ThinkRAG
1.0.0
อังกฤษ |. จีนตัวย่อ
ระบบสร้างการปรับปรุงการดึงข้อมูลแบบจำลองขนาดใหญ่ของ ThinkRAG สามารถติดตั้งบนแล็ปท็อปได้อย่างง่ายดาย เพื่อตอบคำถามอันชาญฉลาดในฐานความรู้ในท้องถิ่น
ระบบนี้สร้างขึ้นโดยใช้ LlamaIndex และ Streamlit และได้รับการปรับปรุงให้เหมาะสมสำหรับผู้ใช้ในประเทศในหลายด้าน เช่น การเลือกรุ่นและการประมวลผลข้อความ
ThinkRAG คือระบบแอปพลิเคชันแบบจำลองขนาดใหญ่ที่พัฒนาขึ้นสำหรับมืออาชีพ นักวิจัย นักศึกษา และพนักงานที่มีความรู้อื่นๆ โดยสามารถใช้งานได้โดยตรงบนแล็ปท็อป และข้อมูลฐานความรู้จะถูกบันทึกไว้ในเครื่องคอมพิวเตอร์
ThinkRAG มีคุณสมบัติดังต่อไปนี้:
โดยเฉพาะอย่างยิ่ง ThinkRAG ได้ทำการปรับแต่งและเพิ่มประสิทธิภาพมากมายสำหรับผู้ใช้ในประเทศ:
ThinkRAG สามารถใช้ทุกรุ่นที่รองรับโดยเฟรมข้อมูล LlamaIndex สำหรับข้อมูลรายการรุ่น โปรดดูเอกสารประกอบที่เกี่ยวข้อง
ThinkRAG มุ่งมั่นที่จะสร้างระบบแอปพลิเคชันที่ใช้งานได้โดยตรง มีประโยชน์ และใช้งานง่าย
ดังนั้นเราจึงตัดสินใจเลือกอย่างรอบคอบและแลกเปลี่ยนระหว่างรุ่น ส่วนประกอบ และเทคโนโลยีต่างๆ
