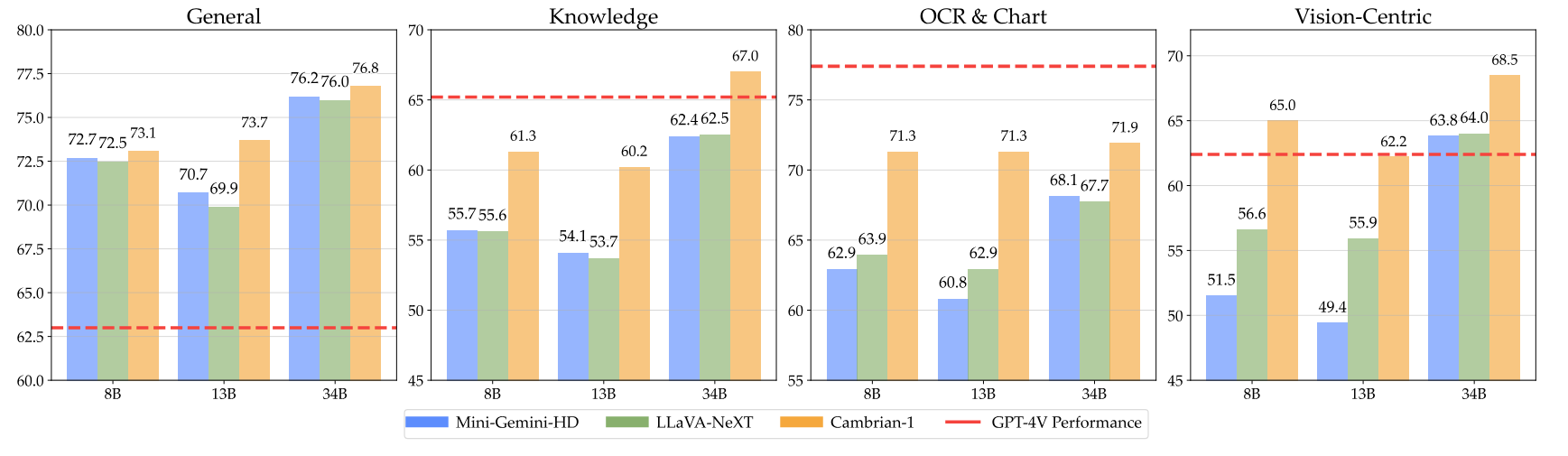
โมเดลของเรานำเสนอประสิทธิภาพการแข่งขันสูงในขณะที่ใช้โทเค็นภาพจำนวนคงที่น้อยกว่า
หากต้องการใช้ตุ้มน้ำหนักโมเดล ให้ดาวน์โหลดจาก Hugging Face:
เรามีตัวอย่างการโหลดและสร้างสคริปต์ใน inference.py

ในงานนี้ เรารวบรวมข้อมูลการปรับแต่งคำสั่ง Cambrian-10M จำนวนมากสำหรับเราและงานในอนาคตเพื่อศึกษาข้อมูลในการฝึกอบรม MLLM ในการศึกษาเบื้องต้น เรากรองข้อมูลลงเหลือชุดจุดข้อมูลคุณภาพสูงที่มีการดูแลจัดการ 7M ซึ่งเราเรียกว่า Cambrian-7M ชุดข้อมูลทั้งสองนี้มีอยู่ในชุดข้อมูล Hugging Face ต่อไปนี้: Cambrian-10M
เรารวบรวมข้อมูลการปรับแต่งการสอนด้วยภาพที่หลากหลายจากแหล่งต่างๆ รวมถึง VQA การสนทนาด้วยภาพ และการโต้ตอบด้วยภาพที่รวบรวมไว้ เพื่อให้มั่นใจว่าข้อมูลความรู้มีคุณภาพสูง เชื่อถือได้ และมีขนาดใหญ่ เราได้ออกแบบ Internet Data Engine
นอกจากนี้ เราสังเกตเห็นว่าข้อมูล VQA มีแนวโน้มที่จะสร้างผลลัพธ์ที่สั้นมาก ทำให้เกิดการเปลี่ยนแปลงการกระจายจากข้อมูลการฝึกอบรม เพื่อแก้ไขปัญหานี้ เราได้ใช้ประโยชน์จาก GPT-4v และ GPT-4o เพื่อสร้างการตอบสนองเพิ่มเติมและข้อมูลเชิงสร้างสรรค์มากขึ้น
เพื่อแก้ไขความไม่เพียงพอของข้อมูลที่เกี่ยวข้องกับวิทยาศาสตร์ เราได้ออกแบบ Internet Data Engine เพื่อรวบรวมข้อมูล VQA ที่เกี่ยวข้องกับวิทยาศาสตร์ที่เชื่อถือได้ เอ็นจิ้นนี้สามารถนำไปใช้ในการรวบรวมข้อมูลในหัวข้อใดก็ได้ ด้วยการใช้กลไกนี้ เราได้รวบรวมจุดข้อมูลการปรับแต่งคำสั่งด้วยภาพที่เกี่ยวข้องกับวิทยาศาสตร์เพิ่มเติมอีก 161,000 จุด ซึ่งเพิ่มข้อมูลทั้งหมดในโดเมนนี้ถึง 400%! หากคุณต้องการใช้ข้อมูลส่วนนี้ โปรดใช้ jsonl นี้
เราใช้ GPT-4v เพื่อสร้างจุดข้อมูลเพิ่มเติม 77,000 จุด ข้อมูลนี้ใช้ GPT-4v เพื่อเขียน VQA แบบตอบอย่างเดียวแบบเดิมให้เป็นคำตอบที่ยาวขึ้นพร้อมคำตอบที่มีรายละเอียดมากขึ้น หรือสร้างข้อมูลการปรับแต่งคำสั่งแบบภาพตามรูปภาพที่กำหนด หากคุณต้องการใช้ข้อมูลส่วนนี้ โปรดใช้ jsonl นี้
