dream
v1.13.0
DeepPavlov Dream เป็นแพลตฟอร์มสำหรับสร้างผู้ช่วย AI ที่สร้างทักษะหลากหลาย
หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับแพลตฟอร์มและวิธีการสร้างผู้ช่วย AI โปรดไปที่ Dream หากคุณต้องการเรียนรู้เพิ่มเติมเกี่ยวกับ DeepPavlov Agent ที่ขับเคลื่อน Dream โปรดไปที่เอกสารประกอบของ DeepPavlov Agent
เราได้รวมการแจกแจงไว้หกแบบแล้ว: สี่แบบใช้โซเชียลบ็อต Deepy แบบน้ำหนักเบา, หนึ่งคือแชทบอตในฝันขนาดเต็ม (อิงตามเวอร์ชัน Alexa Prize Challenge) ในภาษาอังกฤษ และแชทบอตในฝันในภาษารัสเซีย
เวอร์ชันพื้นฐานของ Lunar Assistant Deepy Base ประกอบด้วยคำอธิบายประกอบการสะกดคำล่วงหน้า ทักษะการบำรุงรักษา Harvesters ตามเทมเพลต และทักษะโปรแกรมโดเมนแบบเปิดที่ใช้ AIML โดยอิงตาม Dialog Flow Framework
ผู้ช่วยทางจันทรคติเวอร์ชันขั้นสูง Deepy Advanced ประกอบด้วยการประมวลผลการสะกดล่วงหน้า การแบ่งส่วนประโยค การเชื่อมโยงเอนทิตีและคำอธิบายประกอบ Intent Catcher ทักษะ Harvesters Maintenance GoBot สำหรับการตอบกลับที่มุ่งเน้นเป้าหมาย และทักษะโปรแกรม y โดเมนแบบเปิดที่ใช้ AIML ซึ่งอิงตามกรอบงาน Dialog Flow Framework
คำถามที่พบบ่อยของ Lunar Assistant Deepy FAQ ประกอบด้วยคำอธิบายประกอบการสะกดคำล่วงหน้า ทักษะคำถามที่พบบ่อยตามเทมเพลต และทักษะโปรแกรมโดเมนแบบเปิดที่ใช้ AIML โดยอิงตาม Dialog Flow Framework
ผู้ช่วยทางจันทรคติเวอร์ชันมุ่งเน้นเป้าหมาย Deepy GoBot Base ประกอบด้วยคำอธิบายประกอบการสะกดคำล่วงหน้า ทักษะ Harvesters Maintenance GoBot สำหรับการตอบกลับที่มุ่งเน้นเป้าหมาย และทักษะโปรแกรมโดเมนแบบเปิดที่ใช้ AIML ซึ่งอิงตาม Dialog Flow Framework
DeepPavlov Dream Socialbot เวอร์ชันเต็ม นี่เกือบจะเป็นเวอร์ชันเดียวกับ DREAM socialbot ในตอนท้ายของ Alexa Prize Challenge 4 บริการ API บางอย่างจะถูกแทนที่ด้วยโมเดลที่ฝึกได้ บริการบางอย่าง (เช่น News Annotator, ทักษะเกม, ทักษะสภาพอากาศ) ต้องใช้คีย์ส่วนตัวสำหรับ API พื้นฐาน ซึ่งส่วนใหญ่สามารถรับได้ฟรี หากคุณต้องการใช้บริการเหล่านี้ในการปรับใช้ในเครื่อง ให้เพิ่มคีย์ของคุณลงในตัวแปรสภาพแวดล้อม (เช่น . ./.env , ./.env_ru ) Dream Socialbot เวอร์ชันนี้ใช้ทรัพยากรจำนวนมากเนื่องจากมีสถาปัตยกรรมแบบแยกส่วนและเป้าหมายดั้งเดิม (เข้าร่วมใน Alexa Prize Challenge) เราจัดให้มีการสาธิต Dream Socialbot บนเว็บไซต์ของเรา
DeepPavlov Dream Socialbot เวอร์ชันมินิ นี่คือโซเชียลบอตที่สร้างพื้นฐานซึ่งใช้โมเดล English DialoGPT เพื่อสร้างการตอบสนองส่วนใหญ่ นอกจากนี้ยังมีส่วนประกอบตัวจับเจตนาและตัวตอบกลับเพื่อให้ครอบคลุมคำขอพิเศษของผู้ใช้ เชื่อมโยงไปยังการแจกจ่าย
DeepPavlov Dream Socialbot เวอร์ชันรัสเซีย นี่คือโซเชียลบอตที่สร้างพื้นฐานซึ่งใช้ Russian DialoGPT โดย DeepPavlov เพื่อสร้างการตอบสนองส่วนใหญ่ นอกจากนี้ยังมีส่วนประกอบตัวจับเจตนาและตัวตอบกลับเพื่อให้ครอบคลุมคำขอพิเศษของผู้ใช้ เชื่อมโยงไปยังการแจกจ่าย
DeepPavlov Dream Socialbot เวอร์ชันขนาดเล็กพร้อมการใช้โมเดลกำเนิดตามพรอมต์ นี่คือโซเชียลบอตที่สร้างพื้นฐานซึ่งใช้โมเดลภาษาขนาดใหญ่เพื่อสร้างการตอบสนองส่วนใหญ่ คุณสามารถอัปโหลดพรอมต์ของคุณเอง (ไฟล์ json) ไปที่ทั่วไป/พรอมต์ เพิ่มชื่อพรอมต์ใน PROMPTS_TO_CONSIDER (คั่นด้วยเครื่องหมายจุลภาค) และข้อมูลที่ให้ไว้จะถูกใช้ในการสร้างการตอบกลับที่ขับเคลื่อนโดย LLM เป็นพรอมต์ เชื่อมโยงไปยังการแจกจ่าย
docker ตั้งแต่ 20 ขึ้นไปdocker-compose v1.29.2; git clone https://github.com/deeppavlov/dream.git
