MELD
1.0.0
หากคุณสนใจในการทดสอบ IQ LLM โปรดดูงานใหม่ของเรา: AlgoPuzzleVQA
เราได้เปิดตัวฟีเจอร์ภาพที่แยกออกมาโดยใช้ Resnet - https://github.com/declare-lab/MM-Align
สำหรับข้อมูลพื้นฐานที่อัปเดต โปรดไปที่ลิงก์นี้: Conv-emotion
สำหรับการดาวน์โหลดข้อมูลให้ใช้ wget: wget http://web.eecs.umich.edu/~mihalcea/downloads/MELD.Raw.tar.gz
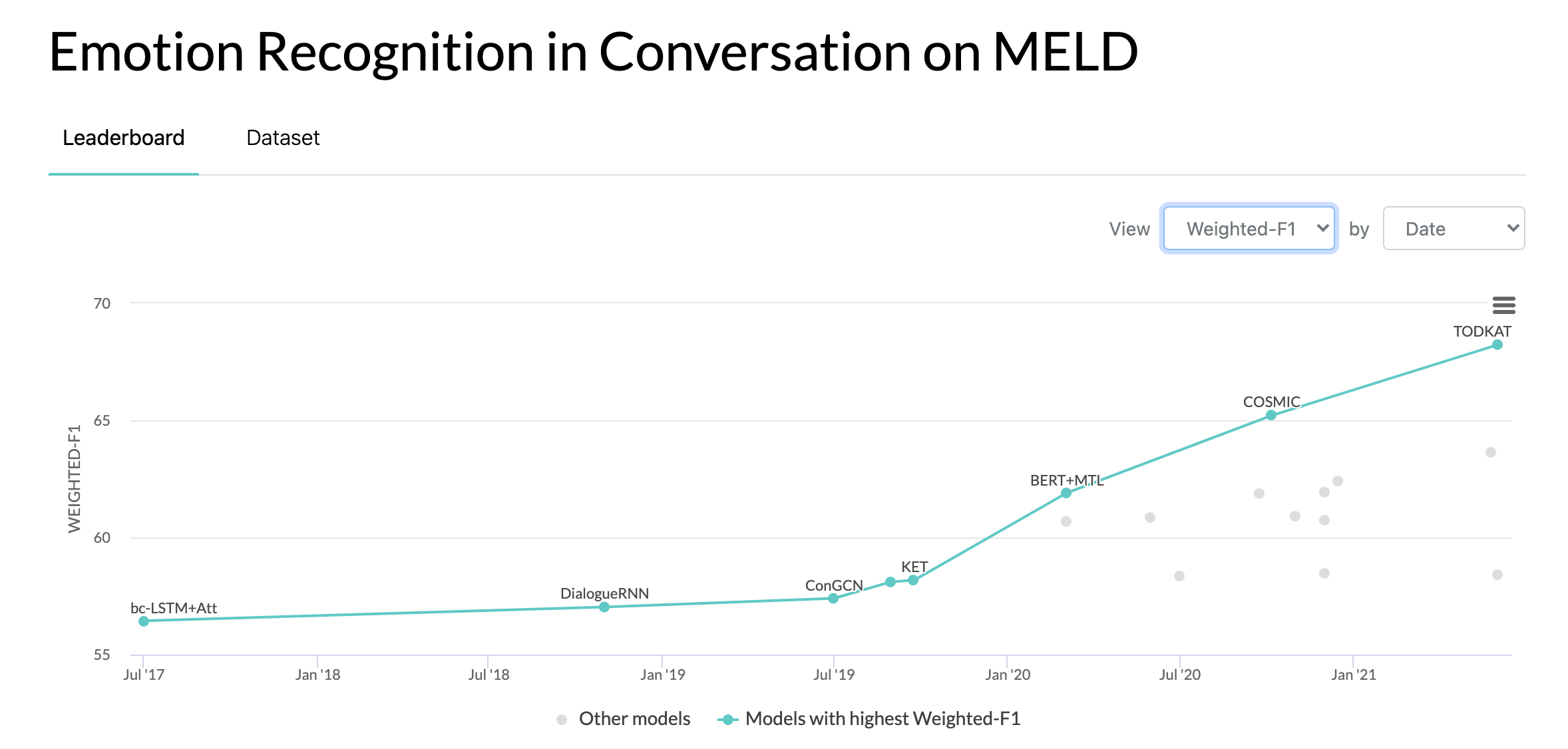
10/10/2020: บทความใหม่และ SOTA ในการจดจำอารมณ์ในการสนทนาบนชุดข้อมูล MELD อ้างถึงไดเร็กทอรี COSMIC สำหรับโค้ด อ่านบทความ -- COSMIC: ความรู้ COmmonSense สำหรับการระบุ eMotion ในการสนทนา
22/05/2019: MELD: A Multimodal Multi-Party Dataset for Emotion Recognition in Conversation ได้รับการยอมรับว่าเป็นรายงานฉบับสมบูรณ์ที่ ACL 2019 ดูรายงานฉบับอัปเดตได้ที่นี่ - https://arxiv.org/pdf/1810.02508 pdf
22/05/2019: Dyadic MELD เปิดตัวแล้ว สามารถใช้ทดสอบโมเดลการสนทนาแบบไดอะดิกได้
15/11/2018: ปัญหาใน train.tar.gz ได้รับการแก้ไขแล้ว
จาง, หยาโจว, ชิวจิ หลี่, ทวายซ่ง, เผิงจาง และปันปัน หวาง "เครือข่ายเชิงโต้ตอบที่ได้รับแรงบันดาลใจจากควอนตัมสำหรับการวิเคราะห์ความรู้สึกในการสนทนา" ไอเจซีเอ 2019.
จาง, ตง, เหลียงชิง อู๋, ฉางหลง ซุน, โชวชาน ลี, เฉียวหมิง จู และกัวตง โจว "การสร้างแบบจำลองทั้งการพึ่งพาบริบทและไวต่อผู้พูดสำหรับการตรวจจับอารมณ์ในการสนทนาแบบหลายลำโพง" ไอเจซีเอ 2019.
โกซาล, ดีปันเวย์, นาโวนิล มาจุมเดอร์, สุจันยา โปเรีย, นิยาติ ชายา และอเล็กซานเดอร์ เกลบุคห์ "DialogueGCN: โครงข่ายประสาทเทียมแบบกราฟสำหรับการรับรู้อารมณ์ในการสนทนา" EMLP 2019.