เราใช้ GPT-4o เพื่อสร้างจุดข้อมูลโฆษณาเพิ่มเติม 60,000 จุด ข้อมูลนี้สนับสนุนให้โมเดลสร้างคำตอบที่ยาวมากและมักมีคำถามที่สร้างสรรค์สูง เช่น การเขียนบทกวี การแต่งเพลง และอื่นๆ หากคุณต้องการใช้ข้อมูลส่วนนี้ โปรดใช้ jsonl นี้
เราทำการศึกษาเบื้องต้นเกี่ยวกับการดูแลจัดการข้อมูลโดย:
ตามเชิงประจักษ์แล้ว เราพบสภาพแวดล้อมนั้น
| หมวดหมู่ | อัตราส่วนข้อมูล |
|---|---|
| ภาษา | 21.00% |
| ทั่วไป | 34.52% |
| โอซีอาร์ | 27.22% |
| การนับ | 8.71% |
| คณิตศาสตร์ | 7.20% |
| รหัส | 0.87% |
| ศาสตร์ | 0.88% |
เมื่อเปรียบเทียบกับรุ่น LLaVA-665K ก่อนหน้า การขยายขนาดและการจัดการข้อมูลที่ได้รับการปรับปรุงจะช่วยเพิ่มประสิทธิภาพการทำงานของโมเดลได้อย่างมาก ดังที่แสดงในตารางด้านล่าง:
| แบบอย่าง | เฉลี่ย | ความรู้ทั่วไป | โอซีอาร์ | แผนภูมิ | วิสัยทัศน์เป็นศูนย์กลาง |
|---|---|---|---|---|---|
| แอลลาวา-665K | 40.4 | 64.7 | 45.2 | 20.8 | 31.0 |
| แคมเบรียน-10เอ็ม | 53.8 | 68.7 | 51.6 | 47.1 | 47.6 |
| แคมเบรียน-7เอ็ม | 54.8 | 69.6 | 52.6 | 47.3 | 49.5 |
ในขณะที่การฝึกอบรมกับ Cambrian-7M ให้ผลลัพธ์การวัดประสิทธิภาพเชิงแข่งขัน เราสังเกตว่าแบบจำลองมีแนวโน้มที่จะให้คำตอบที่สั้นกว่าและทำหน้าที่เหมือนเครื่องตอบคำถาม พฤติกรรมนี้ ซึ่งเราเรียกว่าปรากฏการณ์ "เครื่องตอบรับอัตโนมัติ" สามารถจำกัดประโยชน์ของโมเดลในการโต้ตอบที่ซับซ้อนมากขึ้น
เราพบว่าการเพิ่มระบบแจ้งเตือน เช่น "ตอบคำถามโดยใช้คำหรือวลีเดียว" สามารถช่วยบรรเทาปัญหาได้ แนวทางนี้สนับสนุนให้แบบจำลองให้คำตอบที่กระชับเฉพาะเมื่อมีความเหมาะสมตามบริบทเท่านั้น สำหรับรายละเอียดเพิ่มเติม โปรดดูเอกสารของเรา
นอกจากนี้เรายังได้รวบรวมชุดข้อมูล Cambrian-7M พร้อม พร้อมท์ของระบบ ซึ่งรวมถึงพร้อมท์ระบบเพื่อปรับปรุงความคิดสร้างสรรค์และความสามารถในการแชทของโมเดล
ด้านล่างนี้คือการกำหนดค่าการฝึกล่าสุดสำหรับ Cambrian-1
ในรายงาน Cambrian-1 เราทำการศึกษาอย่างกว้างขวางเพื่อแสดงให้เห็นถึงความจำเป็นของการฝึกอบรมแบบสองขั้นตอน การฝึกอบรม Cambrian-1 ประกอบด้วยสองขั้นตอน:
Cambrian-1 ผ่านการฝึกบน TPU-V4-512 แต่ยังฝึกกับ TPU ได้ โดยเริ่มต้นที่ TPU-V4-64 รหัสการฝึกอบรม GPU จะออกเร็วๆ นี้ สำหรับการฝึกฝน GPU บน GPU น้อยลง ให้ลดขนาด per_device_train_batch_size และเพิ่ม gradient_accumulation_steps ตามลำดับ เพื่อให้แน่ใจว่าขนาดแบตช์ทั่วโลกยังคงเท่าเดิม: per_device_train_batch_size x gradient_accumulation_steps x num_gpus
ไฮเปอร์พารามิเตอร์ทั้งสองที่ใช้ในการฝึกล่วงหน้าและการปรับแต่งมีระบุไว้ด้านล่าง
| ฐาน LLM | ขนาดแบตช์ทั่วโลก | อัตราการเรียนรู้ | อัตราการเรียนรู้ SVA | ยุค | ความยาวสูงสุด |
|---|---|---|---|---|---|
| ลามา-3 8B | 512 | 1e-3 | 1e-4 | 1 | 2048 |
| วิคูน่า-1.5 13B | 512 | 1e-3 | 1e-4 | 1 | 2048 |
| เฮอร์มีส ยี-34บี | 1,024 | 1e-3 | 1e-4 | 1 | 2048 |
| ฐาน LLM | ขนาดแบตช์ทั่วโลก | อัตราการเรียนรู้ | ยุค | ความยาวสูงสุด |
|---|---|---|---|---|
| ลามา-3 8B | 512 | 4e-5 | 1 | 2048 |
| วิคูนา-1.5 13B | 512 | 4e-5 | 1 | 2048 |
| แอร์เมส ยี-34บี | 1,024 | 2e-5 | 1 | 2048 |
สำหรับการปรับแต่งคำสั่งอย่างละเอียด เราทำการทดลองเพื่อกำหนดอัตราการเรียนรู้ที่เหมาะสมที่สุดสำหรับการฝึกโมเดลของเรา จากการค้นพบของเรา เราขอแนะนำให้ใช้สูตรต่อไปนี้เพื่อปรับอัตราการเรียนรู้ตามความพร้อมใช้งานของอุปกรณ์ของคุณ:
optimal lr = base_lr * sqrt(bs / base_bs)
หากต้องการรับ LLM พื้นฐานและฝึกรุ่น 8B, 13B และ 34B:
เราใช้การผสมผสานระหว่างข้อมูลการจัดตำแหน่ง LLaVA, ShareGPT4V, Mini-Gemini และ ALLaVA เพื่อฝึกตัวเชื่อมต่อภาพ (SVA) ของเราล่วงหน้า ใน Cambrian-1 เราทำการศึกษาอย่างกว้างขวางเพื่อแสดงให้เห็นถึงความจำเป็นและประโยชน์ของการใช้ข้อมูลการจัดตำแหน่งเพิ่มเติม
ในการเริ่มต้น โปรดไปที่หน้าข้อมูลการจัดตำแหน่งใบหน้ากอดของเราเพื่อดูรายละเอียดเพิ่มเติม คุณสามารถดาวน์โหลดข้อมูลการจัดตำแหน่งได้จากลิงก์ต่อไปนี้:
เราจัดเตรียมสคริปต์การฝึกอบรมตัวอย่างใน:
หากคุณต้องการฝึกอบรมกับแหล่งข้อมูลอื่นหรือข้อมูลที่กำหนดเอง เรารองรับรูปแบบข้อมูล LLaVA ที่ใช้กันทั่วไป สำหรับการจัดการไฟล์ขนาดใหญ่มาก เราใช้รูปแบบ JSONL แทนรูปแบบ JSON สำหรับการโหลดข้อมูลแบบ Lazy เพื่อเพิ่มประสิทธิภาพการใช้งานหน่วยความจำ