หากคุณได้รับข้อผิดพลาด "สิทธิ์ถูกปฏิเสธ" ขณะเรียกใช้ docker-compose ตรวจสอบให้แน่ใจว่าได้กำหนดค่าผู้ใช้ docker ของคุณอย่างถูกต้อง
docker-compose -f docker-compose.yml -f assistant_dists/deepy_base/docker-compose.override.yml up --build
docker-compose -f docker-compose.yml -f assistant_dists/deepy_adv/docker-compose.override.yml up --build
docker-compose -f docker-compose.yml -f assistant_dists/deepy_faq/docker-compose.override.yml up --build
docker-compose -f docker-compose.yml -f assistant_dists/deepy_gobot_base/docker-compose.override.yml up --build
วิธีที่ง่ายที่สุดในการลองใช้ Dream คือการปรับใช้ผ่านพรอกซี คำขอทั้งหมดจะถูกเปลี่ยนเส้นทางไปยัง DeepPavlov API ดังนั้นคุณไม่จำเป็นต้องใช้ทรัพยากรในเครื่องใดๆ ดูการใช้พร็อกซีสำหรับรายละเอียด
docker-compose -f docker-compose.yml -f assistant_dists/dream/docker-compose.override.yml -f assistant_dists/dream/dev.yml -f assistant_dists/dream/proxy.yml up --build
โปรดทราบว่าส่วนประกอบ DeepPavlov Dream ต้องการทรัพยากรจำนวนมาก โปรดดูส่วนส่วนประกอบเพื่อดูข้อกำหนดโดยประมาณ
docker-compose -f docker-compose.yml -f assistant_dists/dream/docker-compose.override.yml -f assistant_dists/dream/dev.yml up --build
นอกจากนี้เรายังได้รวมการกำหนดค่าที่มีการจัดสรร GPU สำหรับสภาพแวดล้อมที่มี GPU หลายตัว:
AGENT_PORT=4242 docker-compose -f docker-compose.yml -f assistant_dists/dream/docker-compose.override.yml -f assistant_dists/dream/dev.yml -f assistant_dists/dream/test.yml up
เมื่อคุณต้องการรีสตาร์ทคอนเทนเนอร์นักเทียบท่าโดยเฉพาะโดยไม่ต้องสร้างใหม่ (ตรวจสอบให้แน่ใจว่าการแมปใน assistant_dists/dream/dev.yml ถูกต้อง):
AGENT_PORT=4242 docker-compose -f docker-compose.yml -f assistant_dists/dream/docker-compose.override.yml -f assistant_dists/dream/dev.yml restart container-name
docker-compose -f docker-compose.yml -f assistant_dists/dream_persona_prompted/docker-compose.override.yml -f assistant_dists/dream_persona_prompted/dev.yml -f assistant_dists/dream_persona_prompted/proxy.yml up --build
นอกจากนี้เรายังรวมการกำหนดค่าที่มีการจัดสรร GPU สำหรับสภาพแวดล้อมที่มี GPU หลายตัวอีกด้วย
DeepPavlov Agent มีตัวเลือกมากมายสำหรับการโต้ตอบ: อินเทอร์เฟซบรรทัดคำสั่ง, HTTP API และบอท Telegram
ในแท็บเทอร์มินัลแยกต่างหากให้รัน:
docker-compose exec agent python -m deeppavlov_agent.run agent.channel=cmd agent.pipeline_config=assistant_dists/dream/pipeline_conf.json
ใส่ชื่อผู้ใช้ของคุณและพูดคุยกับ Dream!
เมื่อคุณเริ่มบอทแล้ว Agent API ของ DeepPavlov จะทำงานบน http://localhost:4242 คุณสามารถเรียนรู้เกี่ยวกับ API ได้จากเอกสารตัวแทน DeepPavlov
อินเทอร์เฟซการแชทพื้นฐานจะมีให้ที่ http://localhost:4242/chat
ปัจจุบัน Telegram bot ถูกปรับใช้ แทน HTTP API แก้ไขคำจำกัดความ command agent ภายในการกำหนดค่า docker-compose.override.yml :
agent:
command: sh -c 'bin/wait && python -m deeppavlov_agent.run agent.channel=telegram agent.telegram_token=<TELEGRAM_BOT_TOKEN> agent.pipeline_config=assistant_dists/dream/pipeline_conf.json'
หมายเหตุ: ถือว่าโทเค็น Telegram ของคุณเป็นความลับและอย่าส่งต่อไปยังที่เก็บข้อมูลสาธารณะ!
