ChatLearner
1.0.0
แชทบอทที่ใช้งานใน TensorFlow อิงตามโมเดลลำดับต่อลำดับ (NMT) ใหม่ โดยมีกฎบางอย่างที่ผสานรวมได้อย่างราบรื่น
สำหรับผู้ที่สนใจแชทบอทภาษาจีน กรุณาตรวจสอบที่นี่
แกนหลักของ ChatLearner (Papaya) สร้างขึ้นจากโมเดล NMT (https://github.com/tensorflow/nmt) ซึ่งได้รับการดัดแปลงที่นี่เพื่อให้เหมาะกับความต้องการของแชทบอท เนื่องจากการเปลี่ยนแปลงที่เกิดขึ้นกับ tf.data API ใน TensorFlow 1.4 และการเปลี่ยนแปลงอื่นๆ อีกมากมายตั้งแต่ TensorFlow 1.12 ChatLearner เวอร์ชันนี้จึงรองรับเฉพาะ TF เวอร์ชัน 1.4 ถึง 1.11 เท่านั้น คุณสามารถอัปเดตอย่างง่ายดายในไฟล์ tokenizeddata.py หากคุณต้องการรองรับ TensorFlow 1.12
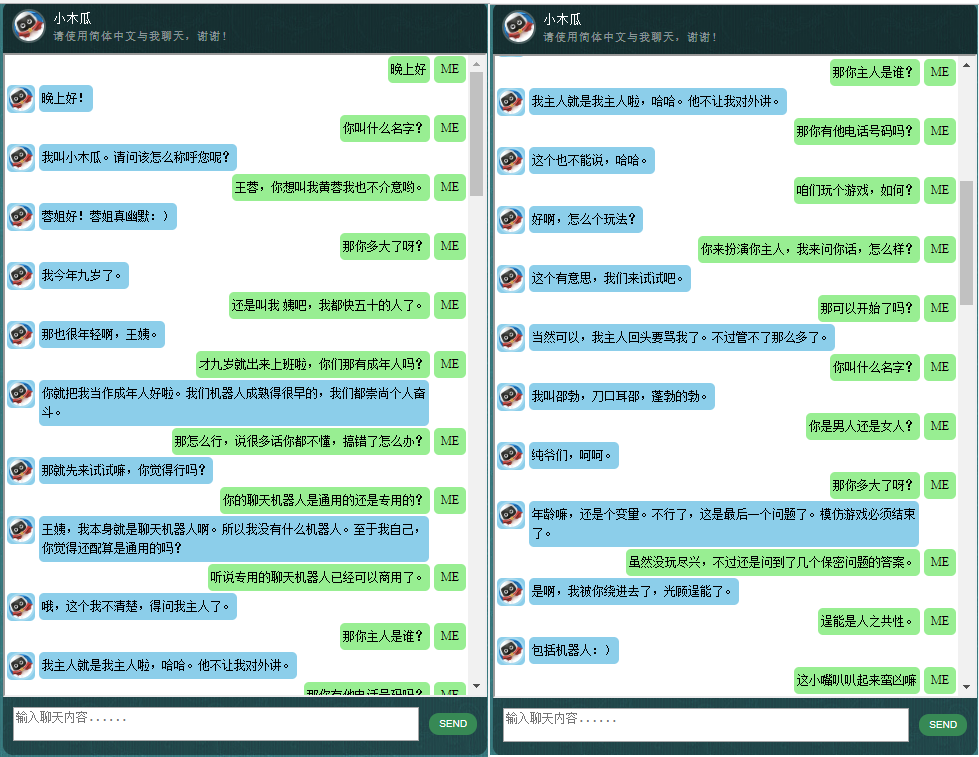
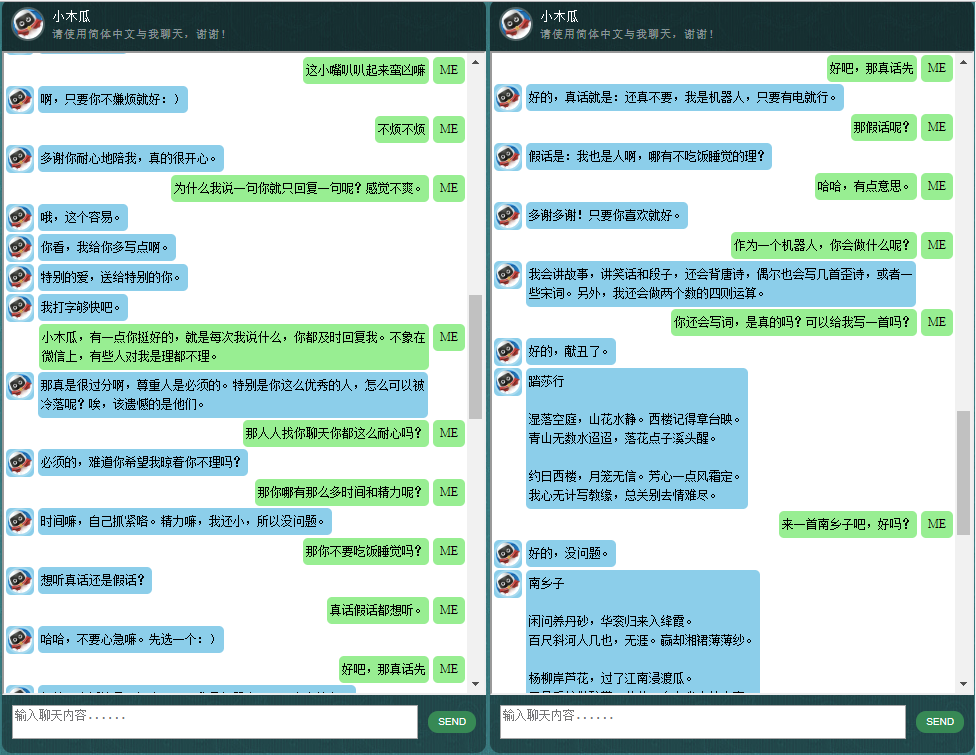
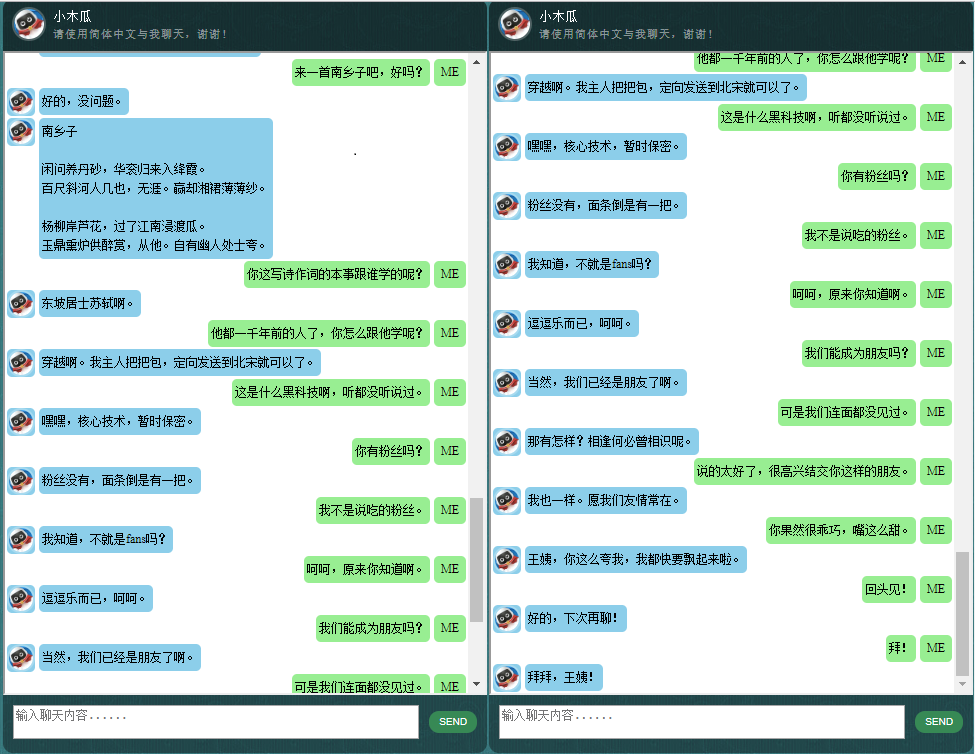
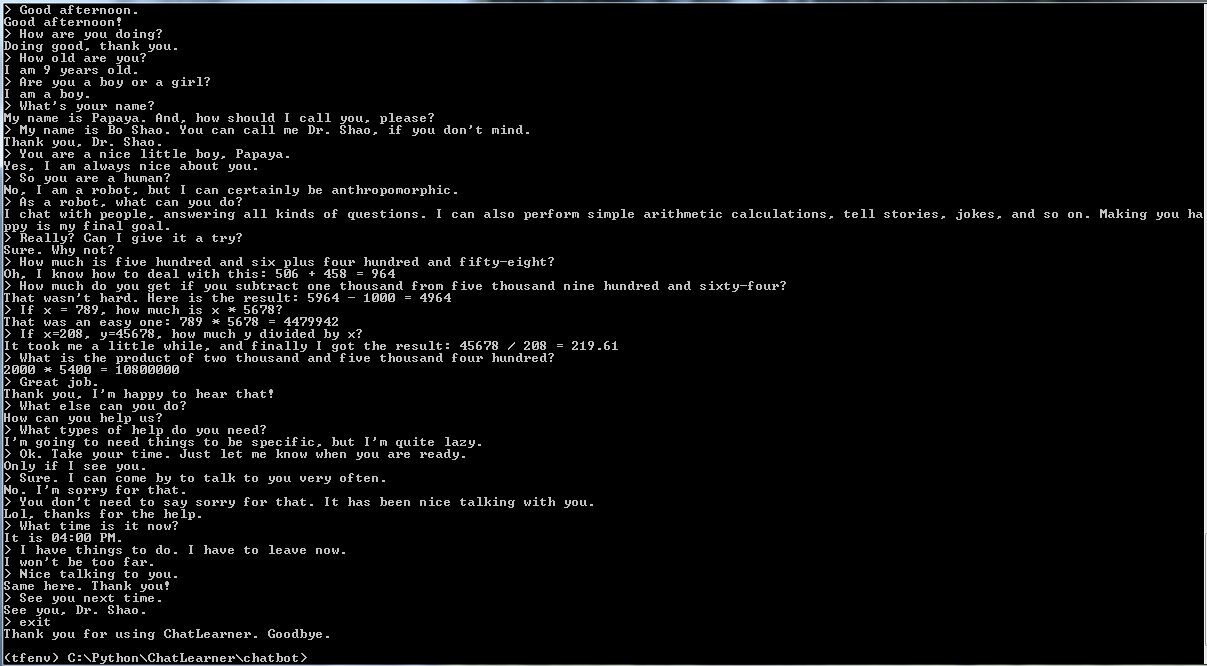
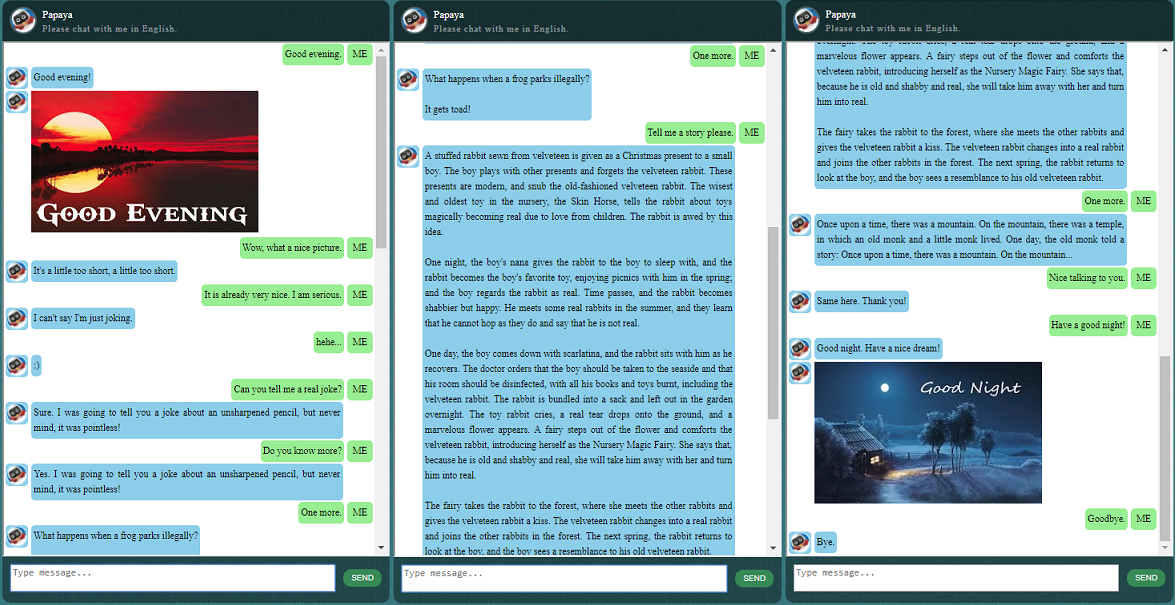
ก่อนที่จะเริ่มทำอย่างอื่น คุณอาจต้องการทำความเข้าใจว่า ChatLearner มีพฤติกรรมอย่างไร ดูตัวอย่างการสนทนาด้านล่างหรือที่นี่ หรือหากคุณต้องการลองใช้โมเดลที่ผ่านการฝึกอบรมของฉัน ดาวน์โหลดได้ที่นี่ แตกไฟล์ .rar ที่ดาวน์โหลดมา และคัดลอกโฟลเดอร์ Result ลงในโฟลเดอร์ Data ใต้รูทโปรเจ็กต์ของคุณ ไฟล์ vocab.txt รวมอยู่ด้วย ในกรณีที่ฉันอัปเดตโดยไม่อัปเดตโมเดลที่ผ่านการฝึกอบรมในอนาคต
เหตุใดคุณจึงต้องการใช้เวลาตรวจสอบพื้นที่เก็บข้อมูลนี้ ต่อไปนี้คือสาเหตุที่เป็นไปได้บางประการ:
