GenDataAttribution
1.0.0
โครงการ | กระดาษ
เซิง-หยู หวาง 1 , อเล็กซี่ เอ. เอฟรอส 2 , จุน-หยาน จู้ 1 , ริชาร์ด จาง 3
มหาวิทยาลัยคาร์เนกีเมลลอน 1 , UC Berkeley 2 , Adobe Research 2
ใน ICCV, 2023.
แม้ว่าโมเดลข้อความเป็นรูปภาพขนาดใหญ่จะสามารถสังเคราะห์รูปภาพที่ "แปลกใหม่" ได้ แต่รูปภาพเหล่านี้จำเป็นต้องสะท้อนถึงข้อมูลการฝึกอบรม ปัญหาการระบุแหล่งที่มาของข้อมูลในโมเดลดังกล่าว ซึ่งรูปภาพในชุดการฝึกมีความรับผิดชอบต่อรูปลักษณ์ของรูปภาพที่สร้างขึ้นมากที่สุด ถือเป็นปัญหาที่ยากแต่ก็สำคัญ ในขั้นเริ่มต้นในการแก้ไขปัญหานี้ เราจะประเมินการระบุแหล่งที่มาด้วยวิธี "การปรับแต่ง" ซึ่งปรับแต่งโมเดลขนาดใหญ่ที่มีอยู่ให้สอดคล้องกับออบเจ็กต์หรือสไตล์ที่เป็นแบบอย่างที่กำหนด ข้อมูลเชิงลึกที่สำคัญของเราคือ สิ่งนี้ทำให้เราสามารถสร้างภาพสังเคราะห์ที่ได้รับอิทธิพลจากโครงสร้างตัวอย่างได้อย่างมีประสิทธิภาพ ด้วยชุดข้อมูลใหม่ของรูปภาพที่ได้รับอิทธิพลแบบอย่างดังกล่าว เราจึงสามารถประเมินอัลกอริธึมการระบุแหล่งที่มาของข้อมูลต่างๆ และพื้นที่คุณลักษณะต่างๆ ที่เป็นไปได้ นอกจากนี้ ด้วยการฝึกอบรมชุดข้อมูลของเรา เราสามารถปรับแต่งโมเดลมาตรฐาน เช่น DINO, CLIP และ ViT เพื่อแก้ไขปัญหาการระบุแหล่งที่มาได้ แม้ว่าขั้นตอนจะถูกปรับไปสู่ชุดตัวอย่างขนาดเล็ก แต่เราจะแสดงลักษณะทั่วไปไปยังชุดที่ใหญ่กว่า สุดท้ายนี้ ด้วยการคำนึงถึงความไม่แน่นอนโดยธรรมชาติของปัญหา เราสามารถกำหนดคะแนนการระบุแหล่งที่มาแบบนุ่มนวลบนชุดรูปภาพการฝึกได้
