idt
1.0.0

เครื่องมือชุดข้อมูลรูปภาพ (IDT) คือแอป CLI ที่พัฒนาขึ้นเพื่อให้สร้างชุดข้อมูลรูปภาพเพื่อใช้สำหรับการเรียนรู้เชิงลึกได้ง่ายและรวดเร็วยิ่งขึ้น เครื่องมือนี้ทำได้โดยการคัดลอกรูปภาพจากเครื่องมือค้นหาต่างๆ เช่น duckgo, bing และ deviantart IDT ยังปรับชุดข้อมูลรูปภาพให้เหมาะสม แม้ว่าฟีเจอร์นี้จะเป็นทางเลือก แต่ผู้ใช้สามารถลดขนาดและบีบอัดรูปภาพเพื่อให้ได้ขนาดและขนาดไฟล์ที่เหมาะสมที่สุด ชุดข้อมูลตัวอย่างที่สร้างโดยใช้ idt ซึ่งมีไฟล์ภาพทั้งหมด 23.688 ไฟล์ มีน้ำหนักเพียง 559.2 เมกะไบต์
ฉันภูมิใจที่จะประกาศเวอร์ชันใหม่ล่าสุดของเรา! -
สิ่งที่เปลี่ยนแปลงไป
คุณสามารถติดตั้งผ่าน pip หรือโคลนพื้นที่เก็บข้อมูลนี้
user@admin:~ $ pip3 install idt
หรือ
user@admin:~ $ git clone https://github.com/deliton/idt.git && cd idt
user@admin:~/idt $ sudo python3 setup.py install
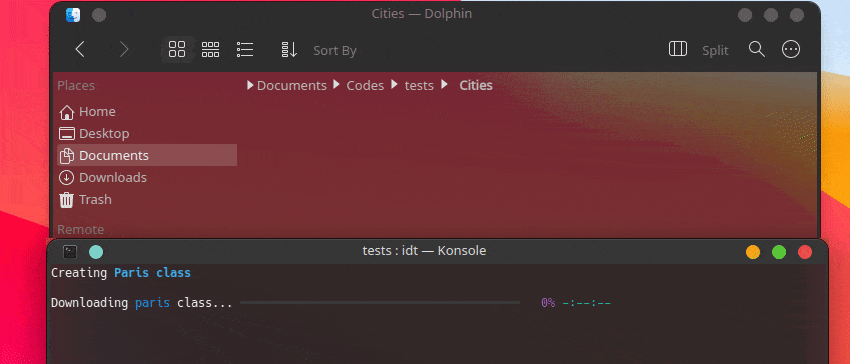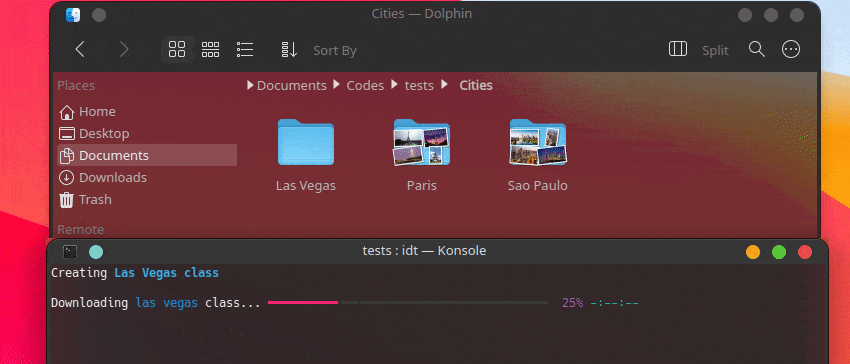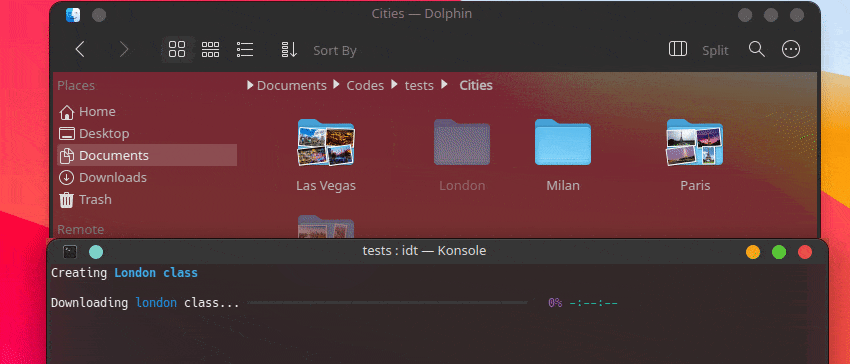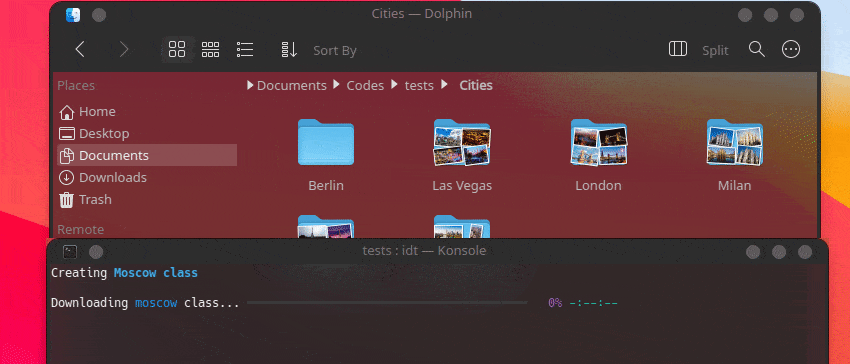
วิธีที่เร็วที่สุดในการเริ่มต้นใช้งาน IDT คือการเรียกใช้คำสั่ง "run" แบบง่ายๆ เพียงเขียนลงในคอนโซลที่คุณชื่นชอบเช่น:
user@admin:~ $ idt run -i apples การดำเนินการนี้จะดาวน์โหลดรูปภาพแอปเปิ้ล 50 รูปอย่างรวดเร็ว ตามค่าเริ่มต้นจะใช้เครื่องมือค้นหา Duckgo เพื่อดำเนินการดังกล่าว คำสั่ง run ยอมรับตัวเลือกต่อไปนี้:
| ตัวเลือก | คำอธิบาย |
|---|---|
| -i หรือ --input | คำสำคัญเพื่อค้นหาภาพที่ต้องการ |
| -s หรือ --size | จำนวนภาพที่จะดาวน์โหลด |
| -e หรือ --engine | เครื่องมือค้นหาที่ต้องการ (ตัวเลือก: duckgo, bing, bing_api และ flickr_api) |
| --resize-method | เลือกวิธีการปรับขนาดรูปภาพ (ตัวเลือก: long_side, shorter_side และ smartcrop) |
| -is หรือ --image-size | ตัวเลือกเพื่อกำหนดอัตราส่วนขนาดภาพที่ต้องการ ค่าเริ่มต้น=512 |