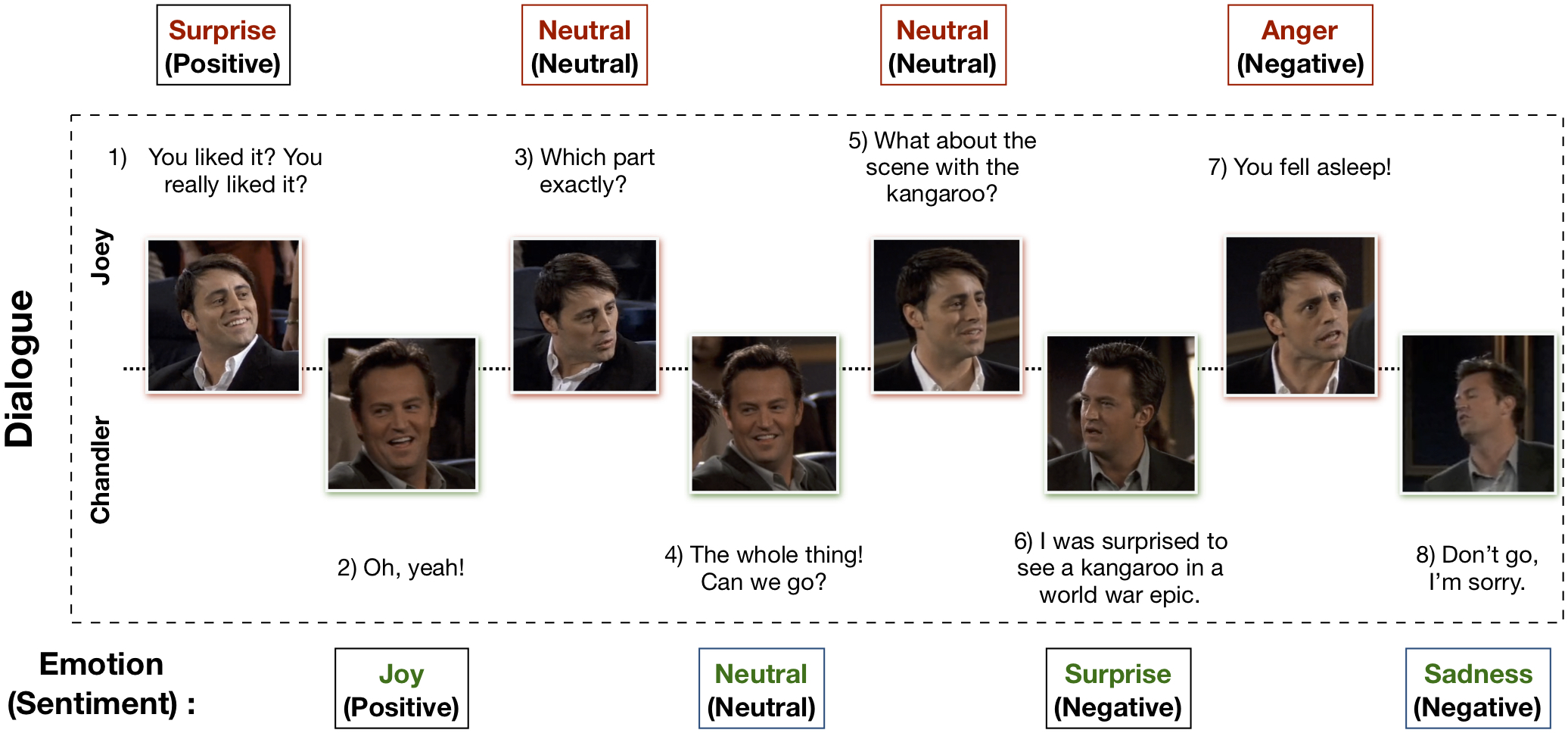
ชุดข้อมูล Multimodal EmotionLines (MELD) ได้รับการสร้างขึ้นโดยการปรับปรุงและขยายชุดข้อมูล EmotionLines MELD มีอินสแตนซ์บทสนทนาเดียวกันกับที่มีอยู่ใน EmotionLines แต่ยังรวมเอารูปแบบเสียงและภาพพร้อมกับข้อความไว้ด้วย MELD มีบทสนทนามากกว่า 1,400 รายการและคำพูด 13,000 รายการจากซีรีส์ Friends TV วิทยากรหลายคนเข้าร่วมในการสนทนา คำพูดแต่ละครั้งในบทสนทนาจะถูกระบุด้วยอารมณ์ทั้งเจ็ดนี้ ได้แก่ ความโกรธ ความรังเกียจ ความโศกเศร้า ความยินดี ความเป็นกลาง ความประหลาดใจ และความกลัว MELD ยังมีคำอธิบายประกอบเกี่ยวกับความรู้สึก (เชิงบวก ลบ และเป็นกลาง) สำหรับคำพูดแต่ละรายการ
| สถิติ | รถไฟ | นักพัฒนา | ทดสอบ |
|---|---|---|---|
| #ของกิริยา | {ก,วี,ที} | {ก,วี,ที} | {ก,วี,ที} |
| #คำที่ไม่ซ้ำใคร | 10,643 | 2,384 | 4,361 |
| เฉลี่ย ความยาวคำพูด | 8.03 | 7.99 | 8.28 |
| สูงสุด ความยาวคำพูด | 69 | 37 | 45 |
| เฉลี่ย #อารมณ์ต่อบทสนทนา | 3.30 | 3.35 | 3.24 |
| #ของบทสนทนา | 1,039 | 114 | 280 |
| #คำพูด | 9989 | 1109 | 2610 |
| #ของวิทยากร | 260 | 47 | 100 |
| #การเปลี่ยนแปลงทางอารมณ์ | 4003 | 427 | 1003 |
| เฉลี่ย ระยะเวลาของคำพูด | 3.59วิ | 3.59วิ | 3.58วิ |
กรุณาเยี่ยมชม https://affective-meld.github.io สำหรับรายละเอียดเพิ่มเติม
| รถไฟ | นักพัฒนา | ทดสอบ | |
|---|---|---|---|
| ความโกรธ | 1109 | 153 | 345 |
| รังเกียจ | 271 | 22 | 68 |
| กลัว | 268 | 40 | 50 |
| จอย | 1743 | 163 | 402 |
| เป็นกลาง | 4710 | 470 | 1256 |
| ความโศกเศร้า | 683 | 111 | 208 |
| เซอร์ไพรส์ | 1205 | 150 | 281 |