เช่นเดียวกับ Training SVA โปรดไปที่ข้อมูล Cambrian-10M ของเราสำหรับรายละเอียดเพิ่มเติมเกี่ยวกับข้อมูลการปรับแต่งคำสั่ง
เราจัดเตรียมสคริปต์การฝึกอบรมตัวอย่างใน:
--mm_projector_type : หากต้องการใช้โมดูล SVA ของเรา ให้ตั้งค่านี้เป็น sva หากต้องการใช้โปรเจ็กเตอร์ MLP 2 เลเยอร์สไตล์ LLaVA ให้ตั้งค่านี้เป็น mlp2x_gelu--vision_tower_aux_list : รายการโมเดลการมองเห็นที่จะใช้ (เช่น '["siglip/CLIP-ViT-SO400M-14-384", "openai/clip-vit-large-patch14-336", "facebook/dinov2-giant-res378", "clip-convnext-XXL-multi-stage"]' )--vision_tower_aux_token_len_list : รายการจำนวนโทเค็นการมองเห็นสำหรับแต่ละวิชันทาวเวอร์ แต่ละหมายเลขควรเป็นเลขยกกำลังสอง (เช่น '[576, 576, 576, 9216]' ) แผนที่แสดงคุณสมบัติของหอสังเกตการณ์แต่ละแห่งจะถูกสอดแทรกเพื่อให้เป็นไปตามข้อกำหนดนี้--image_token_len : จำนวนโทเค็นการมองเห็นสุดท้ายที่จะมอบให้กับ LLM ตัวเลขควรเป็นเลขกำลังสอง (เช่น 576 ) โปรดทราบว่าหาก mm_projector_type เป็น mlp แต่ละหมายเลขใน vision_tower_aux_token_len_list จะต้องเหมือนกับ image_token_len ข้อโต้แย้งด้านล่างนี้มีความหมายสำหรับโปรเจ็กเตอร์ SVA เท่านั้น--num_query_group : ค่า G สำหรับโมดูล SVA--query_num_list : รายการหมายเลขแบบสอบถามสำหรับการสืบค้นแต่ละกลุ่มใน SVA (เช่น '[576]' ) ความยาวของรายการควรเท่ากับ num_query_group--connector_depth : ค่า D สำหรับโมดูล SVA--vision_hidden_size : ขนาดที่ซ่อนอยู่สำหรับโมดูล SVA--connector_only : หากเป็นจริง โมดูล SVA จะปรากฏก่อน LLM เท่านั้น ไม่เช่นนั้นจะถูกแทรกหลายครั้งภายใน LLM อาร์กิวเมนต์สามข้อต่อไปนี้จะมีความหมายเมื่อตั้งค่าเป็น False เท่านั้น--num_of_vision_sampler_layers : จำนวนโมดูล SVA ทั้งหมดที่แทรกภายใน LLM--start_of_vision_sampler_layers : ดัชนีเลเยอร์ LLM หลังจากนั้นการแทรก SVA จะเริ่มต้นขึ้น--stride_of_vision_sampler_layers : ความก้าวหน้าของการแทรกโมดูล SVA ภายใน LLM เราได้เผยแพร่โค้ดการประเมินของเราใน eval/ โฟลเดอร์ย่อยแล้ว โปรดดู README ที่นั่นสำหรับรายละเอียดเพิ่มเติม
