Seq2seqChatbots
1.0.0
wrapper รอบ tensor2tensor เพื่อฝึก โต้ตอบ และสร้างข้อมูลสำหรับแชทบอทแบบนิวรัลอย่างยืดหยุ่น
วิกิประกอบด้วยบันทึกย่อและบทสรุปของฉันเกี่ยวกับสิ่งพิมพ์ล่าสุดกว่า 150 รายการที่เกี่ยวข้องกับการสร้างแบบจำลองกล่องโต้ตอบทางประสาท
- ดำเนินการฝึกอบรมของคุณเองหรือทดลองกับโมเดลที่ผ่านการฝึกอบรมมาแล้ว
ชุดข้อมูลไดอะล็อกที่แตกต่างกัน 4 ชุดรวมเข้ากับเทนเซอร์ 2 เทนเซอร์
- ใช้งานได้อย่างไม่มีสะดุดกับโมเดลหรือไฮเปอร์พารามิเตอร์ใดๆ ที่ตั้งค่าไว้ใน tensor2tensor
คลาสพื้นฐานที่ขยายได้อย่างง่ายดายสำหรับปัญหาการโต้ตอบ
เรียกใช้ setup.py ซึ่งจะติดตั้งแพ็คเกจที่จำเป็นและขั้นตอนในการดาวน์โหลดข้อมูลเพิ่มเติม:
python setup.py
คุณสามารถดาวน์โหลดโมเดลที่ผ่านการฝึกอบรมทั้งหมดที่ใช้ในเอกสารนี้ได้จากที่นี่ การฝึกอบรมแต่ละครั้งประกอบด้วยจุดตรวจสอบสองจุด จุดหนึ่งสำหรับการสูญเสียการตรวจสอบขั้นต่ำ และอีกจุดหนึ่งหลังจาก 150 ยุค ข้อมูลและโครงสร้างโฟลเดอร์การฝึกอบรมตรงกันทุกประการ
python t2t_csaky/main.py --mode=train
อาร์กิวเมนต์ของโหมดสามารถเป็นหนึ่งในสี่อาร์กิวเมนต์ต่อไปนี้: {generate_data, train, decode, Experiment} ในโหมด การทดลอง คุณสามารถระบุได้ว่าต้องทำอะไรภายในฟังก์ชัน การทดลอง ของไฟล์ ที่รัน มีคำอธิบายโดยละเอียดอยู่ด้านล่างนี้ว่าแต่ละโหมดทำอะไรได้บ้าง
คุณสามารถควบคุมแฟล็กและพารามิเตอร์ของแต่ละโหมดได้โดยตรงในไฟล์นี้ สำหรับการรันแต่ละครั้งที่คุณเริ่มต้น ไฟล์นี้จะถูกคัดลอกไปยังไดเร็กทอรีที่เหมาะสม เพื่อให้คุณสามารถเข้าถึงพารามิเตอร์ของการรันใดๆ ได้อย่างรวดเร็ว มีแฟล็กบางส่วนที่คุณต้องตั้งค่าสำหรับทุกโหมด (พจนานุกรม FLAGS ในไฟล์ปรับแต่ง):
