เครื่องยนต์ดึงข้อมูล Meme
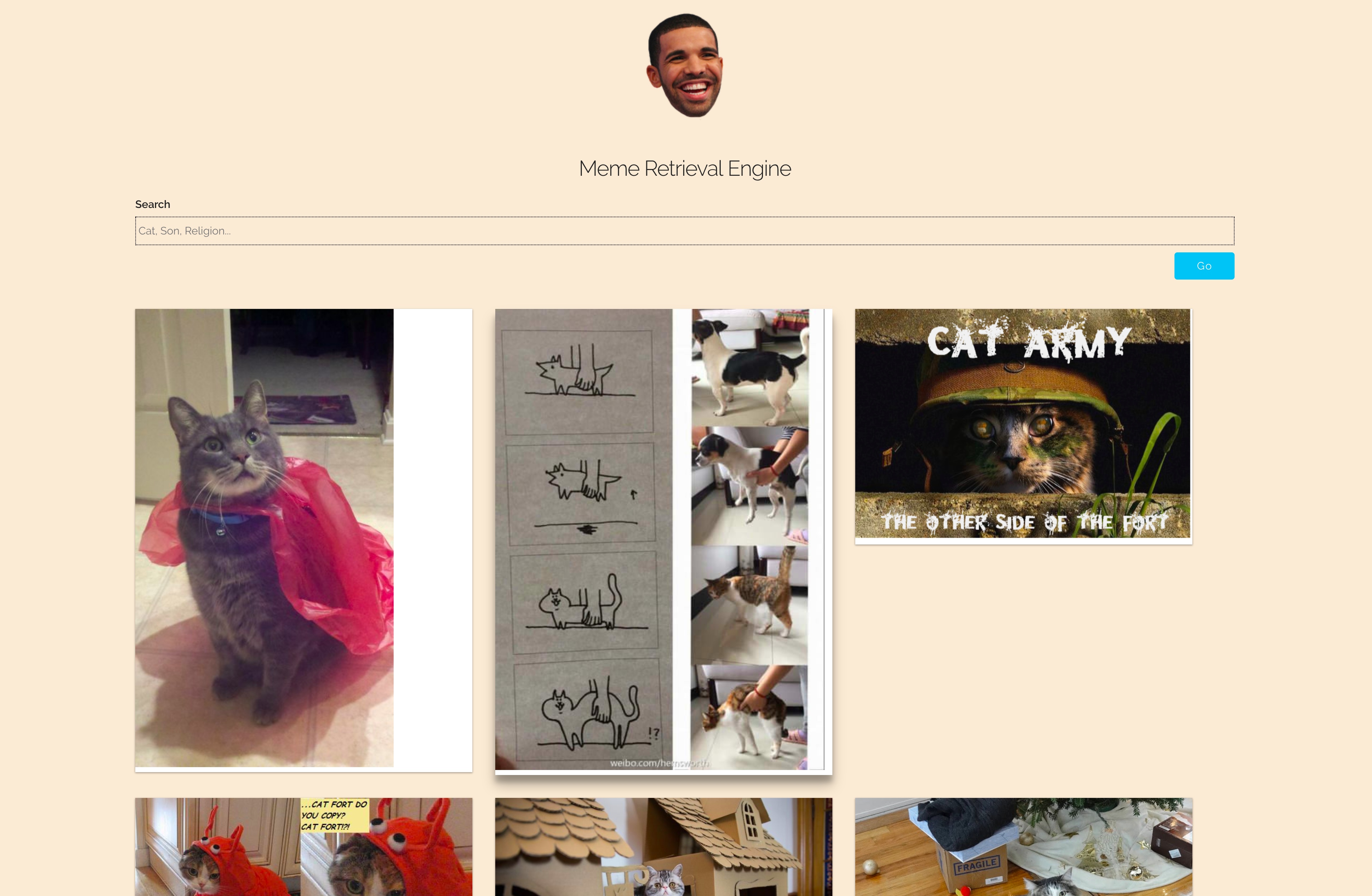
รายละเอียดโครงการ
เทคโนโลยีที่ใช้
- การประมวลผลภาพ
- การเรียนรู้ของเครื่อง
- การประมวลผลภาษาธรรมชาติ
- การเขียนสคริปต์เชลล์
ของสะสม
มีมถูกรวบรวมจาก subreddits ยอดนิยมโดยใช้สคริปต์ขูด scrape/scraper.py
การทำให้เป็นมาตรฐาน
- มส์ที่รวบรวมจะถูกใส่ไว้ในโฟลเดอร์
raw และเรียกใช้สคริปต์ standard.py - ชื่อไฟล์แต่ละชื่อจะถูกแยกและจัดเก็บไว้ในไฟล์ข้อความถัดจากชื่อไฟล์ฐานสิบหกใหม่ที่สร้างขึ้นสำหรับรูปภาพ
- รูปภาพมาตรฐานจะถูกจัดเก็บไว้ในโฟลเดอร์
processed
การแยกแบบสอบถาม
- ข้อความค้นหาที่ป้อนจะถูกแบ่งออกเป็นคำและคำพ้องความหมายสำหรับแต่ละคำจะถูกเพิ่มลงในรายการ
related queries โดยใช้ไลบรารี nltk - เราสแกนฐานข้อมูลเพื่อจับคู่คำกับคำใน
related queries - สิ่งนี้จะขยายพื้นที่การค้นหาและลดสถานการณ์เอาต์พุตเป็นศูนย์ให้เหลือน้อยที่สุด
ความเกี่ยวข้องกับแบบสอบถาม
- มีมเรียงลำดับตามความเกี่ยวข้องกับคำค้นหา
- ทำได้โดยการกำหนดคะแนนให้กับแต่ละมีมที่มีอยู่ในฐานข้อมูล จากนั้นเรียงลำดับคะแนนจากมากไปน้อย
การรู้จำอักขระด้วยแสง
- OCR เสร็จสิ้นโดยใช้ Tesseract เพื่อแยกข้อความจากมีมซึ่งเป็นส่วนสำคัญของโปรเจ็กต์
