msg_reply
1.0.0
คุณเคยเห็นหรือใช้ Google Smart Reply หรือไม่? เป็นบริการที่ให้คำแนะนำตอบกลับอัตโนมัติสำหรับข้อความของผู้ใช้ ดูด้านล่าง
นี่เป็นแอปพลิเคชั่นที่มีประโยชน์ของแชทบอตที่ใช้การดึงข้อมูล ลองคิดดูสิ กี่ครั้งแล้วที่เราส่งข้อความ เช่น ขอบคุณ เฮ้ หรือ แล้วพบกันใหม่ ? ในโปรเจ็กต์นี้ เราสร้างระบบแนะนำการตอบกลับข้อความอย่างง่าย
ปาร์คคยูบยอง
การตรวจสอบรหัสโดย Yj Choe
เราจำเป็นต้องกำหนดรายการข้อเสนอแนะที่จะแสดง โดยปกติแล้ว ความถี่จะถือเป็นอันดับแรก แต่วลีเหล่านั้นที่มีความหมายคล้ายกันล่ะ? ตัวอย่างเช่น ควร ขอบคุณมาก และ ขอบคุณที่ได้ รับการปฏิบัติอย่างเป็นอิสระหรือไม่? เราไม่คิดอย่างนั้น เราต้องการจัดกลุ่มและบันทึกช่องของเรา ยังไง? เราใช้คลังข้อมูลแบบขนาน ทั้ง ขอบคุณมาก และ ขอบคุณ น่าจะแปลเป็นข้อความเดียวกัน ตามสมมติฐานนี้ เราสร้างกลุ่มคำพ้องภาษาอังกฤษที่ใช้คำแปลเดียวกัน
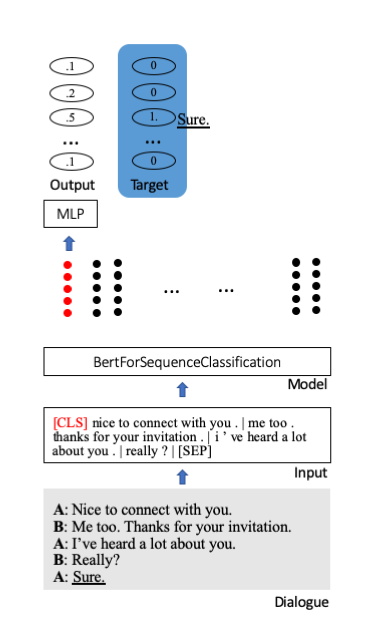