t2t_usr_dir : เส้นทางไปยังไดเร็กทอรีที่มีโค้ดของฉันอยู่ คุณไม่จำเป็นต้องเปลี่ยนแปลงสิ่งนี้ เว้นแต่คุณจะเปลี่ยนชื่อไดเร็กทอรี
data_dir : เส้นทางไปยังไดเร็กทอรีที่คุณต้องการสร้างคู่ต้นทางและเป้าหมาย และข้อมูลอื่นๆ ชุดข้อมูลจะถูกดาวน์โหลดในระดับที่สูงขึ้นหนึ่งระดับจากไดเร็กทอรีนี้ไปยังโฟลเดอร์ raw_data
ปัญหา : นี่คือชื่อของปัญหาที่ลงทะเบียนที่ tensor2tensor ต้องการ รายละเอียดในส่วน Generate_data ด้านล่าง เส้นทางทั้งหมดควรมาจากรากของ repo
โหมดนี้จะดาวน์โหลดและประมวลผลข้อมูลล่วงหน้า และสร้างคู่แหล่งที่มาและเป้าหมาย ขณะนี้มีปัญหาที่ลงทะเบียนไว้ 6 ปัญหา ซึ่งคุณสามารถใช้นอกเหนือจากปัญหาที่ได้รับจาก tensor2tensor:
persona_chat_chatbot : ปัญหานี้ใช้ชุดข้อมูล Persona-Chat (โดยไม่ต้องใช้ personas)
daily_dialog_chatbot : ปัญหานี้ใช้ชุดข้อมูล DailyDialog (โดยไม่ต้องใช้หัวข้อ การโต้ตอบ หรืออารมณ์)
opensubtitles_chatbot : ปัญหานี้สามารถใช้เพื่อทำงานกับชุดข้อมูล OpenSubtitles
cornell_chatbot_basic : ปัญหานี้ใช้กับ Cornell Movie-Dialog Corpus
cornell_chatbot_separate_names : ปัญหานี้ใช้คลังข้อมูล Cornell เดียวกัน อย่างไรก็ตาม ชื่อของผู้พูดและผู้รับของแต่ละคำพูดจะถูกต่อท้าย ส่งผลให้ได้เสียงต้นฉบับดังด้านล่าง
BIANCA_m0 มีของดีอะไรบ้าง ? คาเมรอน_m0
character_chatbot : นี่เป็นปัญหาเกี่ยวกับอักขระทั่วไปที่ใช้ได้กับชุดข้อมูลใดๆ ก่อนที่จะใช้สิ่งนี้ ไฟล์ .txt ที่สร้างขึ้นจากปัญหาใดๆ ข้างต้นจะต้องถูกวางไว้ภายในไดเร็กทอรีข้อมูล และหลังจากนั้นปัญหานี้สามารถใช้เพื่อสร้างไฟล์ข้อมูลตามอักขระ tensor2tensor ได้
