Synonyms
Synonyms
คำพ้องความหมายภาษาจีนสำหรับการประมวลผลและความเข้าใจภาษาธรรมชาติ
คำพ้องความหมายภาษาจีนที่ดีกว่า: chatbot ชุดเครื่องมือคำถามและคำตอบที่ชาญฉลาด
synonyms สามารถนำมาใช้สำหรับงานต่างๆ ในการทำความเข้าใจภาษาธรรมชาติ: การจัดตำแหน่งข้อความ อัลกอริธึมการแนะนำ การคำนวณความคล้ายคลึง การชดเชยความหมาย การแยกคำหลัก การแยกแนวคิด การสรุปอัตโนมัติ เครื่องมือค้นหา ฯลฯ
เพื่อมอบบริการที่เสถียร เชื่อถือได้ และปรับให้เหมาะสมในระยะยาว คำพ้องความหมายจึงเปลี่ยนไปใช้สิทธิ์การใช้งาน Chunsong เวอร์ชัน 1.0 และค่าบริการสำหรับการดาวน์โหลดโมเดลการเรียนรู้ของเครื่อง โปรดดูรายละเอียดที่ร้านค้าใบรับรอง ผู้ร่วมให้ข้อมูลก่อนหน้านี้ (ผู้ร่วมเขียนโค้ดที่มีส่วนสนับสนุนที่โดดเด่น) สามารถติดต่อเราเพื่อหารือเกี่ยวกับปัญหาการเรียกเก็บเงินได้ -- Chatopera Inc. @ ต.ค. 2023
ทำตามขั้นตอนด้านล่างเพื่อติดตั้งและเปิดใช้งานแพ็คเกจ
pip install -U synonymsเวอร์ชันเสถียรปัจจุบันคือ v3.x
แพ็คเกจโมเดลการเรียนรู้ของเครื่องของคำพ้องความหมายต้องมีใบอนุญาตจาก Chatopera License Store ขั้นแรกให้ซื้อใบอนุญาตและรับ license id จากหน้า ใบอนุญาต ใน Chatopera License Store ( license id : ในที่เก็บใบรับรอง ในหน้ารายละเอียดใบรับรอง คลิก [คัดลอก ข้อมูลระบุตัวตนใบรับรอง] )
ประการที่สอง ตั้งค่าตัวแปรสภาพแวดล้อมในเทอร์มินัลหรือเชลล์สคริปต์ของคุณดังนี้
เช่น Shell, สคริปต์ CMD บน Linux, Windows, macOS
# Linux / macOS
export SYNONYMS_DL_LICENSE=YOUR_LICENSE
# # e.g. if your license id is `FOOBAR`, run `export SYNONYMS_DL_LICENSE=FOOBAR`
# Windows
# # 1/2 Command Prompt
set SYNONYMS_DL_LICENSE=YOUR_LICENSE
# # 2/2 PowerShell
$env :SYNONYMS_DL_LICENSE= ' YOUR_LICENSE 'โน๊ตบุ๊ค Jupyter ฯลฯ
import os
os . environ [ "SYNONYMS_DL_LICENSE" ] = "YOUR_LICENSE"
_licenseid = os . environ . get ( "SYNONYMS_DL_LICENSE" , None )
print ( "SYNONYMS_DL_LICENSE=" , _licenseid )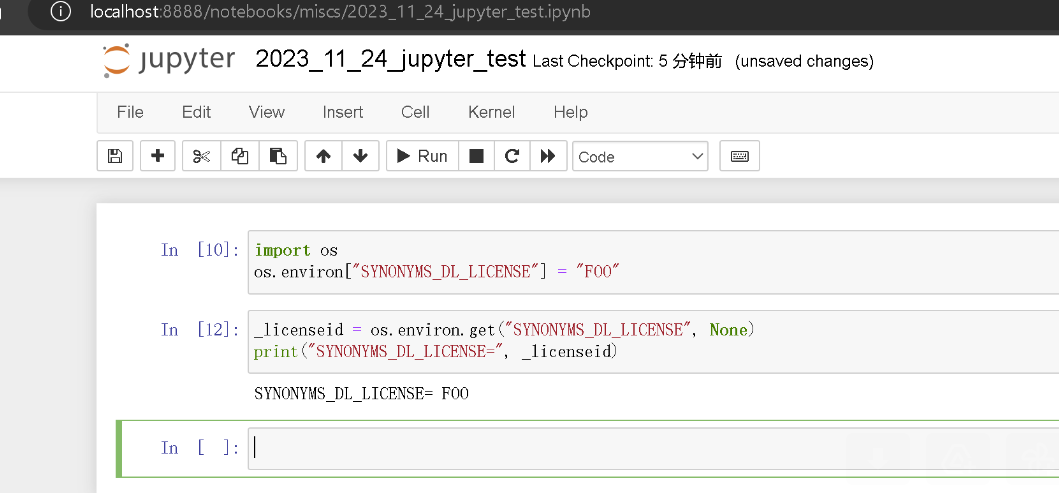
เคล็ดลับ: ไฟล์คำว่า vector จะถูกดาวน์โหลดเป็นครั้งแรกหลังการติดตั้ง และความเร็วในการดาวน์โหลดขึ้นอยู่กับสภาพของเครือข่าย
สุดท้าย ดาวน์โหลดแพ็คเกจโมเดลตามคำสั่งหรือสคริปต์ -
python -c " import synonyms; synonyms.display('能量') " # download word vectors file 
รองรับการใช้ตัวแปรสภาพแวดล้อมเพื่อกำหนดค่าคำศัพท์ในการแบ่งส่วนคำและไฟล์เวกเตอร์คำ word2vec
| ตัวแปรสภาพแวดล้อม | อธิบาย |
|---|---|
| SYNONYMS_WORD2VEC_BIN_MODEL_ZH_CN | ไฟล์เวกเตอร์ Word ฝึกฝนโดยใช้ word2vec รูปแบบไบนารี |
| SYNONYMS_WORDSEG_DICT | พจนานุกรมหลักการ แบ่งส่วนคำภาษาจีน รูปแบบ และการอ้างอิงการใช้งาน |
| คำเหมือน_DEBUG | ["TRUE"|"FALSE"] ไม่ว่าจะส่งออกบันทึกการดีบัก ตั้งค่าเป็นเอาต์พุต "TRUE" ค่าเริ่มต้นคือ "FALSE" |
import synonyms
print ( "人脸: " , synonyms . nearby ( "人脸" ))
print ( "识别: " , synonyms . nearby ( "识别" ))
print ( "NOT_EXIST: " , synonyms . nearby ( "NOT_EXIST" )) synonyms.nearby(WORD [,SIZE]) ส่งคืน tuple มีสองรายการ: ([nearby_words], [nearby_words_score]) nearby_words เป็นคำพ้องของ WORD เช่นกัน ระยะทางเรียงจากใกล้ไปไกล nearby_words_score คือคะแนนระยะห่างระหว่างคำที่ ตำแหน่งที่สอดคล้องกัน ใน nearby_words คะแนนจะอยู่ในช่วงเวลา (0-1) ยิ่งใกล้กับ 1 เท่าใด SIZE ก็คือจำนวนคำที่ส่งคืน และ ค่าเริ่มต้นคือ 10 ตัวอย่างเช่น:
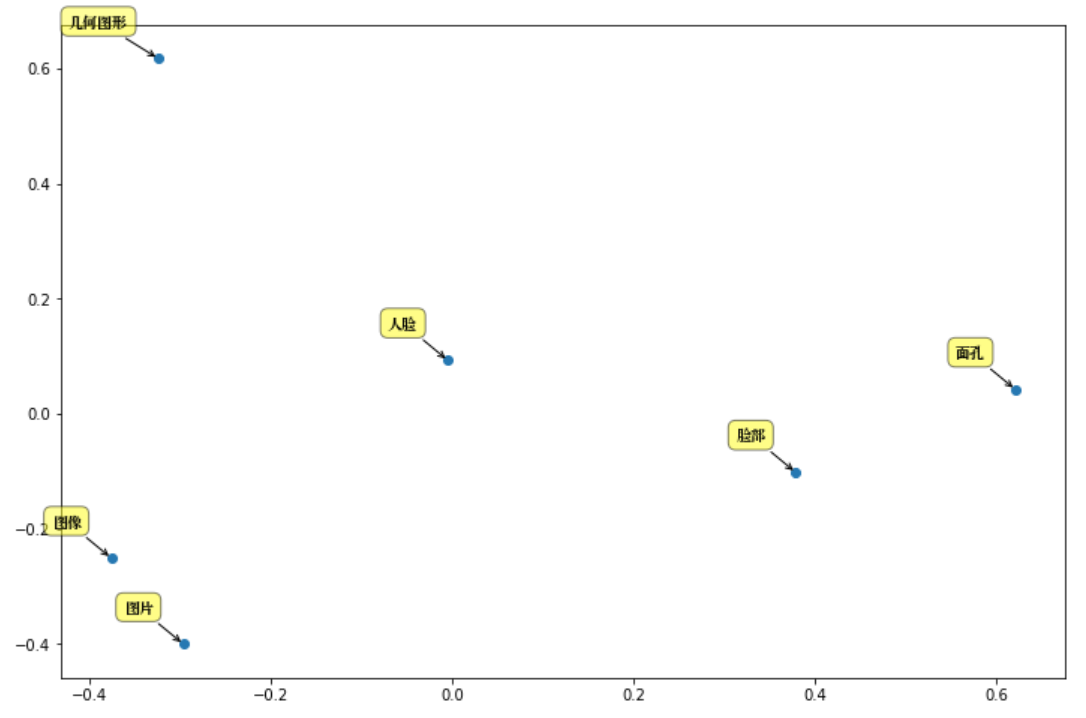
synonyms . nearby (人脸, 10 ) = (
[ "图片" , "图像" , "通过观察" , "数字图像" , "几何图形" , "脸部" , "图象" , "放大镜" , "面孔" , "Mii" ],
[ 0.597284 , 0.580373 , 0.568486 , 0.535674 , 0.531835 , 0.530
095 , 0.525344 , 0.524009 , 0.523101 , 0.516046 ]) ในกรณีของ OOV จะส่งกลับ ([], []) ขนาดพจนานุกรมปัจจุบัน: 435,729
การเปรียบเทียบความคล้ายคลึงระหว่างสองประโยค
sen1 = "发生历史性变革"
sen2 = "发生历史性变革"
r = synonyms . compare ( sen1 , sen2 , seg = True )ในบรรดาพารามิเตอร์เหล่านี้ พารามิเตอร์ seg ระบุว่า synonyms.compare ดำเนินการแบ่งส่วนคำใน sen1 และ sen2 หรือไม่ และค่าเริ่มต้นคือ True ค่าส่งคืน: [0-1] และยิ่งใกล้ 1 ประโยคทั้งสองก็จะยิ่งคล้ายกันมากขึ้น
旗帜引领方向 vs 道路决定命运: 0.429
旗帜引领方向 vs 旗帜指引道路: 0.93
发生历史性变革 vs 发生历史性变革: 1.0 พิมพ์คำพ้องความหมายในลักษณะที่เป็นมิตรเพื่ออำนวยความสะดวกในการแก้ไขจุดบกพร่อง display(WORD [, SIZE]) เรียก synonyms#nearby
>> > synonyms . display ( "飞机" )
'飞机'近义词:
1. 飞机: 1.0
2. 直升机: 0.8423391
3. 客机: 0.8393003
4. 滑翔机: 0.7872388
5. 军用飞机: 0.7832081
6. 水上飞机: 0.77857226
7. 运输机: 0.7724742
8. 航机: 0.7664748
9. 航空器: 0.76592904
10. 民航机: 0.74209654 SIZE คือจำนวนรายการคำศัพท์ที่พิมพ์ ค่าเริ่มต้นคือ 10
พิมพ์ข้อมูลคำอธิบายของแพ็คเกจปัจจุบัน:
>>> synonyms.describe()
Vocab size in vector model: 435729
model_path: /Users/hain/chatopera/Synonyms/synonyms/data/words.vector.gz
version: 3.18.0
{'vocab_size': 435729, 'version': '3.18.0', 'model_path': '/chatopera/Synonyms/synonyms/data/words.vector.gz'}
รับคำเวกเตอร์ซึ่งเป็นอาร์เรย์ตัวเลข เมื่อคำนั้นเป็นคำที่ไม่ได้ลงทะเบียน ข้อยกเว้นของ KeyError จะถูกส่งออกไป
>> > synonyms . v ( "飞机" )
array ([ - 2.412167 , 2.2628384 , - 7.0214124 , 3.9381874 , 0.8219283 ,
- 3.2809453 , 3.8747153 , - 5.217062 , - 2.2786229 , - 1.2572327 ],
dtype = float32 )รับเวกเตอร์ของประโยคหลังจากการแบ่งส่วนคำ เวกเตอร์ถูกประกอบในโหมด BoW
sentence : 句子是分词后通过空格联合起来
ignore : 是否忽略OOV , False时,随机生成一个向量การแบ่งส่วนคำภาษาจีน
