bloomz.cpp
1.0.0
การอนุมานโมเดลที่เหมือน BLOOM ของ HuggingFace ใน C/C++ ล้วนๆ
repo ถูกสร้างขึ้นบน repo llama.cpp ที่น่าทึ่งโดย @ggerganov เพื่อรองรับโมเดล BLOOM รองรับทุกรุ่นที่สามารถโหลดได้โดยใช้ BloomForCausalLM.from_pretrained()
ขั้นแรก คุณต้องโคลน repo และสร้างมันขึ้นมา:
git clone https://github.com/NouamaneTazi/bloomz.cpp
cd bloomz.cpp
makeจากนั้น คุณต้องแปลงน้ำหนักโมเดลเป็นรูปแบบ ggml BLOOM รุ่นใดก็ได้ที่สามารถแปลงได้
น้ำหนักบางส่วนที่โฮสต์บน Hub ได้ถูกแปลงแล้ว คุณสามารถค้นหารายการได้ที่นี่
มิฉะนั้น วิธีที่รวดเร็วที่สุดในการแปลงน้ำหนักคือการใช้เครื่องมือแปลงนี้ เป็น Space ที่โฮสต์บน Huggingface Hub ซึ่งจะแปลงและกำหนดปริมาณน้ำหนักสำหรับคุณ และอัปโหลดไปยังพื้นที่เก็บข้อมูลที่คุณเลือก
หากต้องการ คุณสามารถแปลงตุ้มน้ำหนักบนเครื่องของคุณได้ด้วยตนเอง:
# install required libraries
python3 -m pip install torch numpy transformers accelerate
# download and convert the 7B1 model to ggml FP16 format
python3 convert-hf-to-ggml.py bigscience/bloomz-7b1 ./models