- ข้อความที่แยกออกมานั้นไม่ถูกต้องอย่างสมบูรณ์ ดังนั้นเอาต์พุตจาก ocr จะถูกป้อนเข้าไปในเครื่องตรวจสอบการสะกดของไลบรารี
autocorrect ของ Python - เครื่องตรวจการสะกดทำให้การแปลงมีความแม่นยำมากขึ้น
การทดสอบอย่างรวดเร็ว
หากต้องการเรียกใช้ GUI และทดสอบฟังก์ชันการทำงาน เพียงพิมพ์
รวบรวมและเรียกใช้
- เพื่อรวบรวมมีมจาก subreddits
- สคริปต์ทุบตีเตรียมฐานข้อมูลซึ่งช่วยให้ Meme Engine ทำงานได้อย่างถูกต้อง
- หากต้องการเรียกใช้ประเภท Meme Retrieval Engine (Meme Finder)
- ป้อนคำค้นหาในช่องข้อความแล้วคลิก
Go - มส์จะถูกจัดเรียงตามความเกี่ยวข้อง
- สามารถเรียกดูมส์ที่เลือกได้โดยใช้ปุ่ม
Next และ Previous
เพิ่ม subreddits ใหม่ลงในรายการ
ความต้องการ
- cv2 (โอเพ่นซีวี)
- ไพเทสเซอร์แรค
- ไม่ทราบ
- พิล
- แฮชลิบ
- ชูทิล
- แก้ไขอัตโนมัติ
- ไพมอนโก
การปรับปรุงในอนาคต
- การเพิ่มฟังก์ชันการทำงานให้กับแถบความคืบหน้า
- แก้ไขมาตราส่วนขนาดของมส์เพื่อแสดงบนผืนผ้าใบ
- การเพิ่มคุณสมบัติเพื่อล้างมส์ที่เก็บไว้
- การจัดเก็บเทมเพลตมีมยอดนิยมและตรวจสอบภาพเพื่อความคล้ายคลึงและเชื่อมโยงคำหลักพิเศษ
เอกสารประกอบ
เอกสาร MemeFinder