synonyms . seg ( "中文近义词工具包" )ผลลัพธ์ของการแบ่งส่วนคำคือทูเพิลที่ประกอบด้วยสองรายการ ซึ่งเป็นคำและส่วนของคำพูดที่สอดคล้องกัน
([ '中文' , '近义词' , '工具包' ], [ 'nz' , 'n' , 'n' ])กริยานี้ไม่ได้ลบคำหยุดและเครื่องหมายวรรคตอน
แยกคำสำคัญตามค่าเริ่มต้น คำสำคัญจะถูกแยกตามความสำคัญ
keywords = synonyms.keywords("9月15日以来,台积电、高通、三星等华为的重要合作伙伴,只要没有美国的相关许可证,都无法供应芯片给华为,而中芯国际等国产芯片企业,也因采用美国技术,而无法供货给华为。目前华为部分型号的手机产品出现货少的现象,若该形势持续下去,华为手机业务将遭受重创。")
รับบันทึกเพิ่มเติมสำหรับการดีบัก ตั้งค่าตัวแปรสภาพแวดล้อม
SYNONYMS_DEBUG=TRUE
เอา “ใบหน้ามนุษย์” มาเป็นตัวอย่างในการวิเคราะห์องค์ประกอบหลักๆ ดังนี้
$ pip install -r Requirements.txt
$ python demo.pyปรับปรุงคำชี้แจงสถานะ
ผู้ใช้พูดว่าอย่างไร:
ข้อมูลถูกสร้างขึ้นตาม wikidata-corpus
"Synonyms Cilin" เรียบเรียงโดย Mei Jiaju และคนอื่นๆ ในปี 1983 เวอร์ชันที่ใช้กันอย่างแพร่หลายในปัจจุบันคือ "Synonyms Cilin Expanded Edition" ซึ่งดูแลโดยศูนย์วิจัยคอมพิวเตอร์สังคมและการสืบค้นข้อมูลของสถาบันเทคโนโลยีฮาร์บิน โดยแบ่งคำศัพท์ภาษาจีนออกเป็นขนาดใหญ่อย่างละเอียด หมวดหมู่และหมวดหมู่ย่อยแยกแยะความสัมพันธ์ระหว่างคำ คำพ้องความหมาย Cilin เวอร์ชันขยายมีมากกว่า 70,000 คำ ซึ่งมีการแชร์มากกว่า 30,000 คำในรูปแบบของข้อมูลเปิด
HowNet หรือที่รู้จักในชื่อ HowNet ไม่ใช่แค่พจนานุกรมความหมาย แต่เป็นระบบความรู้ ความสัมพันธ์ระหว่างคำเป็นหนึ่งในสถานการณ์การใช้งานพื้นฐาน CNKI มีมากกว่า 8 คำ
มาตรฐานการประเมินระหว่างประเทศสำหรับอัลกอริธึมความคล้ายคลึงกันของคำโดยทั่วไปจะใช้ค่าการตัดสินด้วยตนเองของชุดคู่คำภาษาอังกฤษที่เผยแพร่โดย Miller&Charles ชุดคำคู่ประกอบด้วยคู่คำที่เกี่ยวข้องสูง 10 คู่ คู่ความสัมพันธ์ปานกลาง 10 คู่ และคู่คำภาษาอังกฤษที่เกี่ยวข้องต่ำ 10 คู่ จากนั้นให้ผู้เรียน 38 รายตัดสินความเกี่ยวข้องเชิงความหมายของคู่ 30 คู่นี้ และสุดท้ายก็เอาค่าเฉลี่ย ค่าทำหน้าที่เป็นเกณฑ์ด้วยตนเอง จากนั้น เครื่องมือคำพ้องความหมายต่างๆ จะให้คะแนนความคล้ายคลึงกันของคำเหล่านี้ และเปรียบเทียบกับเกณฑ์การตัดสินด้วยตนเอง เช่น การใช้สัมประสิทธิ์สหสัมพันธ์แบบเพียร์สัน ในสาขาภาษาจีน วิธีทั่วไปในการใช้รายการคำศัพท์เวอร์ชันแปลเพื่อเปรียบเทียบคำพ้องความหมายภาษาจีน
ความจุรายการคำศัพท์ของคำพ้องความหมายคือ 435,729 ด้านล่างนี้เราเลือกคำบางคำที่มีอยู่ในคำพ้องความหมาย Cilin, CNKI และคำพ้องความหมายเพื่อเปรียบเทียบความคล้ายคลึงกัน:
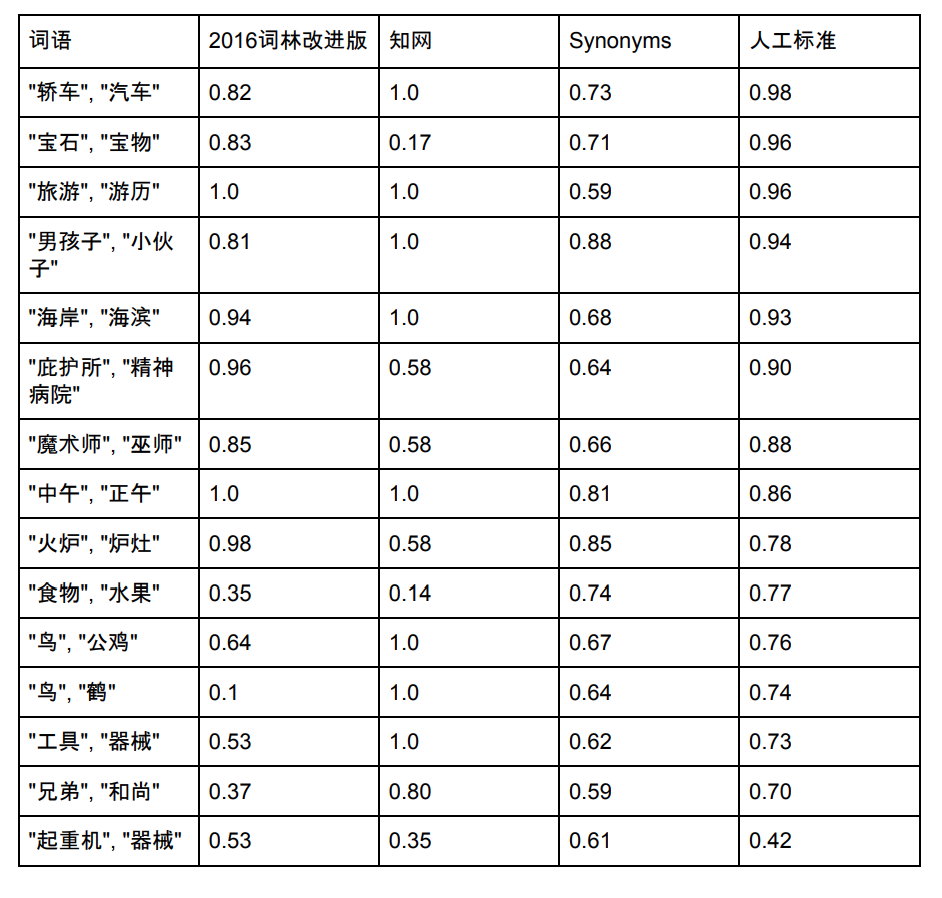
หมายเหตุ: แหล่งที่มาของข้อมูลและคะแนน Synonym Forest และ CNKI คำพ้องความหมายยังได้รับการปรับปรุงอย่างต่อเนื่อง และคะแนนใหม่อาจไม่สอดคล้องกับภาพด้านบน
ผลการเปรียบเทียบเพิ่มเติม
รายชื่อผู้ใช้ที่เกี่ยวข้อง Github
ทดสอบด้วย py3, MacBook Pro
python benchmark.py
++++++++++ ชื่อระบบปฏิบัติการและเวอร์ชัน ++++++++++
แพลตฟอร์ม: ดาร์วิน
เคอร์เนล: 16.7.0
สถาปัตยกรรม: ('64 บิต', '')
++++++++++ แกนซีพียู ++++++++++
แกน: 4
โหลดซีพียู: 60
++++++++++ หน่วยความจำระบบ ++++++++++
เมมโฟน 8GB
synonyms#nearby: 100000 loops, best of 3 epochs: 0.209 usec per loop
52nlp.cn
หัวใจของเครื่อง
บันทึกการแชร์ออนไลน์: Synonyms Chinese synonym toolkit @ 2018-02-07
คำพ้องความหมายเผยแพร่ใบรับรอง MIT ข้อมูลและขั้นตอนอาจนำไปใช้ในการวิจัยและผลิตภัณฑ์เชิงพาณิชย์ และต้องมีการอ้างอิงและกล่าวถึง เช่น ในสื่อ วารสาร นิตยสาร หรือบล็อกที่ตีพิมพ์
@online{Synonyms:hain2017,
author = {Hai Liang Wang, Hu Ying Xi},
title = {中文近义词工具包Synonyms},
year = 2017,
url = {https://github.com/chatopera/Synonyms},
urldate = {2017-09-27}
}
วิกิสนเทศ-คลังข้อมูล
ที่มาของหลักการ word2vec และการวิเคราะห์โค้ด
ไม่รองรับ โปรดดู #5 สำหรับข้อมูลเพิ่มเติม