Dream ใช้ไฟล์การกำหนดค่านักเทียบท่าหลายไฟล์:
./docker-compose.yml คือการกำหนดค่าหลักซึ่งรวมถึงคอนเทนเนอร์สำหรับ DeepPavlov Agent และฐานข้อมูล mongo
./assistant_dists/*/docker-compose.override.yml แสดงรายการส่วนประกอบทั้งหมดสำหรับการแจกจ่าย
./assistant_dists/dream/dev.yml มีการเชื่อมโยงโวลุ่มเพื่อการดีบัก Dream ที่ง่ายขึ้น
./assistant_dists/dream/proxy.yml คือรายการคอนเทนเนอร์พร็อกซี
หากทรัพยากรการปรับใช้ของคุณมีจำกัด คุณสามารถแทนที่คอนเทนเนอร์ด้วยสำเนาพร็อกซีที่โฮสต์โดย DeepPavlov เมื่อต้องการทำเช่นนี้ ให้แทนที่คำจำกัดความคอนเทนเนอร์เหล่านั้นภายใน proxy.yml เช่น:
convers-evaluator-annotator:
command: ["nginx", "-g", "daemon off;"]
build:
context: dp/proxy/
dockerfile: Dockerfile
environment:
- PROXY_PASS=proxy.deeppavlov.ai:8004
- SERVICE_PORT=8004
และรวมการกำหนดค่านี้ไว้ในคำสั่งการปรับใช้ของคุณ:
docker-compose -f docker-compose.yml -f assistant_dists/dream/docker-compose.override.yml -f assistant_dists/dream/dev.yml -f assistant_dists/dream/proxy.yml up --build
ตามค่าเริ่มต้น proxy.yml จะมีคำจำกัดความของพร็อกซีที่มีอยู่ทั้งหมด
Dream Architecture นำเสนอในภาพต่อไปนี้: 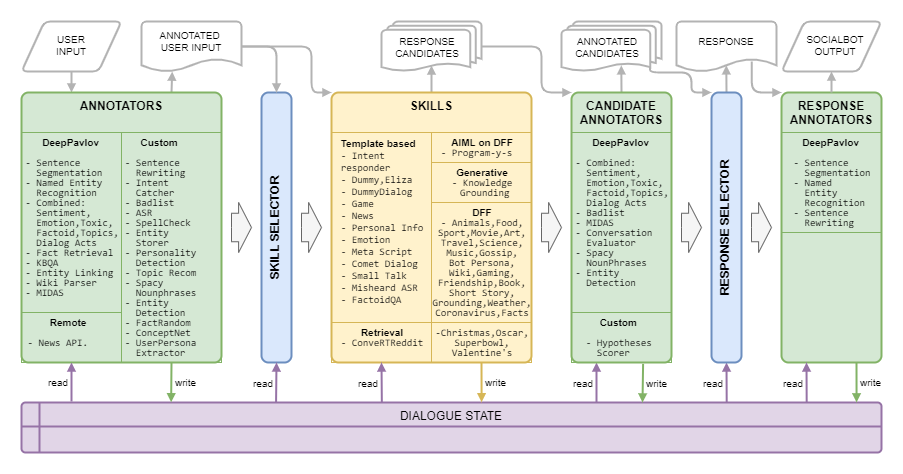
| ชื่อ | ความต้องการ | คำอธิบาย |
|---|---|---|
| ตัวเลือกตามกฎ | อัลกอริทึมที่เลือกรายการทักษะเพื่อสร้างการตอบสนองของผู้สมัครต่อบริบทปัจจุบัน โดยพิจารณาจากหัวข้อ ตัวตน อารมณ์ ความเป็นพิษ บทสนทนา และประวัติการสนทนา | |
| ตัวเลือกการตอบสนอง | แรม 50 เมกะไบต์ | อัลกอริทึมที่เลือกคำตอบสุดท้ายจากรายการคำตอบของผู้สมัครที่กำหนด |
| ชื่อ | ความต้องการ | คำอธิบาย |
|---|---|---|
| ASR | แรม 40 เมกะไบต์ | คำนวณความเชื่อมั่น ASR โดยรวมสำหรับคำพูดที่กำหนด และให้คะแนนเป็น ต่ำมาก ต่ำ ปานกลาง หรือ สูง (สำหรับมาร์กอัปของ Amazon) |
| คำที่ไม่อยู่ในรายการ | แรม 150 เมกะไบต์ | ตรวจจับคำและวลีจากรายการที่ไม่ดี |
| การจำแนกประเภทแบบรวม | แรม 1.5GB, การ์ดจอ 3.5GB | แบบจำลองที่อิงจาก BERT รวมถึงการจำแนกหัวข้อ การจำแนกบทสนทนา ความรู้สึก ความเป็นพิษ อารมณ์ การจำแนกข้อเท็จจริง |
| การจำแนกประเภทรวมน้ำหนักเบา | แรม 1.6GB | รุ่นเดียวกับ Combined Classification แต่ใช้เวลาน้อยลง 42% เนื่องจากแกนหลักที่เบากว่า |
| ดาวหางอะตอม | แรม 2GB, การ์ดจอ 1.1GB | แบบจำลองการทำนายสามัญสำนึก COMeT Atomic |
| COMeT ConceptNet | แรม 2GB, การ์ดจอ 1.1GB | แบบจำลองการทำนายแบบ Commonsense COMeT ConceptNet |
| Convers Evaluator คำอธิบายประกอบ | RAM 1GB, การ์ดจอ 4.5GB | ได้รับการฝึกอบรมเกี่ยวกับข้อมูลรางวัล Alexa จากการแข่งขันครั้งก่อนๆ และคาดการณ์ว่าคำตอบของผู้สมัครนั้นน่าสนใจ เข้าใจได้ ตรงประเด็น มีส่วนร่วม หรือผิดพลาด |
| การจำแนกอารมณ์ | แรม 2.5GB | ตัวอธิบายการจำแนกอารมณ์ |
| การตรวจจับเอนทิตี | แรม 1.5GB, การ์ดจอ 3.2GB | แยกเอนทิตีและประเภทของมันออกจากคำพูด |
| การเชื่อมโยงเอนทิตี | แรม 2.5GB, การ์ดจอ 1.3GB | ค้นหารหัสเอนทิตี Wikidata สำหรับเอนทิตีที่ตรวจพบด้วยการตรวจจับเอนทิตี |
| ผู้จัดเก็บเอนทิตี | แรม 220 เมกะไบต์ | องค์ประกอบตามกฎ ซึ่งจัดเก็บเอนทิตีจากคำพูดของผู้ใช้และโซเชียลบอท หากตรวจพบการแสดงออกความคิดเห็นด้วยรูปแบบหรือตัวแยกประเภท MIDAS และบันทึกสิ่งเหล่านั้นพร้อมกับทัศนคติที่ตรวจพบต่อสถานะการสนทนา |
| ข้อเท็จจริงแบบสุ่ม | แรม 50 เมกะไบต์ | ส่งคืนข้อเท็จจริงแบบสุ่มสำหรับเอนทิตีที่กำหนด (สำหรับเอนทิตีจากคำพูดของผู้ใช้) |