การวิเคราะห์ข้อมูลหลายรูปแบบใช้ประโยชน์จากข้อมูลจากช่องทางข้อมูลหลายช่องทางเพื่อการตัดสินใจ ด้วยการเติบโตอย่างรวดเร็วของ AI การจดจำอารมณ์หลายรูปแบบจึงได้รับความสนใจในการวิจัยที่สำคัญ โดยมีสาเหตุหลักมาจากการประยุกต์ใช้ที่มีศักยภาพในงานที่ท้าทายมากมาย เช่น การสร้างบทสนทนา การโต้ตอบหลายรูปแบบ เป็นต้น ระบบการจดจำอารมณ์ของการสนทนาสามารถใช้เพื่อสร้างการตอบสนองที่เหมาะสมโดย วิเคราะห์อารมณ์ของผู้ใช้ แม้ว่าจะมีงานมากมายที่เกี่ยวข้องกับการรับรู้อารมณ์หลายรูปแบบ แต่มีเพียงไม่กี่งานเท่านั้นที่เน้นการทำความเข้าใจอารมณ์ในการสนทนา อย่างไรก็ตาม งานของพวกเขาจำกัดอยู่เพียงความเข้าใจในการสนทนาแบบไดอะดิคเท่านั้น ดังนั้นจึงไม่สามารถปรับขนาดให้รองรับการจดจำอารมณ์ในการสนทนาหลายฝ่ายที่มีผู้เข้าร่วมมากกว่าสองคนได้ EmotionLines สามารถใช้เป็นแหล่งข้อมูลสำหรับการจดจำอารมณ์สำหรับข้อความเท่านั้น เนื่องจากไม่รวมข้อมูลจากรูปแบบอื่น เช่น ภาพและเสียง ในเวลาเดียวกัน ควรสังเกตว่าไม่มีชุดข้อมูลการสนทนาหลายฝ่ายหลายรูปแบบสำหรับการวิจัยการจดจำอารมณ์ ในงานนี้ เราได้ขยาย ปรับปรุง และพัฒนาชุดข้อมูล EmotionLines เพิ่มเติมสำหรับสถานการณ์หลายรูปแบบ การจดจำอารมณ์ในการเลี้ยวตามลำดับมีความท้าทายหลายประการ และการทำความเข้าใจบริบทก็เป็นหนึ่งในนั้น การเปลี่ยนแปลงอารมณ์และการไหลของอารมณ์ตามลำดับการผลัดกันในบทสนทนาทำให้การสร้างแบบจำลองบริบทที่ถูกต้องเป็นงานที่ยาก ในชุดข้อมูลนี้ เนื่องจากเราสามารถเข้าถึงแหล่งข้อมูลหลายรูปแบบสำหรับแต่ละบทสนทนา เราจึงตั้งสมมติฐานว่าจะปรับปรุงการสร้างแบบจำลองบริบท ซึ่งจะเป็นประโยชน์ต่อประสิทธิภาพการรับรู้อารมณ์โดยรวม