ประการแรก ThinkRAG ที่ใช้โมเดลขนาดใหญ่รองรับ OpenAI API และ LLM API ที่เข้ากันได้ทั้งหมด รวมถึงผู้ผลิตโมเดลขนาดใหญ่กระแสหลักในประเทศ เช่น:
หากคุณต้องการปรับใช้โมเดลขนาดใหญ่ภายในเครื่อง ThinkRAG เลือก Ollama ซึ่งใช้งานง่ายและสะดวก เราสามารถดาวน์โหลดโมเดลขนาดใหญ่เพื่อเรียกใช้ภายในเครื่องผ่าน Ollama
ปัจจุบัน Ollama รองรับการใช้งานแบบโลคัลไลซ์ของโมเดลขนาดใหญ่กระแสหลักเกือบทั้งหมด รวมถึง Llama, Gemma, GLM, Mistral, Phi, Llava ฯลฯ สำหรับรายละเอียด กรุณาเยี่ยมชมเว็บไซต์อย่างเป็นทางการของ Ollama ด้านล่าง
ระบบยังใช้โมเดลแบบฝังและโมเดลที่จัดเรียงใหม่ และรองรับโมเดลส่วนใหญ่จาก Hugging Face ปัจจุบัน ThinkRAG ใช้รุ่นซีรีส์ BGE ของ BAAI เป็นหลัก ผู้ใช้ในประเทศสามารถเยี่ยมชมเว็บไซต์มิเรอร์เพื่อเรียนรู้และดาวน์โหลด
หลังจากดาวน์โหลดโค้ดจาก Github แล้ว ให้ใช้ pip เพื่อติดตั้งส่วนประกอบที่จำเป็น
pip3 install -r requirements.txtหากต้องการใช้งานระบบออฟไลน์ โปรดดาวน์โหลด Ollama จากเว็บไซต์อย่างเป็นทางการก่อน จากนั้นใช้คำสั่ง Ollama เพื่อดาวน์โหลดโมเดลขนาดใหญ่ เช่น GLM, Gemma และ QWen
