EasyNLU
1.0.0
EasyNLU คือไลบรารีความเข้าใจภาษาธรรมชาติ (NLU) ที่เขียนด้วยภาษา Java สำหรับแอปบนมือถือ เนื่องจากอิงตามไวยากรณ์ จึงเหมาะสำหรับโดเมนที่แคบแต่ต้องมีการควบคุมที่เข้มงวด
โปรเจ็กต์นี้มีแอปพลิเคชัน Android ตัวอย่างที่สามารถกำหนดเวลาการแจ้งเตือนจากการป้อนภาษาธรรมชาติได้:
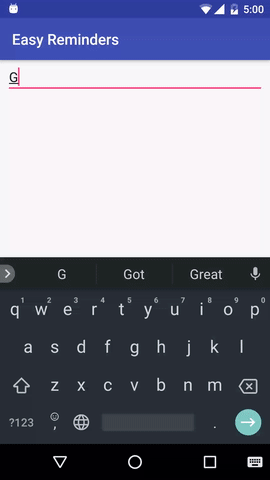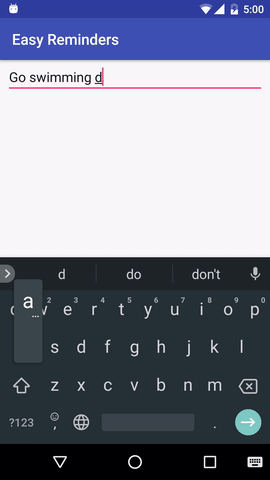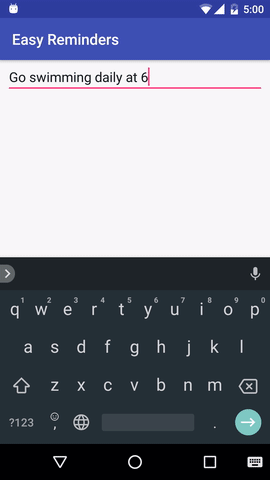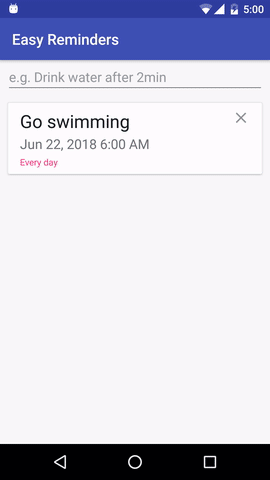
EasyNLU ได้รับอนุญาตภายใต้ Apache 2.0
แกนหลักของ EasyNLU คือตัวแยกวิเคราะห์ความหมายที่ใช้ CCG คุณสามารถดูคำแนะนำที่ดีในการแยกวิเคราะห์ความหมายได้ที่นี่ semantic parser สามารถแยกวิเคราะห์อินพุตเช่น:
พรุ่งนี้ไปหาหมอฟันเวลา 17.00 น
ให้อยู่ในรูปแบบที่มีโครงสร้าง:
{task: "Go to the dentist", startTime:{offset:{day:1}, hour:5, shift:"pm"}}
EasyNLU จัดเตรียมรูปแบบที่มีโครงสร้างเป็นแผนที่ Java แบบเรียกซ้ำ แบบฟอร์มที่มีโครงสร้างนี้สามารถแก้ไขได้เป็นวัตถุเฉพาะงานที่ถูก 'ดำเนินการ' เช่น ในโปรเจ็กต์ตัวอย่าง แบบฟอร์มที่มีโครงสร้างได้รับการแก้ไขเป็นออบเจ็กต์ Reminder ซึ่งมีฟิลด์ต่างๆ เช่น task startTime และ repeat และใช้ในการตั้งค่าการเตือนด้วยบริการ AlarmManager
โดยทั่วไปต่อไปนี้เป็นขั้นตอนระดับสูงในการตั้งค่าความสามารถของ NLU:
ก่อนที่จะเขียนกฎใดๆ เราควรกำหนดขอบเขตของงานและพารามิเตอร์ของแบบฟอร์มที่มีโครงสร้าง ตามตัวอย่างของเล่น สมมติว่างานของเราคือการเปิดและปิดคุณสมบัติของโทรศัพท์ เช่น บลูทูธ, Wifi และ GPS ดังนั้นเขตข้อมูลคือ:
ตัวอย่างแบบฟอร์มที่มีโครงสร้างจะเป็น:
{feature: "bluetooth", action: "enable" }
นอกจากนี้ การมีอินพุตตัวอย่างบางส่วนเพื่อทำความเข้าใจรูปแบบต่างๆ ยังช่วยได้:
ดำเนินการต่อจากตัวอย่างของเล่น เราสามารถพูดได้ว่าที่ระดับบนสุด เรามีการกระทำการตั้งค่าที่ต้องมีคุณสมบัติและการกระทำ จากนั้นเราใช้กฎเพื่อรวบรวมข้อมูลนี้:
Rule r1 = new Rule ( "$Setting" , "$Feature $Action" );
Rule r2 = new Rule ( "$Setting" , "$Action $Feature" ); กฎประกอบด้วย LHS และ RHS เป็นอย่างน้อย ตามแบบแผน เราจะเติม '$' ไว้หน้าคำเพื่อระบุหมวดหมู่ หมวดหมู่แสดงถึงชุดของคำหรือหมวดหมู่อื่นๆ ในกฎข้างต้น $Feature แสดงถึงคำต่างๆ เช่น bluetooth, bt, wifi ฯลฯ ที่เราบันทึกโดยใช้กฎ 'คำศัพท์':