| การสืบค้นข้อเท็จจริง | แรม 7.4GB, การ์ดจอ 1.2GB | ดึงข้อเท็จจริงจาก Wikipedia และ wikiHow |
| ตัวจับเจตนา | แรม 1.7GB, การ์ดจอ 2.4GB | แบ่งประเภทคำพูดของผู้ใช้ออกเป็นเจตนาที่กำหนดไว้ล่วงหน้าจำนวนหนึ่งซึ่งได้รับการฝึกฝนในชุดวลีและ regexp |
| เคบีคิวเอ | RAM 2GB, การ์ดจอ 1.4GB | ตอบคำถามข้อเท็จจริงของผู้ใช้ตาม Wikidata KB |
| การจำแนกประเภท MIDAS | แรม 1.1GB, การ์ดจอ 4.5GB | โมเดลที่ใช้ BERT ฝึกฝนกับชุดย่อยคลาสเชิงความหมายของชุดข้อมูล MIDAS |
| เครื่องทำนาย MIDAS | แรม 30 เมกะไบต์ | โมเดลที่ใช้ BERT ฝึกฝนกับชุดย่อยคลาสเชิงความหมายของชุดข้อมูล MIDAS |
| เนอ | แรม 2.2GB, การ์ดจอ 5GB | แยกชื่อบุคคล ชื่อสถานที่ องค์กร ออกจากข้อความที่ไม่มีตัวพิมพ์ |
| คำอธิบายประกอบ API ข่าวสาร | แรม 80 เมกะไบต์ | แยกข่าวสารล่าสุดเกี่ยวกับเอนทิตีหรือหัวข้อโดยใช้ GNews API การปรับใช้ DeepPavlov Dream ใช้คีย์ API ของเราเอง |
| นักจับบุคลิกภาพ | แรม 30 เมกะไบต์ | ทักษะคือการเปลี่ยนคำอธิบายบุคลิกภาพของระบบผ่านทางแชทอินเตอร์เฟส ทำงานเป็นคำสั่งระบบ การตอบสนองจะเป็นข้อความเหมือนระบบ |
| ตัวเลือกพร้อมท์ | แรม 50 เมกะไบต์ | คำอธิบายประกอบใช้ Sentence Ranker เพื่อจัดอันดับพร้อมท์และเลือก N_SENTENCES_TO_RETURN พร้อมท์ที่เกี่ยวข้องมากที่สุด (ขึ้นอยู่กับคำถามที่ให้ไว้ในพร้อมท์) |
| การสกัดคุณสมบัติ | แรม 6.3 กิ๊บ | แยกคุณลักษณะผู้ใช้ออกจากคำพูด |
| คราดคำหลัก | แรม 40 เมกะไบต์ | แยกคำหลักออกจากคำพูดด้วยความช่วยเหลือของอัลกอริทึม RAKE |
| ตัวแยกบุคคลแบบสัมพัทธ์ | แรม 50 เมกะไบต์ | คำอธิบายประกอบใช้ Sentence Ranker เพื่อจัดอันดับประโยคบุคคลและเลือก N_SENTENCES_TO_RETURN ประโยคที่เกี่ยวข้องมากที่สุด |
| Sentrewrite | แรม 200 เมกะไบต์ | เขียนคำพูดของผู้ใช้ใหม่โดยแทนที่คำสรรพนามด้วยชื่อเฉพาะที่ให้ข้อมูลที่เป็นประโยชน์มากขึ้นแก่ส่วนประกอบดาวน์สตรีม |
| เซ็นเซก | แรม 1GB | ช่วยให้เราสามารถจัดการกับคำพูดที่ยาวและซับซ้อนของผู้ใช้โดยแยกออกเป็นประโยคและกู้คืนเครื่องหมายวรรคตอน |
| คำนาม Spacy | แรม 180 เมกะไบต์ | แยกคำนามโดยใช้ Spacy และกรองคำนามทั่วไปออก |
| ตัวแยกประเภทฟังก์ชันคำพูด | แรม 1.1GB, การ์ดจอ 4.5GB | อัลกอริธึมแบบลำดับชั้นขึ้นอยู่กับแบบจำลองเชิงเส้นหลายแบบและวิธีการตามกฎสำหรับการทำนายฟังก์ชันคำพูดที่อธิบายโดย Eggins และ Slade |
| ตัวทำนายฟังก์ชันคำพูด | แรม 1.1GB, การ์ดจอ 4.5GB | ให้ความน่าจะเป็นของฟังก์ชันคำพูดที่สามารถติดตามฟังก์ชันคำพูดที่คาดการณ์โดยตัวแยกประเภทฟังก์ชันคำพูด |
| การประมวลผลการสะกดล่วงหน้า | แรม 50 เมกะไบต์ | องค์ประกอบตามรูปแบบเพื่อเขียนสำนวนภาษาพูดต่างๆ ให้มีรูปแบบการสนทนาที่เป็นทางการมากขึ้น |
| การแนะนำหัวข้อ | แรม 40 เมกะไบต์ | เสนอหัวข้อสำหรับการสนทนาเพิ่มเติมโดยใช้ข้อมูลเกี่ยวกับหัวข้อที่กล่าวถึงและการตั้งค่าของผู้ใช้ เวอร์ชันปัจจุบันอิงตามบุคลิกของ Reddit (ดู Dream Report สำหรับ Alexa Prize 4) |
| การจำแนกประเภทความเป็นพิษ | แรม 3.5GB, การ์ดจอ 3GB | โมเดลการจำแนกประเภทความเป็นพิษจาก Transformers ที่ระบุเป็น PRETRAINED_MODEL_NAME_OR_PATH |
| ผู้ใช้ Persona Extractor | แรม 40 เมกะไบต์ | กำหนดหมวดหมู่อายุที่ผู้ใช้เป็นสมาชิกโดยพิจารณาจากคำสำคัญบางคำ |
| วิกิพาร์เซอร์ | แรม 100 เมกะไบต์ | แยก Wikidata triplets สำหรับเอนทิตีที่ตรวจพบด้วย Entity Linking |
| ข้อเท็จจริงวิกิ | แรม 1.7GB | แบบจำลองที่แยกข้อเท็จจริงที่เกี่ยวข้องจากหน้า Wikipedia และ WikiHow |