ชุดข้อมูลนี้ยังสามารถใช้เพื่อพัฒนาระบบการสนทนาทางอารมณ์แบบต่อเนื่องหลายรูปแบบได้ IEMOCAP, SEMAINE เป็นชุดข้อมูลการสนทนาหลายรูปแบบซึ่งมีป้ายกำกับอารมณ์สำหรับคำพูดแต่ละรายการ อย่างไรก็ตาม ชุดข้อมูลเหล่านี้มีลักษณะเป็นแบบไดนามิก ซึ่งแสดงให้เห็นถึงความสำคัญของชุดข้อมูล Multimodal-EmotionLines ของเรา ชุดข้อมูลการรับรู้อารมณ์และความรู้สึกแบบต่อเนื่องหลายรูปแบบที่เปิดเผยต่อสาธารณะอื่นๆ ได้แก่ MOSEI, MOSI, MOUD อย่างไรก็ตาม ไม่มีชุดข้อมูลใดที่สามารถสนทนาได้
ขั้นตอนแรกเกี่ยวข้องกับการค้นหาการประทับเวลาของทุกคำพูดในแต่ละบทสนทนาที่มีอยู่ในชุดข้อมูล EmotionLines เพื่อให้บรรลุเป้าหมายนี้ เราได้รวบรวมข้อมูลในไฟล์คำบรรยายของตอนทั้งหมดซึ่งมีการประทับเวลาเริ่มต้นและสิ้นสุดของคำพูด กระบวนการนี้ทำให้เราได้รับรหัสซีซัน รหัสตอน และการประทับเวลาของคำพูดแต่ละรายการในตอนนั้น เราใส่ข้อจำกัดสองประการในขณะที่รับการประทับเวลา: (ก) การประทับเวลาของคำพูดในบทสนทนาจะต้องเรียงลำดับเพิ่มขึ้น (ข) คำพูดทั้งหมดในบทสนทนาต้องเป็นของตอนและฉากเดียวกัน เมื่อจำกัดด้วยเงื่อนไขทั้งสองนี้ เผยให้เห็นว่าใน EmotionLines บทสนทนาบางส่วนประกอบด้วยบทสนทนาที่เป็นธรรมชาติหลายบท เรากรองกรณีเหล่านั้นออกจากชุดข้อมูล เนื่องจากขั้นตอนการแก้ไขข้อผิดพลาดนี้ ในกรณีของเรา เรามีบทสนทนาที่แตกต่างกันเมื่อเปรียบเทียบกับ EmotionLines หลังจากได้รับการประทับเวลาของคำพูดแต่ละรายการแล้ว เราก็แยกคลิปภาพและเสียงที่เกี่ยวข้องออกจากตอนต้นทาง นอกจากนี้ เรายังนำเนื้อหาเสียงออกจากคลิปวิดีโอเหล่านั้นด้วย สุดท้าย ชุดข้อมูลประกอบด้วยภาพ เสียง และข้อความสำหรับแต่ละบทสนทนา
