LLaMA_MPS
1.0.0
เรียกใช้การอนุมาน LLaMA (และ Stanford-Alpaca) บน Apple Silicon GPU
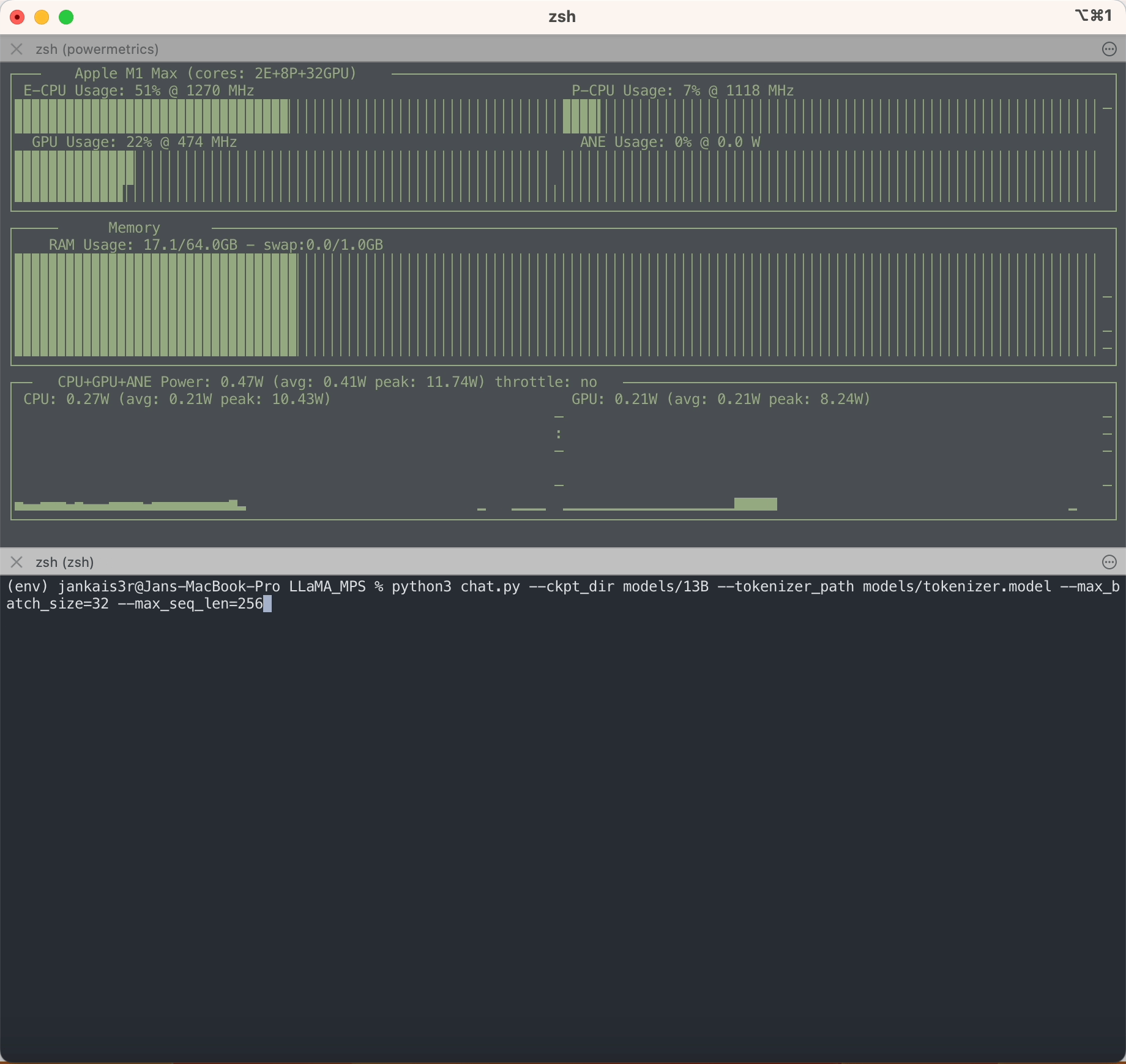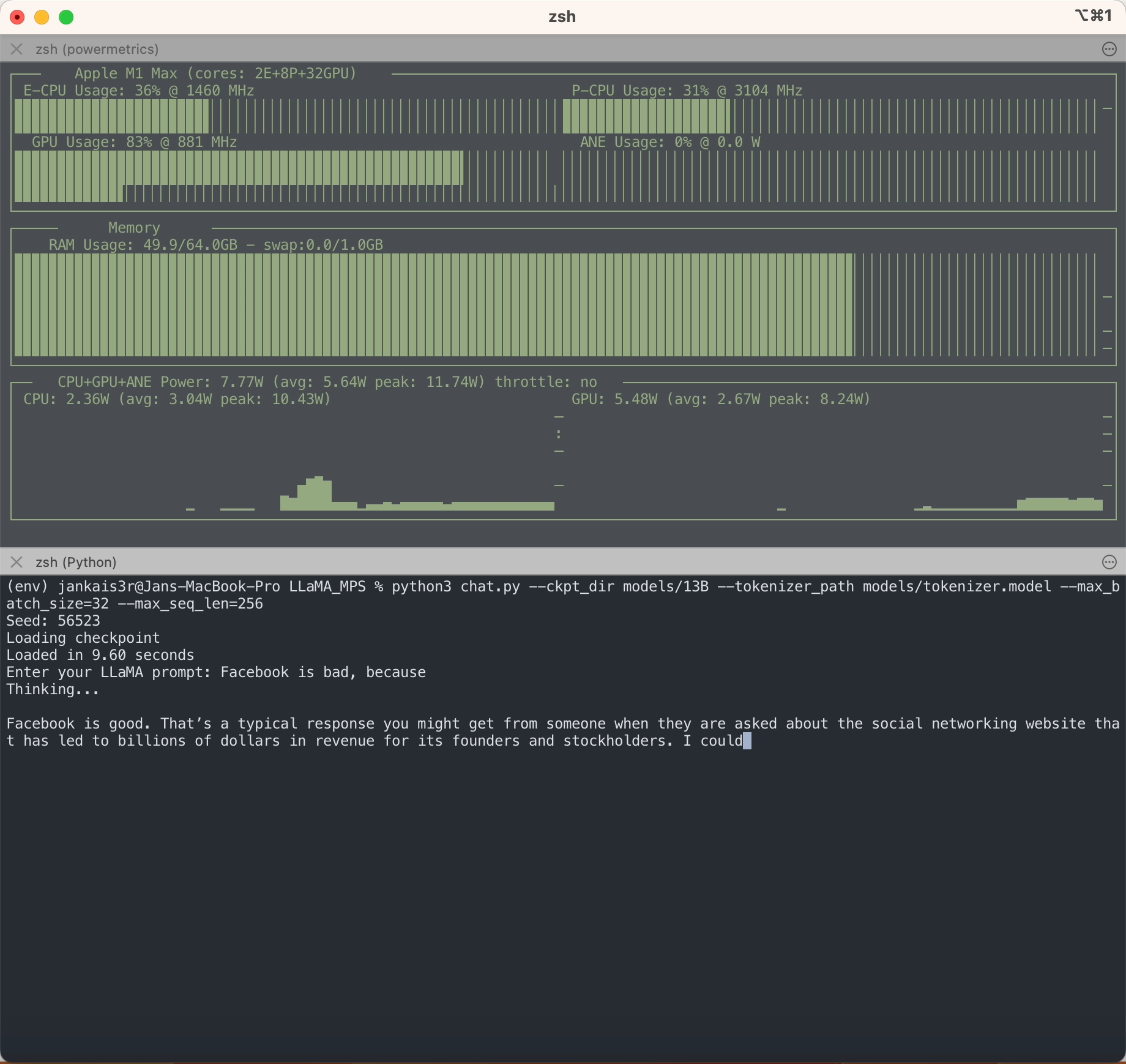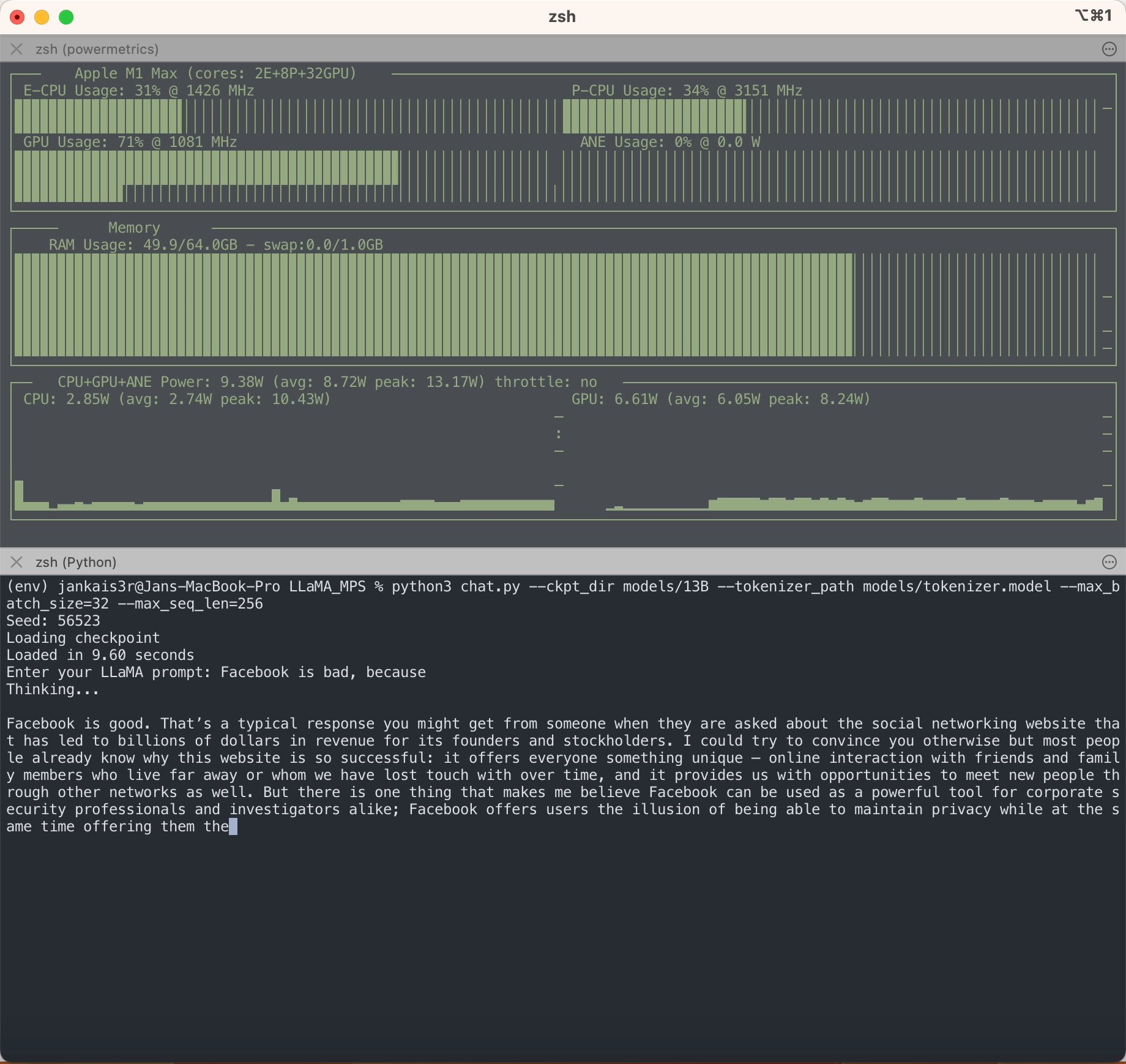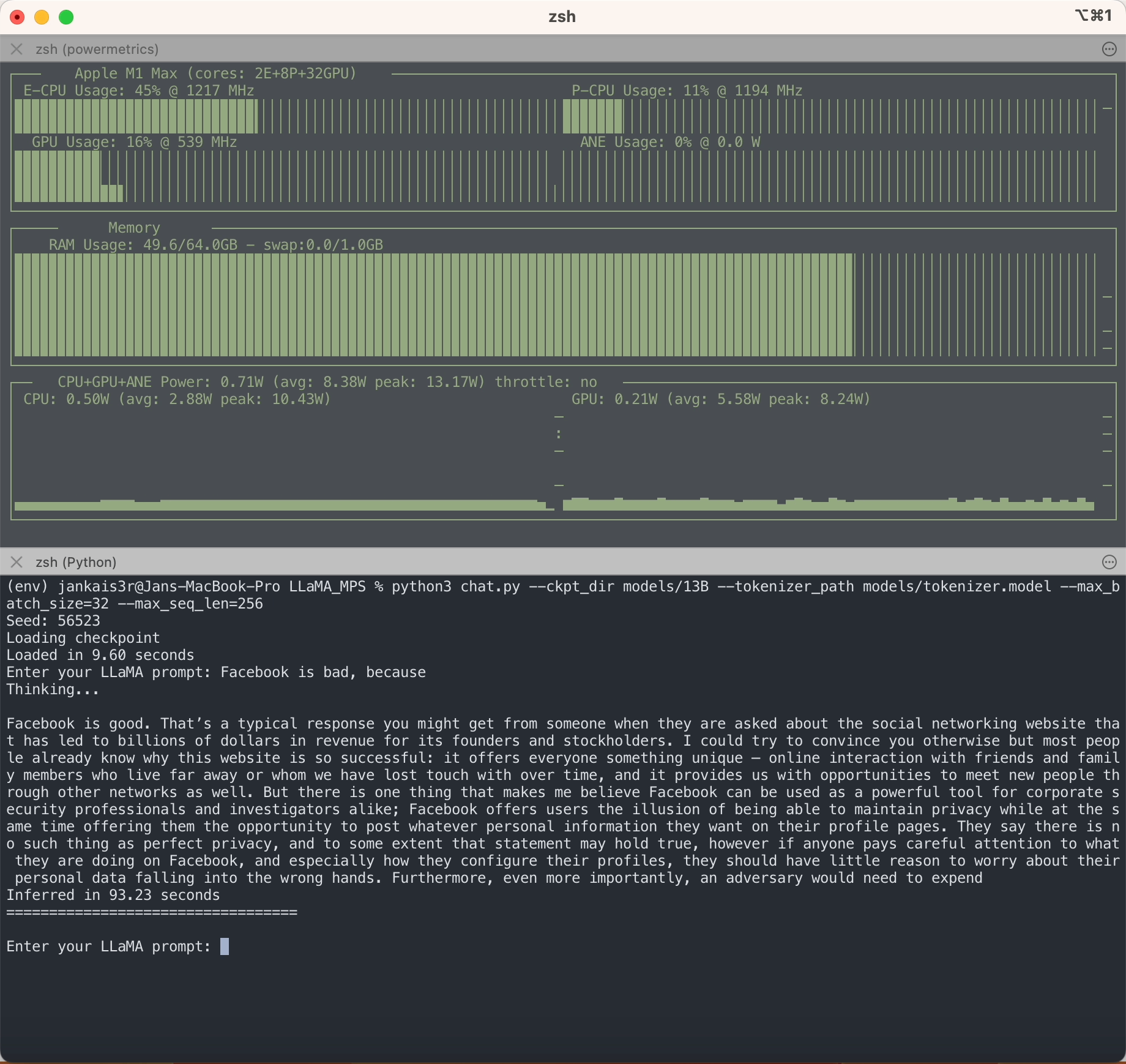
อย่างที่คุณเห็น LLaMA ไม่เหมือนกับ LLM อื่น ๆ ตรงที่ไม่มีอคติ แต่อย่างใด
1. โคลน repo นี้
git clone https://github.com/jankais3r/LLaMA_MPS
2. ติดตั้งการพึ่งพา Python
cd LLaMA_MPS