List < Rule > lexicals = Arrays . asList (
new Rule ( "$Feature" , "bluetooth" ),
new Rule ( "$Feature" , "bt" ),
new Rule ( "$Feature" , "wifi" ),
new Rule ( "$Feature" , "gps" ),
new Rule ( "$Feature" , "location" ),
); เพื่อปรับรูปแบบต่างๆ ในชื่อคุณลักษณะให้เป็นมาตรฐาน เราจึงจัดโครงสร้าง $Features ให้เป็นคุณลักษณะย่อย:
List < Rule > featureRules = Arrays . asList (
new Rule ( "$Feature" , "$Bluetooth" ),
new Rule ( "$Feature" , "$Wifi" ),
new Rule ( "$Feature" , "$Gps" ),
new Rule ( "$Bluetooth" , "bt" ),
new Rule ( "$Bluetooth" , "bluetooth" ),
new Rule ( "$Wifi" , "wifi" ),
new Rule ( "$Gps" , "gps" ),
new Rule ( "$Gps" , "location" )
); คล้ายกันสำหรับ $Action :
List < Rule > actionRules = Arrays . asList (
new Rule ( "$Action" , "$EnableDisable" ),
new Rule ( "$EnableDisable" , "?$Switch $OnOff" ),
new Rule ( "$EnableDisable" , "$Enable" ),
new Rule ( "$EnableDisable" , "$Disable" ),
new Rule ( "$OnOff" , "on" ),
new Rule ( "$OnOff" , "off" ),
new Rule ( "$Switch" , "switch" ),
new Rule ( "$Switch" , "turn" ),
new Rule ( "$Enable" , "enable" ),
new Rule ( "$Disable" , "disable" ),
new Rule ( "$Disable" , "kill" )
); หมายเหตุ '?' ในกฎข้อที่สาม ซึ่งหมายความว่าหมวดหมู่ $Switch เป็นทางเลือก เพื่อตรวจสอบว่าการแยกวิเคราะห์สำเร็จหรือไม่ parser จะค้นหาหมวดหมู่พิเศษที่เรียกว่าหมวดหมู่รูท ตามแบบแผนจะแสดงเป็น $ROOT เราจำเป็นต้องเพิ่มกฎเพื่อเข้าถึงหมวดหมู่นี้:
Rule root = new Rule ( "$ROOT" , "$Setting" );ด้วยชุดกฎเหล่านี้ parser ของเราควรจะสามารถแยกวิเคราะห์ตัวอย่างข้างต้นได้ โดยแปลงให้เป็นสิ่งที่เรียกว่าแผนผังไวยากรณ์
การแยกวิเคราะห์ไม่ดีถ้าเราไม่สามารถแยกความหมายของประโยคได้ ความหมายนี้ถูกจับโดยรูปแบบที่มีโครงสร้าง (รูปแบบลอจิกในศัพท์แสง NLP) ใน EasyNLU เราส่งผ่านพารามิเตอร์ตัวที่สามในคำจำกัดความของกฎเพื่อกำหนดวิธีการแยกซีแมนทิกส์ เราใช้ไวยากรณ์ JSON พร้อมเครื่องหมายพิเศษเพื่อทำสิ่งนี้:
new Rule ( "$Action" , "$EnableDisable" , "{action:@first}" ), @first บอกให้ parser เลือกค่าของหมวดหมู่แรกของกฎ RHS ในกรณีนี้ จะเป็น 'เปิดใช้งาน' หรือ 'ปิดใช้งาน' ตามประโยค เครื่องหมายอื่นๆ ได้แก่:
@identity : ฟังก์ชันตัวตน@last : เลือกค่าของหมวดหมู่ RHS สุดท้าย@N : เลือกค่าของหมวดหมู่ N th RHS เช่น @3 จะเลือกอันที่ 3@merge : รวมค่าของทุกหมวดหมู่ เฉพาะค่าที่มีชื่อ (เช่น {action: enable} ) เท่านั้นที่จะถูกรวมเข้าด้วยกัน@append : ผนวกค่าของหมวดหมู่ทั้งหมดลงในรายการ จะต้องตั้งชื่อรายการผลลัพธ์ อนุญาตเฉพาะค่าที่มีชื่อเท่านั้นหลังจากเพิ่มเครื่องหมายความหมาย กฎของเราจะกลายเป็น:
List < Rule > rules = Arrays . asList (
new Rule ( "$ROOT" , "$Setting" , "@identity" ),
new Rule ( "$Setting" , "$Feature $Action" , "@merge" ),
new Rule ( "$Setting" , "$Action $Feature" , "@merge" ),
new Rule ( "$Feature" , "$Bluetooth" , "{feature: bluetooth}" ),
new Rule ( "$Feature" , "$Wifi" , "{feature: wifi}" ),
new Rule ( "$Feature" , "$Gps" , "{feature: gps}" ),
new Rule ( "$Bluetooth" , "bt" ),
new Rule ( "$Bluetooth" , "bluetooth" ),
new Rule ( "$Wifi" , "wifi" ),
new Rule ( "$Gps" , "gps" ),
new Rule ( "$Gps" , "location" ),
new Rule ( "$Action" , "$EnableDisable" , "{action: @first}" ),
new Rule ( "$EnableDisable" , "?$Switch $OnOff" , "@last" ),
new Rule ( "$EnableDisable" , "$Enable" , "enable" ),
new Rule ( "$EnableDisable" , "$Disable" , "disable" ),
new Rule ( "$OnOff" , "on" , "enable" ),
new Rule ( "$OnOff" , "off" , "disable" ),
new Rule ( "$Switch" , "switch" ),
new Rule ( "$Switch" , "turn" ),
new Rule ( "$Enable" , "enable" ),
new Rule ( "$Disable" , "disable" ),
new Rule ( "$Disable" , "kill" )
);หากไม่ได้ระบุพารามิเตอร์ซีแมนทิกส์ parser จะสร้างค่าเริ่มต้นเท่ากับ RHS
หากต้องการรัน parser clone ที่เก็บข้อมูลนี้และนำเข้าโมดูล parser ไปยังโปรเจ็กต์ Android Studio/IntelliJ ของคุณ โปรแกรมแยกวิเคราะห์ EasyNLU ใช้อ็อบเจ็กต์ Grammar ที่เก็บกฎ ออบเจ็กต์ Tokenizer เพื่อแปลงประโยคอินพุตเป็นคำ และรายการเสริมของอ็อบเจ็กต์ Annotator เพื่อใส่คำอธิบายประกอบเอนทิตี เช่น ตัวเลข วันที่ สถานที่ ฯลฯ รันโค้ดต่อไปนี้หลังจากกำหนดกฎ:
Grammar grammar = new Grammar ( rules , "$ROOT" );
Parser parser = new Parser ( grammar , new BasicTokenizer (), Collections . emptyList ());
System . out . println ( parser . parse ( "kill bt" ));
System . out . println ( parser . parse ( "wifi on" ));
System . out . println ( parser . parse ( "enable location" ));
System . out . println ( parser . parse ( "turn off GPS" ));คุณควรได้รับผลลัพธ์ต่อไปนี้:
23 rules
[{feature=bluetooth, action=disable}]
[{feature=wifi, action=enable}]
[{feature=gps, action=enable}]
[{feature=gps, action=disable}]
ลองใช้รูปแบบอื่นๆ หากการแยกวิเคราะห์ล้มเหลวสำหรับตัวแปรตัวอย่าง คุณจะไม่ได้รับผลลัพธ์ จากนั้นคุณสามารถเพิ่มหรือแก้ไขกฎและทำซ้ำกระบวนการทางวิศวกรรมไวยากรณ์ได้
EasyNLU รองรับรายการในรูปแบบที่มีโครงสร้างแล้ว สำหรับโดเมนข้างต้นสามารถจัดการอินพุตได้เช่น
ปิดการใช้งานตำแหน่ง bt gps
เพิ่มกฎพิเศษ 3 ข้อนี้ลงในไวยากรณ์ด้านบน:
new Rule("$Setting", "$Action $FeatureGroup", "@merge"),
new Rule("$FeatureGroup", "$Feature $Feature", "{featureGroup: @append}"),
new Rule("$FeatureGroup", "$FeatureGroup $Feature", "{featureGroup: @append}"),
เรียกใช้แบบสอบถามใหม่เช่น:
System.out.println(parser.parse("disable location bt gps"));
คุณควรได้รับผลลัพธ์นี้:
[{action=disable, featureGroup=[{feature=gps}, {feature=bluetooth}, {feature=gps}]}]
โปรดทราบว่ากฎเหล่านี้จะถูกทริกเกอร์ก็ต่อเมื่อมีฟีเจอร์มากกว่าหนึ่งรายการในการสืบค้น
คำอธิบายประกอบทำให้ง่ายขึ้นสำหรับโทเค็นบางประเภทที่อาจยุ่งยากหรือเป็นไปไม่ได้เลยที่จะจัดการตามกฎ ตัวอย่างเช่น ใช้คลาส NumberAnnotator มันจะตรวจจับและใส่คำอธิบายประกอบตัวเลขทั้งหมดเป็น $NUMBER จากนั้น คุณสามารถอ้างอิงหมวดหมู่ในกฎของคุณได้โดยตรง เช่น:
Rule r = new Rule("$Conversion", "$Convert $NUMBER $Unit $To $Unit", "{convertFrom: {unit: @2, quantity: @1}, convertTo: {unit: @last}}"
ปัจจุบัน EasyNLU มาพร้อมกับคำอธิบายประกอบบางส่วน:
NumberAnnotator : คำอธิบายประกอบตัวเลขDateTimeAnnotator : ใส่คำอธิบายประกอบรูปแบบวันที่บางรูปแบบ ยังมีกฎของตัวเองที่คุณเพิ่มโดยใช้ DateTimeAnnotator.rules()TokenAnnotator : อธิบายแต่ละโทเค็นของอินพุตเป็น $TOKENPhraseAnnotator : ใส่คำอธิบายประกอบแต่ละวลีที่ต่อเนื่องกันของอินพุตเป็น $PHRASE หากต้องการใช้คำอธิบายประกอบที่คุณกำหนดเอง ให้ใช้อินเทอร์เฟซ Annotator ประกอบและส่งผ่านไปยัง parser อ้างอิงคำอธิบายประกอบที่สร้างขึ้นเพื่อรับทราบวิธีการใช้งาน