ดาวน์โหลดโมเดลการฝัง (BAAI/bge-large-zh-v1.5) และโมเดลการจัดอันดับใหม่ (BAAI/bge-reranker-base) แบบซิงโครนัสจาก Hugging Face ไปยังไดเร็กทอรี localmodels
สำหรับขั้นตอนเฉพาะ โปรดดูเอกสารในไดเรกทอรีเอกสาร: HowToDownloadModels.md
เพื่อให้ได้ประสิทธิภาพที่ดีขึ้น ขอแนะนำให้ใช้ LLM API โมเดลขนาดใหญ่เชิงพาณิชย์ที่มีพารามิเตอร์หลายแสนล้านรายการ
ขั้นแรก รับคีย์ API จากผู้ให้บริการ LLM และกำหนดค่าตัวแปรสภาพแวดล้อมต่อไปนี้
ZHIPU_API_KEY = " "
MOONSHOT_API_KEY = " "
DEEPSEEK_API_KEY = " "
OPENAI_API_KEY = " "คุณสามารถข้ามขั้นตอนนี้และกำหนดค่าคีย์ API ผ่านทางอินเทอร์เฟซของแอปพลิเคชันหลังจากที่ระบบกำลังทำงาน
หากคุณเลือกใช้ LLM API อย่างน้อย 1 รายการ โปรดลบผู้ให้บริการที่คุณไม่ได้ใช้อีกต่อไปในไฟล์การกำหนดค่า config.py
แน่นอน คุณสามารถเพิ่มผู้ให้บริการรายอื่นที่เข้ากันได้กับ OpenAI API ในไฟล์การกำหนดค่าได้
ThinkRAG ทำงานในโหมดการพัฒนาตามค่าเริ่มต้น ในโหมดนี้ ระบบจะใช้พื้นที่จัดเก็บไฟล์ในเครื่อง และคุณไม่จำเป็นต้องติดตั้งฐานข้อมูลใดๆ
หากต้องการสลับไปยังโหมดการใช้งานจริง คุณสามารถกำหนดค่าตัวแปรสภาพแวดล้อมได้ดังต่อไปนี้
THINKRAG_ENV = productionในโหมดการผลิต ระบบจะใช้ฐานข้อมูลเวกเตอร์ Chroma และฐานข้อมูลคีย์-ค่า Redis
หากคุณไม่ได้ติดตั้ง Redis ขอแนะนำให้ติดตั้งผ่าน Docker หรือใช้อินสแตนซ์ Redis ที่มีอยู่ โปรดกำหนดค่าข้อมูลพารามิเตอร์ของอินสแตนซ์ Redis ในไฟล์ config.py
ตอนนี้คุณพร้อมที่จะรัน ThinkRAG แล้ว
โปรดรันคำสั่งต่อไปนี้ในไดเร็กทอรีที่มีไฟล์ app.py
streamlit run app.pyระบบจะทำงานและเปิด URL ต่อไปนี้บนเบราว์เซอร์โดยอัตโนมัติเพื่อแสดงอินเทอร์เฟซแอปพลิเคชัน
http://localhost:8501/
การวิ่งครั้งแรกอาจใช้เวลาสักครู่ หากไม่ได้ดาวน์โหลดโมเดลที่ฝังไว้บน Hugging Face ล่วงหน้า ระบบจะดาวน์โหลดโมเดลโดยอัตโนมัติ และคุณจะต้องรอนานกว่านั้น
ThinkRAG รองรับการกำหนดค่าและการเลือกรุ่นขนาดใหญ่ในส่วนติดต่อผู้ใช้ ซึ่งรวมถึง: URL ฐานและคีย์ API ของ LLM API รุ่นขนาดใหญ่ และคุณสามารถเลือกรุ่นเฉพาะที่จะใช้ได้ เช่น glm-4 ของ ThinkRAG