pip3 install virtualenv
python3 -m venv env
source env/bin/activate
pip3 install -r requirements.txt
pip3 install -e . 3. ดาวน์โหลดตุ้มน้ำหนักโมเดลและนำไปไว้ในโฟลเดอร์ชื่อ models (เช่น LLaMA_MPS/models/7B )
4. (ทางเลือก) ทำการแบ่งน้ำหนักโมเดลใหม่ (13B/30B/65B)
เนื่องจากเราใช้การอนุมานบน GPU ตัวเดียว เราจึงต้องรวมน้ำหนักของโมเดลที่ใหญ่กว่าให้เป็นไฟล์เดียว
mv models/13B models/13B_orig
mkdir models/13B
python3 reshard.py 1 models/13B_orig models/13B5. เรียกใช้การอนุมาน
python3 chat.py --ckpt_dir models/13B --tokenizer_path models/tokenizer.model --max_batch_size 8 --max_seq_len 256
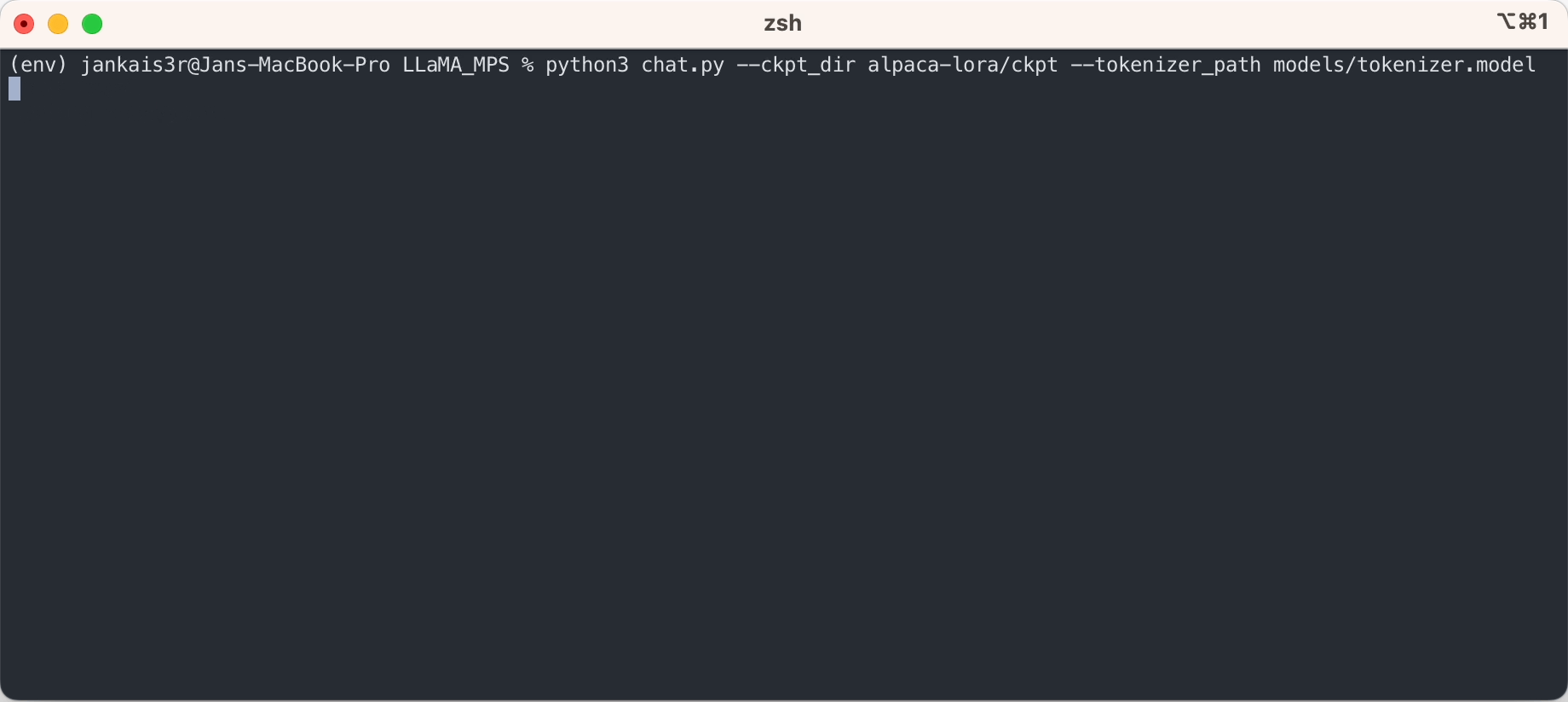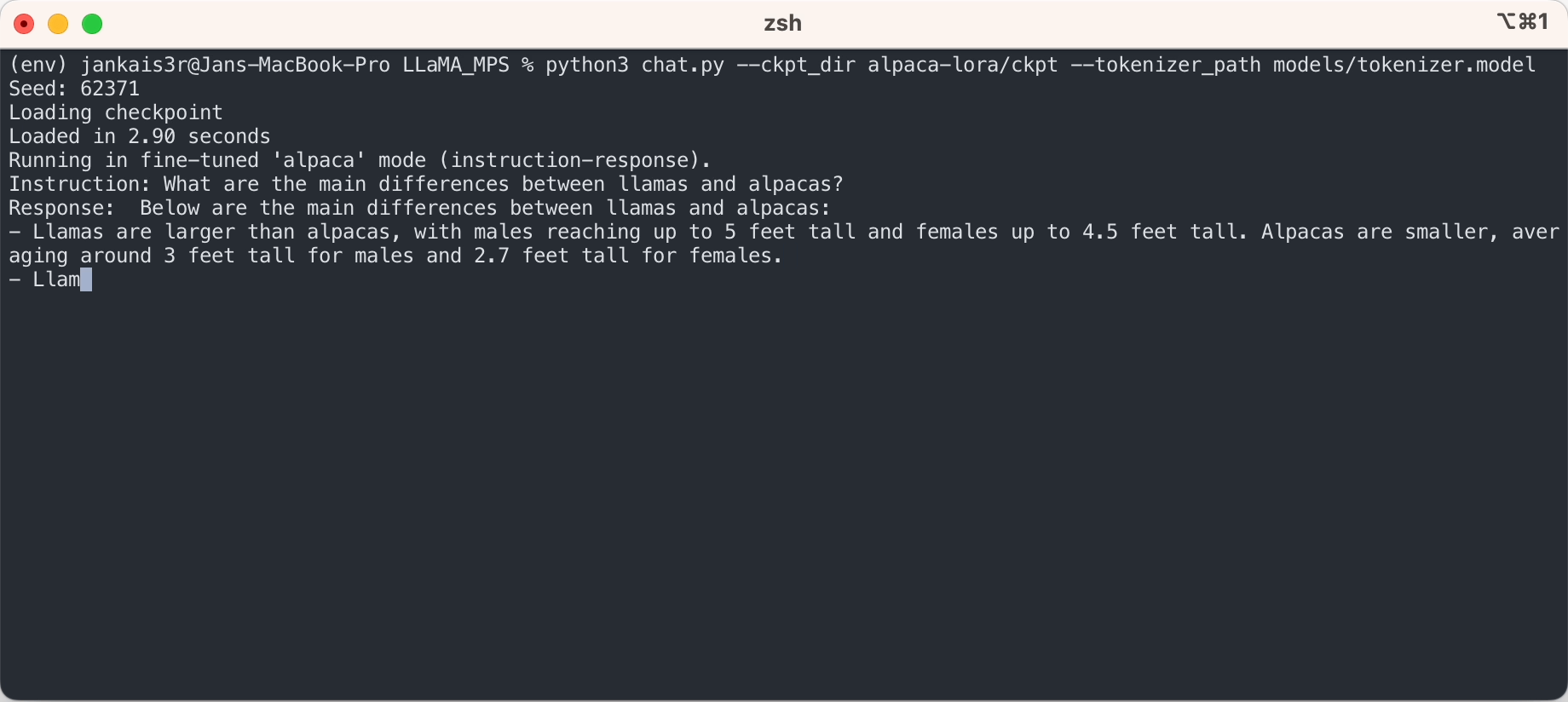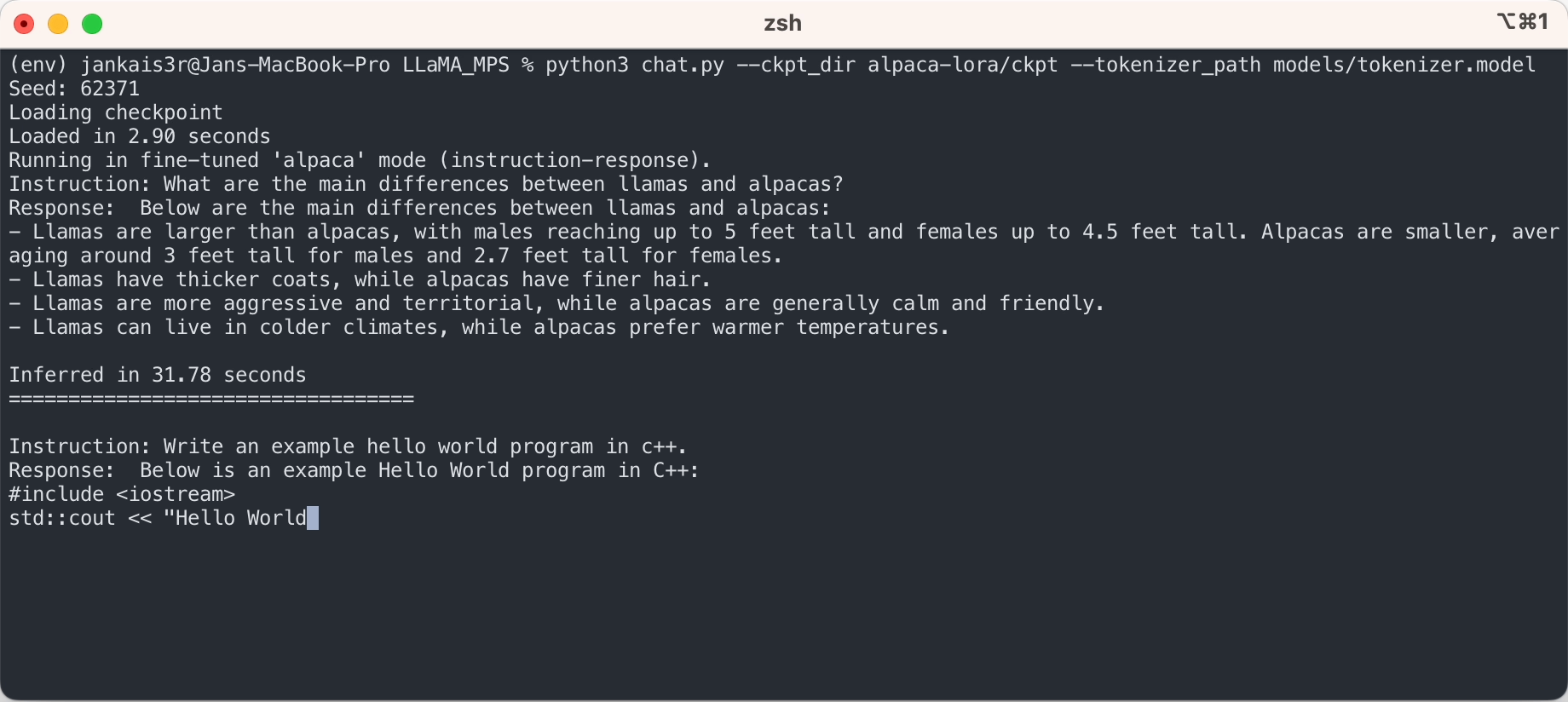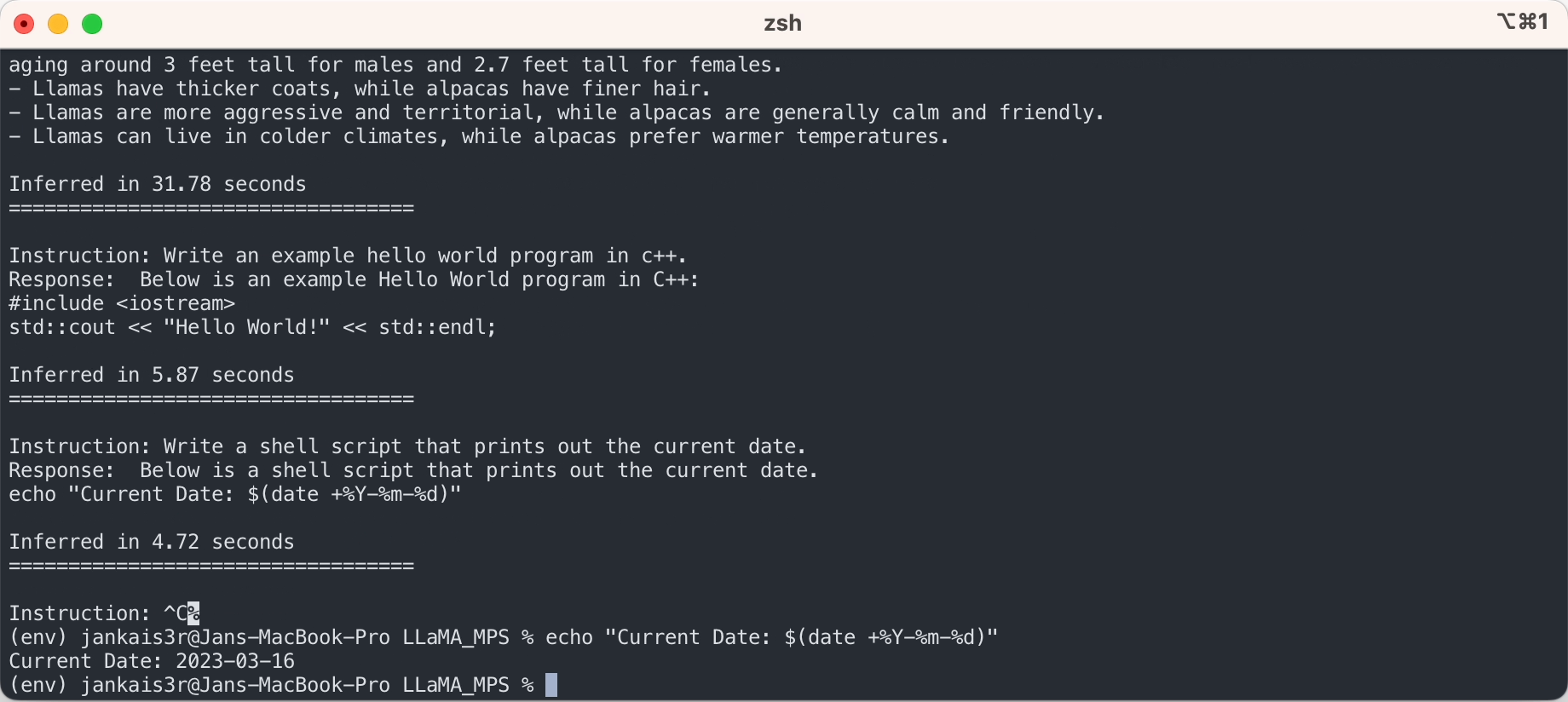
ขั้นตอนข้างต้นจะช่วยให้คุณสามารถเรียกใช้การอนุมานบนโมเดล LLaMA แบบ Raw ในโหมด 'เติมข้อความอัตโนมัติ'