บทความอธิบายชุดข้อมูลนี้สามารถพบได้ - https://arxiv.org/pdf/1810.02508.pdf
โปรดไปที่ - http://web.eecs.umich.edu/~mihalcea/downloads/MELD.Raw.tar.gz เพื่อดาวน์โหลดข้อมูลดิบ ข้อมูลจะถูกจัดเก็บในรูปแบบ .mp4 และสามารถพบได้ในไฟล์ XXX.tar.gz คำอธิบายประกอบสามารถพบได้ในhttps://github.com/declare-lab/MELD/tree/master/data/MELD
| ชื่อคอลัมน์ | คำอธิบาย |
|---|---|
| หมายเลขอาวุโส | หมายเลขซีเรียลของคำพูดเป็นหลักสำหรับอ้างอิงคำพูดในกรณีที่มีเวอร์ชันต่างกันหรือหลายสำเนาที่มีชุดย่อยต่างกัน |
| คำพูด | คำพูดส่วนบุคคลจาก EmotionLines เป็นสตริง |
| วิทยากร | ชื่อผู้พูดที่เกี่ยวข้องกับคำพูด |
| อารมณ์ | อารมณ์ (เป็นกลาง ความสุข ความเศร้า ความโกรธ ความประหลาดใจ ความกลัว ความรังเกียจ) ที่ผู้พูดแสดงออกในคำพูด |
| ความรู้สึก | ความรู้สึก (เชิงบวก เป็นกลาง ลบ) ที่แสดงโดยผู้พูดในคำพูด |
| Dialogue_ID | ดัชนีของบทสนทนาเริ่มต้นจาก 0 |
| คำพูด_ID | ดัชนีของคำพูดเฉพาะในบทสนทนาเริ่มต้นจาก 0 |
| ฤดูกาล | ฤดูกาลที่ ของรายการทีวี Friends ที่มีคำพูดเฉพาะอยู่ |
| ตอน | ตอนที่ # ของรายการทีวี Friends ในฤดูกาลใดฤดูกาลหนึ่งซึ่งมีคำพูดนั้นอยู่ด้วย |
| เวลาเริ่มต้น | เวลาเริ่มต้นของคำพูดในตอนที่กำหนดในรูปแบบ 'hh:mm:ss,ms' |
| เวลาสิ้นสุด | เวลาสิ้นสุดของคำพูดในตอนที่กำหนดในรูปแบบ 'hh:mm:ss,ms' |
มีไฟล์ดอง 13 ไฟล์ที่ประกอบด้วยข้อมูลและฟีเจอร์ที่ใช้สำหรับการฝึกโมเดลพื้นฐาน ต่อไปนี้เป็นคำอธิบายโดยย่อของไฟล์ดองแต่ละไฟล์
import pickle
data , W , vocab , word_idx_map , max_sentence_length , label_index = pickle . load ( open ( filepath , 'rb' )) import pickle