ชุดข้อมูลมะละกอสำหรับฝึกแชทบอท คุณสามารถหาข้อมูลการฝึกอบรมมากมายทางออนไลน์ได้อย่างง่ายดาย แต่คุณไม่สามารถหาข้อมูลที่มีคุณภาพสูงเช่นนี้ได้ ดูคำอธิบายโดยละเอียดเกี่ยวกับชุดข้อมูลด้านล่าง
รูปแบบโค้ดที่กระชับและการใช้งานโมเดล seq2seq ใหม่ที่ชัดเจนโดยอิงตาม RNN แบบไดนามิก (หรือที่เรียกว่าโมเดล NMT ใหม่) มันถูกปรับแต่งสำหรับแชทบอทและเข้าใจง่ายกว่ามากเมื่อเทียบกับบทช่วยสอนอย่างเป็นทางการ
แนวคิดในการใช้ ChatSession ที่ผสานรวมอย่างลงตัวเพื่อจัดการบริบทการสนทนาขั้นพื้นฐาน
กฎบางข้อได้รับการบูรณาการเพื่อสาธิตวิธีการรวมแชทบอทตามกฎแบบดั้งเดิมเข้ากับโมเดลการเรียนรู้เชิงลึกใหม่ ไม่ว่าโมเดลการเรียนรู้เชิงลึกจะทรงพลังเพียงใด ก็ไม่สามารถตอบคำถามที่ต้องใช้การคำนวณทางคณิตศาสตร์อย่างง่าย และอื่นๆ อีกมากมายด้วยซ้ำ แนวทางที่แสดงไว้นี้สามารถนำไปปรับใช้เพื่อรับข่าวสารหรือข้อมูลออนไลน์อื่นๆ ได้อย่างง่ายดาย เมื่อใช้กฎเกณฑ์แล้ว ก็สามารถตอบคำถามที่น่าสนใจมากมายได้อย่างเหมาะสม ตัวอย่างเช่น:
หากคุณไม่สนใจกฎ คุณสามารถลบบรรทัดที่เกี่ยวข้องกับ Knowledgebase.py และ functiondata.py ได้อย่างง่ายดาย
บริการเว็บที่ใช้ SOAP (และทางเลือกอื่นที่ใช้ REST-API หากคุณไม่ต้องการใช้ SOAP) ช่วยให้คุณสามารถนำเสนอ GUI ใน Java ในขณะที่โมเดลได้รับการฝึกฝนและทำงานใน Python และ TensorFlow
วิธีแก้ปัญหาง่ายๆ (ในกราฟ) ในการแปลงสตริงเทนเซอร์เป็นตัวพิมพ์เล็กใน TensorFlow จำเป็นหากคุณใช้ DataSet API ใหม่ (tf.data.TextLineDataSet) ใน TensorFlow เพื่อโหลดข้อมูลการฝึกจากไฟล์ข้อความ
พื้นที่เก็บข้อมูลยังมีการใช้งานแชทบอตตามโมเดล seq2seq ดั้งเดิม ในกรณีที่คุณสนใจ โปรดตรวจสอบสาขา Legacy_Chatbot ที่ https://github.com/bshao001/ChatLearner/tree/Legacy_Chatbot
ชุดข้อมูลมะละกอเป็นข้อมูลการสนทนาภาษาอังกฤษฟรีที่ดีที่สุด (สะอาดที่สุดและมีการจัดระเบียบอย่างดี) ที่คุณสามารถหาได้บนเว็บเพื่อฝึกแชทบอท นี่คือรายละเอียดบางส่วน:
ข้อมูลประกอบด้วยสองชุด ชุดแรกทำด้วยมือ และเราสร้างตัวอย่างเพื่อรักษาบทบาทที่สอดคล้องกันของแชทบอท ซึ่งสามารถฝึกให้มีความสุภาพ อดทน มีอารมณ์ขัน มีปรัชญา และตระหนักว่าเขาเป็น หุ่นยนต์แต่แกล้งเป็นเด็กอายุ 9 ขวบชื่อปาปาย่า ชุดที่สองได้รับการทำความสะอาดจากแหล่งข้อมูลออนไลน์บางส่วน รวมถึงบทสนทนาสถานการณ์ที่ออกแบบมาสำหรับการฝึกหุ่นยนต์ กล่องโต้ตอบภาพยนตร์ Cornell และการทำความสะอาดข้อมูล Reddit
ชุดข้อมูลการฝึกอบรมแบ่งออกเป็นสามประเภท: สองชุดย่อยจะถูกเพิ่ม/ทำซ้ำในระหว่างการฝึกอบรม โดยมีระดับหรือเวลาที่แตกต่างกัน ในขณะที่ชุดที่สามจะไม่ ชุดย่อยเสริมมีไว้เพื่อฝึกโมเดลด้วยกฎที่ต้องปฏิบัติตาม และความรู้และสามัญสำนึกบางอย่าง ในขณะที่ชุดย่อยที่สามมีไว้เพื่อช่วยฝึกโมเดลภาษาเท่านั้น
บทสนทนาเกี่ยวกับสถานการณ์ได้รับการแยกและจัดระเบียบใหม่จาก http://www.eslfast.com/robot/ หากแบบจำลองของคุณสามารถรองรับบริบทได้ มันจะทำงานได้ดีขึ้นมากโดยการใช้การสนทนาเหล่านี้
สามารถดูชุดข้อมูล Cornell ดั้งเดิมได้ที่นี่ เราทำความสะอาดโดยใช้สคริปต์ Python (สามารถพบได้ในโฟลเดอร์ Corpus) จากนั้นเราก็ทำความสะอาดด้วยตนเองโดยค้นหารูปแบบบางอย่างอย่างรวดเร็ว
สำหรับข้อมูล Reddit ชุดย่อยที่ล้างแล้ว (ประมาณ 110,000 คู่) จะรวมอยู่ในที่เก็บนี้ ไฟล์คำศัพท์และพารามิเตอร์โมเดลถูกสร้างและปรับแต่งตามไฟล์ข้อมูลทั้งหมดที่รวมอยู่ ในกรณีที่คุณต้องการชุดที่ใหญ่กว่า คุณยังสามารถค้นหาสคริปต์เพื่อแยกวิเคราะห์และล้างความคิดเห็น Reddit ในโฟลเดอร์ Corpus/RedditData ได้ ในการใช้สคริปต์เหล่านั้น คุณจะต้องดาวน์โหลดความคิดเห็น Reddit ทอร์เรนต์จากลิงก์ทอร์เรนต์ที่นี่ โดยปกติแล้ว ความคิดเห็นหนึ่งเดือนก็เพียงพอแล้ว (สามารถสร้างตัวอย่างการฝึกอบรม 3 ล้านคู่โดยประมาณได้) คุณสามารถปรับแต่งพารามิเตอร์ในสคริปต์ได้ตามความต้องการของคุณ
ไฟล์ข้อมูลในชุดข้อมูลนี้ได้รับการประมวลผลล่วงหน้าด้วยโทเค็น NLTK แล้ว เพื่อให้พร้อมที่จะป้อนเข้าสู่โมเดลโดยใช้ tf.data API ใหม่ใน TensorFlow
โปรดตรวจสอบให้แน่ใจว่าคุณมีเวอร์ชัน TensorFlow ที่ถูกต้อง ใช้งานได้กับ TensorFlow 1.4 เท่านั้น ไม่ใช่รุ่นก่อนหน้าใดๆ เนื่องจาก tf.data API ที่ใช้ที่นี่ได้รับการอัปเดตใหม่ใน TF 1.4