Word2vec เปิดตัวโดย Google ไลบรารีนี้เขียนด้วยภาษา C มีประสิทธิภาพการใช้หน่วยความจำสูงและมีความเร็วในการฝึกอบรมที่รวดเร็ว gensim สามารถโหลดไฟล์โมเดลที่ส่งออกโดย word2vec
ดู #64 สำหรับรายละเอียด
ไห่เหลียงหวาง
หู หยิงซี
หนังสือเล่มนี้ร่วมเขียนโดยผู้เขียนคำพ้องความหมาย
ลิงค์ซื้อหนังสือด่วน 
"การตอบคำถามอัจฉริยะและการเรียนรู้เชิงลึก" หนังสือเล่มนี้เหมาะสำหรับนักเรียนและวิศวกรซอฟต์แวร์ที่กำลังเตรียมเริ่มต้นการเรียนรู้ด้วยเครื่องและการประมวลผลภาษาธรรมชาติ โดยจะแนะนำหลักการและอัลกอริทึมมากมายในทางทฤษฎี และยังมีโปรแกรมตัวอย่างมากมายเพื่อเพิ่มการใช้งานจริง มีการสรุปไว้ในไลบรารีโค้ดโปรแกรมตัวอย่าง โปรแกรมเหล่านี้ มีไว้เพื่อช่วยให้ทุกคนเข้าใจหลักการและอัลกอริธึม คุณสามารถดาวน์โหลดและดำเนินการได้ ที่อยู่ของฐานรหัสคือ:
https://github.com/l11x0m7/book-of-qna-code
Word2vec โดย Google
วิกิมีเดีย: แหล่งคลังข้อมูลการฝึกอบรม
เกนซิม: word2vec.py
SentenceSim: คลังข้อมูลการประเมินความคล้ายคลึงกัน
jieba: การแบ่งคำภาษาจีน
ใบอนุญาตสาธารณะ Chunsong เวอร์ชัน 1.0
https://bot.chatopera.com/
บริการคลาวด์ Chatopera เป็นบริการคลาวด์แบบครบวงจรสำหรับการใช้งานแชทโรบ็อต และเรียกเก็บเงินตามจำนวนการเรียกอินเทอร์เฟซ Chatopera Cloud Service เป็นอินสแตนซ์ซอฟต์แวร์ในรูปแบบบริการของแพลตฟอร์มบอท Chatopera บริการคลาวด์ Chatopera อิงจากการประมวลผลแบบคลาวด์ เป็นบริการคลาวด์ แบบแชทบอท
แพลตฟอร์มหุ่นยนต์ Chatopera ประกอบด้วยส่วนประกอบต่างๆ เช่น ฐานความรู้ บทสนทนาหลายรอบ การจดจำเจตนาและการรู้จำคำพูด การพัฒนาหุ่นยนต์แชทที่ได้มาตรฐาน และรองรับสถานการณ์ต่างๆ เช่น การถามตอบอัจฉริยะ OA ระดับองค์กร การถามตอบอัจฉริยะด้านทรัพยากรบุคคล การบริการลูกค้าอัจฉริยะ และการตลาดออนไลน์ แผนกไอทีขององค์กรและแผนกธุรกิจใช้บริการคลาวด์ของ Chatopera เพื่อนำแชทบอทออนไลน์อย่างรวดเร็ว!