train_text_avg_emb , val_text_avg_emb , test_text_avg_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_audio_emb , val_audio_emb , test_audio_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_text_CNN_emb , val_text_CNN_emb , test_text_CNN_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_text_emb , val_text_emb , test_text_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_audio_emb , val_audio_emb , test_audio_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_bimodal_emb , val_bimodal_emb , test_bimodal_emb = pickle . load ( open ( filepath , 'rb' ))มีสคริปต์หลาม 2 ตัวที่ให้ไว้ใน './utils/':
สำหรับการทดลอง ป้ายกำกับทั้งหมดจะแสดงเป็นการเข้ารหัสแบบร้อนแรงเดียว ซึ่งมีดัชนีดังต่อไปนี้:
สำหรับพื้นฐานในการจำแนกอารมณ์ จะใช้น้ำหนักของชั้นเรียนดังต่อไปนี้ การจัดทำดัชนีจะเหมือนกับที่กล่าวไว้ข้างต้น น้ำหนักชั้นเรียน: [4.0, 15.0, 15.0, 3.0, 1.0, 6.0, 3.0]
โปรดทำตามขั้นตอนเหล่านี้เพื่อดำเนินการพื้นฐาน -
./data/pickles/baseline/baseline.py ดังนี้:python baseline.py -classify [Sentiment|Emotion] -modality [text|audio|bimodal] [-train|-test]python baseline.py -classify Sentiment -modality text -trainpython baseline.py -h เพื่อรับข้อความช่วยเหลือสำหรับพารามิเตอร์./data/models/ / โปรดอ้างอิงเอกสารต่อไปนี้หากคุณพบว่าชุดข้อมูลนี้มีประโยชน์ในการวิจัยของคุณ
เอส. โพเรีย, ดี. ฮาซาริกา, เอ็น. มาจุมเดอร์, จี. ไนค์, อี. แคมเบรีย, ร. มิฮาลเซีย MELD: ชุดข้อมูลหลายฝ่ายหลายรูปแบบสำหรับการรับรู้อารมณ์ในการสนทนา เอซีแอล 2019.