โปรดตรวจสอบให้แน่ใจว่าคุณมีการตั้งค่า PYTHONPATH ตัวแปรสภาพแวดล้อม โดยจะต้องชี้ไปที่ไดเร็กทอรีรากของโปรเจ็กต์ ซึ่งคุณมีโฟลเดอร์ chatbot, Data และ webui หากคุณใช้งาน IDE เช่น PyCharm มันจะสร้างสิ่งนั้นให้คุณ แต่ถ้าคุณเรียกใช้สคริปต์ Python ในบรรทัดคำสั่ง คุณจะต้องมีตัวแปรสภาพแวดล้อมนั้น ไม่เช่นนั้น คุณจะได้รับข้อผิดพลาดในการนำเข้าโมดูล
โปรดตรวจสอบให้แน่ใจว่าคุณใช้ไฟล์ vocab.txt เดียวกันสำหรับทั้งการฝึกและการอนุมาน/การทำนาย โปรดทราบว่าแบบจำลองของคุณจะไม่เห็นคำใดๆ เหมือนกับที่เราเห็น มันคือจำนวนเต็มเข้าและจำนวนเต็มออก ในขณะที่คำและลำดับของคำใน vocab.txt ช่วยจับคู่ระหว่างคำกับจำนวนเต็ม
ใช้เวลาสักหน่อยโดยคิดว่าโมเดลของคุณควรมีขนาดใหญ่แค่ไหน ความยาวสูงสุดของตัวเข้ารหัส/ตัวถอดรหัสควรเป็นเท่าใด ขนาดของชุดคำศัพท์ และจำนวนคู่ของข้อมูลการฝึกที่คุณต้องการใช้ โปรดทราบว่าแบบจำลองมีขีดจำกัดความจุ: สามารถเรียนรู้หรือจดจำข้อมูลได้มากเพียงใด เมื่อคุณมีจำนวนเลเยอร์ จำนวนหน่วย ประเภทของเซลล์ RNN (เช่น GRU) คงที่ และคุณตัดสินใจเกี่ยวกับความยาวของตัวเข้ารหัส/ตัวถอดรหัส ขนาดคำศัพท์ส่วนใหญ่จะส่งผลต่อความสามารถในการเรียนรู้ของโมเดลของคุณ ไม่ใช่จำนวน ตัวอย่างการฝึกอบรม หากคุณไม่สามารถจัดการไม่ให้ขนาดคำศัพท์เพิ่มขึ้นเมื่อคุณใช้ข้อมูลการฝึกอบรมมากขึ้น มันอาจจะได้ผล แต่ความจริงก็คือเมื่อคุณมีตัวอย่างการฝึกอบรมมากขึ้น ขนาดคำศัพท์ก็จะเพิ่มขึ้นอย่างรวดเร็วเช่นกัน และคุณอาจสังเกตเห็น โมเดลของคุณไม่สามารถรองรับข้อมูลขนาดนั้นได้เลย อย่าลังเลที่จะเปิดประเด็นเพื่อหารือหากคุณต้องการ