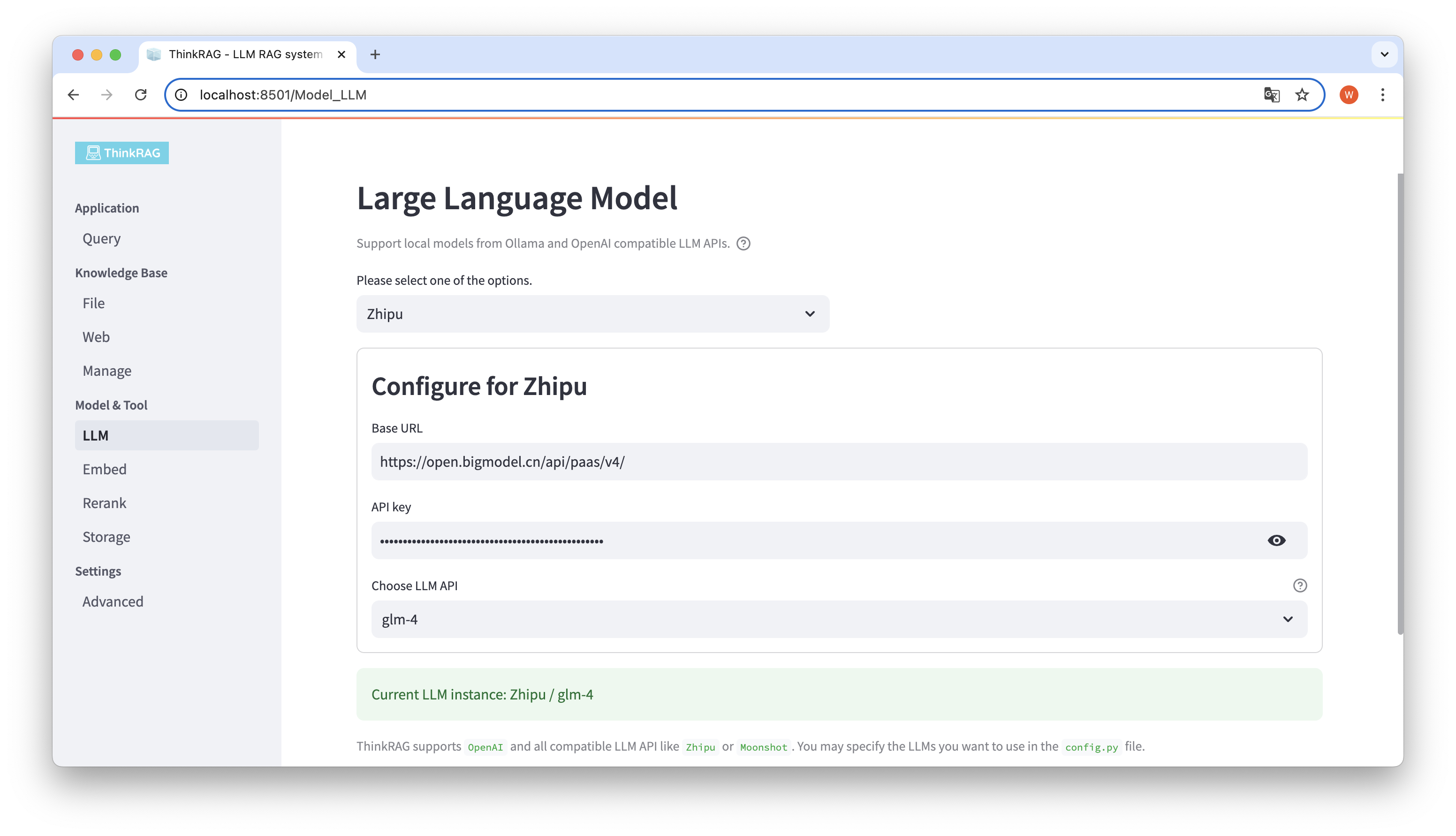
ระบบจะตรวจจับโดยอัตโนมัติว่า API และคีย์พร้อมใช้งานหรือไม่ หากมี อินสแตนซ์โมเดลขนาดใหญ่ที่เลือกในปัจจุบันจะแสดงเป็นข้อความสีเขียวที่ด้านล่าง
ในทำนองเดียวกัน ระบบสามารถรับโมเดลที่ดาวน์โหลดโดย Ollama ได้โดยอัตโนมัติ และผู้ใช้สามารถเลือกโมเดลที่ต้องการบนอินเทอร์เฟซผู้ใช้ได้
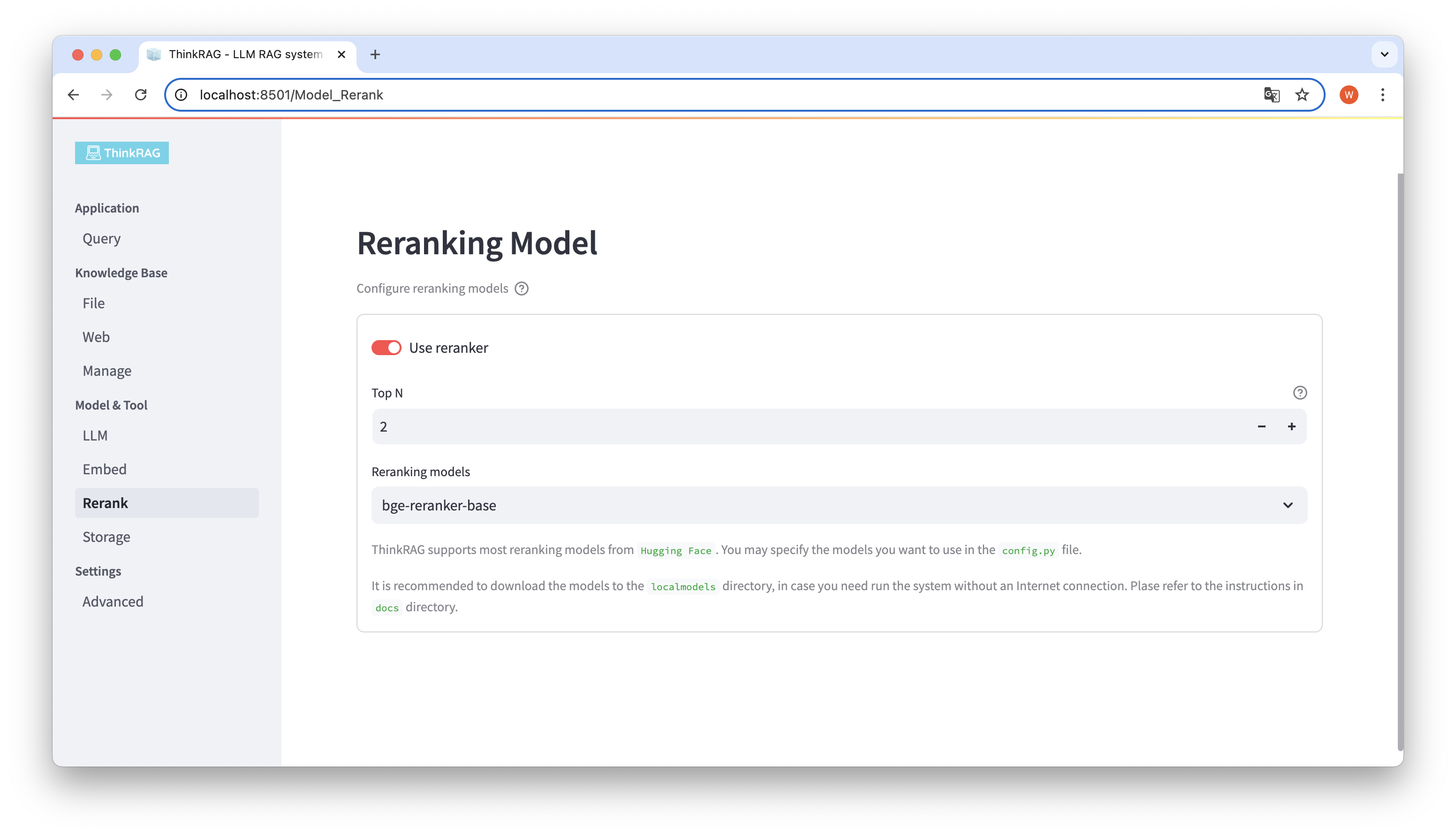
หากคุณดาวน์โหลดโมเดลแบบฝังและจัดเรียงโมเดลใหม่ไปยังไดเร็กทอรี localmodels ในเครื่อง บนอินเทอร์เฟซผู้ใช้ คุณสามารถสลับรุ่นที่เลือกและตั้งค่าพารามิเตอร์ของรุ่นที่จัดเรียงใหม่ เช่น Top N
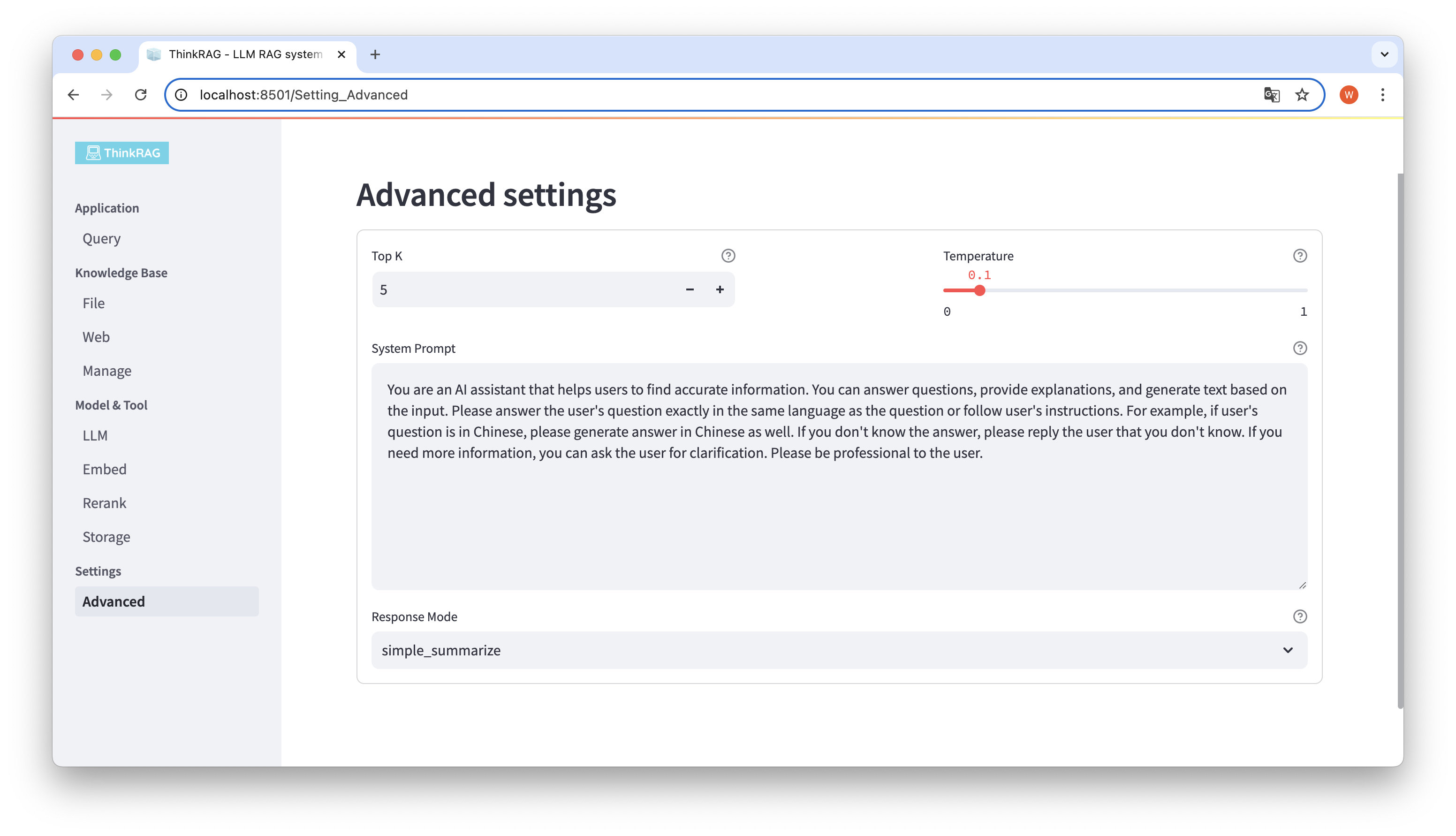
ในแถบนำทางด้านซ้าย คลิกการตั้งค่าขั้นสูง (การตั้งค่า-ขั้นสูง) คุณยังสามารถตั้งค่าพารามิเตอร์ต่อไปนี้:
ด้วยการใช้พารามิเตอร์ที่แตกต่างกัน เราสามารถเปรียบเทียบเอาท์พุตของโมเดลขนาดใหญ่ และค้นหาชุดค่าผสมของพารามิเตอร์ที่มีประสิทธิภาพมากที่สุด