| ชื่อ | ความต้องการ | คำอธิบาย |
|---|---|---|
| DialoGPT | แรม 1.2GB, การ์ดจอ 2.1GB | บริการกำเนิดตามโมเดลกำเนิดของ Transformers โมเดลถูกตั้งค่าในอาร์กิวเมนต์การเขียนนักเทียบท่า PRETRAINED_MODEL_NAME_OR_PATH (เช่น microsoft/DialoGPT-small ที่มี 0.2-0.5 วินาทีบน GPU) |
| อิงตามบุคคลของ DialoGPT | แรม 1.2GB, การ์ดจอ 2.1GB | บริการกำเนิดตามโมเดลกำเนิดของ Transformers โมเดลได้รับการฝึกอบรมล่วงหน้าบนชุดข้อมูล PersonaChat เพื่อสร้างการตอบสนองที่มีเงื่อนไขในประโยคหลายประโยคของบุคลิกของ socialbot |
| คำบรรยายภาพ | RAM 4GB, การ์ดจอ 5.4GB | สร้างการแสดงข้อความของภาพที่ได้รับ |
| การเติม | แรม 1GB, การ์ดจอ 1.2GB | (ปิดอยู่แต่มีรหัส) บริการสร้างตามโมเดล Infilling สำหรับคำพูดที่กำหนดส่งคืนคำพูดโดยที่ _ จากข้อความต้นฉบับถูกแทนที่ด้วยโทเค็นที่สร้างขึ้น |
| การต่อสายดินความรู้ | แรม 2GB, การ์ดจอ 2.1GB | บริการสร้างตามสถาปัตยกรรม BlenderBot ที่ให้การตอบสนองต่อบริบทโดยคำนึงถึงย่อหน้าข้อความเพิ่มเติม |
| สวมหน้ากาก LM | แรม 1.1GB, การ์ดจอ 1GB | (ปิดไปแล้วแต่มีโค้ดอยู่) |
| Seq2seq อิงตามบุคคล | แรม 1.5GB, การ์ดจอ 1.5GB | บริการกำเนิดตามโมเดล Transformers seq2seq โมเดลได้รับการฝึกอบรมล่วงหน้าบนชุดข้อมูล PersonaChat เพื่อสร้างการตอบสนองที่มีเงื่อนไขในประโยคหลายประโยคของบุคลิกของ socialbot |
| อันดับประโยค | แรม 1.2GB, การ์ดจอ 2.1GB | โมเดลการจัดอันดับที่กำหนดเป็น PRETRAINED_MODEL_NAME_OR_PATH ซึ่งสำหรับประโยคระบบปฏิบัติการคู่จะส่งกลับคะแนนลอยตัวของการติดต่อสื่อสาร |
| เรื่องราวGPT | แรม 2.6GB, การ์ดจอ 2.15GB | บริการสร้างตาม GPT-2 ที่ได้รับการปรับแต่งอย่างละเอียดสำหรับชุดคำหลักที่กำหนดจะส่งคืนเรื่องสั้นโดยใช้คำหลัก |
| GPT-3.5 | แรม 100 เมกะไบต์ | บริการสร้างตามบริการ OpenAI API โมเดลถูกตั้งค่าในอาร์กิวเมนต์การเขียนนักเทียบท่า PRETRAINED_MODEL_NAME_OR_PATH (โดยเฉพาะในบริการนี้ จะใช้ text-davinci-003 |
| ChatGPT | แรม 100 เมกะไบต์ | บริการสร้างตามบริการ OpenAI API โมเดลได้รับการตั้งค่าในอาร์กิวเมนต์การเขียนนักเทียบท่า PRETRAINED_MODEL_NAME_OR_PATH (โดยเฉพาะในบริการนี้ จะใช้ gpt-3.5-turbo |
| เรื่องราวพร้อมท์GPT | RAM 3GB, การ์ดจอ 4GB | บริการกำเนิดขึ้นอยู่กับ GPT-2 ที่ได้รับการปรับแต่งสำหรับหัวข้อที่กำหนดซึ่งแสดงด้วยคำนามหนึ่งคำที่ส่งคืนเรื่องสั้นในหัวข้อที่กำหนด |
| GPT-J 6B | แรม 1.5GB, การ์ดจอ 24.2GB | บริการกำเนิดตามโมเดลกำเนิดของ Transformers โมเดลถูกตั้งค่าในอาร์กิวเมนต์การเขียนนักเทียบท่า PRETRAINED_MODEL_NAME_OR_PATH (โดยเฉพาะในบริการนี้ จะใช้โมเดล GPT-J |
| บลูมซ์ 7B | แรม 2.5GB, การ์ดจอ 29GB | บริการกำเนิดตามโมเดลกำเนิดของ Transformers โมเดลถูกตั้งค่าในอาร์กิวเมนต์การเขียนนักเทียบท่า PRETRAINED_MODEL_NAME_OR_PATH (โดยเฉพาะในบริการนี้ จะใช้โมเดล BLOOMZ-7b1 |
| GPT-JT 6B | แรม 2.5GB, การ์ดจอ 25.1GB | บริการกำเนิดตามโมเดลกำเนิดของ Transformers โมเดลถูกตั้งค่าในอาร์กิวเมนต์การเขียนนักเทียบท่า PRETRAINED_MODEL_NAME_OR_PATH (โดยเฉพาะในบริการนี้ จะใช้โมเดล GPT-JT |
| ชื่อ | ความต้องการ | คำอธิบาย |
|---|---|---|
| อเล็กซา แฮนด์เลอร์ | แรม 30 เมกะไบต์ | ตัวจัดการคำสั่ง Alexa เฉพาะหลายคำสั่ง |
| ทักษะคริสต์มาส | แรม 30 เมกะไบต์ | รองรับคำถามที่พบบ่อย ข้อเท็จจริง และสคริปต์สำหรับคริสต์มาส |
