turing
v0.3.8
Viglet Turing ES (https://openviglet.github.io/turing/) เป็นโซลูชันโอเพ่นซอร์ส (https://github.com/openturing) ซึ่งมี Semantic Navigation และ Chat bot เป็นคุณสมบัติหลัก คุณสามารถเลือกจาก NLP ต่างๆ เพื่อเพิ่มคุณค่าให้กับข้อมูล เนื้อหาทั้งหมดได้รับการจัดทำดัชนีใน Solr เป็นเครื่องมือค้นหา
เอกสารทางเทคนิคเกี่ยวกับ Turing ES มีอยู่ที่ https://openviglet.github.io/docs/turing/
หากต้องการรัน Turing ES เพียงดำเนินการบรรทัดต่อไปนี้:
# Turing Appmvn -Dmaven.repo.local=D:repo spring-boot:run -pl turing-app -Dskip.npm# ใหม่ Turing ES UI โดยใช้ Angular 18 และ Primer CSS.cd turing-ui## Loginng ให้บริการต้อนรับ ## Consoleng ให้บริการคอนโซล## Searchng ให้บริการ sn## Chat botng ให้บริการสนทนา
คุณสามารถเริ่ม Turing ES ได้โดยใช้ MariaDB, Solr และ Nginx
นักเทียบท่า-เขียนขึ้น
คอนโซลการดูแลระบบ: http://localhost:2700 (ผู้ดูแลระบบ/ผู้ดูแลระบบ)
ตัวอย่างการนำทางความหมาย: http://localhost:2700/sn/Sample
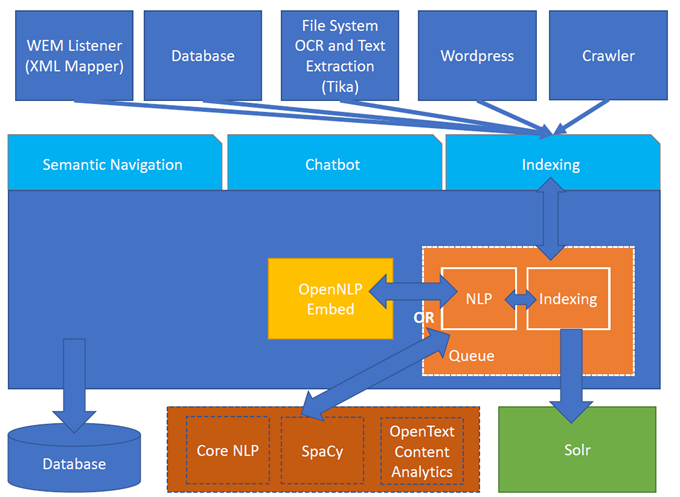
รูปที่ 1 สถาปัตยกรรมทัวริง ES
ทัวริงสนับสนุนผู้ให้บริการดังต่อไปนี้:
Apache OpenNLP เป็นชุดเครื่องมือที่ใช้การเรียนรู้ของเครื่องสำหรับการประมวลผลข้อความภาษาธรรมชาติ
เว็บไซต์: https://opennlp.apache.org/
โดยจะแปลงข้อมูลให้เป็นข้อมูลเชิงลึกเพื่อการตัดสินใจและการจัดการข้อมูลที่ดีขึ้น ในขณะเดียวกันก็ทำให้ทรัพยากรและเวลามีอิสระมากขึ้น
เว็บไซต์: https://www.opentext.com/
CoreNLP เป็นร้านค้าครบวงจรสำหรับการประมวลผลภาษาธรรมชาติใน Java! CoreNLP ช่วยให้ผู้ใช้สามารถได้รับคำอธิบายประกอบทางภาษาสำหรับข้อความ รวมถึงขอบเขตโทเค็นและประโยค ส่วนของคำพูด เอนทิตีที่มีชื่อ ค่าตัวเลขและเวลา การแยกวิเคราะห์การขึ้นต่อกันและการเลือกตั้ง การอ้างอิงหลัก ความคิดเห็น การระบุแหล่งที่มาของคำพูด และความสัมพันธ์ ปัจจุบัน CoreNLP รองรับ 6 ภาษา: อารบิก จีน อังกฤษ ฝรั่งเศส เยอรมัน และสเปน