ThinkRAG รองรับการอัพโหลดไฟล์ต่างๆ เช่น PDF, DOCX, PPTX ฯลฯ และยังรองรับการอัพโหลด URL ของหน้าเว็บอีกด้วย
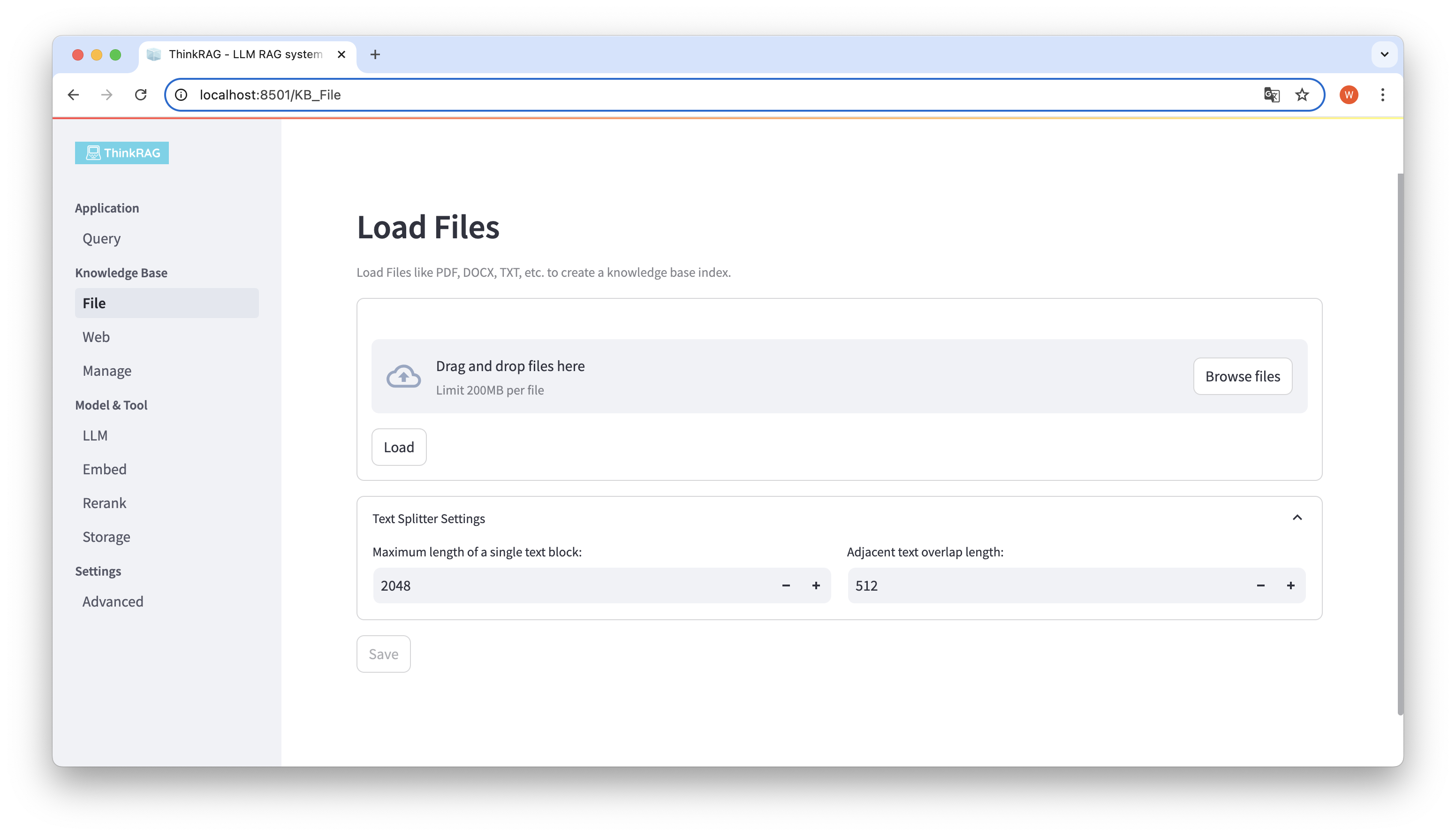
คลิกปุ่มเรียกดูไฟล์ เลือกไฟล์บนคอมพิวเตอร์ของคุณ จากนั้นคลิกปุ่มโหลดเพื่อโหลดจะแสดงรายการ
จากนั้นคลิกปุ่มบันทึก จากนั้นระบบจะประมวลผลไฟล์ รวมถึงการแบ่งส่วนข้อความและการฝัง และบันทึกลงในฐานความรู้
ในทำนองเดียวกัน คุณสามารถป้อนหรือวาง URL ของหน้าเว็บ รับข้อมูลหน้าเว็บ และบันทึกลงในฐานความรู้หลังการประมวลผล
ระบบรองรับการจัดการฐานความรู้
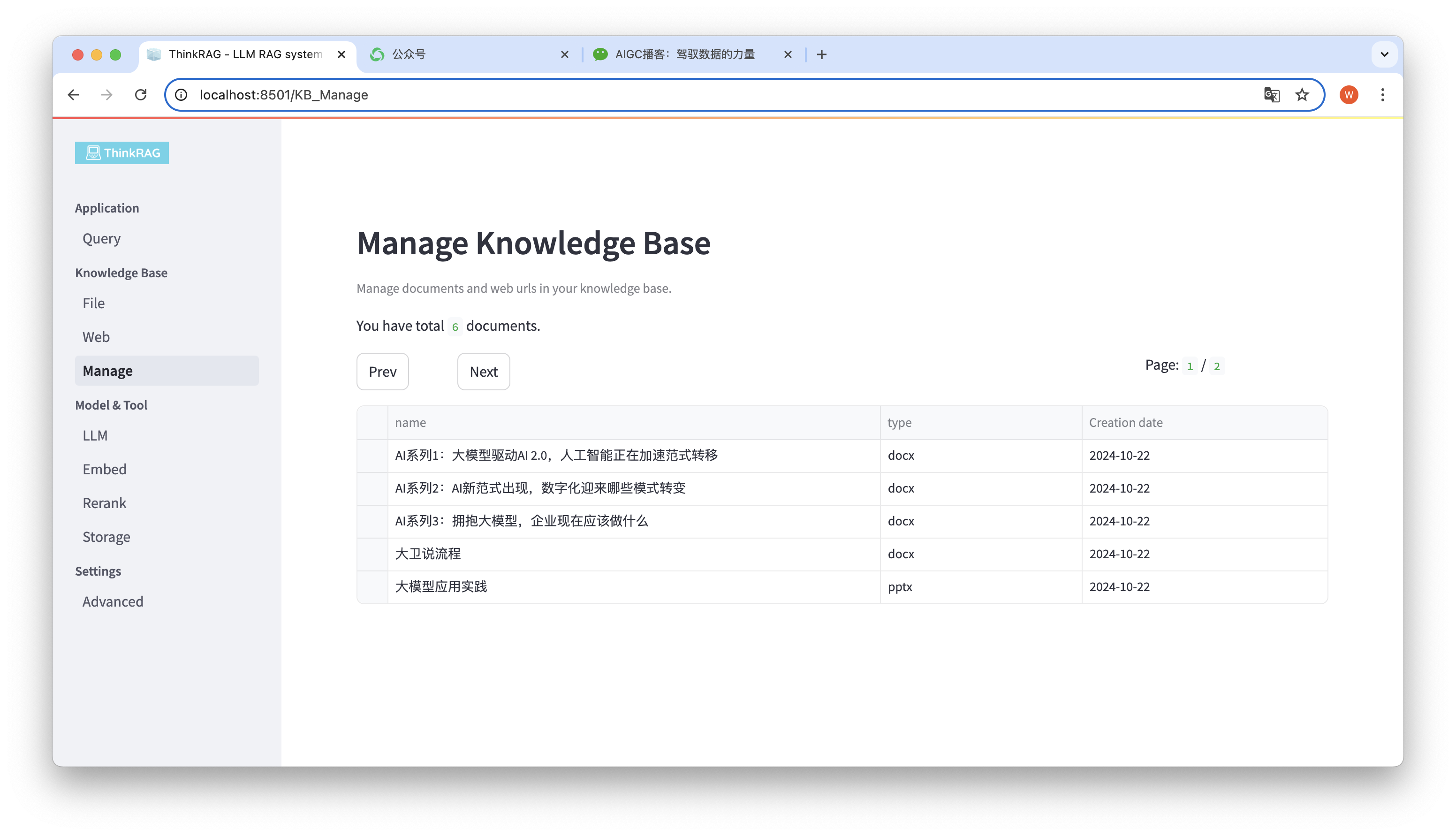
ดังแสดงในรูปด้านบน ThinkRAG สามารถแสดงรายการเอกสารทั้งหมดในฐานความรู้ในหน้าต่างๆ
เลือกเอกสารที่จะลบ และปุ่ม ลบเอกสารที่เลือก จะปรากฏขึ้น คลิกปุ่มนี้เพื่อลบเอกสารออกจากฐานความรู้
ในแถบนำทางด้านซ้าย คลิกแบบสอบถาม จากนั้นหน้าถามตอบอัจฉริยะจะปรากฏขึ้น
หลังจากป้อนคำถามแล้ว ระบบจะค้นหาฐานความรู้และให้คำตอบ ในระหว่างกระบวนการนี้ ระบบจะใช้เทคโนโลยี เช่น การดึงข้อมูลแบบไฮบริดและการจัดเรียงใหม่ เพื่อให้ได้เนื้อหาที่ถูกต้องจากฐานความรู้