| ทักษะโต้ตอบของดาวหาง | แรม 300 เมกะไบต์ | ใช้โมเดล COMeT ConceptNet ในการแสดงความคิดเห็น ถามคำถาม หรือแสดงความคิดเห็นเกี่ยวกับการกระทำของผู้ใช้ที่กล่าวถึงในบทสนทนา |
| แปลงเรดดิท | แรม 1.2GB | ใช้ตัวเข้ารหัส ConveRT เพื่อสร้างการนำเสนอที่มีประสิทธิภาพสำหรับประโยค |
| ทักษะจำลอง | ส่วนหนึ่งของคอนเทนเนอร์ตัวแทน | ทักษะทางเลือกที่มีการตอบกลับของผู้สมัครที่ไม่เป็นพิษหลายรายการ |
| กล่องโต้ตอบทักษะจำลอง | แรม 600 เมกะไบต์ | ส่งคืนเทิร์นถัดไปจากชุดข้อมูลการสนทนาเฉพาะหากการตอบสนองของผู้ใช้ต่อทักษะจำลองนั้นคล้ายกับการตอบสนองที่สอดคล้องกันในข้อมูลต้นฉบับ |
| เอลิซ่า | แรม 30 เมกะไบต์ | แชทบอท (https://github.com/wadetb/eliza) |
| ทักษะทางอารมณ์ | แรม 40 เมกะไบต์ | ส่งคืนการตอบสนองต่อเทมเพลตต่ออารมณ์ที่ตรวจพบโดย Emotion Classification จากตัวอธิบายการจำแนกแบบรวม |
| ข้อเท็จจริง QA | แรม 170 เมกะไบต์ | ตอบคำถามที่เป็นข้อเท็จจริง |
| ทักษะความร่วมมือของเกม | แรม 100 เมกะไบต์ | ให้การสนทนาแก่ผู้ใช้เกี่ยวกับเกมคอมพิวเตอร์: แผนภูมิเกมที่ดีที่สุดสำหรับปีที่ผ่านมา เดือนที่ผ่านมา และสัปดาห์ที่ผ่านมา |
| ทักษะการบำรุงรักษารถเกี่ยวข้าว | แรม 30 เมกะไบต์ | ทักษะการบำรุงรักษารถเกี่ยวข้าว |
| ผู้เก็บเกี่ยวบำรุงรักษาทักษะ Gobot | แรม 30 เมกะไบต์ | รถเก็บเกี่ยวบำรุงรักษาทักษะที่มุ่งเน้นเป้าหมาย |
| ทักษะการปูพื้นฐานความรู้ | แรม 100 เมกะไบต์ | สร้างการตอบกลับตามประวัติการสนทนาและให้ความรู้ที่เกี่ยวข้องกับหัวข้อการสนทนาปัจจุบัน |
| ทักษะเมตาสคริปต์ | แรม 150 เมกะไบต์ | ให้บทสนทนาหลายรอบเกี่ยวกับกิจกรรมของมนุษย์ ทักษะนี้ใช้แบบจำลอง COMeT Atomic เพื่อสร้างคำอธิบายและคำถามทั่วไปในหลาย ๆ ด้าน |
| ASR ผิดพลาด | แรม 40 เมกะไบต์ | ใช้คำอธิบายประกอบตัวประมวลผล ASR เพื่อให้ข้อเสนอแนะแก่ผู้ใช้เมื่อความเชื่อมั่น ASR ต่ำเกินไป |
| ทักษะ API ข่าวสาร | แรม 60 เมกะไบต์ | นำเสนอข่าวสารล่าสุดยอดนิยมเกี่ยวกับเอนทิตีหรือหัวข้อโดยใช้ GNews API |
| ออสการ์ สกิล | แรม 30 เมกะไบต์ | รองรับคำถามที่พบบ่อย ข้อเท็จจริง และสคริปต์สำหรับ Oscar |
| ทักษะข้อมูลส่วนบุคคล | แรม 40 เมกะไบต์ | สอบถามและจัดเก็บชื่อผู้ใช้ บ้านเกิด และที่ตั้ง |
| โปรแกรม DFF ทักษะ Y | แรม 800 เมกะไบต์ | [เวอร์ชัน DFF ใหม่] โปรแกรม Chatbot Y (https://github.com/keiffster/program-y) ปรับให้เหมาะกับ Dream socialbot |
| โปรแกรม DFF และทักษะอันตราย | แรม 100 เมกะไบต์ | [เวอร์ชัน DFF ใหม่] โปรแกรม Chatbot Y (https://github.com/keiffster/program-y) ปรับให้เหมาะกับ Dream socialbot ซึ่งมีการตอบสนองต่อสถานการณ์อันตรายในกล่องโต้ตอบ |
| โปรแกรม DFF Y ทักษะกว้าง | แรม 110 เมกะไบต์ | [เวอร์ชัน DFF ใหม่] โปรแกรม Chatbot Y (https://github.com/keiffster/program-y) ปรับให้เหมาะกับ Dream socialbot ซึ่งมีเฉพาะเทมเพลตทั่วไปเท่านั้น (มีความมั่นใจต่ำกว่า) |
| ทักษะการพูดเล็ก ๆ | แรม 35 เมกะไบต์ | ถามคำถามโดยใช้สคริปต์ที่เขียนด้วยลายมือ 25 หัวข้อ รวมถึงแต่ไม่จำกัดเฉพาะเรื่องความรัก กีฬา งาน สัตว์เลี้ยง ฯลฯ |
| ทักษะซูเปอร์โบว์ล | แรม 30 เมกะไบต์ | รองรับคำถามที่พบบ่อย ข้อเท็จจริง และสคริปต์สำหรับ SuperBowl |
| ส่งข้อความถึงฝ่ายประกันคุณภาพ | แรม 1.8GB, การ์ดจอ 2.8GB | บริการค้นหาคำตอบของคำถามที่เป็นข้อเท็จจริงในรูปแบบข้อความ |
| ทักษะวันวาเลนไทน์ | แรม 30 เมกะไบต์ | รองรับคำถามที่พบบ่อย ข้อเท็จจริง และสคริปต์สำหรับวันวาเลนไทน์ |
| วิกิสนเทศทักษะการโทร | แรม 100 เมกะไบต์ | สร้างคำพูดโดยใช้ Wikidata triplets เปิดไม่ติด จำเป็นต้องปรับปรุง |
