clearml fractional gpu
1.0.0
? Leave a star to support the project! ?
การแบ่งปัน GPU ระดับไฮเอนด์ หรือแม้แต่ GPU สำหรับผู้บริโภคและผู้บริโภคระหว่างผู้ใช้หลายคนเป็นวิธีที่คุ้มค่าที่สุดในการเร่งการพัฒนา AI น่าเสียดายที่จนถึงขณะนี้โซลูชันเดียวที่มีอยู่สำหรับ MIG/Slicing GPU ระดับไฮเอนด์ (A100+) และ Kubernetes ที่จำเป็น
- ยินดีต้อนรับสู่ Fractional GPU แบบคอนเทนเนอร์สำหรับการ์ด Nvidia ทุกรุ่น! -
เรานำเสนอคอนเทนเนอร์สำเร็จรูปที่รองรับ CUDA 11.x และ CUDA 12.x พร้อมข้อจำกัดของหน่วยความจำฮาร์ดที่สร้างไว้ล่วงหน้า! ซึ่งหมายความว่าสามารถเปิดใช้งานคอนเทนเนอร์หลายตัวบน GPU เดียวกันได้ ทำให้มั่นใจได้ว่าผู้ใช้รายหนึ่งจะไม่สามารถจัดสรรหน่วยความจำ GPU ของโฮสต์ทั้งหมดได้! (ไม่มีกระบวนการที่โลภอีกต่อไปเพื่อคว้าหน่วยความจำ GPU ทั้งหมด! ในที่สุดเราก็มีตัวเลือกหน่วยความจำจำกัดระดับฮาร์ดไดร์เวอร์)
ClearML เสนอตัวเลือกมากมายเพื่อเพิ่มประสิทธิภาพการใช้ทรัพยากร GPU โดยการแบ่งพาร์ติชัน GPU:
ด้วยตัวเลือกเหล่านี้ ClearML เปิดใช้งานการรันปริมาณงาน AI ด้วยการใช้ฮาร์ดแวร์ที่เหมาะสมที่สุดและประสิทธิภาพของปริมาณงาน พื้นที่เก็บข้อมูลนี้ครอบคลุม GPU แบบเศษส่วนตามคอนเทนเนอร์ สำหรับข้อมูลเพิ่มเติมเกี่ยวกับข้อเสนอ GPU แบบเศษส่วนของ ClearML โปรดดูเอกสารประกอบของ ClearML
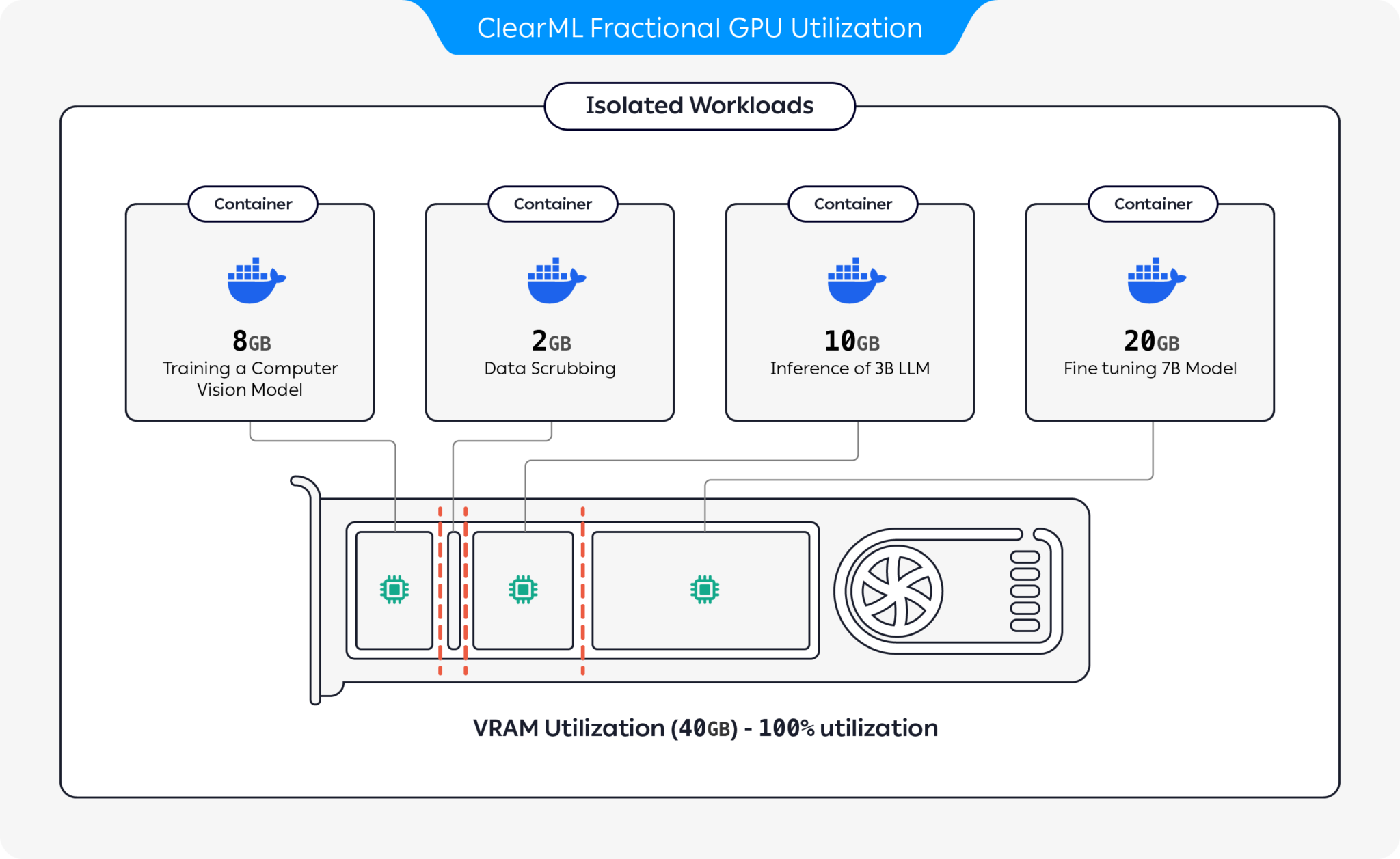
เลือกคอนเทนเนอร์ที่เหมาะกับคุณแล้วเปิดใช้งาน:
docker run -it --gpus 0 --ipc=host --pid=host clearml/fractional-gpu:u22-cu12.3-8gb bashหากต้องการตรวจสอบว่าขีดจำกัดหน่วยความจำ GPU แบบเศษส่วนทำงานอย่างถูกต้อง ให้รันภายในคอนเทนเนอร์:
nvidia-smiนี่คือตัวอย่างเอาต์พุตจาก A100 GPU:
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 545.23.08 Driver Version: 545.23.08 CUDA Version: 12.3 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 A100-PCIE-40GB Off | 00000000:01:00.0 Off | N/A |
| 32% 33C P0 66W / 250W | 0MiB / 8128MiB | 3% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
+---------------------------------------------------------------------------------------+
| ขีดจำกัดหน่วยความจำ | CUDA เวอร์ชั่น | อูบุนตูเวอร์ชัน | รูปภาพนักเทียบท่า |
|---|---|---|---|
| 12 กิ๊บ | 12.3 | 22.04 | clearml/fractional-gpu:u22-cu12.3-12gb |
| 12 กิ๊บ | 12.3 | 20.04 | clearml/fractional-gpu:u20-cu12.3-12gb |
| 12 กิ๊บ | 11.7 | 22.04 | clearml/fractional-gpu:u22-cu11.7-12gb |
| 12 กิ๊บ | 11.1 | 20.04 | clearml/fractional-gpu:u20-cu11.1-12gb |
| 8 กิ๊บ | 12.3 | 22.04 | clearml/fractional-gpu:u22-cu12.3-8gb |
| 8 กิ๊บ | 12.3 | 20.04 | clearml/fractional-gpu:u20-cu12.3-8gb |
| 8 กิ๊บ | 11.7 | 22.04 | clearml/fractional-gpu:u22-cu11.7-8gb |
| 8 กิ๊บ | 11.1 | 20.04 | clearml/fractional-gpu:u20-cu11.1-8gb |
| 4 กิ๊บ | 12.3 | 22.04 | clearml/fractional-gpu:u22-cu12.3-4gb |
| 4 กิ๊บ | 12.3 | 20.04 | clearml/fractional-gpu:u20-cu12.3-4gb |
| 4 กิ๊บ | 11.7 | 22.04 | clearml/fractional-gpu:u22-cu11.7-4gb |
| 4 กิ๊บ | 11.1 | 20.04 | clearml/fractional-gpu:u20-cu11.1-4gb |
| 2 กิ๊บ | 12.3 | 22.04 | clearml/fractional-gpu:u22-cu12.3-2gb |
| 2 กิ๊บ | 12.3 | 20.04 | clearml/fractional-gpu:u20-cu12.3-2gb |
| 2 กิ๊บ | 11.7 | 22.04 | clearml/fractional-gpu:u22-cu11.7-2gb |
| 2 กิ๊บ | 11.1 | 20.04 | clearml/fractional-gpu:u20-cu11.1-2gb |
สำคัญ
คุณต้องรันคอนเทนเนอร์ด้วย --pid=host !