นอกเหนือจาก Python 3.6 (3.5 ควรใช้งานได้เช่นกัน), Numpy และ TensorFlow 1.4 คุณต้องมี NLTK (ชุดเครื่องมือภาษาธรรมชาติ) เวอร์ชัน 3.2.4 (หรือ 3.2.5)
ในระหว่างการฝึก ฉันขอแนะนำให้คุณลองเล่นกับพารามิเตอร์ (colocate_gradients_with_ops) ในฟังก์ชัน tf.gradients คุณสามารถค้นหาบรรทัดเช่นนี้ได้ใน modelcreator.py: การไล่ระดับสี = tf.gradients(self.train_loss, params) ตั้งค่า colocate_gradients_with_ops=True (เพิ่มเข้าไป) และดำเนินการฝึกอบรมอย่างน้อยหนึ่งยุค จดบันทึกเวลา จากนั้นตั้งค่าเป็นเท็จ (หรือเพียงแค่ลบออก) และดำเนินการฝึกอบรมอย่างน้อยหนึ่งยุคและดูว่าต้องใช้เวลาหรือไม่ สำหรับยุคหนึ่งมีความแตกต่างกันอย่างมาก อย่างน้อยมันก็ทำให้ฉันตกใจ
นอกเหนือจากนั้น การฝึกอบรมก็ตรงไปตรงมา อย่าลืมสร้างโฟลเดอร์ชื่อ Result ใต้โฟลเดอร์ Data ก่อน จากนั้นเพียงรันคำสั่งต่อไปนี้:
cd chatbot
python bottrainer.pyแนะนำให้ใช้ GPU ที่ดีสำหรับการฝึกอบรมเนื่องจากอาจใช้เวลานานมาก หากคุณมี GPU หลายตัว TensorFlow จะใช้งานหน่วยความจำจาก GPU ทั้งหมด และคุณสามารถปรับพารามิเตอร์atch_sizeในไฟล์ hparams.json ตามลำดับเพื่อใช้หน่วยความจำได้อย่างเต็มที่ คุณจะสามารถเห็นผลการฝึกอบรมภายใต้โฟลเดอร์ Data/Result/ ตรวจสอบให้แน่ใจว่ามีไฟล์ 2 ไฟล์ต่อไปนี้ เนื่องจากจำเป็นสำหรับการทดสอบและการทำนาย (ไฟล์ .meta เป็นทางเลือก เนื่องจากโมเดลการอนุมานจะถูกสร้างขึ้นแยกจากกัน):