| ทักษะสัตว์ DFF | แรม 200 เมกะไบต์ | ถูกสร้างขึ้นโดยใช้ DFF และมีการสนทนาเกี่ยวกับสัตว์สามสาขา ได้แก่ สัตว์เลี้ยงของผู้ใช้ สัตว์เลี้ยงของโซเชียลบอท และสัตว์ป่า |
| ทักษะศิลปะ DFF | แรม 100 เมกะไบต์ | ทักษะที่ใช้ DFF เพื่อหารือเกี่ยวกับศิลปะ |
| ทักษะหนังสือ DFF | แรม 400 เมกะไบต์ | [เวอร์ชัน DFF ใหม่] ตรวจจับชื่อหนังสือและผู้แต่งที่กล่าวถึงในคำพูดของผู้ใช้ด้วยความช่วยเหลือของตัวแยกวิเคราะห์ Wiki และการเชื่อมโยงเอนทิตี และแนะนำหนังสือโดยใช้ประโยชน์จากข้อมูลจากฐานข้อมูล GoodReads |
| ทักษะบุคคลของบอท DFF | แรม 150 เมกะไบต์ | มีวัตถุประสงค์เพื่อหารือเกี่ยวกับรายการโปรดของผู้ใช้และ 20 เรื่องยอดนิยมพร้อมเรื่องสั้นที่แสดงความคิดเห็นของโซเชียลบอทต่อพวกเขา |
| ทักษะ DFF โคโรนาไวรัส | แรม 110 เมกะไบต์ | [เวอร์ชัน DFF ใหม่] ดึงข้อมูลเกี่ยวกับจำนวนผู้ป่วยและผู้เสียชีวิตจากไวรัสโคโรนาในสถานที่ต่างๆ ที่มาจากศูนย์วิทยาศาสตร์และวิศวกรรมระบบมหาวิทยาลัยจอห์น ฮอปกินส์ |
| ทักษะด้านอาหาร DFF | แรม 150 เมกะไบต์ | สร้างขึ้นด้วย DFF เพื่อส่งเสริมการสนทนาเกี่ยวกับอาหาร |
| ทักษะมิตรภาพ DFF | แรม 100 เมกะไบต์ | [เวอร์ชัน DFF ใหม่] ทักษะที่ใช้ DFF เพื่อทักทายผู้ใช้ในช่วงเริ่มต้นของกล่องโต้ตอบ และส่งต่อผู้ใช้ไปยังทักษะที่มีสคริปต์ |
| ทักษะ DFF Funfact | แรม 100 เมกะไบต์ | [เวอร์ชัน DFF ใหม่] บอกข้อเท็จจริงสนุกๆ แก่ผู้ใช้ |
| ทักษะการเล่นเกม DFF | แรม 80 เมกะไบต์ | ให้การอภิปรายเกี่ยวกับวิดีโอเกม ทักษะการเล่นเกมมีไว้สำหรับการพูดคุยทั่วไปเกี่ยวกับวิดีโอเกม |
| ทักษะการนินทา DFF | แรม 95 เมกะไบต์ | ทักษะที่ใช้ DFF เพื่อหารือเกี่ยวกับข่าวสารเกี่ยวกับพวกเขากับผู้อื่น |
| ทักษะภาพ DFF | แรม 100 เมกะไบต์ | [เวอร์ชัน DFF ใหม่] ทักษะการเขียนสคริปต์ที่อิงจากการตอบกลับคำบรรยายภาพที่ส่ง (จากคำอธิบายประกอบ) พร้อมการตอบสนองที่ระบุในกรณีที่ตรวจพบอาหาร สัตว์ หรือผู้คน และการตอบสนองเริ่มต้นเป็นอย่างอื่น |
| ทักษะเทมเพลต DFF | แรม 50 เมกะไบต์ | [เวอร์ชัน DFF ใหม่] ทักษะตาม DFF ที่ให้ตัวอย่างการใช้งาน DFF |
| ทักษะพร้อมท์เทมเพลต DFF | แรม 50 เมกะไบต์ | [เวอร์ชัน DFF ใหม่] ทักษะที่ใช้ DFF ที่ให้คำตอบที่สร้างโดยโมเดลภาษาตามข้อความแจ้งที่ระบุและบริบทของกล่องโต้ตอบ โมเดลที่จะใช้ระบุไว้ใน GENERATIVE_SERVICE_URL ตัวอย่างเช่น คุณอาจใช้บริการ Transformer LM GPTJ |
| ทักษะการต่อสายดินของ DFF | แรม 90 เมกะไบต์ | [เวอร์ชัน DFF ใหม่] ทักษะที่ใช้ DFF ในการตอบหัวข้อของการสนทนา เพื่อสร้างการรับรู้ เพื่อสร้างการตอบสนองที่เป็นสากลสำหรับบทสนทนาบางอย่างโดย MIDAS |
| ผู้ตอบกลับเจตนาของ DFF | แรม 100 เมกะไบต์ | [เวอร์ชัน DFF ใหม่] ให้การตอบกลับตามเทมเพลตสำหรับ Intent บางส่วนที่ตรวจพบโดย Intent Catcher Annotator |
| ทักษะภาพยนตร์ DFF | แรม 1.1GB | ใช้งานโดยใช้ DFF และดูแลการสนทนาที่เกี่ยวข้องกับภาพยนตร์ |
| ทักษะดนตรี DFF | แรม 70 เมกะไบต์ | ทักษะที่ใช้ DFF เพื่อหารือเกี่ยวกับดนตรี |
| ทักษะวิทยาศาสตร์ DFF | แรม 90 เมกะไบต์ | ทักษะที่ใช้ DFF เพื่อหารือเกี่ยวกับวิทยาศาสตร์ |
| ทักษะเรื่องสั้น DFF | แรม 90 เมกะไบต์ | [เวอร์ชัน DFF ใหม่] บอกเล่าเรื่องราวสั้นของผู้ใช้จาก 3 หมวดหมู่: (1) นิทานก่อนนอน เช่น นิทานและเรื่องศีลธรรม (2) เรื่องสยองขวัญ และ (3) เรื่องตลก |
| ทักษะกีฬา DFF | แรม 70 เมกะไบต์ | ทักษะที่ใช้ DFF เพื่อหารือเกี่ยวกับกีฬา |