conda env create -f environment.yaml
conda activate gen-attr # Download precomputed features of 1M LAION images
bash feats/download_laion_feats.sh
# Download jpeg-ed 1M LAION images for visualization
bash dataset/download_dataset.sh laion_jpeg
# Download pretrained models
bash weights/download_weights.sh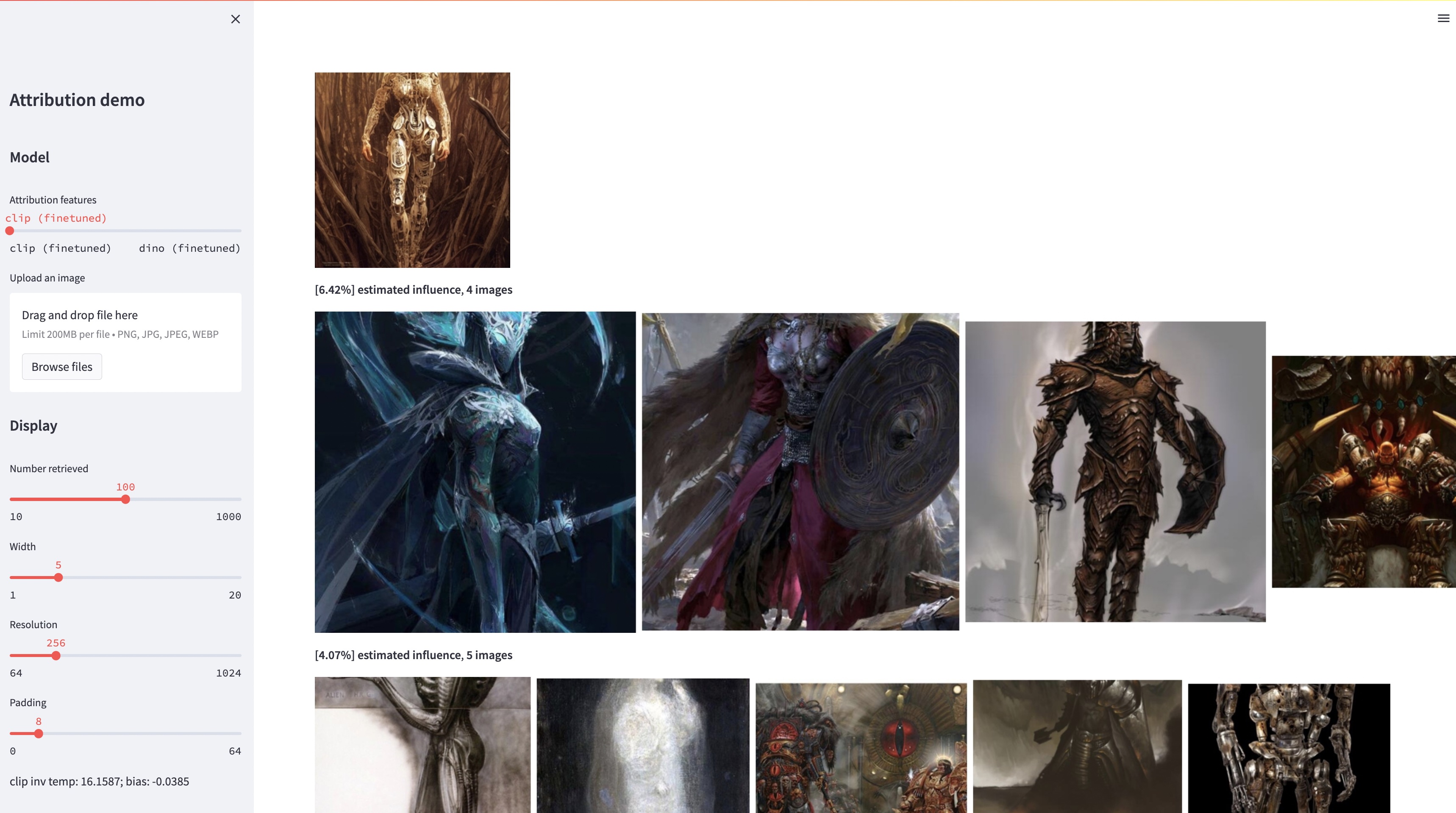
streamlit run streamlit_demo.pyเราเผยแพร่ชุดทดสอบของเราสำหรับการประเมินผล หากต้องการดาวน์โหลดชุดข้อมูล:
# Download the exemplar real images
bash dataset/download_dataset.sh exemplar
# Download the testset portion of images synthesized from Custom Diffusion
bash dataset/download_dataset.sh testset
# (Optional, can download precomputed features instead!)
# Download the uncompressed 1M LAION subset in pngs
bash dataset/download_dataset.sh laionชุดข้อมูลมีโครงสร้างดังนี้:
dataset
├── exemplar
│ ├── artchive
│ ├── bamfg
│ └── imagenet
├── synth
│ ├── artchive
│ ├── bamfg
│ └── imagenet
├── laion_subset
└── json
├──test_artchive.json
├──test_bamfg.json
├──...