บันทึก
--pid=host จำเป็นเพื่อให้ไดรเวอร์แยกความแตกต่างระหว่างกระบวนการของคอนเทนเนอร์และกระบวนการโฮสต์อื่น ๆ เมื่อจำกัดการใช้หน่วยความจำ / การใช้งาน
เคล็ดลับ
ผู้ใช้ ClearML-Agent เพิ่ม [--pid=host] ในส่วน agent.extra_docker_arguments ของคุณในไฟล์ปรับแต่งของคุณ
สร้างคอนเทนเนอร์ของคุณเองและสืบทอดจากคอนเทนเนอร์ดั้งเดิม
คุณสามารถดูตัวอย่างบางส่วนได้ที่นี่
คอนเทนเนอร์ GPU แบบเศษส่วนสามารถใช้กับการดำเนินการแบบ Bare Metal เช่นเดียวกับ Kubernetes POD ใช่! ด้วยการใช้คอนเทนเนอร์ Fractional GPU คุณสามารถจำกัดการใช้หน่วยความจำของ Job/Pod ของคุณ และแบ่งปัน GPU ได้อย่างง่ายดายโดยไม่ต้องกลัวว่าหน่วยความจำจะพังกัน!
เทมเพลต Kubernetes POD ง่ายๆ มีดังนี้
apiVersion : v1
kind : Pod
metadata :
name : train-pod
labels :
app : trainme
spec :
hostPID : true
containers :
- name : train-container
image : clearml/fractional-gpu:u22-cu12.3-8gb
command : ['python3', '-c', 'print(f"Free GPU Memory: (free, global) {torch.cuda.mem_get_info()}")'] สำคัญ
คุณต้องรันพ็อดด้วย hostPID: true !
บันทึก
hostPID: true เพื่อให้ไดรเวอร์แยกความแตกต่างระหว่างกระบวนการของพ็อดและกระบวนการโฮสต์อื่น ๆ เมื่อจำกัดการใช้หน่วยความจำ / การใช้งาน
คอนเทนเนอร์รองรับไดรเวอร์ Nvidia <= 545.xx เราจะอัปเดตและสนับสนุนไดรเวอร์ใหม่ต่อไปเมื่อมีการเปิดตัวต่อไป
GPU ที่รองรับ : RTX ซีรีส์ 10, 20, 30, 40, ซีรีส์ A และ Data-Center P100, A100, A10/A40, L40/s, H100
ข้อจำกัด : ขณะนี้ยังไม่รองรับเครื่องโฮสต์ Windows หากสิ่งนี้สำคัญสำหรับคุณ โปรดฝากคำขอไว้ในส่วนปัญหา
ถาม : การรัน nvidia-smi ภายในคอนเทนเนอร์จะรายงานปริมาณการใช้ GPU ของกระบวนการในเครื่องหรือไม่
ตอบ : ใช่ nvidia-smi กำลังสื่อสารโดยตรงกับไดรเวอร์ระดับต่ำและรายงานทั้งหน่วยความจำ GPU คอนเทนเนอร์ที่แม่นยำตลอดจนข้อจำกัดของหน่วยความจำภายในคอนเทนเนอร์
ประกาศ การใช้งาน GPU จะเป็นการใช้งาน GPU ทั่วโลก (เช่น ฝั่งโฮสต์) ไม่ใช่การใช้งาน GPU ของคอนเทนเนอร์เฉพาะที่
ถาม : ฉันจะแน่ใจได้อย่างไรว่า Python / Pytorch / Tensorflow ของฉันมีหน่วยความจำจำกัดจริงๆ
ตอบ : สำหรับ PyTorch คุณสามารถเรียกใช้:
import torch
print ( f'Free GPU Memory: (free, global) { torch . cuda . mem_get_info () } ' )ตัวอย่างนัมบะ:
from numba import cuda
print ( f'Free GPU Memory: { cuda . current_context (). get_memory_info () } ' ) ถาม : ผู้ใช้สามารถทำลายข้อจำกัดได้หรือไม่?
