amazon bedrock rag
1.0.0
การดึงข้อมูล-Augmented Generation (RAG) เป็นกระบวนการเพิ่มประสิทธิภาพผลลัพธ์ของโมเดลภาษาขนาดใหญ่ ดังนั้นจึงอ้างอิงฐานความรู้ที่เชื่อถือได้นอกแหล่งข้อมูลการฝึกอบรมก่อนที่จะสร้างการตอบกลับ Large Language Models (LLM) ได้รับการฝึกอบรมเกี่ยวกับข้อมูลปริมาณมหาศาล และใช้พารามิเตอร์นับพันล้านรายการเพื่อสร้างผลลัพธ์ต้นฉบับสำหรับงานต่างๆ เช่น การตอบคำถาม การแปลภาษา และการเติมประโยคให้สมบูรณ์ RAG ขยายขีดความสามารถอันทรงพลังอยู่แล้วของ LLM ไปยังโดเมนเฉพาะหรือฐานความรู้ภายในขององค์กร โดยไม่จำเป็นต้องฝึกอบรมโมเดลใหม่ เป็นแนวทางที่คุ้มค่าในการปรับปรุงผลผลิต LLM ดังนั้นจึงยังคงมีความเกี่ยวข้อง ถูกต้อง และมีประโยชน์ในบริบทต่างๆ เรียนรู้เพิ่มเติมเกี่ยวกับ RAG ที่นี่
Amazon Bedrock เป็นบริการที่มีการจัดการเต็มรูปแบบซึ่งเสนอตัวเลือกโมเดลพื้นฐาน (FM) ที่มีประสิทธิภาพสูงจากบริษัท AI ชั้นนำ เช่น AI21 Labs, Anthropic, Cohere, Meta, Stability AI และ Amazon ผ่าน API เดียว พร้อมด้วยชุดของ ความสามารถที่คุณต้องการเพื่อสร้างแอปพลิเคชัน AI เชิงสร้างสรรค์ที่มีการรักษาความปลอดภัย ความเป็นส่วนตัว และ AI ที่มีความรับผิดชอบ เมื่อใช้ Amazon Bedrock คุณสามารถทดลองและประเมิน FM ชั้นนำสำหรับกรณีการใช้งานของคุณ ปรับแต่งข้อมูลของคุณแบบส่วนตัวโดยใช้เทคนิค เช่น การปรับแต่งแบบละเอียดและ RAG และสร้างตัวแทนที่ดำเนินงานโดยใช้ระบบองค์กรและแหล่งข้อมูลของคุณ เนื่องจาก Amazon Bedrock เป็นแบบไร้เซิร์ฟเวอร์ คุณจึงไม่จำเป็นต้องจัดการโครงสร้างพื้นฐานใดๆ และคุณสามารถรวมและปรับใช้ความสามารถ AI เชิงสร้างสรรค์ได้อย่างปลอดภัยในแอปพลิเคชันของคุณโดยใช้บริการของ AWS ที่คุณคุ้นเคยอยู่แล้ว
ฐานความรู้สำหรับ Amazon Bedrock คือความสามารถที่มีการจัดการเต็มรูปแบบ ซึ่งช่วยให้คุณปรับใช้เวิร์กโฟลว์ RAG ทั้งหมดตั้งแต่การนำเข้าไปจนถึงการดึงข้อมูลและการเพิ่มที่รวดเร็ว โดยไม่ต้องสร้างการผสานรวมแบบกำหนดเองกับแหล่งข้อมูลและจัดการโฟลว์ข้อมูล มีการจัดการบริบทเซสชันในตัว ดังนั้นแอปของคุณจึงสามารถรองรับการสนทนาแบบหลายรอบได้ทันที
ในส่วนของการสร้างฐานความรู้ คุณจะต้องกำหนดค่าแหล่งข้อมูลและที่เก็บเวกเตอร์ที่คุณเลือก ตัวเชื่อมต่อแหล่งข้อมูลช่วยให้คุณเชื่อมต่อข้อมูลที่เป็นกรรมสิทธิ์ของคุณกับฐานความรู้ เมื่อคุณกำหนดค่าตัวเชื่อมต่อแหล่งข้อมูลแล้ว คุณสามารถซิงค์หรือรักษาข้อมูลของคุณให้ทันสมัยอยู่เสมอด้วยฐานความรู้ของคุณ และทำให้ข้อมูลของคุณพร้อมสำหรับการสืบค้น ขั้นแรก Amazon Bedrock จะแบ่งเอกสารหรือเนื้อหาของคุณออกเป็นส่วนๆ ที่สามารถจัดการได้เพื่อการดึงข้อมูลที่มีประสิทธิภาพ จากนั้นชิ้นส่วนจะถูกแปลงเป็นการฝังและเขียนเป็นดัชนีเวกเตอร์ (การแสดงเวกเตอร์ของข้อมูล) ในขณะที่ยังคงการแมปกับเอกสารต้นฉบับ การฝังเวกเตอร์ช่วยให้สามารถเปรียบเทียบข้อความทางคณิตศาสตร์เพื่อความคล้ายคลึงกัน
โครงการนี้ดำเนินการโดยใช้แหล่งข้อมูลสองแหล่ง แหล่งข้อมูลสำหรับเอกสารที่จัดเก็บไว้ใน Amazon S3 และแหล่งข้อมูลอื่นสำหรับเนื้อหาที่เผยแพร่บนเว็บไซต์ คอลเลกชันการค้นหาเวกเตอร์ถูกสร้างขึ้นใน Amazon OpenSearch Serverless สำหรับพื้นที่จัดเก็บเวกเตอร์
ถาม-ตอบ แชทบอท 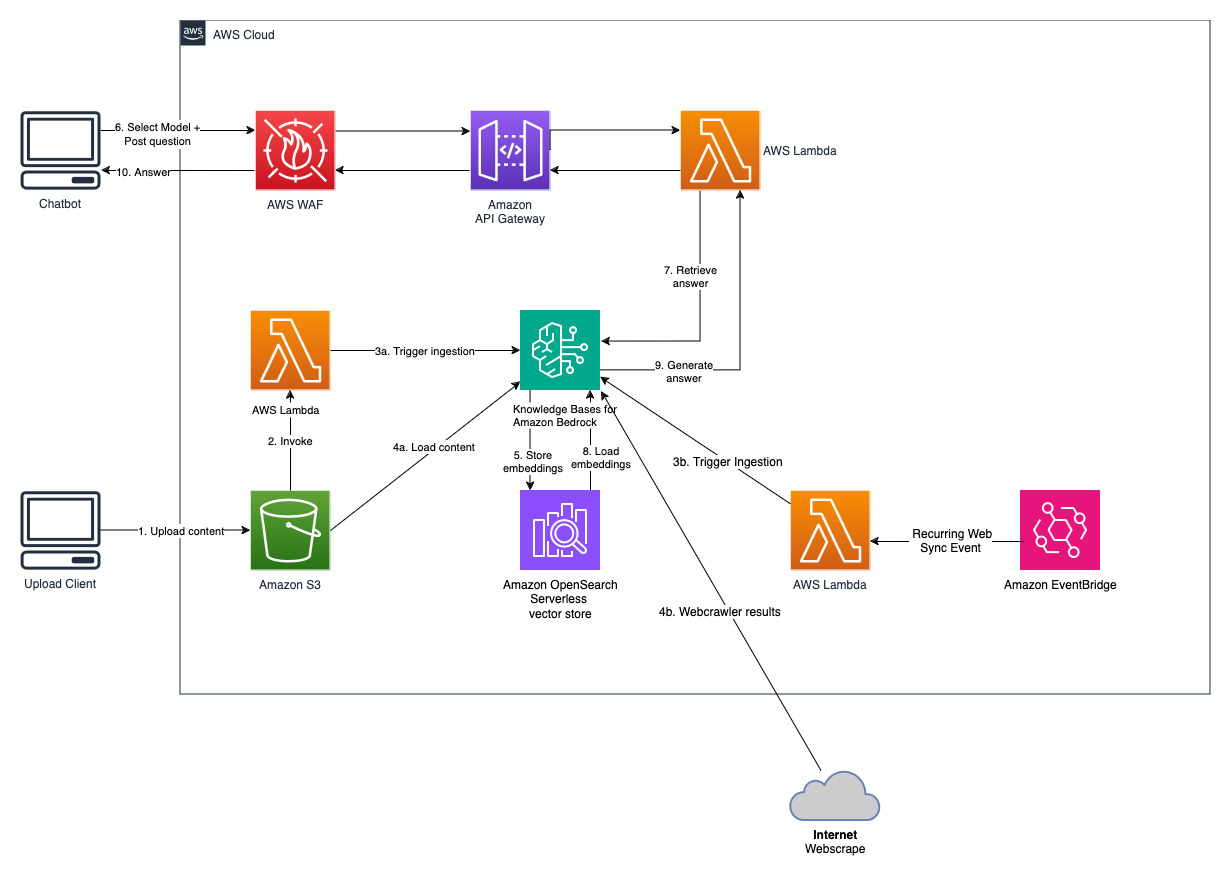
เพิ่มเว็บไซต์ใหม่สำหรับแหล่งข้อมูลบนเว็บ 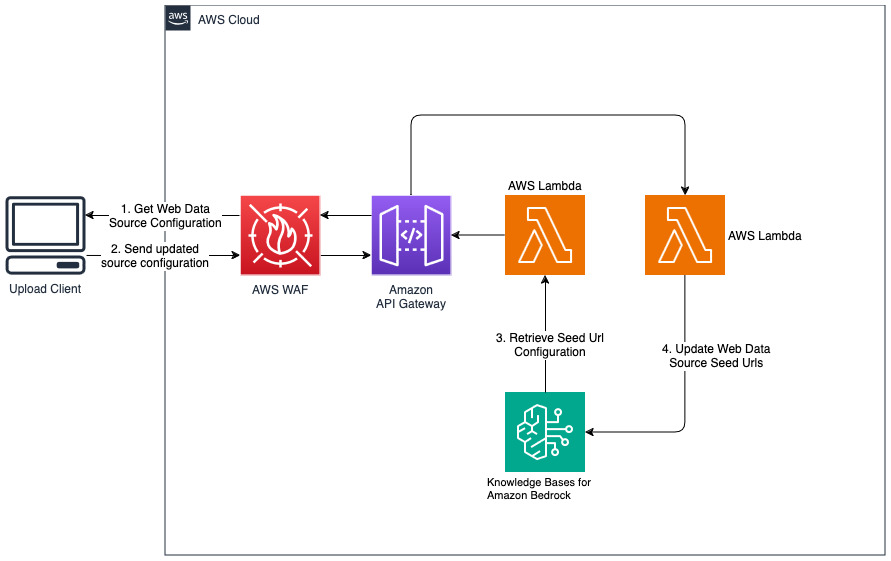
cdk deploy --context allowedip="xxx.xxx.xxx.xxx/32"
ระบุที่อยู่ IP ไคลเอ็นต์ที่ได้รับอนุญาตให้เข้าถึง API Gateway ในรูปแบบ CIDR โดยเป็นส่วนหนึ่งของตัวแปรบริบท 'allowedip'
เมื่อปรับใช้เสร็จสิ้น
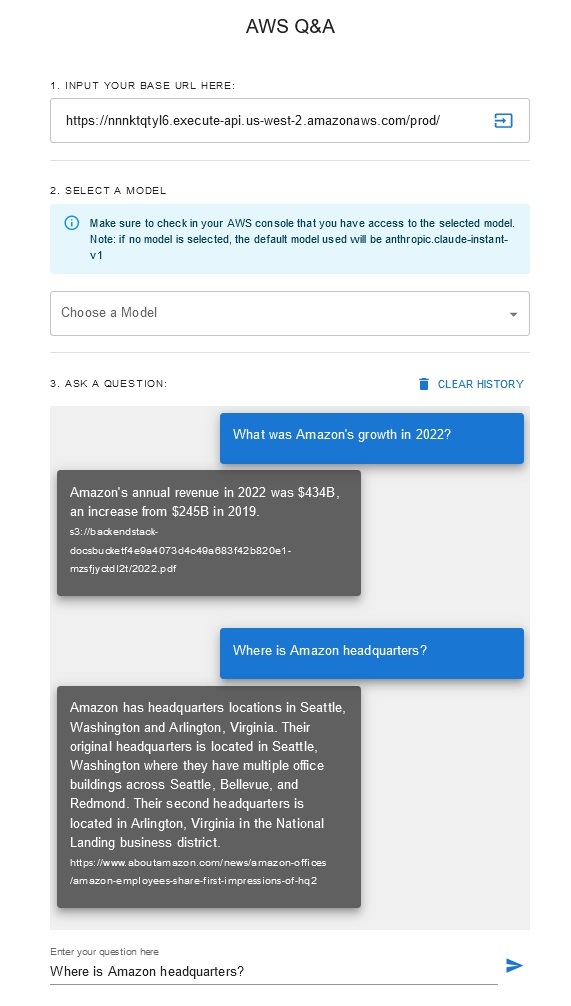
โซลูชันนี้ช่วยให้ผู้ใช้สามารถเลือกโมเดลพื้นฐานที่ต้องการใช้ในระหว่างขั้นตอนการดึงข้อมูลและการสร้าง โมเดลเริ่มต้นคือ Anthropic Claude Instant สำหรับโมเดลการฝังฐานความรู้ โซลูชันนี้ใช้ Amazon Titan Embeddings G1 - โมเดลข้อความ ตรวจสอบให้แน่ใจว่าคุณมีสิทธิ์เข้าถึงโมเดลพื้นฐานเหล่านี้
