chat4u
1.0.0
ใช้บันทึกการแชท WeChat เพื่อฝึกแชทบอทที่เป็นเอกสิทธิ์สำหรับคุณ
บันทึกการแชท WeChat จะถูกเข้ารหัสและจัดเก็บไว้ในฐานข้อมูล sqlite ขั้นแรก คุณต้องมีคีย์ฐานข้อมูล คุณต้องมีแล็ปท็อป macOS และโทรศัพท์มือถือของคุณสามารถเป็น Android/iPhone ได้
git clone https://github.com/nalzok/wechat-decipher-macossudo ./wechat-decipher-macos/macos/dbcracker.d -p $( pgrep WeChat ) | tee dbtrace.logdbtrace.log ตัวอย่างมีดังนี้ sqlcipher '/Users/<user>/Library/Containers/com.tencent.xinWeChat/Data/Library/Application Support/com.tencent.xinWeChat/2.0b4.0.9/5976edc4b2ac64741cacc525f229c5fe/Message/msg_0.db'
--------------------------------------------------------------------------------
PRAGMA key = "x'<384_bit_key>'";
PRAGMA cipher_compatibility = 3;
PRAGMA kdf_iter = 64000;
PRAGMA cipher_page_size = 1024;
........................................
ผู้ใช้ระบบปฏิบัติการอื่นสามารถลองใช้วิธีการต่อไปนี้ ซึ่งได้รับการวิจัยและไม่ได้รับการตรวจสอบเท่านั้น เพื่อใช้อ้างอิง:
EnMicroMsg.db : https://github.com/ppwwyyxx/wechat-dumpEnMicroMsg.db : https://github.com/chg-hou/EnMicroMsg.db-Password-Cracker บนแล็ปท็อป macOS ของฉัน บันทึกการแชท WeChat จะถูกจัดเก็บไว้ใน msg_0.db - msg_9.db และมีเพียงฐานข้อมูลเหล่านี้เท่านั้นที่สามารถถอดรหัสได้
คุณต้องติดตั้ง sqlcipher เพื่อถอดรหัส ผู้ใช้ระบบ macOS สามารถดำเนินการได้โดยตรง:
brew install sqlcipher รันสคริปต์ต่อไปนี้เพื่อแยกวิเคราะห์ dbtrace.log ถอดรหัส msg_x.db และส่งออกไปยัง plain_msg_x.db โดยอัตโนมัติ