รูปภาพตัวอย่างทั้งหมดจะถูกจัดเก็บไว้ใน dataset/exemplar รูปภาพที่สังเคราะห์ทั้งหมดจะถูกจัดเก็บไว้ใน dataset/synth และอิมเมจ laion 1M ใน pngs จะถูกจัดเก็บไว้ใน dataset/laion_subset ไฟล์ JSON ใน dataset/json ระบุการแยก train/val/test รวมถึงกรณีการทดสอบต่างๆ และทำหน้าที่เป็นป้ายกำกับความจริงภาคพื้นดิน แต่ละรายการในไฟล์ JSON เป็นโมเดลที่ได้รับการปรับแต่งโดยเฉพาะ รายการยังบันทึกรูปภาพตัวอย่างที่ใช้สำหรับการปรับแต่งอย่างละเอียดและรูปภาพสังเคราะห์ที่สร้างโดยโมเดล เรามีกรณีทดสอบสี่กรณี: test_artchive.json , test_bamfg.json , test_observed_imagenet.json และ test_unobserved_imagenet.json
หลังจากดาวน์โหลดชุดทดสอบ คุณลักษณะ LAION ที่คำนวณล่วงหน้า และน้ำหนักที่ฝึกไว้แล้ว เราสามารถคำนวณคุณลักษณะล่วงหน้าจากชุดทดสอบได้โดยการเรียกใช้ extract_feat.py จากนั้นประเมินประสิทธิภาพด้วยการเรียกใช้ eval.py ด้านล่างนี้คือสคริปต์ทุบตีที่รันการประเมินเป็นชุด:
# precompute all features from the testset
bash scripts/preprocess_feats.sh
# run evaluation in batches
bash scripts/run_eval.sh หน่วยเมตริกจะถูกจัดเก็บไว้ในไฟล์ .pkl ใน results ในปัจจุบัน สคริปต์จะรันแต่ละคำสั่งตามลำดับ โปรดแก้ไขเพื่อรันคำสั่งแบบขนาน คำสั่งต่อไปนี้จะแยกวิเคราะห์ไฟล์ .pkl ลงในตารางที่จัดเก็บเป็นไฟล์ .csv :
python results_to_csv.py 12/18/2023 อัปเดต หากต้องการดาวน์โหลดโมเดลที่ได้รับการฝึกเฉพาะในโมเดลแบบ object-centric หรือ style-centric ให้รัน bash weights/download_style_object_ablation.sh
@inproceedings{wang2023evaluating,
title={Evaluating Data Attribution for Text-to-Image Models},
author={Wang, Sheng-Yu and Efros, Alexei A. and Zhu, Jun-Yan and Zhang, Richard},
booktitle={ICCV},
year={2023}
}
เราขอขอบคุณ Aaron Hertzmann ที่อ่านร่างฉบับก่อนหน้านี้และสำหรับข้อเสนอแนะที่ลึกซึ้ง เราขอขอบคุณเพื่อนร่วมงานใน Adobe Research รวมถึง Eli Shechtman, Oliver Wang, Nick Kolkin, Taesung Park, John Collomosse และ Sylvain Paris พร้อมด้วย Alex Li และ Yonglong Tian สำหรับการสนทนาที่เป็นประโยชน์ เราขอขอบคุณ Nupur Kumari สำหรับคำแนะนำเกี่ยวกับการฝึกอบรม Custom Diffusion, Ruihan Gao สำหรับการอ่านแบบร่างเพื่อพิสูจน์อักษร, Alex Li สำหรับคำแนะนำในการแยกฟีเจอร์ Stable Diffusion และ Dan Ruta สำหรับความช่วยเหลือเกี่ยวกับชุดข้อมูล BAM-FG เราขอขอบคุณ Bryan Russell สำหรับการเดินป่าและการระดมความคิดเรื่องโรคระบาด งานนี้เริ่มต้นเมื่อ SYW เคยเป็นนักศึกษาฝึกงานของ Adobe และได้รับการสนับสนุนบางส่วนจากของขวัญจาก Adobe และรางวัลการวิจัยคณะ JP Morgan Chase