ตอบ : เรามั่นใจว่าผู้ใช้ที่เป็นอันตรายจะหาทางได้ เราไม่เคยมีความตั้งใจที่จะป้องกันผู้ใช้ที่เป็นอันตราย
หากคุณมีผู้ใช้ที่เป็นอันตรายซึ่งสามารถเข้าถึงเครื่องของคุณได้ GPU แบบเศษส่วนไม่ใช่ปัญหาอันดับ 1 ของคุณใช่หรือไม่
ถาม : ฉันจะตรวจสอบข้อจำกัดของหน่วยความจำโดยทางโปรแกรมได้อย่างไร
ตอบ : คุณสามารถตรวจสอบตัวแปรสภาพแวดล้อมระบบปฏิบัติการ GPU_MEM_LIMIT_GB ได้
โปรดสังเกตว่าการเปลี่ยนแปลงจะไม่ลบหรือลดข้อจำกัด
ถาม : ใช้งานคอนเทนเนอร์ ด้วย --pid=host ปลอดภัย / ปลอดภัยหรือไม่
ตอบ : ควรทั้งปลอดภัยและปลอดภัย ข้อแม้หลักจากมุมมองด้านความปลอดภัยก็คือ กระบวนการคอนเทนเนอร์สามารถเห็นบรรทัดคำสั่งใดๆ ที่ทำงานบนระบบโฮสต์ได้ หากบรรทัดคำสั่งของกระบวนการมี "ความลับ" แสดงว่าใช่ นี่อาจทำให้ข้อมูลรั่วไหลได้ โปรดสังเกตว่าการส่ง "ความลับ" ในบรรทัดคำสั่งนั้นไม่เหมาะสม ดังนั้นเราจึงไม่ถือว่าเป็นความเสี่ยงด้านความปลอดภัย ดังที่กล่าวไว้ว่าหากการรักษาความปลอดภัยเป็นสิ่งสำคัญ รุ่นองค์กร (ดูด้านล่าง) จะขจัดความจำเป็นในการรันด้วย pid-host และทำให้มีความปลอดภัยอย่างเต็มที่
ถาม : คุณสามารถรันคอนเทนเนอร์ โดยไม่มี --pid=host ได้หรือไม่
ตอบ : คุณทำได้! แต่คุณจะต้องใช้คอนเทนเนอร์ clearml-fractional-gpu เวอร์ชันองค์กร (ไม่เช่นนั้น ขีดจำกัดหน่วยความจำจะใช้ทั้งระบบ แทนที่จะเป็นทั้งคอนเทนเนอร์) หากคุณสมบัตินี้สำคัญสำหรับคุณ โปรดติดต่อฝ่ายขายและฝ่ายสนับสนุนของ ClearML
ใบอนุญาตให้ใช้ ClearML นั้นมอบให้เพื่อวัตถุประสงค์ในการวิจัยหรือการพัฒนาเท่านั้น ClearML อาจนำไปใช้เพื่อการศึกษา ส่วนบุคคล หรือการใช้งานเชิงพาณิชย์ภายใน
ใบอนุญาตเชิงพาณิชย์แบบขยายสำหรับการใช้งานภายในผลิตภัณฑ์หรือบริการมีให้โดยเป็นส่วนหนึ่งของโซลูชัน ClearML Scale หรือ Enterprise
ClearML เสนอใบอนุญาตระดับองค์กรและเชิงพาณิชย์โดยเพิ่มคุณสมบัติเพิ่มเติมมากมายนอกเหนือจาก GPU แบบแยกส่วน ซึ่งรวมถึงการจัดการ คิวลำดับความสำคัญ การจัดการโควต้า แดชบอร์ดคลัสเตอร์การประมวลผล การจัดการชุดข้อมูลและการจัดการการทดสอบ รวมถึงการรักษาความปลอดภัยและการสนับสนุนระดับองค์กร เรียนรู้เพิ่มเติมเกี่ยวกับ ClearML Orchestration หรือพูดคุยกับเราโดยตรงที่ฝ่ายขาย ClearML
เล่าเรื่องนี้ให้ทุกคนฟัง! #ล้างMLFractionalGPU
เข้าร่วมช่อง Slack ของเรา
บอกเราเมื่อสิ่งต่างๆ ใช้งานไม่ได้ และช่วยเราแก้ไขข้อบกพร่องในหน้าปัญหา
สินค้าชิ้นนี้นำเสนอโดยทีมงาน ClearML พร้อมด้วย ❤️