| -ak หรือ --api-key | หากคุณใช้เครื่องมือค้นหาที่ต้องใช้คีย์ API จำเป็นต้องใช้ตัวเลือกนี้ |
IDT ต้องใช้ไฟล์กำหนดค่าที่บอกว่าชุดข้อมูลของคุณควรจัดระเบียบอย่างไร คุณสามารถสร้างมันขึ้นมาได้โดยใช้คำสั่งต่อไปนี้:
user@admin:~ $ idt initคำสั่งนี้จะทริกเกอร์ผู้สร้างไฟล์กำหนดค่า และจะถามพารามิเตอร์ชุดข้อมูลที่ต้องการ ในตัวอย่างนี้ เราจะมาสร้างชุดข้อมูลที่มีรูปภาพของรถคันโปรดของคุณ พารามิเตอร์แรกที่คำสั่งนี้จะถามคือชุดข้อมูลของคุณควรมีชื่ออะไร ในตัวอย่างนี้ ตั้งชื่อชุดข้อมูลของเราว่า "รถยนต์คันโปรดของฉัน"
Insert a name for your dataset: : My favorite carsจากนั้นเครื่องมือจะถามว่าต้องใช้ตัวอย่างกี่ตัวอย่างต่อการค้นหาเพื่อติดตั้งชุดข้อมูลของคุณ ในการสร้างชุดข้อมูลที่ดีสำหรับการเรียนรู้เชิงลึก จำเป็นต้องมีรูปภาพจำนวนมาก และเนื่องจากเราใช้เครื่องมือค้นหาในการคัดลอกรูปภาพ การค้นหาจำนวนมากด้วยคำหลักที่แตกต่างกันจึงจำเป็นต้องติดตั้งชุดข้อมูลที่มีขนาดเหมาะสม ค่านี้จะสอดคล้องกับจำนวนรูปภาพที่ควรดาวน์โหลดในการค้นหาแต่ละครั้ง ในตัวอย่างนี้ เราต้องการชุดข้อมูลที่มีรูปภาพ 250 ภาพในแต่ละคลาส และเราจะใช้คำหลัก 5 คำเพื่อต่อเชื่อมแต่ละคลาส ดังนั้นหากเราพิมพ์ตัวเลข 50 ที่นี่ IDT จะดาวน์โหลดรูปภาพ 50 ภาพจากคำหลักทุกคำที่ให้ไว้ หากเราระบุคำหลัก 5 คำ เราควรจะได้รูปภาพที่จำเป็น 250 ภาพ
How many samples per search will be necessary? : 50ตอนนี้เครื่องมือจะขอและอัตราส่วนขนาดรูปภาพ เนื่องจากการใช้รูปภาพขนาดใหญ่เพื่อฝึกโครงข่ายประสาทเทียมนั้นไม่สามารถทำได้ เราจึงสามารถเลือกอัตราส่วนขนาดรูปภาพแบบใดแบบหนึ่งต่อไปนี้และย่อขนาดรูปภาพของเราให้มีขนาดนั้นได้ ในตัวอย่างนี้ เราจะเลือกขนาด 512x512 แม้ว่า 256x256 จะเป็นตัวเลือกที่ดีกว่าสำหรับงานนี้ก็ตาม
Choose images resolution:
[1] 512 pixels / 512 pixels (recommended)
[2] 1024 pixels / 1024 pixels
[3] 256 pixels / 256 pixels
[4] 128 pixels / 128 pixels