Chen, SY, Hsu, CC, Kuo, CC และ Ku, LW EmotionLines: คลังข้อมูลอารมณ์ของการสนทนาหลายฝ่าย arXiv พิมพ์ล่วงหน้า arXiv:1802.08379 (2018)
ชุดข้อมูล EmoryNLP Emotion Detection หลายรูปแบบถูกสร้างขึ้นโดยการปรับปรุงและขยายชุดข้อมูล EmoryNLP Emotion Detection ประกอบด้วยอินสแตนซ์บทสนทนาเดียวกันกับที่มีอยู่ในชุดข้อมูล EmoryNLP Emotion Detection แต่ยังรวมถึงรูปแบบเสียงและภาพพร้อมกับข้อความด้วย มีบทสนทนามากกว่า 800 รายการและคำพูด 9,000 รายการจากซีรีส์ Friends TV อยู่ในชุดข้อมูล EmoryNLP แบบต่อเนื่องหลายรูปแบบ วิทยากรหลายคนเข้าร่วมในการสนทนา คำพูดแต่ละคำในบทสนทนาถูกระบุด้วยอารมณ์ทั้ง 7 อารมณ์เหล่านี้ ได้แก่ เป็นกลาง ร่าเริง สงบ มีพลัง หวาดกลัว โกรธ และเศร้า คำอธิบายประกอบถูกยืมมาจากชุดข้อมูลดั้งเดิม
| สถิติ | รถไฟ | นักพัฒนา | ทดสอบ |
|---|---|---|---|
| #ของกิริยา | {ก,วี,ที} | {ก,วี,ที} | {ก,วี,ที} |
| #คำที่ไม่ซ้ำใคร | 9,744 | 2,123 | 2,345 |
| เฉลี่ย ความยาวคำพูด | 7.86 | 6.97 | 7.79 |
| สูงสุด ความยาวคำพูด | 78 | 60 | 61 |
| เฉลี่ย #ความรู้สึกต่อฉาก | 4.10 | 4.00 น | 4.40 |
| #ของบทสนทนา | 659 | 89 | 79 |
| #คำพูด | 7551 | 954 | 984 |
| #ของวิทยากร | 250 | 46 | 48 |
| #การเปลี่ยนแปลงทางอารมณ์ | 4596 | 575 | 653 |
| เฉลี่ย ระยะเวลาของคำพูด | 5.55วิ | 5.46วิ | 5.27วิ |
| รถไฟ | นักพัฒนา | ทดสอบ | |
|---|---|---|---|
| สนุกสนาน | 1677 | 205 | 217 |
| โกรธ | 785 | 97 | 86 |
| เป็นกลาง | 2485 | 322 | 288 |
| สงบ | 638 | 82 | 111 |
| ทรงพลัง | 551 | 70 | 96 |
| เศร้า | 474 | 51 | 70 |
| กลัว | 941 | 127 | 116 |
คลิปวิดีโอของชุดข้อมูลนี้สามารถดาวน์โหลดได้จากลิงค์นี้ ไฟล์คำอธิบายประกอบสามารถพบได้ใน https://github.com/SenticNet/MELD/tree/master/data/emorynlp มีไฟล์ .csv จำนวน 3 ไฟล์ แต่ละรายการในคอลัมน์แรกของไฟล์ CSV เหล่านี้ประกอบด้วยคำพูด ซึ่งสามารถดูคลิปวิดีโอที่เกี่ยวข้องได้ที่นี่ คำพูดและคลิปวิดีโอแต่ละรายการจะถูกจัดทำดัชนีตามหมายเลขซีซัน