ตัวอย่างเช่น เราได้อัปโหลดเอกสาร Word ในฐานความรู้: "David Says Process.docx"
ตอนนี้ให้ป้อนคำถาม: "คุณลักษณะสามประการของกระบวนการคืออะไร"
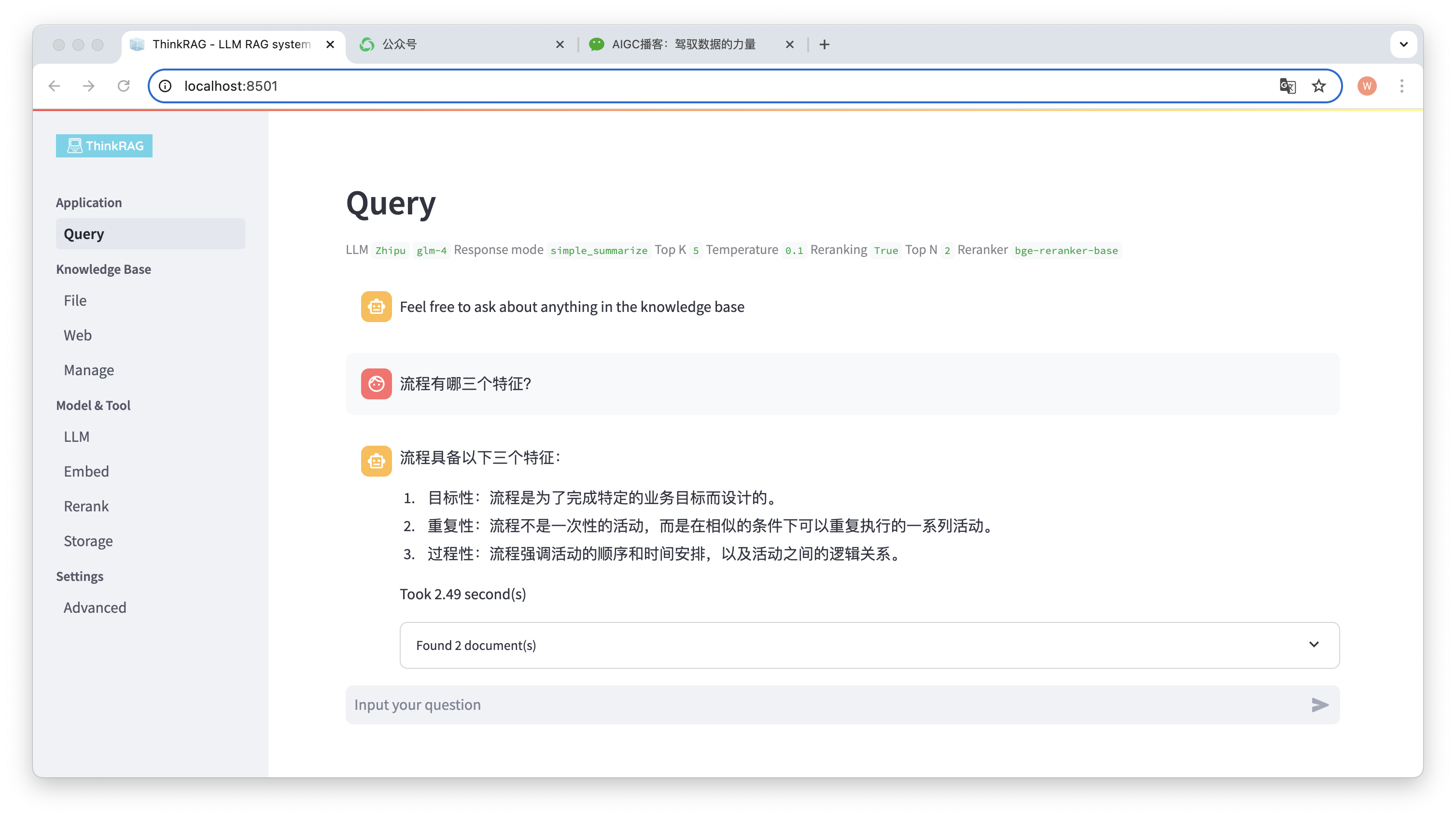
ดังที่แสดงในภาพ ระบบใช้เวลา 2.49 วินาทีในการให้คำตอบที่ถูกต้อง: กระบวนการนี้เป็นแบบกำหนดเป้าหมาย ทำซ้ำ และเป็นขั้นตอน ในเวลาเดียวกัน ระบบยังจัดเตรียมเอกสารที่เกี่ยวข้อง 2 ฉบับที่ดึงมาจากฐานความรู้
จะเห็นได้ว่า ThinkRAG ใช้งานฟังก์ชั่นการสร้างแบบจำลองขนาดใหญ่ที่ได้รับการปรับปรุงอย่างสมบูรณ์และมีประสิทธิภาพโดยอาศัยฐานความรู้ในท้องถิ่น
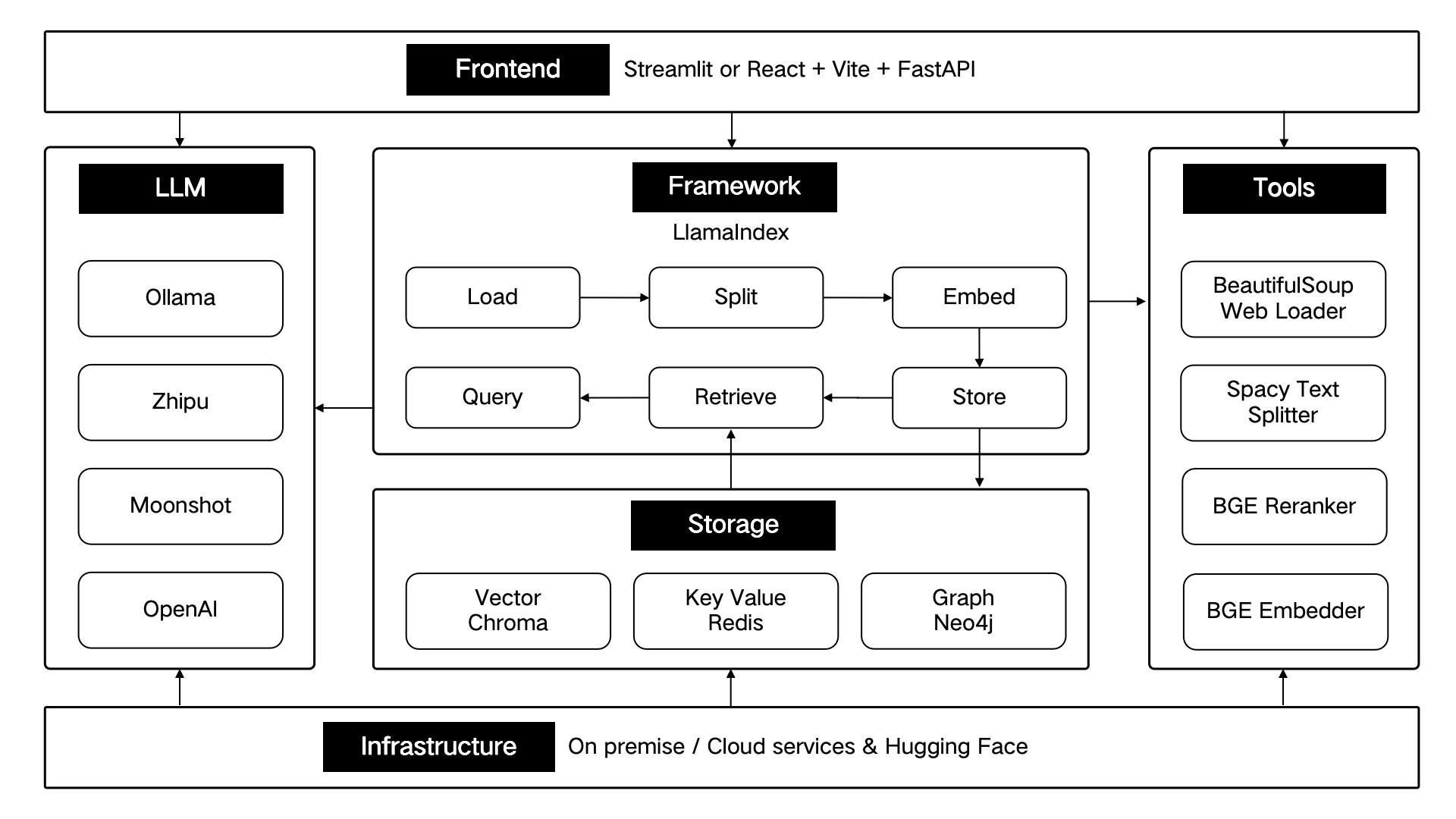
ThinkRAG ได้รับการพัฒนาโดยใช้เฟรมเวิร์กข้อมูล LlamaIndex และใช้ Streamlit สำหรับส่วนหน้า โหมดการพัฒนาและโหมดการใช้งานจริงของระบบใช้องค์ประกอบทางเทคนิคที่แตกต่างกันตามลำดับ ดังแสดงในตารางต่อไปนี้:
| โหมดการพัฒนา | โหมดการผลิต | |
|---|---|---|
| กรอบงาน RAG | ลามะIndex | ลามะIndex |
| กรอบส่วนหน้า | สตรีมไลท์ | สตรีมไลท์ |