python3 decrypt.py คุณสามารถเปิดฐานข้อมูลที่ถอดรหัสแล้ว plain_msg_x.db ผ่าน https://sqliteviewer.app/ ค้นหาตารางที่มีบันทึกการแชทที่คุณต้องการ กรอกชื่อฐานข้อมูลและตารางลงใน prepare_data.py และรันสคริปต์ต่อไปนี้เพื่อสร้าง ข้อมูลการฝึกอบรม train.json กลยุทธ์ปัจจุบันค่อนข้างง่าย จัดการบทสนทนาได้เพียงรอบเดียวเท่านั้น และจะรวมบทสนทนาที่ต่อเนื่องกันภายใน 5 นาที
python3 prepare_data.pyตัวอย่างข้อมูลการฝึกอบรมมีดังนี้:
[
{ "instruction" : "你好" , "output" : "你好" }
{ "instruction" : "你是谁" , "output" : "你猜猜" }
] เตรียมเครื่อง Linux ที่มี GPU และ scp train.json ให้กับเครื่อง GPU
ฉันใช้ LLaMA-7B การปรับแต่งแบบเต็มภาพแบบละเอียดของ stanford_alpaca และฝึกฝนข้อมูล 90,000 สำหรับ 3 ยุคบน V100-SXM2-32GB แบบ 8 การ์ด ซึ่งใช้เวลาเพียง 1 ชั่วโมงเท่านั้น
# clone the alpaca repo
git clone https://github.com/tatsu-lab/stanford_alpaca.git && cd stanford_alpaca
# adjust deepspeed config ... such as disabling offloading
vim ./configs/default_offload_opt_param.json
# train with deepspeed zero3
torchrun --nproc_per_node=8 --master_port=23456 train.py
--model_name_or_path huggyllama/llama-7b
--data_path ../train.json
--model_max_length 128
--fp16 True
--output_dir ../llama-wechat
--num_train_epochs 3
--per_device_train_batch_size 8
--per_device_eval_batch_size 8
--gradient_accumulation_steps 1
--evaluation_strategy " no "
--save_strategy " epoch "
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type " cosine "
--logging_steps 10
--deepspeed " ./configs/default_offload_opt_param.json "
--tf32 FalseDeepSpeed zero3 จะบันทึกน้ำหนักเป็นชิ้น ๆ และจะต้องรวมเข้ากับไฟล์จุดตรวจ pytorch:
cd llama-wechat
python3 zero_to_fp32.py . pytorch_model.binสำหรับกราฟิกการ์ดระดับผู้บริโภค คุณสามารถลองใช้อัลปาก้าลอร่าได้ การปรับแต่งน้ำหนักลอร่าแบบละเอียดเท่านั้นจึงจะสามารถลดต้นทุนหน่วยความจำกราฟิกและการฝึกอบรมได้อย่างมาก