หมายเลขตอน รหัสฉาก และรหัสคำพูด ตัวอย่างเช่น sea1_ep2_sc6_utt3.mp4 บอกเป็นนัยว่าคลิปสอดคล้องกับคำพูดของซีซันที่ ตอนที่ 1 ตอนที่ 1 2, scene_id 6 และ utterance_id 3 ฉากเป็นเพียงบทสนทนา การจัดทำดัชนีนี้สอดคล้องกับชุดข้อมูลดั้งเดิม ไฟล์ .csv และไฟล์วิดีโอแบ่งออกเป็นชุดฝึก การตรวจสอบ และชุดทดสอบตามชุดข้อมูลต้นฉบับ คำอธิบายประกอบได้รับการยืมโดยตรงจากชุดข้อมูล EmoryNLP ดั้งเดิม (Zahiri et al. (2018))
| ชื่อคอลัมน์ | คำอธิบาย |
|---|---|
| คำพูด | คำพูดส่วนบุคคลจาก EmoryNLP ในรูปแบบสตริง |
| วิทยากร | ชื่อผู้พูดที่เกี่ยวข้องกับคำพูด |
| อารมณ์ | อารมณ์ (เป็นกลาง สนุกสนาน สงบ มีพลัง หวาดกลัว โกรธ และเศร้า) ที่ผู้พูดแสดงออกในคำพูด |
| ฉาก_ID | ดัชนีของบทสนทนาเริ่มต้นจาก 0 |
| คำพูด_ID | ดัชนีของคำพูดเฉพาะในบทสนทนาเริ่มต้นจาก 0 |
| ฤดูกาล | ฤดูกาลที่ ของรายการทีวี Friends ที่มีคำพูดเฉพาะอยู่ |
| ตอน | ตอนที่ # ของรายการทีวี Friends ในฤดูกาลใดฤดูกาลหนึ่งซึ่งมีคำพูดนั้นอยู่ด้วย |
| เวลาเริ่มต้น | เวลาเริ่มต้นของคำพูดในตอนที่กำหนดในรูปแบบ 'hh:mm:ss,ms' |
| เวลาสิ้นสุด | เวลาสิ้นสุดของคำพูดในตอนที่กำหนดในรูปแบบ 'hh:mm:ss,ms' |
หมายเหตุ : มีคำพูดบางส่วนที่เราไม่สามารถค้นหาเวลาเริ่มต้นและเวลาสิ้นสุดได้เนื่องจากคำบรรยายไม่สอดคล้องกัน คำพูดดังกล่าวถูกละเว้นจากชุดข้อมูล อย่างไรก็ตาม เราขอแนะนำให้ผู้ใช้ค้นหาคำพูดที่เกี่ยวข้องจากชุดข้อมูลต้นฉบับ และสร้างคลิปวิดีโอสำหรับสิ่งเดียวกัน
โปรดอ้างอิงเอกสารต่อไปนี้หากคุณพบว่าชุดข้อมูลนี้มีประโยชน์ในการวิจัยของคุณ
เอส. ซาฮิรี และ เจดี ชอย. การตรวจจับอารมณ์ในการถอดเสียงรายการทีวีด้วยโครงข่ายประสาทเทียมแบบเรียงลำดับ ในการประชุมเชิงปฏิบัติการ AAAI เรื่องการวิเคราะห์เนื้อหาเชิงอารมณ์ AFFCON'18 ปี 2018
เอส. โพเรีย, ดี. ฮาซาริกา, เอ็น. มาจุมเดอร์, จี. ไนค์, อี. แคมเบรีย, ร. มิฮาลเซีย MELD: ชุดข้อมูลหลายฝ่ายหลายรูปแบบสำหรับการรับรู้อารมณ์ในการสนทนา เอซีแอล 2019.