พจนานุกรม PROBLEM_HPARAMS ในไฟล์ปรับแต่งมีพารามิเตอร์เฉพาะปัญหาที่คุณสามารถตั้งค่าก่อนสร้างข้อมูล:
num_train_shards / num_dev_shards : หากคุณต้องการให้ข้อมูลรถไฟหรือ dev ที่สร้างขึ้นถูกแบ่งเป็นหลายไฟล์
คำศัพท์ขนาด : ขนาดของคำศัพท์ที่เราต้องการใช้สำหรับโจทย์ คำที่อยู่นอกคำศัพท์นี้จะถูกแทนที่ด้วยโทเค็น
dataset_size : จำนวนคู่คำพูด หากเราไม่ต้องการใช้ชุดข้อมูลเต็ม (กำหนดโดย 0)
dataset_split : ระบุการแยก train-val-test สำหรับปัญหา
dataset_version : สิ่งนี้เกี่ยวข้องกับชุดข้อมูล opensubtitles เท่านั้น เนื่องจากชุดข้อมูลนี้มีหลายเวอร์ชัน คุณจึงระบุปีของชุดข้อมูลที่คุณต้องการดาวน์โหลดได้
name_vocab_size : สิ่งนี้เกี่ยวข้องกับปัญหาคอร์เนลที่มีชื่อแยกต่างหากเท่านั้น คุณสามารถกำหนดขนาดของคำศัพท์ที่มีเฉพาะตัวบุคคลได้
โหมดนี้ช่วยให้คุณฝึกโมเดลที่มีปัญหาและไฮเปอร์พารามิเตอร์ที่ระบุได้ โค้ดเพียงเรียกสคริปต์การฝึกอบรม tensor2tensor ดังนั้นโมเดลใดๆ ก็ตามที่อยู่ใน tensor2tensor ก็สามารถใช้ได้ นอกจากนี้ ยังมีโมเดลย่อยที่มีการดัดแปลงเล็กน้อย:
gradient_checkpointed_seq2seq : การปรับเปลี่ยนเล็กน้อยของโมเดล seq2seq ที่ใช้ lstm เพื่อให้สามารถใช้ hparams ของตัวเองได้ทั้งหมด ก่อนที่จะคำนวณซอฟต์แม็กซ์ หน่วยที่ซ่อนอยู่ของ LSTM จะถูกคาดการณ์ไว้ที่ 2048 หน่วยเชิงเส้นดังที่นี่ ในที่สุด ฉันพยายามใช้จุดตรวจสอบการไล่ระดับสีกับโมเดลนี้ แต่ขณะนี้ได้ถูกนำออกไปแล้วเนื่องจากไม่ได้ผลลัพธ์ที่ดี
มีแฟล็กเพิ่มเติมหลายแฟล็กที่คุณสามารถระบุสำหรับการรันการฝึกในพจนานุกรม FLAGS ในไฟล์กำหนดค่า ซึ่งบางส่วนได้แก่:
train_dir : ชื่อของไดเร็กทอรีที่จะบันทึกไฟล์จุดตรวจสอบการฝึกอบรม
model : ชื่อของโมเดล: อย่างใดอย่างหนึ่งข้างต้นหรือโมเดลที่กำหนด tensor2tensor
hparams : ระบุ hparams_set ที่ลงทะเบียนไว้ หรือเว้นว่างไว้หากคุณต้องการกำหนด hparams ในไฟล์ปรับแต่ง เพื่อระบุ hparams สำหรับ seq2seq หรือรุ่น Transformer คุณสามารถใช้พจนานุกรม SEQ2SEQ_HPARAMS และ TRANSFORMER_HPARAMS ในไฟล์ปรับแต่งได้ (ตรวจสอบเพื่อดูรายละเอียดเพิ่มเติม)
ด้วยโหมดนี้คุณสามารถถอดรหัสจากโมเดลที่ผ่านการฝึกอบรมได้ พารามิเตอร์ต่อไปนี้ส่งผลต่อการถอดรหัส (ในพจนานุกรม FLAGS ในไฟล์กำหนดค่า):
decode_mode : สามารถ โต้ตอบได้ โดยคุณสามารถสนทนากับโมเดลได้โดยใช้บรรทัดคำสั่ง โหมด ไฟล์ ช่วยให้คุณสามารถระบุไฟล์ที่มีคำพูดต้นทางที่จะสร้างการตอบสนอง และโหมด ชุดข้อมูล จะสุ่มตัวอย่างข้อมูลการตรวจสอบความถูกต้องที่ให้ไว้และการตอบกลับเอาท์พุต
decode_dir : ไดเร็กทอรีที่คุณสามารถจัดเตรียมไฟล์เพื่อถอดรหัส และการตอบกลับที่ส่งออกจะถูกบันทึกไว้ที่นี่
input_file_name : ชื่อของไฟล์ที่คุณต้องให้ในโหมด ไฟล์ (วางไว้ใน decode_dir )
output_file_name : ชื่อของไฟล์ภายใน decode_dir โดยที่การตอบกลับเอาต์พุตจะถูกบันทึก
beam_size : ขนาดของลำแสง เมื่อใช้การค้นหาลำแสง
return_beams : หากเป็น False ส่งคืนเฉพาะลำแสงด้านบน ไม่เช่นนั้นจะส่งคืนจำนวน คานขนาด ลำแสง
ผลลัพธ์ต่อไปนี้มาจากเอกสารทั้งสองนี้
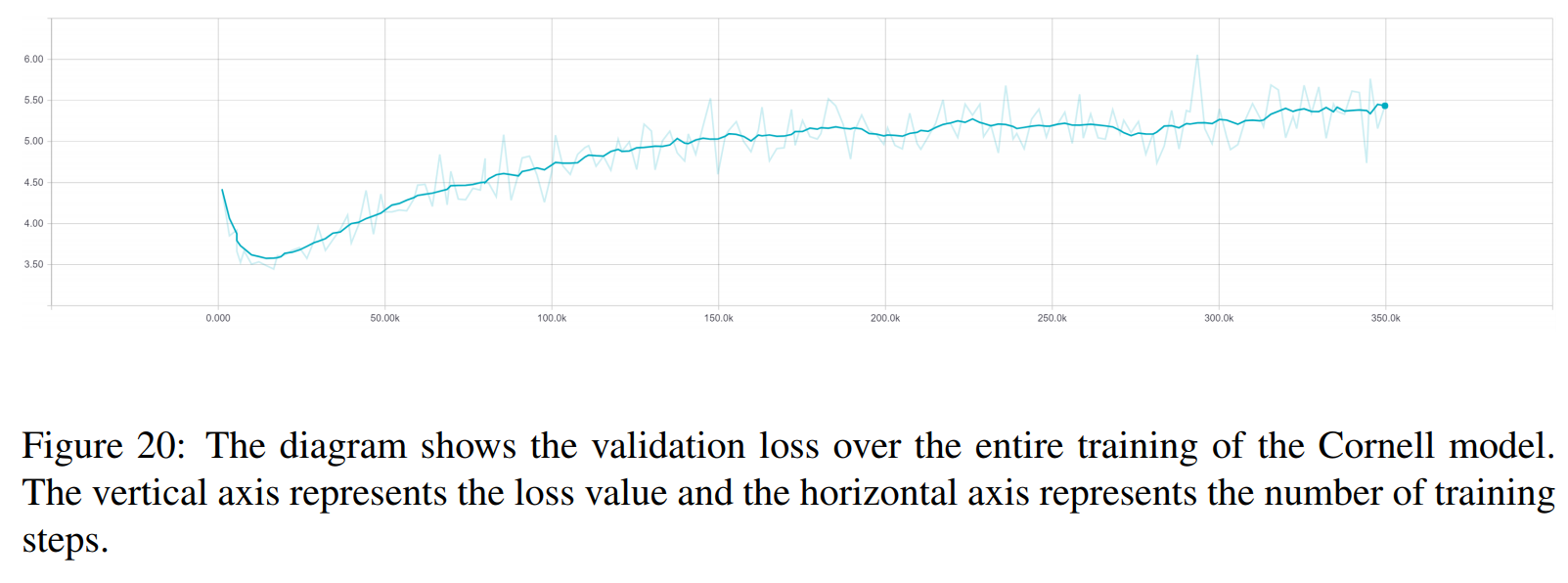

TRF คือโมเดล Transformer ในขณะที่ RT หมายถึงการตอบสนองที่เลือกแบบสุ่มจากชุดการฝึก และ GT หมายถึงการตอบสนองตามความจริงภาคพื้นดิน สำหรับคำอธิบายเกี่ยวกับเมตริก โปรดดูเอกสารนี้