EasyNLU รองรับกฎการโหลดจากไฟล์ข้อความ แต่ละกฎจะต้องอยู่ในบรรทัดแยกกัน LHS, RHS และซีแมนทิกส์ต้องคั่นด้วยแท็บ:
$EnableDisable ?$Switch $OnOff @last
ระวังอย่าใช้ IDE ที่แปลงแท็บเป็นช่องว่างโดยอัตโนมัติ
เมื่อมีการเพิ่มกฎเพิ่มเติมให้กับ parser คุณจะพบว่า parser พบหลาย parses สำหรับอินพุตบางอย่าง นี่เป็นเพราะความคลุมเครือโดยทั่วไปของภาษามนุษย์ หากต้องการทราบว่า parser สำหรับงานของคุณมีความแม่นยำเพียงใด คุณต้องดำเนินการโดยใช้ตัวอย่างที่มีป้ายกำกับ
เช่นเดียวกับกฎก่อนหน้านี้ EasyNLU ใช้ตัวอย่างที่กำหนดเป็นข้อความธรรมดา แต่ละบรรทัดควรเป็นตัวอย่างที่แยกจากกัน และควรมีข้อความดิบและรูปแบบที่มีโครงสร้างคั่นด้วยแท็บ:
take my medicine at 4pm {task:"take my medicine", startTime:{hour:4, shift:"pm"}}
สิ่งสำคัญคือคุณต้องครอบคลุมตัวเลขหรือรูปแบบที่ยอมรับได้ในอินพุต คุณจะได้รับความหลากหลายมากขึ้นหากมีคนต่างกันมาทำภารกิจนี้ จำนวนตัวอย่างขึ้นอยู่กับความซับซ้อนของโดเมน ชุดข้อมูลตัวอย่างที่ให้ไว้ในโปรเจ็กต์นี้มีตัวอย่างมากกว่า 100 รายการ
เมื่อคุณมีข้อมูลแล้ว คุณก็สามารถนำข้อมูลนั้นไปรวมไว้ในชุดข้อมูลได้ ส่วนการเรียนรู้ได้รับการจัดการโดยโมดูล trainer นำเข้าสู่โครงการของคุณ โหลดชุดข้อมูลดังนี้:
Dataset dataset = Dataset . fromText ( 'filename.txt' )เราประเมิน parser เพื่อพิจารณาความถูกต้องสองประเภท
ในการรันการประเมินเราใช้คลาส Model :
Model model = new Model(parser);
model.evaluate(dataset, 2);
พารามิเตอร์ตัวที่ 2 ของฟังก์ชันประเมินผลคือระดับรายละเอียด ยิ่งตัวเลขมาก ก็ยิ่งละเอียดมากขึ้น ฟังก์ชัน evaluate() ที่มีการรัน parser ผ่านแต่ละตัวอย่างและแสดงการแยกวิเคราะห์ที่ไม่ถูกต้องในที่สุดก็แสดงความแม่นยำ หากคุณได้รับความแม่นยำทั้งสองอย่างในช่วงยุค 90 การฝึกอบรมก็ไม่จำเป็น คุณอาจจัดการกับการแยกวิเคราะห์ที่ไม่ดีเหล่านั้นด้วยการประมวลผลภายหลัง หากความแม่นยำของออราเคิลสูงแต่ความแม่นยำในการทำนายต่ำ การฝึกอบรมระบบจะช่วยได้ หากความแม่นยำของ Oracle นั้นต่ำ คุณจะต้องทำวิศวกรรมไวยากรณ์เพิ่มเติม