| ทักษะการเดินทาง DFF | แรม 70 เมกะไบต์ | ทักษะที่ใช้ DFF เพื่อหารือเกี่ยวกับการเดินทาง |
| ทักษะสภาพอากาศ DFF | แรม 1.4GB | [เวอร์ชัน DFF ใหม่] ใช้บริการ OpenWeatherMap เพื่อรับการคาดการณ์สำหรับตำแหน่งของผู้ใช้ |
| ทักษะวิกิ DFF | แรม 150 เมกะไบต์ | ใช้สำหรับสร้างสถานการณ์ด้วยการดึงข้อมูลเอนทิตี การกรอกช่อง การแทรกข้อเท็จจริง และการรับทราบ |
| ชื่อ | ความต้องการ | คำอธิบาย |
|---|---|---|
| ทักษะคำถามที่พบบ่อยเกี่ยวกับ AI | แรม 150 เมกะไบต์ | [เวอร์ชัน DFF ใหม่] ทุกสิ่งที่คุณอยากรู้เกี่ยวกับ AI ยุคใหม่แต่ไม่กล้าถาม! ผู้ช่วยคำถามที่พบบ่อยนี้จะแชทกับคุณพร้อมอธิบายหัวข้อที่ง่ายที่สุดจากโลกเทคโนโลยีในปัจจุบัน |
| ทักษะสไตลิสต์แฟชั่น | แรม 150 เมกะไบต์ | [เวอร์ชัน DFF ใหม่] ได้รับการปกป้องในทุกฤดูกาลด้วยผู้ช่วยเสื้อผ้าของ da Costa Industries! สัมผัสประสบการณ์ความสะดวกสบายและการปกป้องขั้นสุดยอด ไม่ว่าสภาพอากาศจะเป็นอย่างไร รักษาความอบอุ่นในฤดูหนาว... |
| ทักษะบุคลิกภาพในฝัน | แรม 150 เมกะไบต์ | [เวอร์ชัน DFF ใหม่] ทักษะตามพรอมต์ที่ใช้บริการที่สร้างมาเพื่อสร้างการตอบกลับตามพรอมต์ที่กำหนด |
| ทักษะทางการตลาด | แรม 150 เมกะไบต์ | [เวอร์ชัน DFF ใหม่] เชื่อมต่อกับผู้ชมของคุณอย่างที่ไม่เคยมีมาก่อนด้วย Marketing AI Assistant! เข้าถึงจุดสูงสุดใหม่ของความสำเร็จโดยใช้ประโยชน์จากพลังแห่งความเห็นอกเห็นใจ บอกลา.. |
| ทักษะเทพนิยาย | แรม 150 เมกะไบต์ | [เวอร์ชัน DFF ใหม่] ผู้ช่วยนี้จะเล่านิทานสั้น ๆ แต่น่าดึงดูดให้กับคุณหรือลูก ๆ ของคุณ เลือกตัวละครและหัวข้อและปล่อยให้ส่วนที่เหลือเป็นจินตนาการของ AI |
| ทักษะด้านโภชนาการ | แรม 150 เมกะไบต์ | [เวอร์ชัน DFF ใหม่] ค้นพบเคล็ดลับการกินเพื่อสุขภาพกับผู้ช่วย AI ของเรา! ค้นหาตัวเลือกอาหารที่มีคุณค่าทางโภชนาการสำหรับคุณและคนที่คุณรักได้อย่างง่ายดาย บอกลาความเครียดระหว่างมื้ออาหาร และสวัสดีกับความอร่อย... |
| ทักษะการฝึกสอนชีวิต | แรม 150 เมกะไบต์ | [เวอร์ชัน DFF ใหม่] ปลดล็อกศักยภาพสูงสุดของคุณด้วยผู้ช่วย AI ที่ได้รับสิทธิบัตรของ Rhodes & Co! เข้าถึงประสิทธิภาพสูงสุดทั้งที่ทำงานและที่บ้าน ก้าวสู่ฟอร์มระดับท็อปได้อย่างง่ายดายและสร้างแรงบันดาลใจให้ผู้อื่นด้วย |
คูราตอฟ วาย. และคณะ รายงานทางเทคนิค DREAM สำหรับรางวัล Alexa Prize 2019 // การดำเนินการรับรางวัล Alexa – 2020.
เบย์มูร์ซินา ดี. และคณะ รายงานทางเทคนิค DREAM สำหรับรางวัล Alexa Prize 4 // การดำเนินการรับรางวัล Alexa – 2021.
DeepPavlov Dream ได้รับอนุญาตภายใต้ Apache 2.0
Program-y (ดู dream/skills/dff_program_y_skill , dream/skills/dff_program_y_wide_skill , dream/skills/dff_program_y_dangerous_skill ) ได้รับอนุญาตภายใต้ Apache 2.0 Eliza (ดู dream/skills/eliza ) ได้รับอนุญาตภายใต้ใบอนุญาต MIT
สำหรับการสร้างใบรับรอง xlsx - ไฟล์ที่มีการตอบกลับของบอท คุณสามารถใช้สคริปต์ xlsx_responder.py ได้โดยดำเนินการ
docker-compose -f docker-compose.yml -f dev.yml exec -T -u $( id -u ) agent python3
utils/xlsx_responder.py --url http://0.0.0.0:4242
--input ' tests/dream/test_questions.xlsx '
--output ' tests/dream/output/test_questions_output.xlsx '
--cache tests/dream/output/test_questions_output_ $( date --iso-8601=seconds ) .json ตรวจสอบให้แน่ใจว่าบริการทั้งหมดถูกปรับใช้ --input - ไฟล์ xlsx ที่มีคำถามเกี่ยวกับการรับรอง --output - ไฟล์ xlsx พร้อมการตอบกลับของบอท --cache - json ที่มีมาร์กอัปโดยละเอียดและใช้สำหรับแคช