เว็บไซต์: https://stanfordnlp.github.io/CoreNLP/,
เป็นไลบรารีโอเพ่นซอร์สฟรีสำหรับการประมวลผลภาษาธรรมชาติใน Python มันมี NER, การแท็ก POS, การแยกวิเคราะห์การอ้างอิง, เวกเตอร์คำ และอื่นๆ
เว็บไซต์: https://spacy.io
Polyglot เป็นไปป์ไลน์ภาษาธรรมชาติที่รองรับแอปพลิเคชันหลายภาษาขนาดใหญ่
เว็บไซต์: https://polyglot.readthedocs.io
สามารถอ่าน PDF และเอกสารและแปลงเป็นข้อความธรรมดาได้ และยังใช้ OCR เพื่อตรวจจับข้อความในรูปภาพและรูปภาพลงในเอกสาร
Semantic Navigation ใช้ตัวเชื่อมต่อเพื่อสร้างดัชนีเนื้อหาจากหลายแหล่ง
ปลั๊กอินสำหรับ Apache Nutch เพื่อสร้างดัชนีเนื้อหาโดยใช้ซอฟต์แวร์รวบรวมข้อมูล
เรียนรู้เพิ่มเติมที่ https://docs.viglet.com/turing/connectors/#nutch
บรรทัดคำสั่งที่ใช้แนวคิดเดียวกันกับ sqoop (https://sqoop.apache.org/) เพื่อสร้างแบบสอบถามที่ซับซ้อนและแอตทริบิวต์แผนที่เพื่อจัดทำดัชนีตามผลลัพธ์
เรียนรู้เพิ่มเติมที่ https://docs.viglet.com/turing/connectors/#database
บรรทัดคำสั่งสำหรับจัดทำดัชนีไฟล์ แยกข้อความจากไฟล์เช่น Word, Excel, PDF รวมถึงรูปภาพ ผ่าน OCR
เรียนรู้เพิ่มเติมที่ https://docs.viglet.com/turing/connectors/#file-system
OpenText WEM Listener เพื่อเผยแพร่เนื้อหาไปยัง Viglet Turing
เรียนรู้เพิ่มเติมที่ https://docs.viglet.com/turing/connectors/#wem
ปลั๊กอิน WordPress ที่ให้คุณจัดทำดัชนีโพสต์
เรียนรู้เพิ่มเติมที่ https://docs.viglet.com/turing/connectors/#wordpress
ด้วย NLP คุณสามารถตรวจจับเอนทิตีต่างๆ เช่น:
ประชากร
สถานที่
องค์กร
เงิน
เวลา
เปอร์เซ็นต์
กำหนดแอตทริบิวต์ที่จะใช้เป็นตัวกรองสำหรับการนำทางของคุณ โดยรวบรวมเนื้อหาทั้งหมดในจอแสดงผลของคุณ
ด้วยคุณลักษณะที่กำหนดไว้ในเนื้อหา คุณจึงสามารถใช้เพื่อจำกัดการแสดงผลตามโปรไฟล์ของผู้ใช้ได้