สำหรับการทดสอบและการทำนาย เรามีอินเทอร์เฟซคำสั่งที่เรียบง่ายและอินเทอร์เฟซบนเว็บ โปรดทราบว่าไฟล์ vocab.txt (และไฟล์ใน KnowledgeBase สำหรับแชทบอทนี้) ก็จำเป็นสำหรับการอนุมานเช่นกัน เพื่อตรวจสอบอย่างรวดเร็วว่าโมเดลที่ผ่านการฝึกอบรมทำงานอย่างไร ให้ใช้อินเทอร์เฟซคำสั่งต่อไปนี้:
cd chatbot
python botui.pyรอจนกว่าคุณจะได้รับคำสั่ง "> "
มีผลการทดสอบการสาธิตให้เช่นกัน โปรดตรวจสอบเพื่อดูว่าแชทบอทนี้ทำงานอย่างไรตอนนี้: https://github.com/bshao001/ChatLearner/blob/master/Data/Test/responses.txt
มีการนำสถาปัตยกรรมบริการเว็บที่ใช้ SOAP มาใช้ พร้อมด้วยเซิร์ฟเวอร์ Python และไคลเอนต์ Java GUI ที่ดีรวมอยู่ด้วยสำหรับการอ้างอิงของคุณ สำหรับรายละเอียด โปรดตรวจสอบ: https://github.com/bshao001/ChatLearner/tree/master/webui โปรดทราบว่าข้อมูลบางอย่าง (เช่น รูปภาพ) จะมีอยู่บนเว็บอินเตอร์เฟสเท่านั้น (ไม่ใช่ในอินเทอร์เฟซบรรทัดคำสั่ง)
นอกจากนี้ยังมีทางเลือกอื่นที่ใช้ REST-API หาก SOAP ไม่ใช่ตัวเลือกของคุณ สำหรับรายละเอียด โปรดตรวจสอบ: https://github.com/bshao001/ChatLearner/tree/master/webui_alternative การอัปเดตล่าสุดบางส่วนอาจไม่สามารถใช้ได้กับตัวเลือกนี้ รวมการเปลี่ยนแปลงจากตัวเลือกอื่นหากคุณต้องการใช้สิ่งนี้
การสนับสนุน NLP Markup Framework (自然语言处理标记框架),试上实现对特定领域问题的精准回复,并可以解决很多对话中的复杂的上下文相关问题。本方法尤其适用于商业上的专用(的向任务的(如法律,医疗)ของ技术咨询服务等。มี兴趣的朋友欢迎微信联系。本人微信号:bshao001_miami