Okapi
1.0.0
โอคาปิ
โมเดลภาษาขนาดใหญ่ที่ปรับแต่งตามคำสั่งในหลายภาษาพร้อมการเรียนรู้เสริมจากผลตอบรับของมนุษย์
นี่คือการซื้อคืนสำหรับกรอบงาน Okapi ที่แนะนำทรัพยากรและแบบจำลองสำหรับการปรับแต่งคำสั่งสำหรับโมเดลภาษาขนาดใหญ่ (LLM) พร้อมการเรียนรู้แบบเสริมแรงจากผลตอบรับของมนุษย์ (RLHF) ในหลายภาษา เฟรมเวิร์กของเรารองรับ 26 ภาษา รวมถึงภาษาที่มีทรัพยากรสูง 8 ภาษา ภาษาที่มีทรัพยากรปานกลาง 11 ภาษา และภาษาที่มีทรัพยากรต่ำ 7 ภาษา
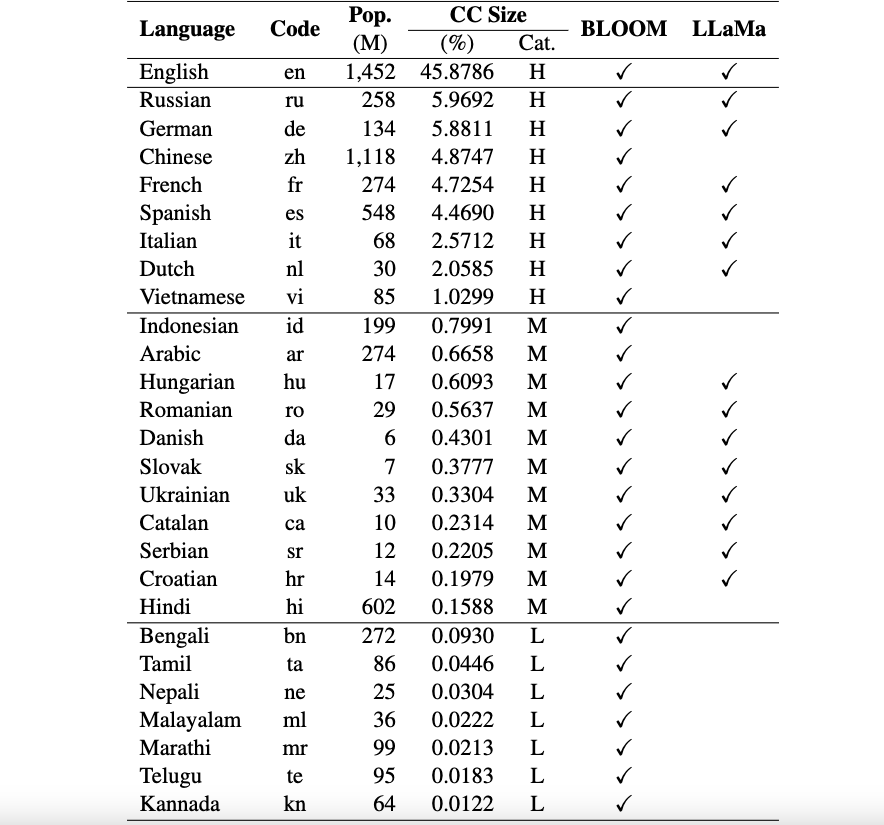
ทรัพยากร Okapi : เราจัดเตรียมทรัพยากรเพื่อดำเนินการปรับแต่งคำสั่งด้วย RLHF สำหรับ 26 ภาษา รวมถึงข้อความแจ้ง ChatGPT ชุดข้อมูลคำสั่งหลายภาษา และข้อมูลการจัดอันดับการตอบสนองหลายภาษา
โมเดล Okapi : เราให้บริการ LLM ที่ปรับแต่งตามคำสั่ง RLHF สำหรับ 26 ภาษาบนชุดข้อมูล Okapi โมเดลของเรามีทั้งเวอร์ชันที่ใช้ BLOOM และ LLaMa นอกจากนี้เรายังจัดเตรียมสคริปต์เพื่อโต้ตอบกับโมเดลของเราและปรับแต่ง LLM ด้วยทรัพยากรของเรา
ชุดข้อมูลเกณฑ์มาตรฐานการประเมินหลายภาษา : เรามีชุดข้อมูลเกณฑ์มาตรฐานสามชุดสำหรับการประเมินแบบจำลองภาษาขนาดใหญ่หลายภาษา (LLM) สำหรับ 26 ภาษา คุณสามารถเข้าถึงชุดข้อมูลและสคริปต์การประเมินผลทั้งหมดได้ที่นี่
ประกาศเกี่ยวกับการใช้งานและใบอนุญาต : Okapi มีวัตถุประสงค์และได้รับใบอนุญาตเพื่อใช้ในการวิจัยเท่านั้น ชุดข้อมูลเป็นแบบ CC BY NC 4.0 (อนุญาตเฉพาะการใช้งานที่ไม่ใช่เชิงพาณิชย์) และแบบจำลองที่ได้รับการฝึกอบรมโดยใช้ชุดข้อมูลไม่ควรนำไปใช้นอกวัตถุประสงค์การวิจัย
สามารถดูเอกสารทางเทคนิคของเราพร้อมผลการประเมินได้ที่นี่
เราดำเนินการกระบวนการรวบรวมข้อมูลที่ครอบคลุมเพื่อเตรียมข้อมูลที่จำเป็นสำหรับกรอบการทำงานหลายภาษาของเรา Okapi ในสี่ขั้นตอนหลัก:
หากต้องการดาวน์โหลดชุดข้อมูลทั้งหมด คุณสามารถใช้สคริปต์ต่อไปนี้:
bash scripts/download.shหากคุณต้องการเพียงข้อมูลสำหรับภาษาใดภาษาหนึ่ง คุณสามารถระบุรหัสภาษาเป็นอาร์กิวเมนต์ของสคริปต์ได้:
bash scripts/download.sh [LANG]
# For example, to download the dataset for Vietnamese: bash scripts/download.sh viหลังจากดาวน์โหลด ข้อมูลที่เผยแพร่ของเราสามารถพบได้ในไดเร็กทอรี ชุดข้อมูล ประกอบด้วย:
multilingual-alpaca-52k : ข้อมูลการแปลคำแนะนำภาษาอังกฤษ 52K ใน Alpaca เป็น 26 ภาษา