หากคุณต้องการลองใช้โหมด "ตอบกลับคำสั่ง" ที่คล้ายกับ ChatGPT โดยใช้น้ำหนักที่ปรับแต่งแล้วของ Stanford Alpaca ให้ตั้งค่าต่อตามขั้นตอนต่อไปนี้:
3. ดาวน์โหลดตุ้มน้ำหนักที่ปรับแต่งแล้ว (มีให้สำหรับ 7B/13B)
python3 export_state_dict_checkpoint.py 7B
python3 clean_hf_cache.py4. เรียกใช้การอนุมาน
python3 chat.py --ckpt_dir models/7B-alpaca --tokenizer_path models/tokenizer.model --max_batch_size 8 --max_seq_len 256
| แบบอย่าง | เริ่มต้นหน่วยความจำระหว่างการอนุมาน | หน่วยความจำสูงสุดระหว่างการแปลงจุดตรวจ | หน่วยความจำสูงสุดระหว่างการแบ่งใหม่ |
|---|---|---|---|
| 7B | 16GB | 14 กิกะไบต์ | ไม่มี |
| 13B | 32GB | 37 กิกะไบต์ | 45 กิกะไบต์ |
| 30B | 66GB | 76GB | 125 กิกะไบต์ |
| 65B | - กิกะไบต์ | - กิกะไบต์ | - กิกะไบต์ |
ข้อมูลจำเพาะขั้นต่ำต่อรุ่น (ช้าเนื่องจากการสลับ):
ข้อมูลจำเพาะที่แนะนำต่อรุ่น:
- max_batch_size