เราปรับแต่งโมเดล Bert ที่ได้รับการฝึกล่วงหน้าของ Huggingface เพื่อการจำแนกลำดับ ในนั้นโทเค็นเริ่มต้นพิเศษ [CLS] จะจัดเก็บข้อมูลทั้งหมดของประโยค มีการแนบเลเยอร์พิเศษเพื่อฉายข้อมูลที่ย่อไปยังหน่วยการจำแนกประเภท (ที่นี่ 100)
เราใช้คลังข้อมูลคู่ขนานภาษาสเปน-อังกฤษของ OpenSubtitles 2018 เพื่อสร้างกลุ่มคำพ้องความหมาย OpenSubtitles คือชุดคำบรรยายภาพยนตร์ที่แปลจำนวนมาก ข้อมูล en-es ประกอบด้วยเส้นที่จัดชิดกันมากกว่า 61M
ตามหลักการแล้ว จำเป็นต้องมีคลังข้อมูลโต้ตอบขนาดใหญ่ (มาก) สำหรับการฝึกอบรม ซึ่งเราไม่พบ เราใช้ Cornell Movie Dialogue Corpus แทน ประกอบด้วยบทสนทนา 83,097 บทหรือ 304,713 บรรทัด
หลาม>=3.6
ทีคิวเอ็ม>=4.30.0
ไพทอร์ช>=1.0
pytorch_pretrained_bert>=0.6.1
nltk>=3.4
ขั้นตอนที่ 0 ดาวน์โหลดข้อมูลคู่ขนานภาษาสเปน-อังกฤษของ OpenSubtitles 2018
bash download.sh
ขั้นตอนที่ 1 สร้างกลุ่มคำพ้องความหมายจากคลังข้อมูล
python construct_sg.py
ขั้นตอนที่ 2 สร้างพจนานุกรม phr2sg_id และ sg_id2phr