คำแนะนำต่อไปนี้จะแนะนำคุณตลอดการเปิดตัวสาธิต Gradio ในพื้นที่กับ Cambrian เรามีเว็บอินเตอร์เฟสที่เรียบง่ายเพื่อให้คุณโต้ตอบกับโมเดลได้ คุณยังสามารถใช้ CLI เพื่อการอนุมานได้ การตั้งค่านี้ได้รับแรงบันดาลใจอย่างมากจาก LLaVA
โปรดทำตามขั้นตอนด้านล่างเพื่อเริ่มการสาธิต Gradio ในพื้นที่ แผนภาพของโค้ดการให้บริการในเครื่องอยู่ด้านล่าง 1
%%{init: {"theme": "base"}}%%
ผังงาน BT
%% ประกาศโหนด
สไตล์ gws เติม:#f9f,จังหวะ:#333,ความกว้างของเส้นขีด:2px
สไตล์ c เติม:#bbf,โรคหลอดเลือดสมอง:#333,ความกว้างของเส้นขีด:2px
สไตล์ mw8b เติม:#aff,โรคหลอดเลือดสมอง:#333,โรคหลอดเลือดสมองกว้าง:2px
สไตล์ mw13b เติม:#aff,โรคหลอดเลือดสมอง:#333,โรคหลอดเลือดสมองกว้าง:2px
%% สไตล์ sglw13b เติม:#ffa,จังหวะ:#333,ความกว้างของเส้นขีด:2px
%% สไตล์ lsglw13b เติม:#ffa,จังหวะ:#333,ความกว้างของเส้นขีด:2px
gws["Gradio (เซิร์ฟเวอร์ UI)"]
c["คอนโทรลเลอร์ (เซิร์ฟเวอร์ API):<br/>พอร์ต: 10000"]
mw8b["ผู้ปฏิบัติงานโมเดล:<br/><b>Cambrian-1-8B</b><br/>พอร์ต: 40000"]
mw13b["ผู้ปฏิบัติงานโมเดล:<br/><b>Cambrian-1-13B</b><br/>พอร์ต: 40001"]
%% sglw13b["แบ็กเอนด์ SGLang:<br/><b>Cambrian-1-34B</b><br/>http://localhost:30000"]
%% lsglw13b["ผู้ปฏิบัติงาน SGLang:<br/><b>Cambrian-1-34B<b><br/>พอร์ต: 40002"]
กราฟย่อย "สถาปัตยกรรมสาธิต"
ทิศทางบีที
ค <--> gws
mw8b <--> ค
mw13b <--> ค
%% lsglw13b <--> ค
%% sglw13b <--> lsglw13b
จบ
python -m cambrian.serve.controller --host 0.0.0.0 --port 10000python -m cambrian.serve.gradio_web_server --controller http://localhost:10000 --model-list-mode reloadคุณเพิ่งเปิดตัวเว็บอินเตอร์เฟส Gradio ตอนนี้คุณสามารถเปิดเว็บอินเตอร์เฟสด้วย URL ที่พิมพ์บนหน้าจอได้ คุณอาจสังเกตเห็นว่าไม่มีรุ่นอยู่ในรายการรุ่น ไม่ต้องกังวล เนื่องจากเรายังไม่ได้เปิดตัวโมเดลเวิร์คเวอร์ใดๆ เลย มันจะได้รับการอัปเดตโดยอัตโนมัติเมื่อคุณเปิดตัวผู้ปฏิบัติงานแบบจำลอง
เร็วๆ นี้.
นี่คือ ผู้ปฏิบัติงาน จริงที่ทำการอนุมานบน GPU ผู้ปฏิบัติงานแต่ละคนมีหน้าที่รับผิดชอบแบบจำลองเดียวที่ระบุใน --model-path
python -m cambrian.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path nyu-visionx/cambrian-8bรอจนกว่ากระบวนการโหลดโมเดลเสร็จสิ้น และคุณจะเห็นข้อความ "Uvicorn ทำงานบน ... " ตอนนี้ รีเฟรช Gradio web UI ของคุณ แล้วคุณจะเห็นโมเดลที่คุณเพิ่งเปิดตัวในรายการโมเดล
คุณสามารถเปิดใช้พนักงานได้มากเท่าที่คุณต้องการ และเปรียบเทียบระหว่างจุดตรวจสอบโมเดลต่างๆ ในอินเทอร์เฟซ Gradio เดียวกัน โปรดคง --controller ไว้เหมือนเดิม และแก้ไข --port และ --worker เป็นหมายเลขพอร์ตที่แตกต่างกันสำหรับผู้ปฏิบัติงานแต่ละคน
python -m cambrian.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port < different from 40000, say 40001> --worker http://localhost: < change accordingly, i.e. 40001> --model-path < ckpt 2> หากคุณใช้อุปกรณ์ Apple ที่มีชิป M1 หรือ M2 คุณสามารถระบุอุปกรณ์ mps ได้โดยใช้แฟล็ก --device : --device mps
หาก VRAM ของ GPU ของคุณน้อยกว่า 24GB (เช่น RTX 3090, RTX 4090 เป็นต้น) คุณอาจลองใช้งานด้วย GPU หลายตัว ฐานโค้ดล่าสุดของเราจะพยายามใช้ GPU หลายตัวโดยอัตโนมัติ หากคุณมี GPU มากกว่าหนึ่งตัว คุณสามารถระบุ GPU ที่จะใช้กับ CUDA_VISIBLE_DEVICES ได้ ด้านล่างนี้เป็นตัวอย่างการทำงานกับ GPU สองตัวแรก
CUDA_VISIBLE_DEVICES=0,1 python -m cambrian.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path nyu-visionx/cambrian-8bสิ่งที่ต้องทำ
หากคุณพบว่า Cambrian มีประโยชน์สำหรับการวิจัยและการใช้งานของคุณ โปรดอ้างอิงโดยใช้ BibTeX นี้:
@misc { tong2024cambrian1 ,
title = { Cambrian-1: A Fully Open, Vision-Centric Exploration of Multimodal LLMs } ,
author = { Shengbang Tong and Ellis Brown and Penghao Wu and Sanghyun Woo and Manoj Middepogu and Sai Charitha Akula and Jihan Yang and Shusheng Yang and Adithya Iyer and Xichen Pan and Austin Wang and Rob Fergus and Yann LeCun and Saining Xie } ,
year = { 2024 } ,
eprint = { 2406.16860 } ,
}
ประกาศการใช้งานและใบอนุญาต : โครงการนี้ใช้ชุดข้อมูลและจุดตรวจสอบบางอย่างที่อยู่ภายใต้ใบอนุญาตดั้งเดิมที่เกี่ยวข้อง ผู้ใช้จะต้องปฏิบัติตามข้อกำหนดและเงื่อนไขทั้งหมดของใบอนุญาตดั้งเดิมเหล่านี้ ซึ่งรวมถึงแต่ไม่จำกัดเพียงข้อกำหนดการใช้งาน OpenAI สำหรับชุดข้อมูลและใบอนุญาตเฉพาะสำหรับโมเดลภาษาพื้นฐานสำหรับจุดตรวจที่ได้รับการฝึกอบรมโดยใช้ชุดข้อมูล (เช่น ใบอนุญาตชุมชน Llama สำหรับ LLaMA-3, และวิคูนา-1.5) โครงการนี้ไม่ได้กำหนดข้อจำกัดเพิ่มเติมใดๆ นอกเหนือจากที่กำหนดไว้ในใบอนุญาตดั้งเดิม นอกจากนี้ ผู้ใช้จะได้รับการเตือนเพื่อให้แน่ใจว่าการใช้ชุดข้อมูลและจุดตรวจสอบเป็นไปตามกฎหมายและข้อบังคับที่เกี่ยวข้องทั้งหมด
คัดลอกมาจากแผนภาพของ LLaVA