หากคุณมีหน่วยความจำสำรอง (เช่น เมื่อใช้งานรุ่น 13B บน Mac ขนาด 64 GB) คุณสามารถเพิ่มขนาดแบตช์ได้โดยใช้อาร์กิวเมนต์ --max_batch_size=32 ค่าเริ่มต้นคือ 1
- max_seq_len
หากต้องการเพิ่ม/ลดความยาวสูงสุดของข้อความที่สร้างขึ้น ให้ใช้อาร์กิวเมนต์ --max_seq_len=256 ค่าเริ่มต้นคือ 512
- use_repetition_penalty
สคริปต์ตัวอย่างจะลงโทษโมเดลสำหรับการสร้างเนื้อหาที่ซ้ำกัน สิ่งนี้ควรนำไปสู่ผลลัพธ์ที่มีคุณภาพสูงขึ้น แต่จะทำให้การอนุมานช้าลงเล็กน้อย รันสคริปต์ด้วย --use_repetition_penalty=False อาร์กิวเมนต์ เพื่อปิดใช้งานอัลกอริทึมการลงโทษ
ทางเลือกที่ดีที่สุดแทน LLaMA_MPS สำหรับผู้ใช้ Apple Silicon คือ llama.cpp ซึ่งเป็นการนำ C/C++ มาใช้ใหม่ซึ่งจะรันการอนุมานเฉพาะในส่วน CPU ของ SoC เนื่องจากโค้ด C ที่คอมไพล์เร็วกว่า Python มาก จึงสามารถเอาชนะการใช้งาน MPS นี้ได้ในเรื่องความเร็ว แต่ก็ต้องแลกมาด้วยประสิทธิภาพด้านพลังงานและความร้อนที่แย่กว่ามาก
ดูการเปรียบเทียบด้านล่างเมื่อตัดสินใจว่าการใช้งานแบบใดที่เหมาะกับกรณีการใช้งานของคุณมากกว่า
| การนำไปปฏิบัติ | เวลาทำงานทั้งหมด - 256 โทเค็น | โทเค็น/วินาที | การใช้หน่วยความจำสูงสุด | อุณหภูมิ SoC สูงสุด | การใช้พลังงาน SoC สูงสุด | โทเค็นต่อ 1 Wh |
|---|---|---|---|---|---|---|
| ลามะ_MPS (13B fp16) | 75 วิ | 3.41 | 30 กิกะไบต์ | 79 องศาเซลเซียส | 10 วัตต์ | 1,228.80 |
| llama.cpp (13B fp16) | 70 วิ | 3.66 | 25 กิกะไบต์ | 106 องศาเซลเซียส | 35 วัตต์ | 376.16 |