python make_phr2sg_id.py
ขั้นตอนที่ 3 แปลงข้อความภาษาอังกฤษเป็นภาษาเดียวเป็นรหัส
python encode.py
ขั้นตอนที่ 4 สร้างข้อมูลการฝึกอบรมและบันทึกเป็นของดอง
python prepro.py
ขั้นตอนที่ 5 ฝึก
python train.py
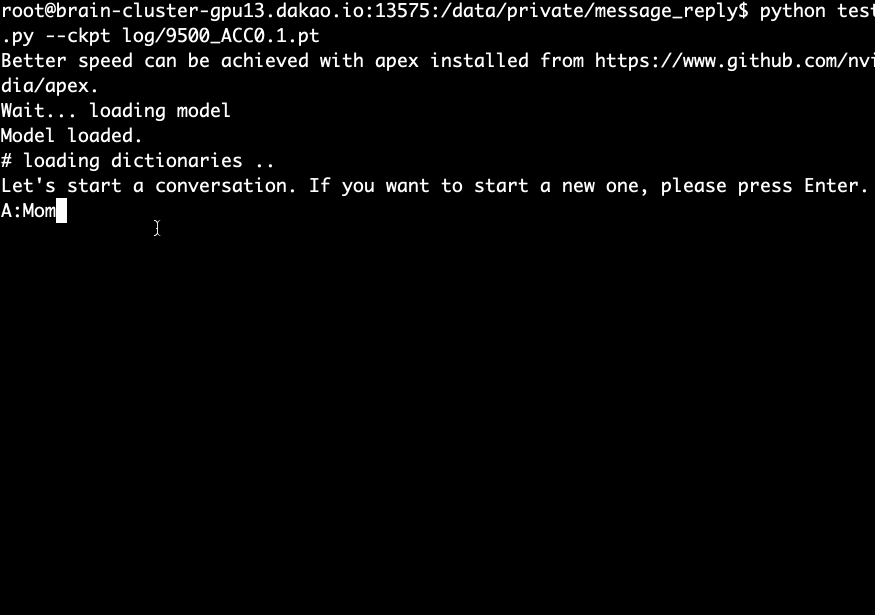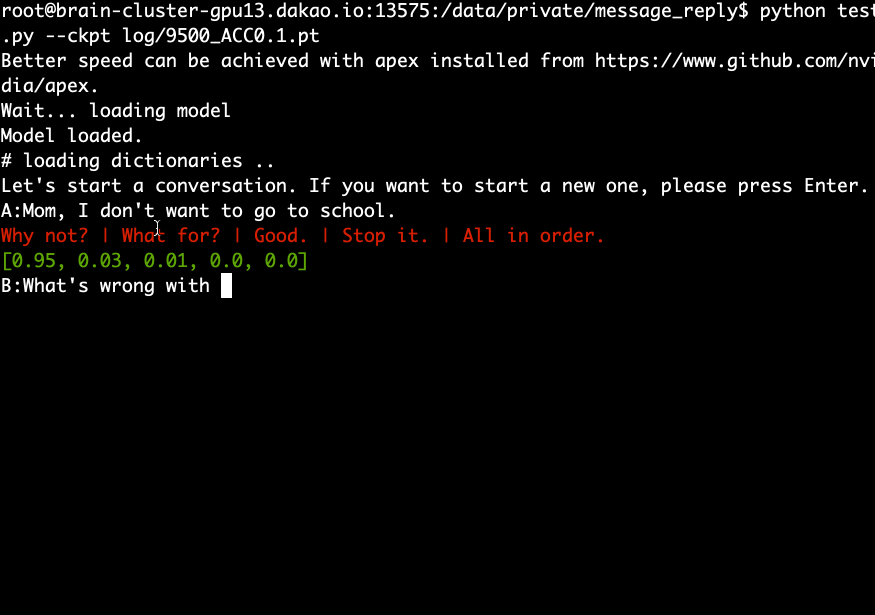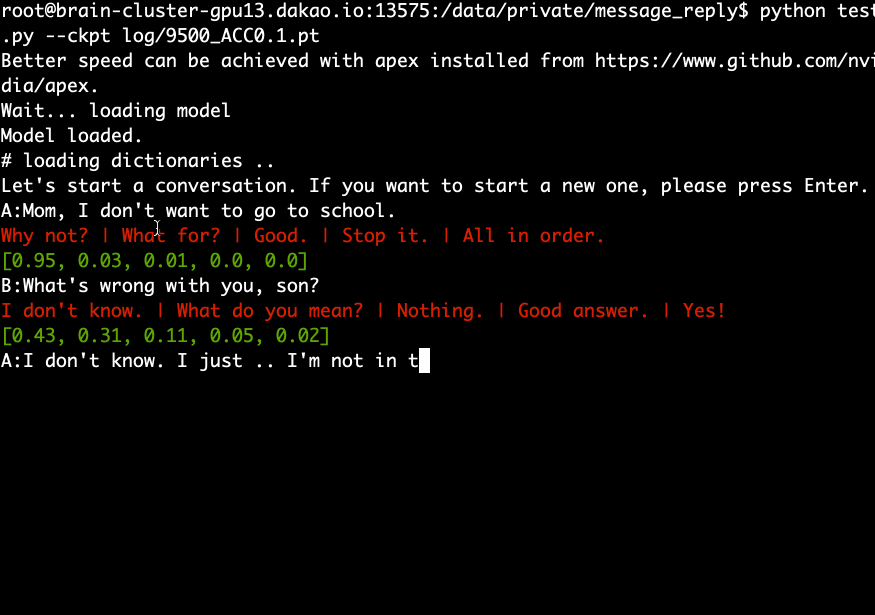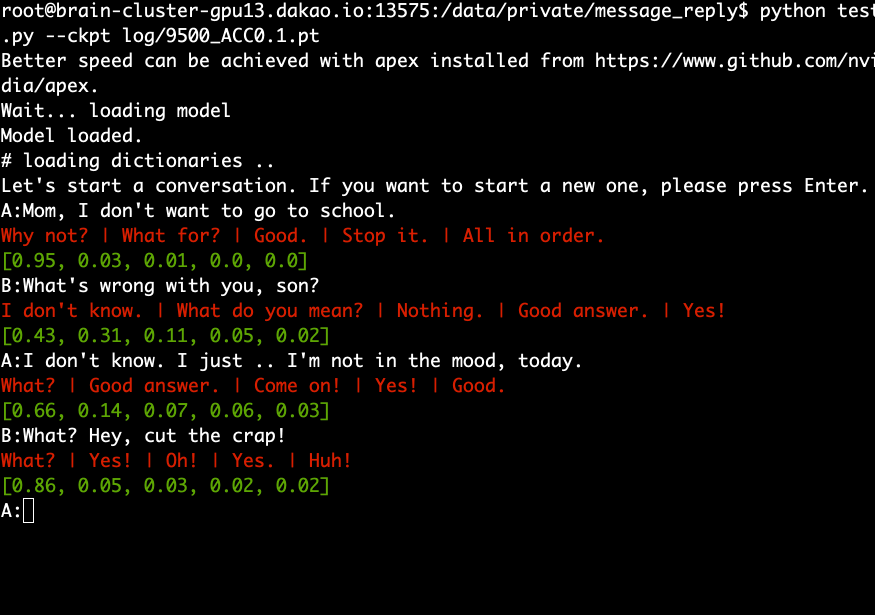
ดาวน์โหลดและแยกโมเดลที่ได้รับการฝึกอบรมล่วงหน้าแล้วรันคำสั่งต่อไปนี้
python test.py --ckpt log/9500_ACC0.1.pt
การสูญเสียการฝึกอย่างช้าๆ แต่ลดลงอย่างต่อเนื่อง
ความแม่นยำ@5 ในข้อมูลการประเมินอยู่ระหว่าง 10 ถึง 20 เปอร์เซ็นต์
สำหรับการใช้งานจริง จำเป็นต้องมีคลังข้อมูลที่ใหญ่กว่ามาก
ไม่แน่ใจว่าสคริปต์ภาพยนตร์มีความคล้ายคลึงกับบทสนทนาข้อความมากแค่ไหน
กลยุทธ์ที่ดีกว่าสำหรับการสร้างกลุ่มคำพ้องความหมายเป็นสิ่งจำเป็น
แชทบอตแบบดึงข้อมูลเป็นแอปพลิเคชันที่สมจริง เนื่องจากปลอดภัยและง่ายกว่าแบบตามรุ่น


