Dialog
1.0.0
Dialog เป็นโครงการแชทบอทของญี่ปุ่น
สถาปัตยกรรมที่ใช้ในโปรเจ็กต์นี้คือรุ่น EncoderDecoder ที่มี BERT Encoder และ Transformer Decoder
บทความที่เขียนเป็นภาษาญี่ปุ่น
คุณสามารถเรียกใช้สคริปต์การฝึกอบรมและการประเมินผลบน Google Colab ได้โดยไม่ต้องสร้างสภาพแวดล้อม
กรุณาคลิกลิงค์ต่อไปนี้
โปรดทราบว่าในสมุดบันทึกการฝึกอบรม คำสั่งดาวน์โหลดจะอธิบายไว้ในส่วนท้ายของบันทึกย่อ แต่ยังไม่ได้ทดสอบ ดังนั้น หากคุณใช้สมุดบันทึกการฝึกอบรมและไม่สามารถดาวน์โหลดแฟ้มน้ำหนักที่ผ่านการฝึกอบรมได้ โปรดดาวน์โหลดด้วยตนเอง
บล็อกเขียนเป็นภาษาญี่ปุ่น
@ycat3 สร้างตัวอย่างการอ่านออกเสียงข้อความโดยใช้โปรเจ็กต์นี้สำหรับการสร้างประโยคและ Parallel Wavenet สำหรับการสังเคราะห์เสียงพูด ไม่มีการแชร์ซอร์สโค้ด แต่คุณสามารถสร้างซ้ำได้หากคุณใช้ประโยชน์จาก Parallel Wavenet บล็อกนั้นมีตัวอย่างเสียงอยู่บ้าง ดังนั้นโปรดลองฟังดู
ผมอยากสร้างแอพให้เราคุยกับ AI ด้วยเสียงได้ โดยใช้การสังเคราะห์เสียงพูดและการรู้จำเสียงพูดถ้ามีเวลาว่างมาก แต่ตอนนี้ทำไม่ได้เพราะต้องเตรียมสอบ...
2ยุค
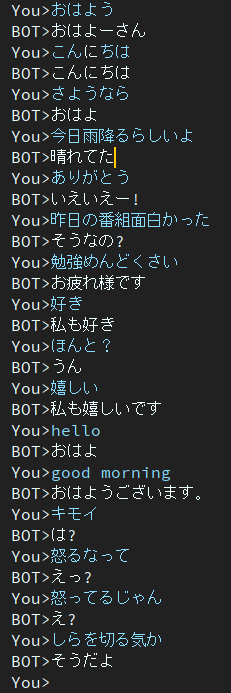
รุ่นนี้ยังคงมีปัญหาเรื่องการตอบสนองที่น่าเบื่อ
เพื่อแก้ไขปัญหานี้ ฉันกำลังค้นคว้าอยู่ตอนนี้
จากนั้นฉันก็พบว่ากระดาษนี้แก้ไขปัญหานี้ได้
ฟังก์ชั่นวัตถุประสงค์ที่ส่งเสริมความหลากหลายอีกประการหนึ่งสำหรับการสร้างบทสนทนาทางประสาท
ผู้เขียนอยู่ในสถาบันวิทยาศาสตร์และเทคโนโลยีนาราหรือที่รู้จักในชื่อ NAIST
พวกเขาเสนอฟังก์ชั่นวัตถุประสงค์ใหม่ของการสร้างบทสนทนาทางประสาท
ฉันหวังว่าวิธีนี้จะช่วยฉันแก้ปัญหานั้นได้
ใน Google ไดรฟ์
แพ็คเกจที่จำเป็นได้แก่
หากเกิดข้อผิดพลาดเนื่องจากแพ็คเกจ โปรดติดตั้งแพ็คเกจที่ขาดหายไป
ตัวอย่างถ้าคุณใช้ conda
# create new environment
$ conda create -n dialog python=3.7
# activate new environment
$ activate dialog
# install pytorch
$ conda install pytorch torchvision cudatoolkit={YOUR_VERSION} -c pytorch
# install rest of depending package except for MeCab
$ pip install transformers tqdm neologdn emoji
# #### Already installed MeCab #####
# ## Ubuntu ###
$ pip install mecab-python3
# ## Windows ###
# check that "path/to/MeCab/bin" are added to system envrionment variable
$ pip install mecab-python-windows
# #### Not Installed MeCab #####
# install Mecab in accordance with your OS.
# method described in below is one of the way,
# so you can use your way if you'll be able to use transformers.BertJapaneseTokenizer.
# ## Ubuntu ###
# if you've not installed MeCab, please execute following comannds.
$ apt install aptitude
$ aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y
$ pip install mecab-python3
# ## Windows ###
# Install MeCab from https://github.com/ikegami-yukino/mecab/releases/tag/v0.996
# and add "path/to/Mecab/bin" to system environment variable.
# then run the following command.
$ pip install mecab-python-windows # in config.py, line 24
# default value is './data'
data_dir = 'path/to/dir_contains_training_data'หากคุณพร้อมที่จะเริ่มการฝึกอบรม ให้รันสคริปต์หลัก
$ python main.py # in config.py, line 24
# default value is './data'
data_dir = 'path/to/dir_contains_pretrained'$ python run_eval.pyหากคุณต้องการรับข้อมูลการสนทนาเพิ่มเติม โปรดใช้ get_twitter.py
โปรดทราบว่าคุณต้องเปลี่ยน Consumer_key และ access_token เพื่อที่จะใช้สคริปต์นี้
จากนั้นให้รันคำสั่งต่อไปนี้
# usage
$ python get_tweet.py " query " " Num of continuous utterances "
# Example
# This command works until occurs errors
# and makes a file named "tweet_data_私は_5.txt" in "./data"
$ python get_tweet.py 私は 5หากคุณดำเนินการคำสั่งตัวอย่าง สคริปต์จะเริ่มรวบรวม 5 ประโยคติดต่อกันหากประโยคสุดท้ายมีคำว่า "私HA"
ไม่ว่าคุณจะตั้งค่าตัวเลข 3 ตัวขึ้นไปเป็น "คำพูดต่อเนื่อง" make_training_data.py จะสร้างคู่ของคำพูดโดยอัตโนมัติ
จากนั้นดำเนินการคำสั่งต่อไปนี้
$ python make_training_data.pyสคริปต์นี้สร้างข้อมูลการฝึกอบรมโดยใช้ './data/twitter_data_*.txt' เช่นเดียวกับชื่อ
ตัวเข้ารหัส: BERT
ตัวถอดรหัส: ตัวถอดรหัสของ Vanilla Transformer
การสูญเสีย: ข้ามเอนโทรปี
เครื่องมือเพิ่มประสิทธิภาพ: AdamW
Tokenizer: Bert JapaneseTokenizer
หากคุณต้องการข้อมูลเพิ่มเติมเกี่ยวกับสถาปัตยกรรมของ BERT หรือ Transformer โปรดดูบทความต่อไปนี้