multilingual-ranking-data-42k : ข้อมูลการจัดอันดับการตอบสนองหลายภาษาสำหรับ 26 ภาษา สำหรับแต่ละภาษา เรามีคำแนะนำ 42K; แต่ละคนมีคำตอบอันดับ 4 ข้อมูลนี้สามารถใช้เพื่อฝึกโมเดลรางวัลสำหรับ 26 ภาษา
multilingual-rl-tuning-64k : ข้อมูลคำแนะนำหลายภาษาสำหรับ RLHF เราให้คำแนะนำ 62,000 รายการสำหรับแต่ละภาษาจาก 26 ภาษา
ด้วยการใช้ชุดข้อมูล Okapi และเทคนิคการปรับแต่งคำสั่งแบบ RLHF เราแนะนำ LLM ที่ปรับแต่งอย่างละเอียดหลายภาษาสำหรับ 26 ภาษา ซึ่งสร้างขึ้นจาก LLaMA และ BLOOM เวอร์ชัน 7B สามารถรับแบบจำลองได้จาก HuggingFace ที่นี่
Okapi รองรับการแชทแบบโต้ตอบด้วย LLM ที่ปรับแต่งตามคำแนะนำหลายภาษาใน 26 ภาษา ทำตามขั้นตอนต่อไปนี้สำหรับการแชท:
git clone https://github.com/nlp-uoregon/Okapi.git
cd Okapi
pip install -r requirements.txt
from chat import pipeline
model_path = 'uonlp/okapi-vi-bloom'
p = pipeline ( model_path , gpu = True )
instruction = 'Dịch câu sau sang Tiếng Việt' # Translate the following sentence into Vietnamese
prompt_input = 'The City of Eugene - a great city for the arts and outdoors. '
response = p . generate ( instruction = instruction , prompt_input = prompt_input )
print ( response )นอกจากนี้เรายังจัดเตรียมสคริปต์เพื่อปรับแต่ง LLM ด้วยข้อมูลคำแนะนำของเราโดยใช้ RLHF ซึ่งครอบคลุมสามขั้นตอนหลัก: การปรับแต่งอย่างละเอียดภายใต้การดูแล การสร้างแบบจำลองการให้รางวัล และการปรับแต่งอย่างละเอียดด้วย RLHF ใช้ขั้นตอนต่อไปนี้เพื่อปรับแต่ง LLM:
conda create -n okapi python=3.9
conda activate okapi
pip install -r requirements.txtbash scripts/supervised_finetuning.sh [LANG]bash scripts/reward_modeling.sh [LANG]bash scripts/rl_training.sh [LANG]หากคุณใช้ข้อมูล โมเดล หรือโค้ดในพื้นที่เก็บข้อมูลนี้ โปรดอ้างอิง:
@article { dac2023okapi ,
title = { Okapi: Instruction-tuned Large Language Models in Multiple Languages with Reinforcement Learning from Human Feedback } ,
author = { Dac Lai, Viet and Van Nguyen, Chien and Ngo, Nghia Trung and Nguyen, Thuat and Dernoncourt, Franck and Rossi, Ryan A and Nguyen, Thien Huu } ,
journal = { arXiv e-prints } ,
pages = { arXiv--2307 } ,
year = { 2023 }
}