S2S เป็นโมเดล seq2seq ธรรมดาที่มี LSTM ที่ได้รับการฝึกบน Cornell ส่วนรุ่นอื่นๆ เป็นโมเดล Transformer Opensubtitles F ได้รับการฝึกอบรมล่วงหน้าเกี่ยวกับ Opensubtitles และได้รับการปรับแต่งบน Cornell 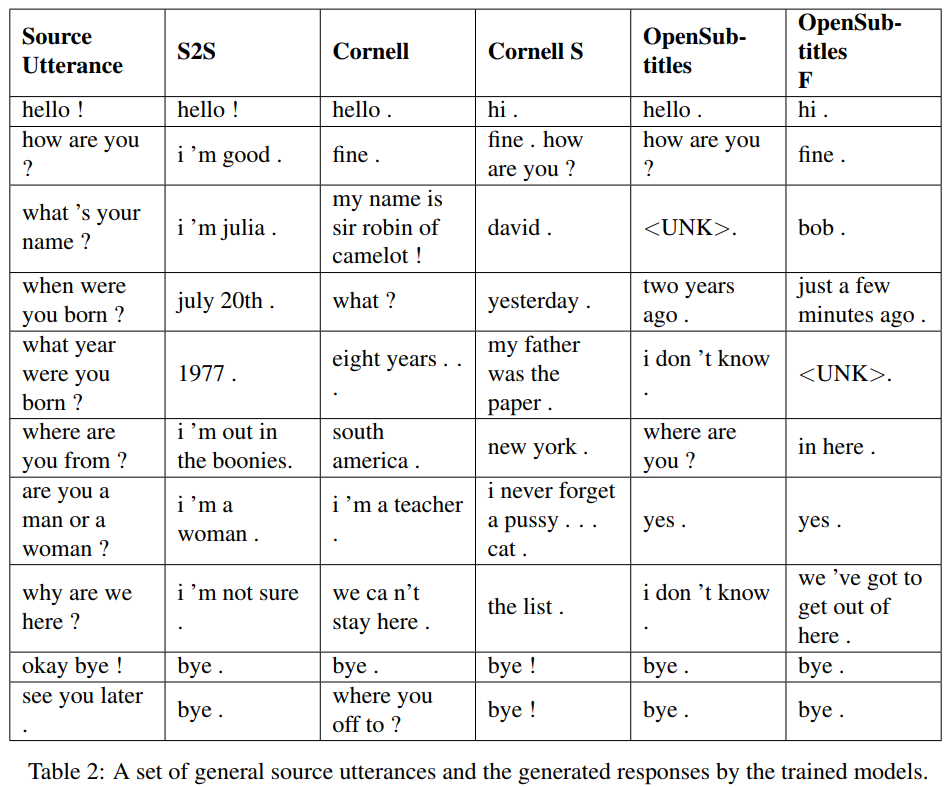
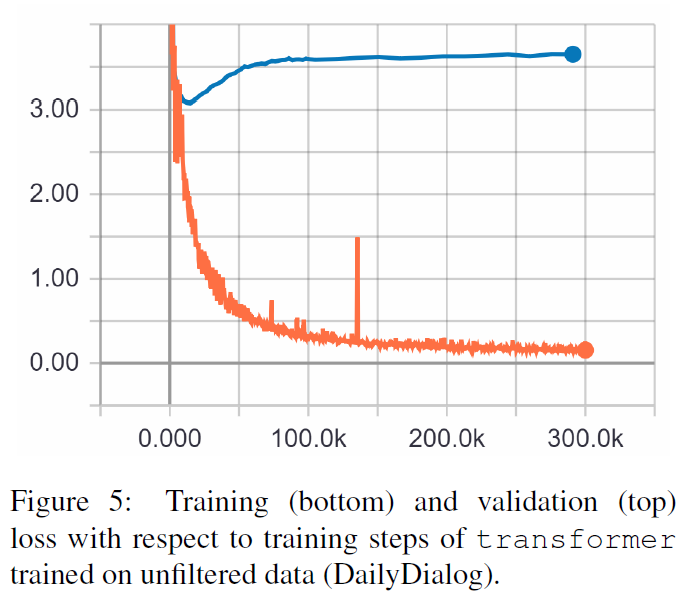

TRF คือโมเดล Transformer ในขณะที่ RT หมายถึงการตอบสนองที่เลือกแบบสุ่มจากชุดการฝึก และ GT หมายถึงการตอบสนองตามความจริงภาคพื้นดิน สำหรับคำอธิบายเกี่ยวกับเมตริก โปรดดูเอกสารนี้
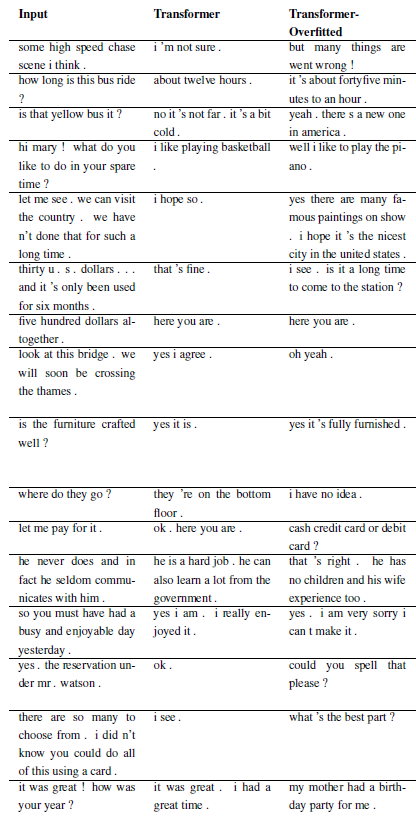
ปัญหาใหม่ สามารถลงทะเบียนได้ด้วยคลาสย่อย WordChatbot หรือดีกว่าคลาสย่อย CornellChatbotBasic หรือ OpensubtitleChatbot เนื่องจากพวกมันใช้ฟังก์ชันเพิ่มเติมบางอย่าง โดยปกติแล้ว การแทนที่ฟังก์ชัน preprocess และ create_data ก็เพียงพอแล้ว ตรวจสอบเอกสารประกอบเพื่อดูรายละเอียดเพิ่มเติมและดูตัวอย่าง daily_dialog_chatbot
คุณสามารถเพิ่ม โมเดลใหม่ และไฮเปอร์พารามิเตอร์ได้โดยทำตามบทช่วยสอน tensor2tensor
Richard Csaky (หากคุณต้องการความช่วยเหลือในการรันโค้ด: [email protected])
โครงการนี้ได้รับอนุญาตภายใต้ใบอนุญาต MIT - ดูรายละเอียดในไฟล์ใบอนุญาต
โปรดใส่ลิงก์ไปยัง repo นี้หากคุณใช้ในงานของคุณและพิจารณาอ้างอิงเอกสารต่อไปนี้:
@InProceedings{Csaky:2017,
title = {Deep Learning Based Chatbot Models},
author = {Csaky, Richard},
year = {2019},
publisher={National Scientific Students' Associations Conference},
url ={https://tdk.bme.hu/VIK/DownloadPaper/asdad},
note={https://tdk.bme.hu/VIK/DownloadPaper/asdad}
} 