# Note: you can add --use-f32 to convert to FP32 instead of FP16หรือคุณสามารถกำหนดปริมาณโมเดลเป็น 4 บิตได้
./quantize ./models/ggml-model-bloomz-7b1-f16.bin ./models/ggml-model-bloomz-7b1-f16-q4_0.bin 2ในที่สุด คุณสามารถเรียกใช้การอนุมานได้
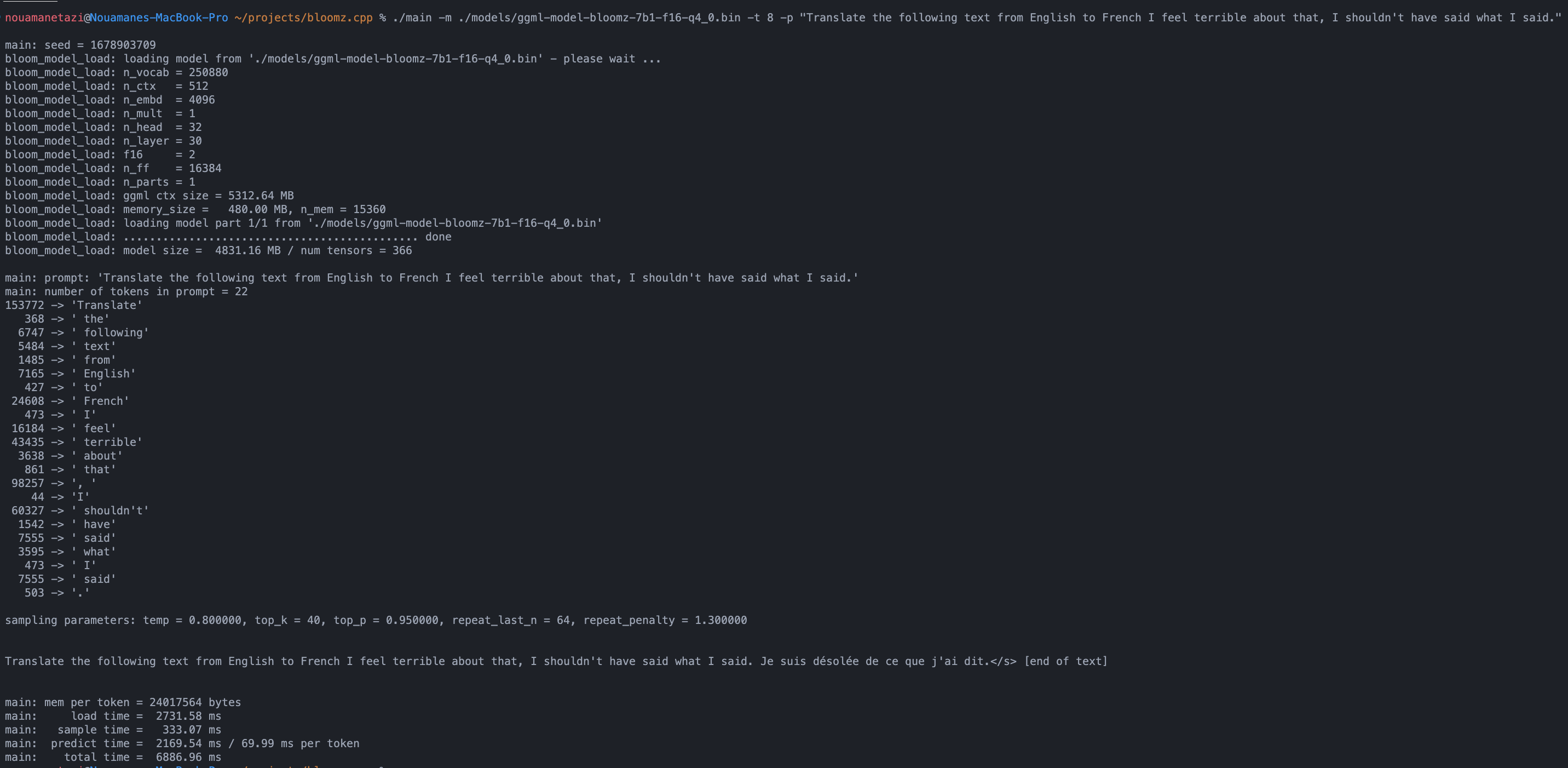
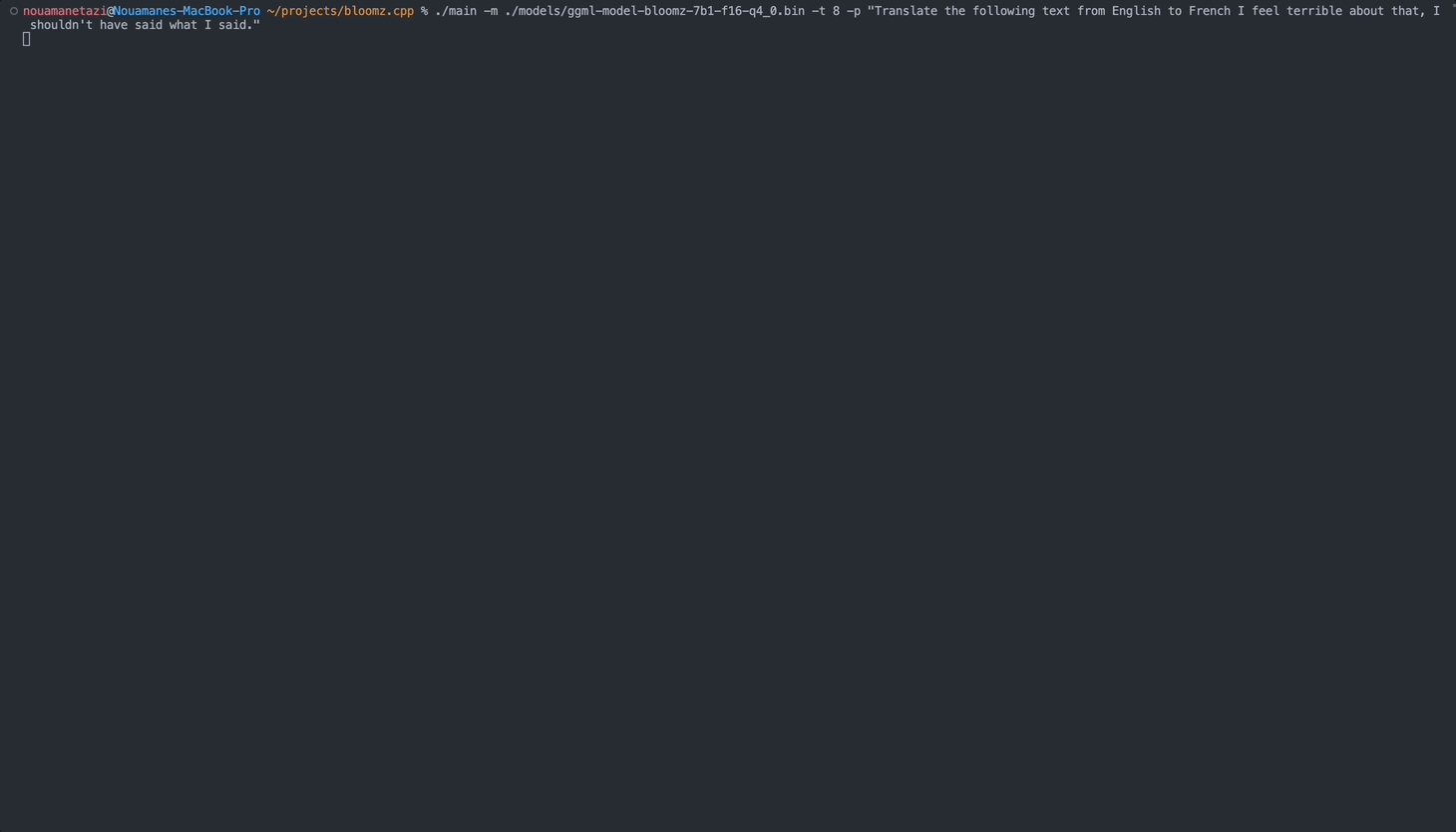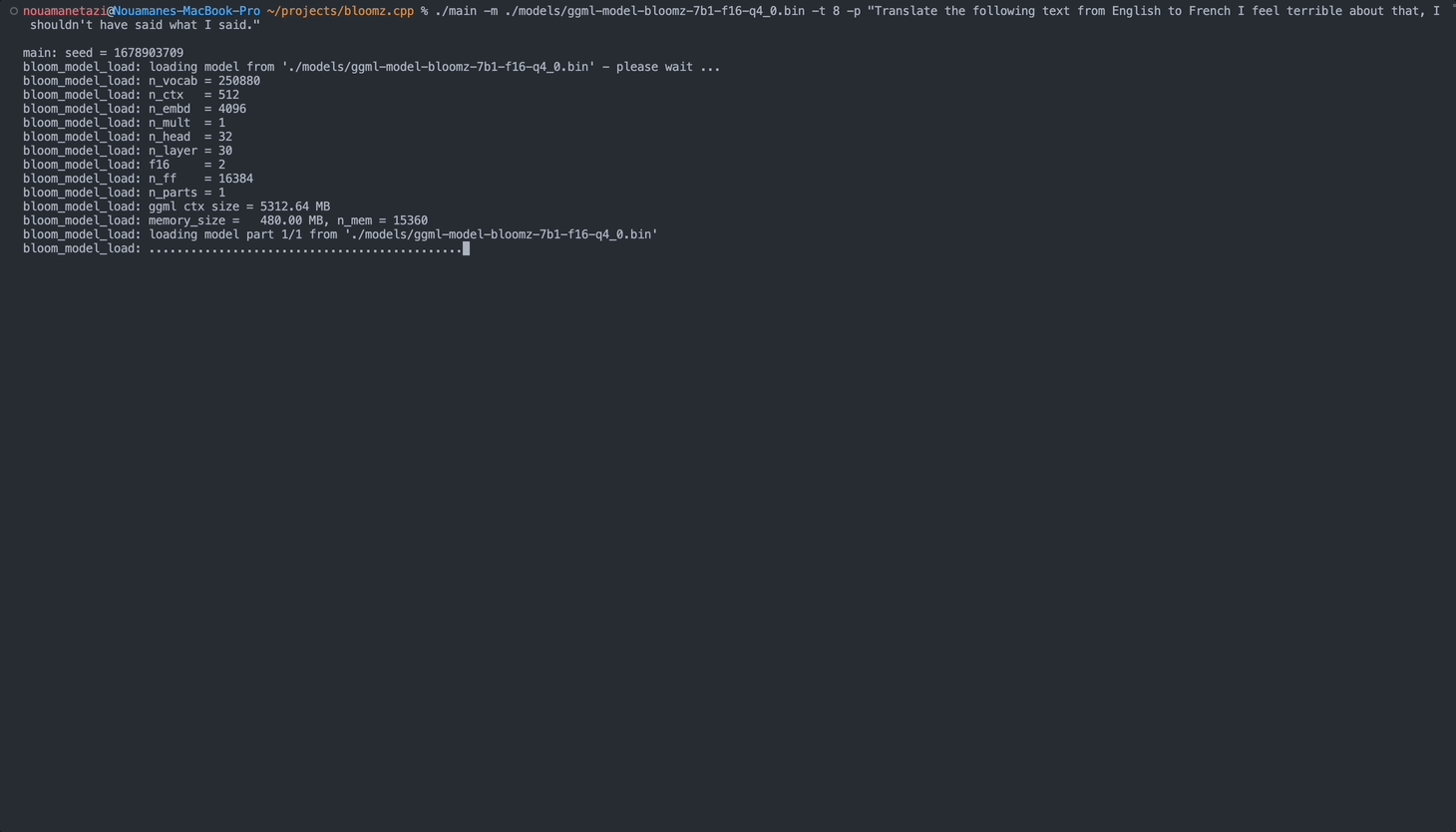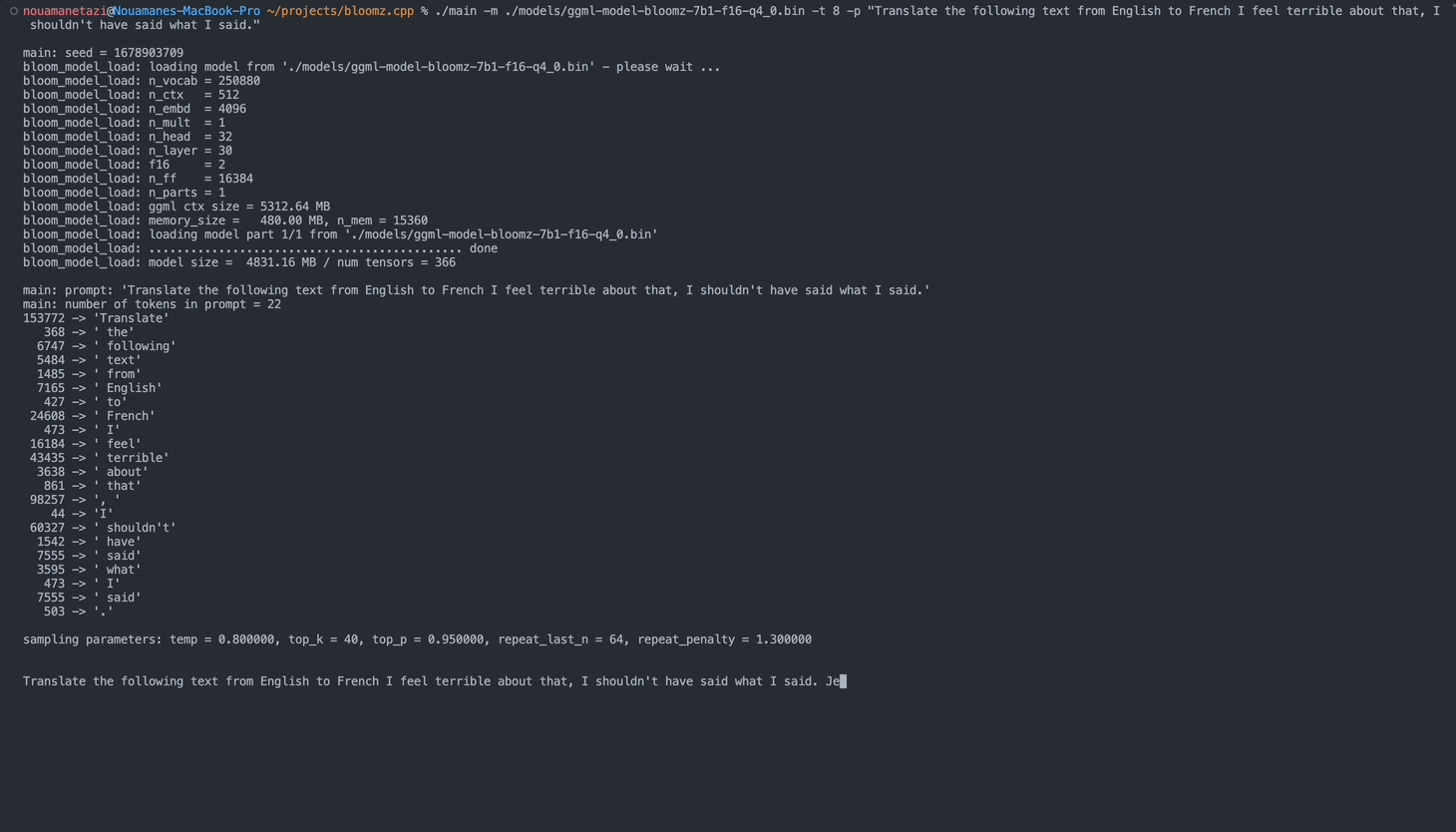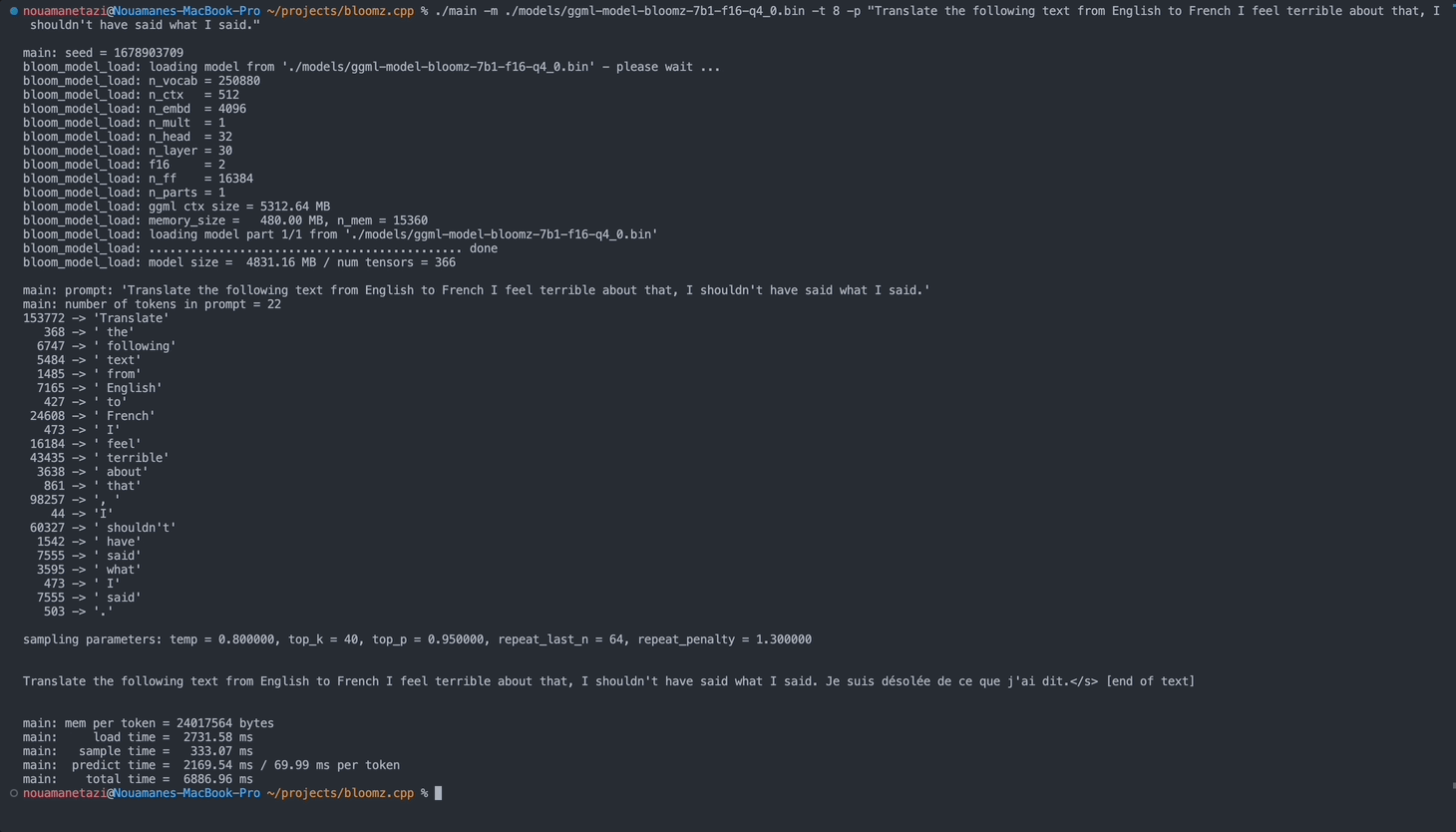
./main -m ./models/ggml-model-bloomz-7b1-f16-q4_0.bin -t 8 -n 128ผลลัพธ์ของคุณควรมีลักษณะดังนี้:
make && ./main -m models/ggml-model-bloomz-7b1-f16-q4_0.bin -p ' Translate "Hi, how are you?" in French: ' -t 8 -n 256
I llama.cpp build info:
I UNAME_S: Darwin
I UNAME_P: arm
I UNAME_M: arm64
I CFLAGS: -I. -O3 -DNDEBUG -std=c11 -fPIC -pthread -DGGML_USE_ACCELERATE
I CXXFLAGS: -I. -I./examples -O3 -DNDEBUG -std=c++11 -fPIC -pthread
I LDFLAGS: -framework Accelerate
I CC: Apple clang version 13.1.6 (clang-1316.0.21.2.5)
I CXX: Apple clang version 13.1.6 (clang-1316.0.21.2.5)
make: Nothing to be done for ` default ' .
main: seed = 1678899845
llama_model_load: loading model from ' models/ggml-model-bloomz-7b1-f16-q4_0.bin ' - please wait ...
llama_model_load: n_vocab = 250880
llama_model_load: n_ctx = 512
llama_model_load: n_embd = 4096
llama_model_load: n_mult = 1
llama_model_load: n_head = 32
llama_model_load: n_layer = 30
llama_model_load: f16 = 2
llama_model_load: n_ff = 16384
llama_model_load: n_parts = 1
llama_model_load: ggml ctx size = 5312.64 MB
llama_model_load: memory_size = 480.00 MB, n_mem = 15360
llama_model_load: loading model part 1/1 from ' models/ggml-model-bloomz-7b1-f16-q4_0.bin '
llama_model_load: ............................................. done
llama_model_load: model size = 4831.16 MB / num tensors = 366
main: prompt: ' Translate " Hi, how are you? " in French: '
main: number of tokens in prompt = 11
153772 -> ' Translate '
17959 -> ' " H'
76 -> 'i'
98257 -> ', '
20263 -> 'how'
1306 -> ' are'
1152 -> ' you'
2040 -> '?'