Java API (https://github.com/openturing/turing-java-sdk) อำนวยความสะดวกในการใช้งานและการเข้าถึง Viglet Turing ES โดยไม่จำเป็นต้องค้นหาเนื้อหาผู้บริโภคที่มีการสืบค้นที่ซับซ้อน
สื่อสารกับลูกค้าของคุณและอธิบายเจตนาที่ซับซ้อน รับรายงาน และพัฒนาปฏิสัมพันธ์ของคุณอย่างต่อเนื่อง
ส่วนประกอบ:
จัดการการสนทนากับผู้ใช้ปลายทางของคุณ เป็นโมดูลประมวลผลภาษาธรรมชาติที่เข้าใจถึงความแตกต่างของภาษามนุษย์
เจตนาจะจัดหมวดหมู่ความตั้งใจของผู้ใช้ในการเปลี่ยนการสนทนา สำหรับแต่ละตัวแทน คุณจะกำหนดเจตนาหลายอย่าง โดยที่เจตนารวมของคุณสามารถจัดการกับการสนทนาที่สมบูรณ์ได้
ขอบเขตการดำเนินการเป็นขอบเขตความสะดวกสบายที่เรียบง่ายซึ่งช่วยในการดำเนินการตรรกะในบริการ
พารามิเตอร์ Intent แต่ละตัวมีประเภทที่เรียกว่าประเภทเอนทิตี ซึ่งกำหนดวิธีการแยกข้อมูลในนิพจน์ของผู้ใช้อย่างชัดเจน
กำหนดและแก้ไขเจตนา
แสดงประวัติการสนทนาและรายงาน
ทัวริง ES ตรวจจับเอนทิตีของเอกสาร OpenText Blazon โดยใช้ OCR และ NLP สร้าง Blazon XML เพื่อแสดงเอนทิตีลงในเอกสาร
Turing ES มีองค์ประกอบมากมาย: Search Engine, NLP, Converse (Chat bot), Semantic Navigation
เมื่อเข้าถึง Turing ES จะปรากฏหน้าเข้าสู่ระบบ สำหรับค่าเริ่มต้น การเข้าสู่ระบบ/รหัสผ่านคือ admin / admin
รูปที่ 2 หน้าเข้าสู่ระบบ
ทัวริงใช้เครื่องมือค้นหาเพื่อจัดเก็บและดึงข้อมูลของ Converse (แชทบอท) และไซต์การนำทางเชิงความหมาย
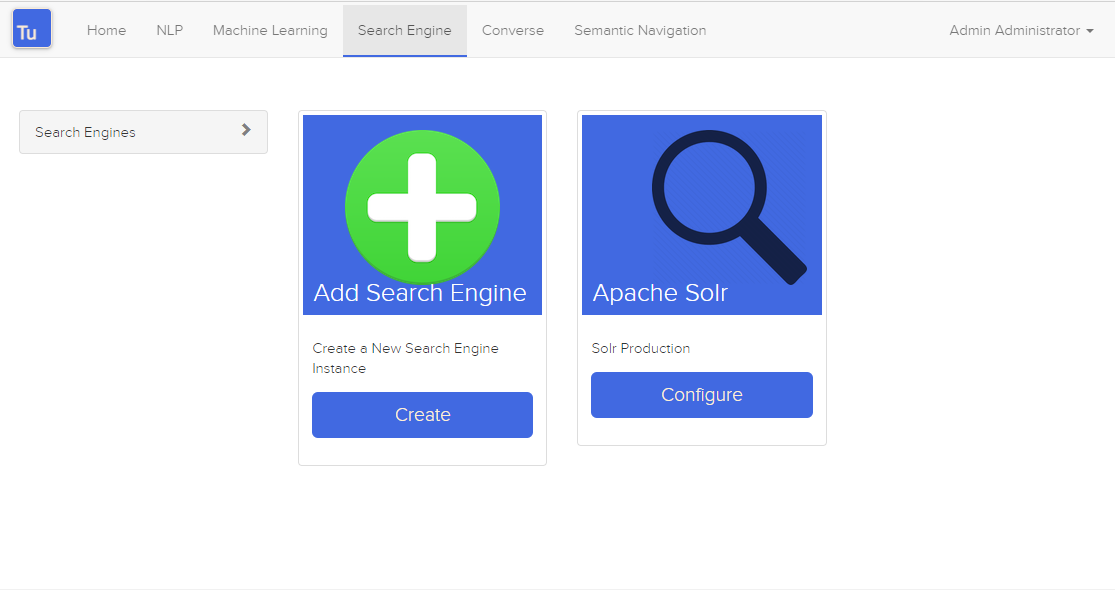
รูปที่ 3 หน้าเครื่องมือค้นหา
สามารถสร้างหรือแก้ไขเครื่องมือค้นหาด้วยคุณลักษณะต่อไปนี้:
| คุณลักษณะ | คำอธิบาย |
|---|---|
ชื่อ | ชื่อของเครื่องมือค้นหา |
คำอธิบาย | คำอธิบายของเครื่องมือค้นหา |
ผู้ขาย | เลือกผู้จำหน่ายเครื่องมือค้นหา สำหรับตอนนี้รองรับเฉพาะ Solr เท่านั้น |
เจ้าภาพ | ชื่อโฮสต์ที่ติดตั้งบริการ Search Engine |
