local LLM with RAG
1.0.0

โปรเจ็กต์นี้เป็นแซนด์บ็อกซ์ทดลองสำหรับทดสอบแนวคิดที่เกี่ยวข้องกับการใช้งานโมเดลภาษาขนาดใหญ่ (LLM) ในท้องถิ่นกับ Ollama เพื่อดำเนินการดึงข้อมูล-Augmented Generation (RAG) สำหรับการตอบคำถามตามตัวอย่าง PDF ในโปรเจ็กต์นี้ เรายังใช้ Ollama เพื่อสร้างการฝังด้วยข้อความแบบฝังแบบโนมิกเพื่อใช้กับ Chroma โปรดทราบว่าการฝังจะถูกโหลดซ้ำทุกครั้งที่แอปพลิเคชันทำงาน ซึ่งไม่มีประสิทธิภาพและทำที่นี่เพื่อการทดสอบเท่านั้น
นอกจากนี้ยังมี UI ของเว็บที่สร้างขึ้นโดยใช้ Streamlit เพื่อให้มีวิธีโต้ตอบกับ Ollama ที่แตกต่างออกไป
python3 -m venv .venvsource .venv/bin/activate บน Unix หรือ MacOS หรือ ..venvScriptsactivate บน Windowspip install -r requirements.txt หมายเหตุ: ในครั้งแรกที่คุณรันโปรเจ็กต์ โปรเจ็กต์จะดาวน์โหลดโมเดลที่จำเป็นจาก Ollama สำหรับ LLM และการฝัง นี่เป็นขั้นตอนการตั้งค่าเพียงครั้งเดียวและอาจใช้เวลาสักครู่ขึ้นอยู่กับการเชื่อมต่ออินเทอร์เน็ตของคุณ
python app.py -m <model_name> -p <path_to_documents> เพื่อระบุโมเดลและพาธไปยังเอกสาร หากไม่มีการระบุรุ่น จะมีค่าเริ่มต้นเป็นมิสทรัล หากไม่มีการระบุเส้นทาง ระบบจะใช้ค่าเริ่มต้นเป็นการ Research ที่อยู่ในพื้นที่เก็บข้อมูลเพื่อวัตถุประสงค์ตัวอย่าง-e <embedding_model_name> หากไม่ได้ระบุ จะมีค่าเริ่มต้นเป็น nomic-embed-text สิ่งนี้จะโหลดไฟล์ PDF และ Markdown สร้างการฝัง ค้นหาคอลเลกชัน และตอบคำถามที่กำหนดไว้ใน app.py
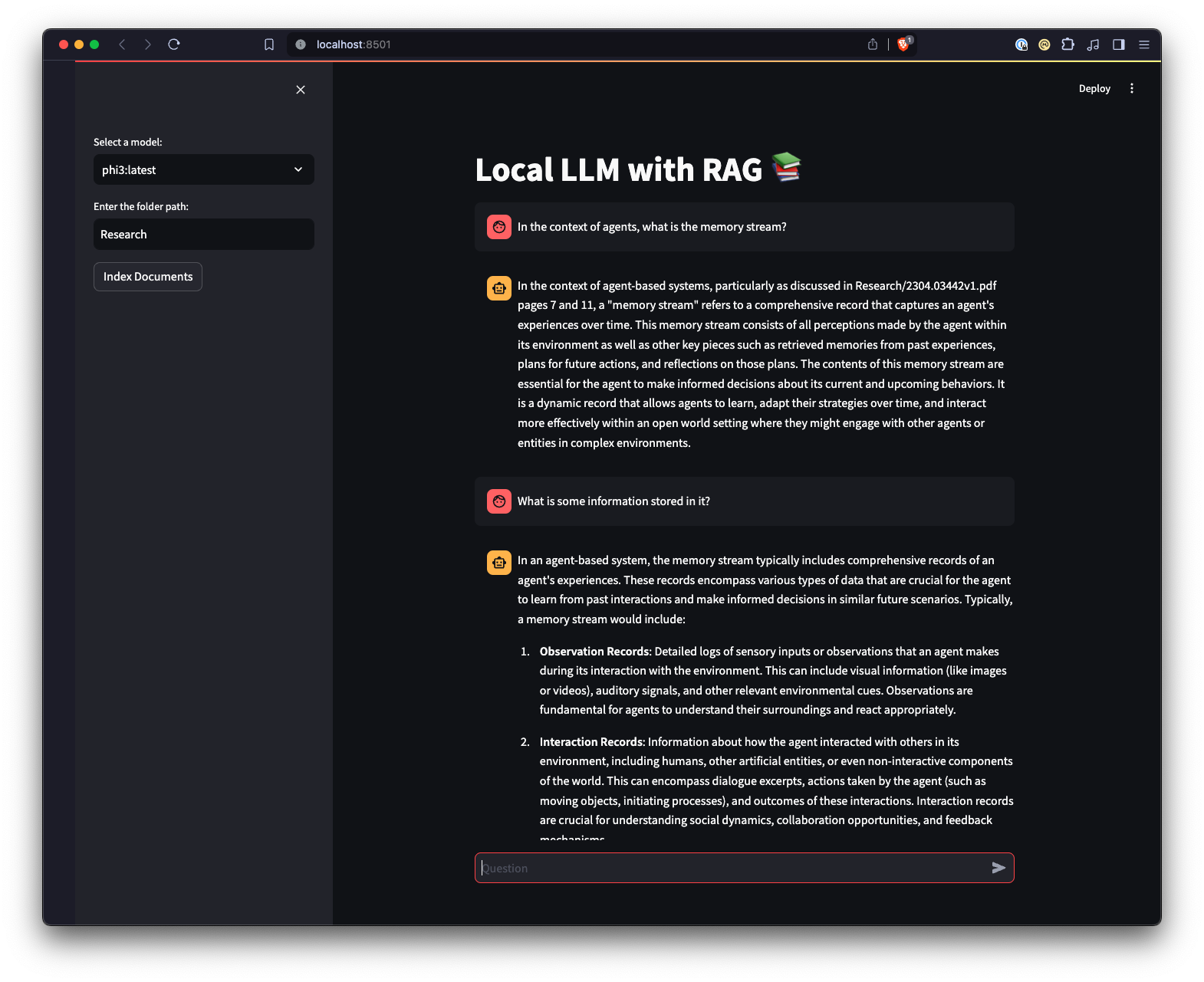
ui.pystreamlit run ui.py ในเทอร์มินัลของคุณสิ่งนี้จะเริ่มต้นเว็บเซิร์ฟเวอร์ในเครื่องและเปิดแท็บใหม่ในเว็บเบราว์เซอร์เริ่มต้นของคุณซึ่งคุณสามารถโต้ตอบกับแอปพลิเคชันได้ Streamlit UI ช่วยให้คุณสามารถเลือกรุ่น เลือกโฟลเดอร์ ช่วยให้โต้ตอบกับระบบแชทบอท RAG ได้ง่ายขึ้นและเป็นธรรมชาติมากขึ้น เมื่อเปรียบเทียบกับอินเทอร์เฟซบรรทัดคำสั่ง แอปพลิเคชันจะจัดการการโหลดเอกสาร การสร้างการฝัง การสอบถามคอลเลกชัน และการแสดงผลลัพธ์แบบโต้ตอบ