[5] Keep original image size
ps: note that the aspect ratio of the image will not be changed,
so possibly the images received will have slightly different size
What is the desired image size ratio: 1จากนั้นเลือก "longer_side" สำหรับวิธีการปรับขนาด
[1] Resize image based on longer side
[2] Resize image based on shorter side
[3] Smartcrop
ps: note that the aspect ratio of the image will not be changed,
so possibly the images received will have slightly different size
Desired Image resize method: : longer_side
ตอนนี้ คุณต้องเลือกจำนวนคลาส/โฟลเดอร์ที่ชุดข้อมูลของคุณควรมี ในตัวอย่างนี้ ส่วนนี้อาจเป็นเรื่องส่วนตัวมาก แต่รถคันโปรดของฉันคือ Chevrolet Impala, Range Rover Evoque, Tesla Model X และ (ทำไมจะไม่ใช่) AvtoVAZ Lada ดังนั้นในกรณีนี้ เรามี 4 คลาส สำหรับแต่ละคลาสที่ชื่นชอบ
How many image classes are required? : 4หลังจากนั้นคุณจะถูกขอให้เลือกระหว่างเครื่องมือค้นหาที่มีอยู่ ในตัวอย่างนี้ เราจะใช้ DuckGO เพื่อค้นหารูปภาพให้เรา
Choose a search engine:
[1] Duck GO (recommended)
[2] Bing
[3] Bing API
[4] Flickr API
Select option:: 1ตอนนี้เราต้องกรอกแบบฟอร์มซ้ำๆ เราต้องตั้งชื่อแต่ละคลาสและคำสำคัญทั้งหมดที่จะใช้ในการค้นหาภาพ โปรดทราบว่าส่วนนี้สามารถเปลี่ยนแปลงได้ในภายหลังด้วยโค้ดของคุณเอง เพื่อสร้างคลาสและคีย์เวิร์ดเพิ่มเติม
Class 1 name: : Chevrolet Impalaหลังจากพิมพ์ชื่อคลาสแรกแล้ว เราจะถูกขอให้ระบุคีย์เวิร์ดทั้งหมดเพื่อค้นหาชุดข้อมูล โปรดจำไว้ว่าเราบอกให้โปรแกรมดาวน์โหลดรูปภาพ 50 ภาพสำหรับคำหลักแต่ละคำ ดังนั้นในกรณีนี้เราจะต้องระบุคำหลัก 5 คำเพื่อให้ได้รูปภาพทั้งหมด 250 ภาพ คำหลักแต่ละคำจะต้องคั่นด้วยเครื่องหมายจุลภาค (,)
In order to achieve better results, choose several keywords that will
be provided to the search engine to find your class in different settings.