ท่าเรือ | ท่าเรือบริการเครื่องมือค้นหา |
ภาษา | ภาษาของบริการเครื่องมือค้นหา |
เปิดใช้งานแล้ว | หากเปิดใช้งานเครื่องมือค้นหา |
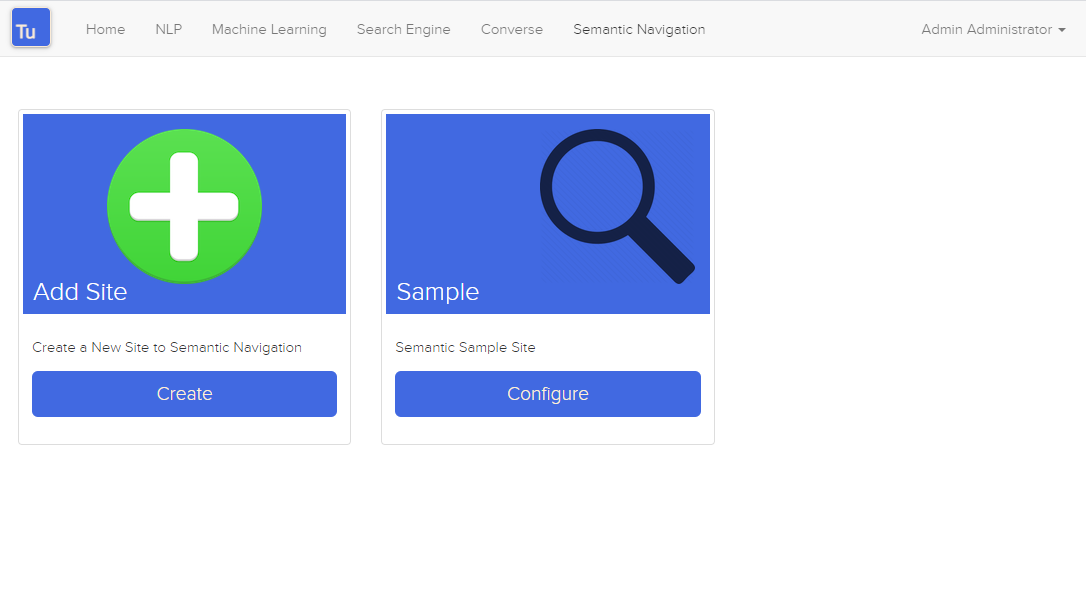
รูปที่ 4 หน้าการนำทางความหมาย
รายละเอียดของไซต์การนำทางเชิงความหมายประกอบด้วยแอตทริบิวต์ต่อไปนี้:
| คุณลักษณะ | คำอธิบาย |
|---|---|
ชื่อ | ชื่อของไซต์การนำทางความหมาย |
คำอธิบาย | คำอธิบายของไซต์การนำทางเชิงความหมาย |
เครื่องมือค้นหา | เลือกเครื่องมือค้นหาที่สร้างขึ้นในส่วนเครื่องมือค้นหา ไซต์การนำทางความหมายจะใช้เครื่องมือค้นหานี้เพื่อจัดเก็บและดึงข้อมูล |
เอ็นแอลพี | เลือก NLP ที่สร้างขึ้นในส่วน NLP ไซต์การนำทางความหมายจะใช้ NLP นี้เพื่อตรวจจับเอนทิตีระหว่างการจัดทำดัชนี |
พจนานุกรม | ถ้าคุณใช้อรรถาภิธาน |
ภาษา | ภาษาของไซต์การนำทางความหมาย |
แกนกลาง | ชื่อแกนหลักของ Search Engine ที่จะจัดเก็บและเรียกข้อมูล |
แท็บฟิลด์ประกอบด้วยตารางที่มีคอลัมน์ต่อไปนี้: .คอลัมน์ฟิลด์ไซต์การนำทางแบบความหมาย
| ชื่อคอลัมน์ | คำอธิบาย |
|---|---|
พิมพ์ | ประเภทของสนาม มันสามารถ: - NER (การรับรู้เอนทิตีที่มีชื่อ) ใช้โดย NLP - เครื่องมือค้นหาที่ใช้โดย Solr |
สนาม | ชื่อสนาม. |
เปิดใช้งานแล้ว | หากสนามเปิดใช้งานอยู่หรือไม่ |
มทส | หากฟิลด์นี้จะถูกใช้ใน MLT |
แง่มุม | หากต้องการใช้ฟิลด์นี้เหมือนกับแง่มุม (ตัวกรอง) |
เน้น | หากช่องนี้จะแสดงเส้นที่ไฮไลต์ |
เอ็นแอลพี | หากฟิลด์นี้จะถูกประมวลผลโดย NLP เพื่อตรวจจับเอนทิตี (NER) เช่น ผู้คน องค์กร และสถานที่ |
เมื่อคลิกใน Field จะปรากฏหน้าใหม่พร้อมรายละเอียดฟิลด์พร้อมคุณสมบัติดังต่อไปนี้:
| คุณลักษณะ | คำอธิบาย |
|---|---|
ชื่อ | ชื่อสนาม |
คำอธิบาย | คำอธิบายของฟิลด์ |
พิมพ์ | ประเภทของสนาม อาจเป็น: |
มีหลายมูลค่า | ถ้าเป็นอาร์เรย์ |
ชื่อด้าน | ชื่อของป้ายกำกับด้าน (ตัวกรอง) บนหน้าการค้นหา |
ด้าน | หากต้องการใช้ฟิลด์นี้เหมือนกับแง่มุม (ตัวกรอง) |