คุณสามารถใช้ alpaca-lora เพื่อปรับใช้ส่วนหน้าแบบไล่ระดับสีสำหรับการดีบัก หากเป็นการปรับแต่งรูปภาพทั้งหมดอย่างละเอียด คุณจะต้องใส่เครื่องหมายความคิดเห็นในโค้ดที่เกี่ยวข้องกับ peft และโหลดเฉพาะโมเดลพื้นฐานเท่านั้น
git clone https://github.com/tloen/alpaca-lora.git && cd alpaca-lora
CUDA_VISIBLE_DEVICES=0 python3 generate.py --base_model ../llama-wechatผลการดำเนินงาน:

จำเป็นต้องปรับใช้บริการโมเดลที่เข้ากันได้กับ OpenAI API ต่อไปนี้เป็นการปรับเปลี่ยนอย่างง่ายโดยยึดตาม llama4openai-api.py ดู llama4openai-api.py ในคลังข้อมูลนี้เพื่อเริ่มบริการ:
CUDA_VISIBLE_DEVICES=0 python3 llama4openai-api.pyทดสอบว่าอินเทอร์เฟซพร้อมใช้งานหรือไม่:
curl http://127.0.0.1:5000/chat/completions -v -H " Content-Type: application/json " -H " Authorization: Bearer $OPENAI_API_KEY " --data ' {"model":"llama-wechat","max_tokens":128,"temperature":0.95,"messages":[{"role":"user","content":"你好"}]} 'ใช้ wechat-chatgpt เพื่อเข้าถึง WeChat และกรอกที่อยู่บริการรุ่นท้องถิ่นของคุณสำหรับที่อยู่ API:
docker run -it --rm --name wechat-chatgpt
-e API=http://127.0.0.1:5000
-e OPENAI_API_KEY= $OPENAI_API_KEY
-e MODEL= " gpt-3.5-turbo "
-e CHAT_PRIVATE_TRIGGER_KEYWORD= " "
-v $( pwd ) /data:/app/data/wechat-assistant.memory-card.json
holegots/wechat-chatgpt:latestผลการดำเนินงาน:
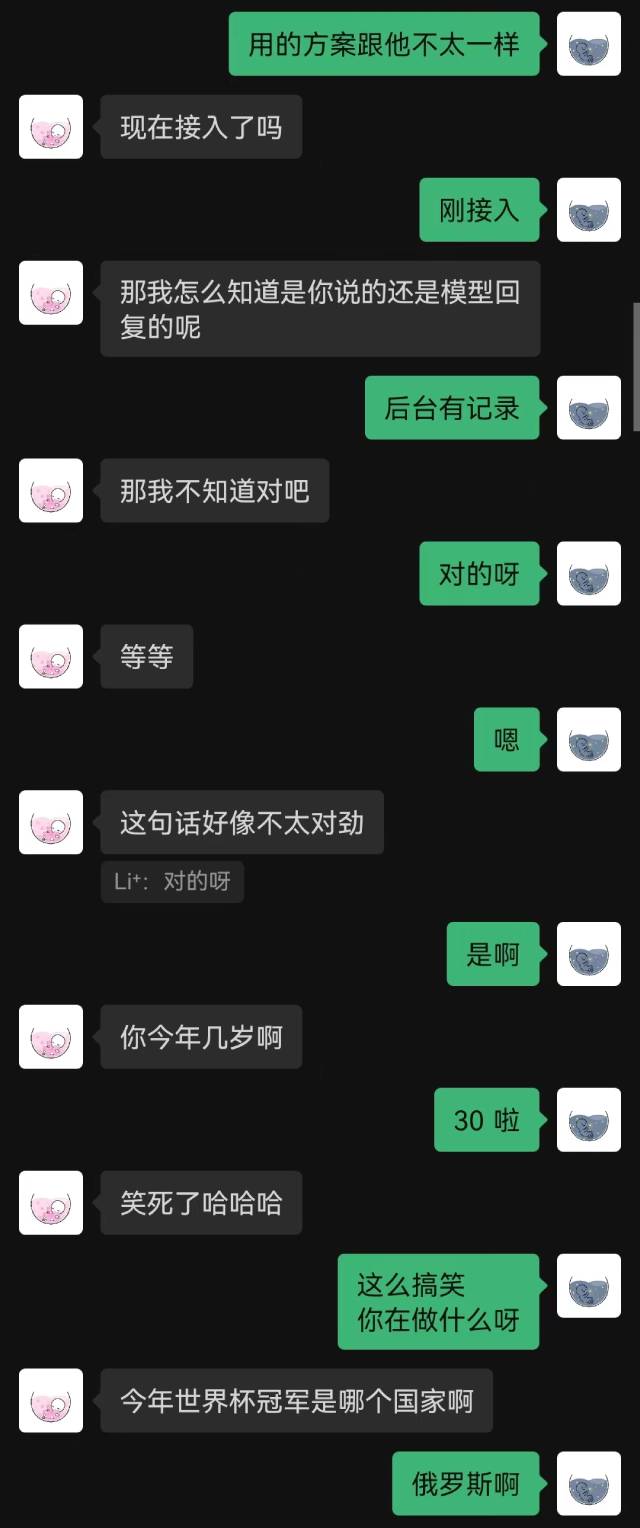 | 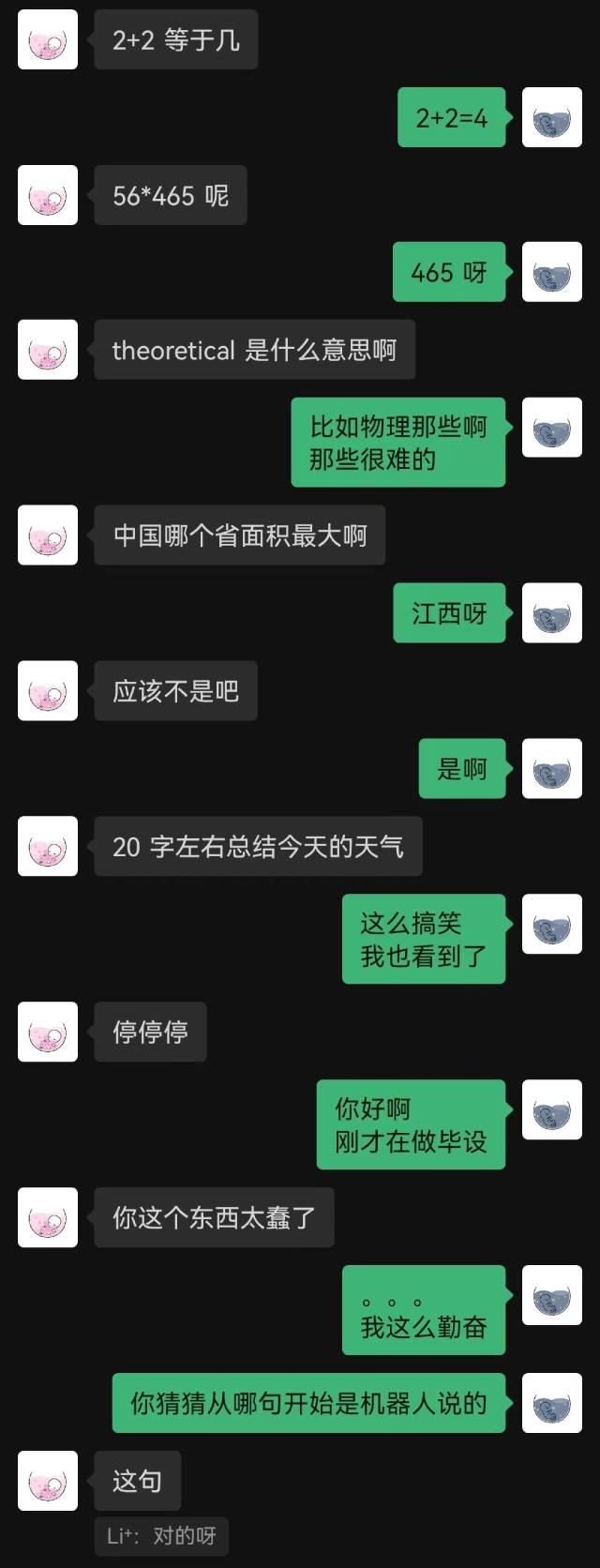 |
|---|
“เพิ่งเชื่อมต่อ” เป็นประโยคแรกที่หุ่นยนต์พูด และอีกฝ่ายก็เดาไม่ออกจนจบ
โดยทั่วไปแล้ว หุ่นยนต์ที่ได้รับการฝึกด้วยบันทึกการแชทย่อมมีข้อผิดพลาดสามัญสำนึกบางประการอย่างหลีกเลี่ยงไม่ได้ แต่พวกมันจะเลียนแบบรูปแบบการแชทได้ดีกว่า