เพื่อให้ได้การแยกวิเคราะห์ที่ถูกต้อง เราจะให้คะแนนและเลือกอันที่มีคะแนนสูงสุด EasyNLU ใช้แบบจำลองเชิงเส้นอย่างง่ายในการคำนวณคะแนน การฝึกอบรมดำเนินการโดยใช้ Stochastic Gradient Descent (SGD) พร้อมฟังก์ชันการสูญเสียบานพับ คุณลักษณะอินพุตจะขึ้นอยู่กับจำนวนกฎและฟิลด์ในรูปแบบที่มีโครงสร้าง ตุ้มน้ำหนักที่ฝึกแล้วจะถูกบันทึกลงในไฟล์ข้อความ
คุณสามารถปรับแต่งพารามิเตอร์โมเดล/การฝึกบางส่วนเพื่อให้ได้ความแม่นยำมากขึ้น สำหรับโมเดลการแจ้งเตือน มีการใช้พารามิเตอร์ต่อไปนี้:
HParams hparams = HParams . hparams ()
. withLearnRate ( 0.08f )
. withL2Penalty ( 0.01f )
. set ( SVMOptimizer . CORRECT_PROB , 0.4f );เรียกใช้รหัสการฝึกอบรมดังต่อไปนี้:
Experiment experiment = new Experiment ( model , dataset , hparams , "yourdomain.weights" );
experiment . train ( 100 , false );สิ่งนี้จะฝึกโมเดลสำหรับ 100 ยุคด้วยการแบ่งการทดสอบรถไฟ 0.8 มันจะแสดงความแม่นยำของชุดทดสอบและบันทึกน้ำหนักแบบจำลองลงในเส้นทางไฟล์ที่ให้ไว้ หากต้องการฝึกชุดข้อมูลทั้งหมด ให้ตั้งค่าพารามิเตอร์การปรับใช้เป็นจริง คุณสามารถเรียกใช้โหมดโต้ตอบโดยรับอินพุตจากคอนโซล:
experiement.interactive();
หมายเหตุ: การฝึกอบรมดังกล่าวไม่รับประกันว่าจะมีความแม่นยำสูงแม้จะมีตัวอย่างจำนวนมากก็ตาม สำหรับบางสถานการณ์ คุณสมบัติที่ให้มาอาจไม่เลือกปฏิบัติเพียงพอ หากคุณติดอยู่ในกรณีดังกล่าว โปรดบันทึกปัญหา แล้วเราจะค้นหาคุณสมบัติเพิ่มเติมได้
ตุ้มน้ำหนักโมเดลเป็นไฟล์ข้อความธรรมดา สำหรับโครงการ Android คุณสามารถวางไว้ในโฟลเดอร์ assets และโหลดโดยใช้ AssetManager โปรดดู ReminderNlu.java สำหรับรายละเอียดเพิ่มเติม คุณยังสามารถจัดเก็บน้ำหนักและกฎเกณฑ์ของคุณไว้ในคลาวด์และอัปเดตโมเดลของคุณแบบไร้สายได้ (มีใครใช้ Firebase บ้างไหม)
เมื่อ parser ทำงานได้ดีในการแปลงอินพุตภาษาธรรมชาติเป็นรูปแบบที่มีโครงสร้าง คุณอาจต้องการข้อมูลนั้นในวัตถุเฉพาะงาน สำหรับบางโดเมน เช่น ตัวอย่างของเล่นด้านบน อาจตรงไปตรงมา สำหรับคนอื่นๆ คุณอาจต้องแก้ไขการอ้างอิงถึงสิ่งต่างๆ เช่น วันที่ สถานที่ รายชื่อติดต่อ ฯลฯ ในตัวอย่างการแจ้งเตือน วันที่มักจะเป็นแบบสัมพัทธ์ (เช่น 'พรุ่งนี้' 'หลังจาก 2 ชั่วโมง' ฯลฯ) ซึ่งจำเป็นต้องแปลงเป็นค่าสัมบูรณ์ โปรดดู ArgumentResolver.java เพื่อดูว่าการแก้ปัญหาเสร็จสิ้นแล้ว
เคล็ดลับ: ใช้ตรรกะในการแก้ปัญหาให้น้อยที่สุดเมื่อกำหนดกฎ และทำส่วนใหญ่ในการประมวลผลภายหลัง มันจะทำให้กฎง่ายขึ้น