| โมเดลฝังตัว | BAAI/bge-ขนาดเล็ก-zh-v1.5 | BAAI/bge-ขนาดใหญ่-zh-v1.5 |
| จัดเรียงโมเดลใหม่ | BAAI/bge-reranker-base | BAAI/bge-reranker-ขนาดใหญ่ |
| ตัวแยกข้อความ | ตัวแยกประโยค | SpacyTextSplitter |
| ที่เก็บข้อมูลการสนทนา | SimpleChatStore | เรดิส |
| การจัดเก็บเอกสาร | SimpleDocumentStore | เรดิส |
| การจัดเก็บดัชนี | SimpleIndexStore | เรดิส |
| การจัดเก็บเวกเตอร์ | SimpleVectorStore | แลนซ์ดีบี |
ส่วนประกอบทางเทคนิคเหล่านี้ได้รับการออกแบบทางสถาปัตยกรรมตามหกส่วน: ส่วนหน้า เฟรมเวิร์ก โมเดลขนาดใหญ่ เครื่องมือ พื้นที่เก็บข้อมูล และโครงสร้างพื้นฐาน
ดังที่แสดงด้านล่าง:
ThinkRAG จะยังคงเพิ่มประสิทธิภาพฟังก์ชันหลักต่อไป และปรับปรุงประสิทธิภาพและความแม่นยำในการดึงข้อมูลต่อไป โดยหลักๆ ได้แก่:
ในเวลาเดียวกัน เราจะปรับปรุงสถาปัตยกรรมแอปพลิเคชันเพิ่มเติมและปรับปรุงประสบการณ์ผู้ใช้ ซึ่งส่วนใหญ่ได้แก่:
คุณสามารถเข้าร่วมโครงการโอเพ่นซอร์ส ThinkRAG และทำงานร่วมกันเพื่อสร้างผลิตภัณฑ์ AI ที่ผู้ใช้ชื่นชอบ!
ThinkRAG ใช้ใบอนุญาต MIT