เน้น | หากช่องนี้จะแสดงเส้นที่ไฮไลต์ |
มทส | หากฟิลด์นี้จะถูกใช้ใน MLT |
เปิดใช้งานแล้ว | หากฟิลด์นี้เปิดใช้งานอยู่ |
ที่จำเป็น | หากจำเป็นต้องกรอกข้อมูลในสนาม |
ค่าเริ่มต้น | กรณีที่เนื้อหาถูกจัดทำดัชนีโดยไม่มีฟิลด์เหล่านี้ นั่นคือค่าเริ่มต้น |
เอ็นแอลพี | หากฟิลด์นี้จะถูกประมวลผลโดย NLP เพื่อตรวจจับเอนทิตี (NER) เช่น ผู้คน องค์กร และสถานที่ |
ประกอบด้วยแอตทริบิวต์ต่อไปนี้:
| ส่วน | คุณลักษณะ | คำอธิบาย |
|---|---|---|
รูปร่าง | จำนวนรายการต่อหน้า | จำนวนรายการที่จะปรากฏในการค้นหา |
ด้าน | เปิดใช้งาน Facet แล้วหรือยัง? | หากจะแสดง Facet (ตัวกรอง) ในการค้นหา |
จำนวนรายการต่อด้าน | จำนวนรายการที่จะปรากฏในแต่ละ Facet (ตัวกรอง) | |
เน้น | เปิดใช้งานการไฮไลต์แล้วใช่ไหม | กำหนดว่าจะแสดงเส้นที่เน้นสีหรือไม่ |
แท็กล่วงหน้า | แท็ก HTML ที่จะใช้เมื่อเริ่มต้นภาคเรียน ตัวอย่างเช่น: <เครื่องหมาย> | |
โพสต์แท็ก | แท็ก HTML ที่จะใช้เมื่อสิ้นสุดภาคเรียน ตัวอย่างเช่น: </เครื่องหมาย> | |
มทส | เปิดใช้งานลักษณะนี้เพิ่มเติมหรือไม่ | กำหนดว่าจะแสดง MLT หรือไม่ |
ฟิลด์เริ่มต้น | ชื่อ | ฟิลด์ที่จะใช้เป็นชื่อที่กำหนดไว้ใน Solr schema.xml |
ข้อความ | ฟิลด์ที่จะใช้เป็นชื่อที่กำหนดไว้ใน Solr schema.xml | |
คำอธิบาย | ฟิลด์ที่จะใช้เป็นคำอธิบายที่กำหนดไว้ใน Solr schema.xml | |
วันที่ | ฟิลด์ที่จะใช้เป็นวันที่ที่กำหนดไว้ใน Solr schema.xml | |
ภาพ | ฟิลด์ที่จะใช้เป็น URL รูปภาพที่กำหนดไว้ใน Solr schema.xml | |
URL | ฟิลด์ที่จะใช้เป็น URL ที่กำหนดไว้ใน Solr schema.xml |
ใน Turing ES Console > Semantic Navigation > <SITE_NAME> คลิกปุ่ม Configure และคลิกปุ่ม Search Page
มันจะเปิดหน้าค้นหาที่ใช้รูปแบบ:
รับ http://localhost:2700/sn/<SITE_NAME>
หน้านี้ขอ Turing Rest API ผ่าน AJAX ตัวอย่างเช่น หากต้องการส่งคืนผลลัพธ์ทั้งหมดของ Semantic Navigation Site ในรูปแบบ JSON:
รับ http://localhost:2700/api/sn/<SITE_NAME>/search?p=1&q=*&sort=relevance
| คุณลักษณะ | จำเป็น / ไม่จำเป็น | คำอธิบาย | ตัวอย่าง |
|---|---|---|---|
ถาม | ที่จำเป็น | คำค้นหา | คิว=ฟู |
พี | ที่จำเป็น | หมายเลขหน้า หน้าแรกคือ 1 | พี=1 |
เรียงลำดับ | ที่จำเป็น | จัดเรียงค่า: | เรียงลำดับ=ความเกี่ยวข้อง |
ฟค[] | ไม่จำเป็น | ฟิลด์แบบสอบถาม กรองตามฟิลด์ โดยใช้รูปแบบต่อไปนี้: FIELD : VALUE | fq[]=หัวเรื่อง:bar |
ตร[] | ไม่จำเป็น | กฎการกำหนดเป้าหมาย จำกัดการค้นหาตาม: FIELD : VALUE | tr[]=แผนก:foobar |
แถว | ไม่จำเป็น | จำนวนแถวที่แบบสอบถามจะส่งกลับ | แถว=10 |
บนอินทราเน็ตของบริษัทประกันภัยใช้ OpenText WEM และ OpenText Portal รวมกับ Dynamic Portal Module การค้นหาแบบรวมถูกสร้างขึ้นใน Viglet Turing ES โดยใช้ตัวเชื่อมต่อ: WEM, ฐานข้อมูลพร้อมระบบไฟล์ ด้วยวิธีนี้ จึงสามารถแสดงเนื้อหาและไฟล์ทั้งหมดของอินทราเน็ตการค้นหาด้วยกฎการกำหนดเป้าหมาย ซึ่งอนุญาตให้แสดงเฉพาะเนื้อหาที่ผู้ใช้ได้รับอนุญาตเท่านั้น พอร์ทัล OpenText เข้าถึง Viglet Turing ES Java API ดังนั้นจึงไม่จำเป็นต้องสร้างการสืบค้นที่ซับซ้อนเพื่อส่งคืนผลลัพธ์
ชุดของ API Rest ถูกสร้างขึ้นเพื่อให้เนื้อหาของบริษัทภาครัฐทั้งหมดพร้อมใช้งานสำหรับพันธมิตร เนื้อหาทั้งหมดเหล่านี้อยู่ใน OpenText WEM และตัวเชื่อมต่อ WEM ถูกใช้เพื่อสร้างดัชนีเนื้อหาใน Viglet Turing ES แอปพลิเคชัน Spring Boot ถูกสร้างขึ้นด้วยชุด Rest API ที่ใช้เนื้อหา Turing ES ผ่าน Viglet Turing ES Java API
เว็บไซต์มหาวิทยาลัยบราซิลได้รับการพัฒนาโดยใช้ Viglet Shio CMS (https://viglet.com/shio) และเนื้อหาทั้งหมดได้รับการจัดทำดัชนีใน Viglet Turing ES โดยอัตโนมัติ การกำหนดค่านี้สร้างขึ้นในการสร้างแบบจำลองเนื้อหา และการพัฒนาเทมเพลตการค้นหาเกิดขึ้นใน Viglet Shio CMS