Example:
Class Name: Pineapple
keywords: pineapple, pineapple fruit, ananas, abacaxi, pineapple drawing
Type in all keywords used to find your desired class, separated by commas: Chevrolet Impala 1967 car photos,
chevrolet impala on the road, chevrolet impala vintage car, chevrolet impala convertible 1961, chevrolet impala 1964 lowrider
จากนั้นทำซ้ำขั้นตอนการกรอกชื่อคลาสและคีย์เวิร์ดจนกระทั่งครบ 4 คลาสที่ต้องการ
Dataset YAML file has been created successfully. Now run idt build to mount your dataset!สร้างไฟล์การกำหนดค่าชุดข้อมูลของคุณแล้ว ตอนนี้เพียงแค่สนิมคำสั่งต่อไปนี้แล้วดูความมหัศจรรย์เกิดขึ้น:
user@admin:~ $ idt buildและรอในขณะที่ชุดข้อมูลกำลังถูกเมาท์:
Creating Chevrolet Impala class
Downloading Chevrolet Impala 1967 car photos [#########################-----------] 72% 00:00:12
ในตอนท้าย รูปภาพทั้งหมดของคุณจะอยู่ในโฟลเดอร์ที่มีชื่อชุดข้อมูล นอกจากนี้ ไฟล์ CSV ที่มีสถิติชุดข้อมูลจะรวมอยู่ในโฟลเดอร์รูทของชุดข้อมูลด้วย
เนื่องจากการเรียนรู้เชิงลึกมักกำหนดให้คุณต้องแบ่งชุดข้อมูลออกเป็นชุดย่อยของโฟลเดอร์การฝึกอบรม/การตรวจสอบความถูกต้อง โปรเจ็กต์นี้จึงสามารถดำเนินการนี้ให้คุณได้เช่นกัน! เพียงแค่เรียกใช้:
user@admin:~ $ idt splitตอนนี้คุณต้องเลือกรถไฟ/สัดส่วนที่ถูกต้อง ในตัวอย่างนี้ ฉันเลือกว่า 70% ของรูปภาพจะถูกสงวนไว้สำหรับการฝึก ในขณะที่ส่วนที่เหลือจะถูกสงวนไว้สำหรับการตรวจสอบความถูกต้อง:
Choose the desired proportion of images of each class to be distributed in train/valid folders.
What percentage of images should be distributed towards training?
(0-100): 70
70 percent of the images will be moved to a train folder, while 30 percent of the remaining images
will be stored in a validation folder.
Is that ok? [Y/n]: yแค่นั้นแหละ! ตอนนี้ควรพบการแยกชุดข้อมูลพร้อมกับไดเรกทอรีย่อยรถไฟ/ที่ถูกต้อง
โปรเจ็กต์นี้กำลังได้รับการพัฒนาในช่วงเวลาว่างของฉัน และยังต้องใช้ความพยายามอย่างมากเพื่อที่จะไม่มีข้อบกพร่อง คำขอดึงและผู้มีส่วนร่วมได้รับการชื่นชมจริงๆ อย่าลังเลที่จะมีส่วนร่วมในทุกวิถีทางที่คุณสามารถทำได้!