รับรายงานประจำปีของ Amazon ที่เปิดเผยต่อสาธารณะล่าสุด และคัดลอกไปยังชื่อบัคเก็ต S3 ที่ระบุไว้ก่อนหน้านี้ เพื่อการทดสอบอย่างรวดเร็ว คุณสามารถคัดลอกรายงานประจำปี 2022 ของ Amazon ได้โดยใช้ AWS S3 Console เนื้อหาจากบัคเก็ต S3 จะถูกซิงโครไนซ์กับฐานความรู้โดยอัตโนมัติ เนื่องจากการปรับใช้โซลูชันจะคอยดูเนื้อหาใหม่ในบัคเก็ต S3 และทริกเกอร์เวิร์กโฟลว์การนำเข้า
โซลูชันที่ปรับใช้จะเริ่มต้นแหล่งข้อมูลเว็บที่เรียกว่า "WebCrawlerDataSource" ด้วย URL https://www.aboutamazon.com/news/amazon-offices คุณต้องซิงโครไนซ์แหล่งข้อมูล Web Crawler นี้กับฐานความรู้จากคอนโซล AWS ด้วยตนเองเพื่อค้นหาเนื้อหาเว็บไซต์ เนื่องจากการนำเข้าเว็บไซต์มีกำหนดจะเกิดขึ้นในอนาคต เลือกแหล่งข้อมูลนี้จากคลังความรู้ตามคอนโซล Amazon Bedrock และเริ่มการดำเนินการ "ซิงค์" ดูการซิงค์แหล่งข้อมูลของคุณกับฐานความรู้ Amazon Bedrock ของคุณเพื่อดูรายละเอียด โปรดทราบว่าเนื้อหาเว็บไซต์จะพร้อมใช้งานสำหรับแชทบอทถามตอบหลังจากการซิงโครไนซ์เสร็จสิ้นเท่านั้น โปรดใช้คำแนะนำนี้เมื่อตั้งค่าเว็บไซต์เป็นแหล่งข้อมูล
ใช้ "cdk destroy" เพื่อลบสแต็กของทรัพยากรระบบคลาวด์ที่สร้างขึ้นในการปรับใช้โซลูชันนี้