5 -> ' " '
361 -> ' in '
196427 -> ' French: '
sampling parameters: temp = 0.800000, top_k = 40, top_p = 0.950000, repeat_last_n = 64, repeat_penalty = 1.300000
Translate "Hi, how are you?" in French: Bonjour, comment ça va?</s> [end of text]
main: mem per token = 24017564 bytes
main: load time = 3092.29 ms
main: sample time = 2.40 ms
main: predict time = 1003.04 ms / 59.00 ms per token
main: total time = 5307.23 ms นี่คือรายการตัวเลือกที่ใช้ได้:
usage: ./main [options]
options:
-h, --help show this help message and exit
-s SEED, --seed SEED RNG seed (default: -1)
-t N, --threads N number of threads to use during computation (default: 4)
-p PROMPT, --prompt PROMPT
prompt to start generation with (default: random)
-n N, --n_predict N number of tokens to predict (default: 128)
--top_k N top-k sampling (default: 40)
--top_p N top-p sampling (default: 0.9)
--repeat_last_n N last n tokens to consider for penalize (default: 64)
--repeat_penalty N penalize repeat sequence of tokens (default: 1.3)
--temp N temperature (default: 0.8)
-b N, --batch_size N batch size for prompt processing (default: 8)
-m FNAME, --model FNAME
model path (default: models/ggml-model-bloomz-7b1-f16-q4_0.bin)| แบบอย่าง | ดิสก์ | เมม |
|---|---|---|
bloomz-7b1-f16-q4_0 | 4.7 กิกะไบต์ | 5.3 กิกะไบต์ |
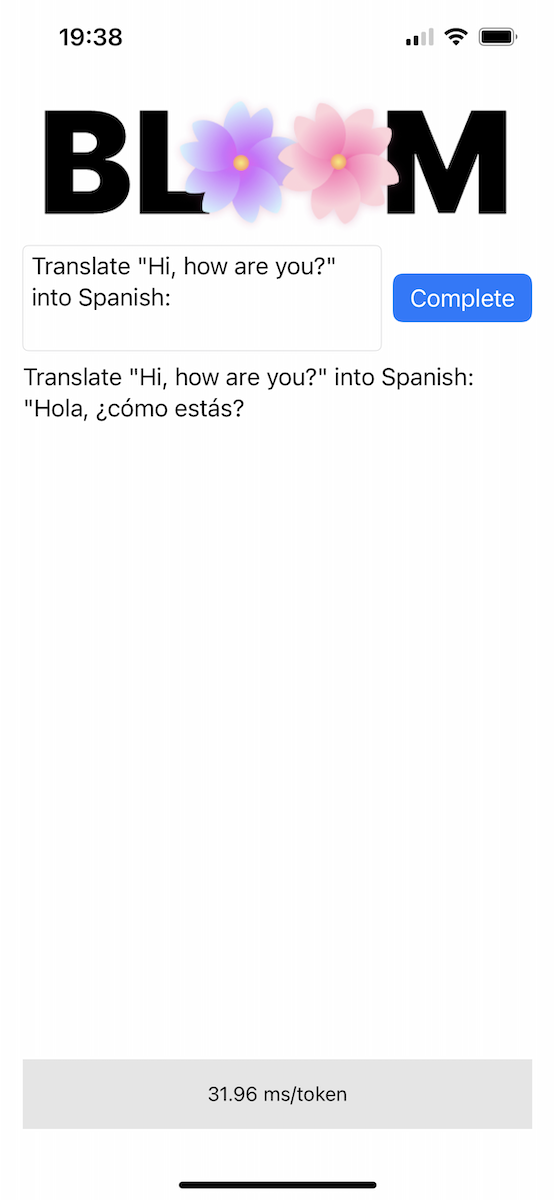
repo มีแอป iOS ที่พิสูจน์แนวคิดไว้ในไดเร็กทอรี Bloomer คุณต้องจัดเตรียมน้ำหนักของโมเดลที่แปลงแล้ว โดยวางไฟล์ชื่อ ggml-model-bloomz-560m-f16.bin ไว้ในโฟลเดอร์นั้น นี่คือลักษณะที่ปรากฏบน iPhone: